2023年东南大学论文:Evaluation of ChatGPT as a Question Answering System for Answering Complex Questions
代码库已经无法访问了:https://github.com/tan92hl/Complex-Question-Answering- Evaluation-of-ChatGPT
1.简介
复杂问题的回答(KB-based CQA)是一种很有挑战性的KBQA任务,希望模型能具备compositional reasoning的学习能力,比如通过多步推理、进行集合操作或者其他复杂推理得到最终的答案。
如何去评判ChatGPT的回答表现呢?一方面,该文章采用的方法是,对测试问题进行打多个标签:答案类型(语法分析获得),推理操作,语种(数据集带了),这些标签每一个都可以助于分析ChatGPT的推理能力,标签间的组合也有助于发现潜在的问答场景和ChatGPT的表现情况。另一方面,沿用了checklist的测试方法对模型推理任务执行情况、推理过程可信服进行了测试。
KBQA数据集有很多,格式也不尽相同,这里选择的是基于SPARQL格式的数据集,并利用关键字来识别可能用于回答的推理操作。
结果简述:
- 单语问题的回答上,ChatGPT除了数字和时间类的,其他表现都是最好的;如果问题需要多步推理或者基于事实的推理(这里我不知道start-shape是啥意思),ChatGPT表现不如GPT3.5;多语言问答上,在少数据源的语言上表现最好
- checklist测试上,ChatGPT在复杂问题回答上有几个问题:在单推理类型的任务表现不好(MFT结果);和传统的KBQA相比,ChatGPT在相似问题上表现不稳定(INV结果);ChatGPT并不能按照预期prompt生成相应的结果(DIR结果)
2.相关工作
2.1 LLM和prompt
简单介绍了一下GPT3及3.5、T5、BERT。这里不再赘述。
2.2 LLM的评估
之前最全面的评估要数HELM了(Holistic Evaluation of Language Models,该文为大模型评估方向的综述论文,由Percy Liang团队打造,将2022年四月份前的大模型进行了统一的评估。其中,被评估的模型包括GPT-3,InstructGPT等。在经过大量的实验之后,论文提出了一些可供参考的经验总结。)
和HELM类似,本文提出了自己的评价方法(前面说过了,对测试问题进行打多个标签,然后基于标签进行评估)
2.3 NLP模型的黑盒测试
这里用了CheckList的方案,每一项评估包括三项:最小功能测试(MFT),不变性测试(INV),定向期望测试(DIR)。
1. 最小功能测试(MFT, minimum functionality test): 类似软工中的“单元测试”,用大量简单但具有极强针对性的样例进行测试。
2. 不变性测试(INT, invariance test): 对原有数据做一些不影响结果的轻微变化。比如拼写错误或者语法错误。
3. 定向期望测试(DIR, directional expectation test): 也是对原有数据做少许改动。改动后,模型的结果应该朝一个期望的方向变化。比如“明天星期六,我很{开心}”,“周末要加班,我很{难过}”
接下来的问题就是,有那么多测试要进行,如何针对每一项测试大规模生成测试样例呢?根据checklist原文的说法,测试样例可以完全“无中生有”,也可以通过改动已有数据得到。而作者们已经给出了强大的开源工具,帮助你快速生成测试样例。整个工具完全可视化,操作性极强。
本文采用的是利用CoT prompting来生成INV和DIR的测试用例。
3.本文提出的LLM评估框架
之前在简介也提到了,整个评估框架包含两部分,第一部分是通过试用多标签来描述一个测试问题,第二部分是针对每一个标签,测试模型的功能性、鲁棒性和控制性。、
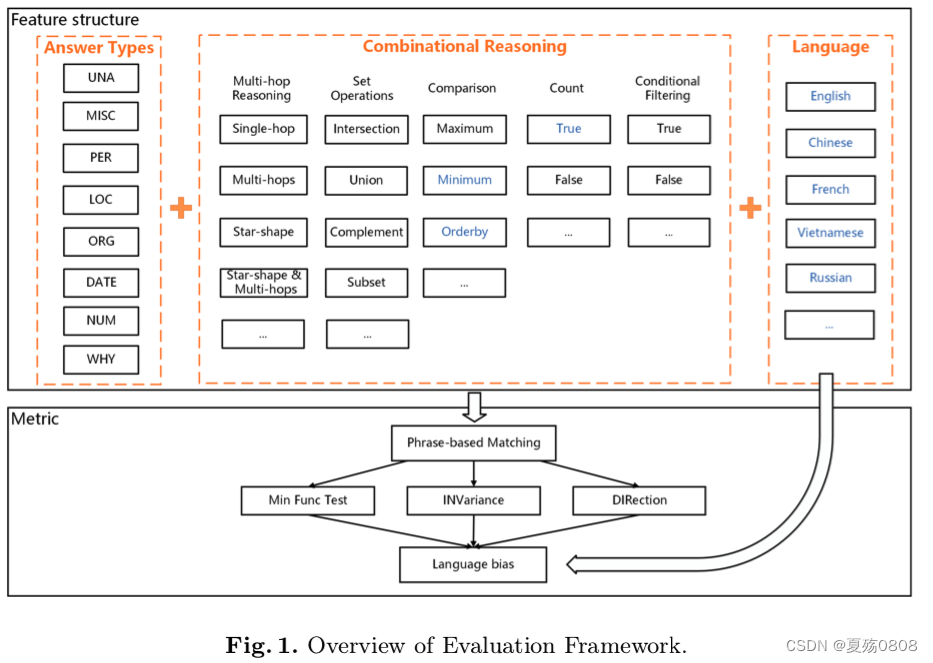
3.1 特征驱动的多标签问题打标
原因:现在数据集使用不同标签来定义回答类型、推理类型等,为了可以进行统一的评估,需要对这些特征类型进行标准化。本文设计了三类标签:回答类型(问题涉及的话题)、推理类型(获得答案的方法)、语言类型(描述问题的语种)。一般一个问题只包含一个回答类型。
- 参考NER类型定义、英文问题类型、现有KBQA数据集给出的回答类型,本文最终选定8类作为回答类型。
- 基于KBQA数据集提供的推理类型,本文选了8个
- 语言标签使用了数据集中的标签
3.2 衡量方法
3.2.1 答案匹配策略
背景:ChatGPT生成的是句子,标答给的是短语
匹配方法:
对于日期、布尔类型、数字的匹配,直接和标答进行匹配。否则,按照如下方式:
基于提取的匹配:
- 将ChatGPT生成的句子进行语法解析,提取出名词短语,然后按照[名词,名词短语,短句]升序排列
- 对标答进行扩充,包括同义、多语言、别名
基于向量的匹配:
如果不能基于名词短语匹配,就是用向量相似度算匹配程度
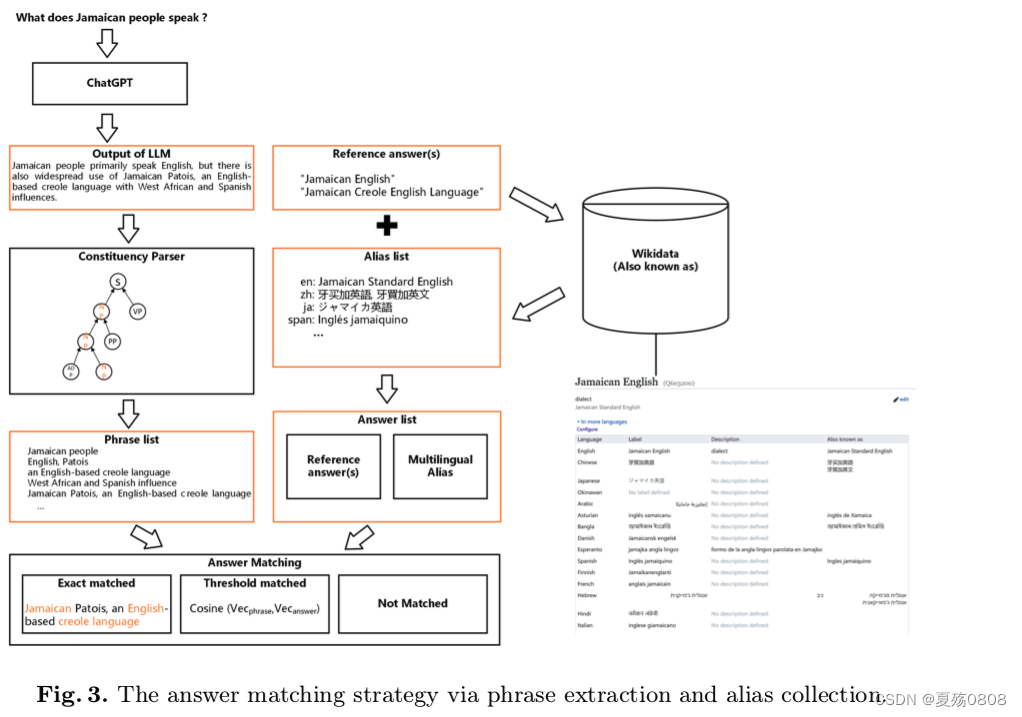
3.2.2 基于prompt的checklist策略
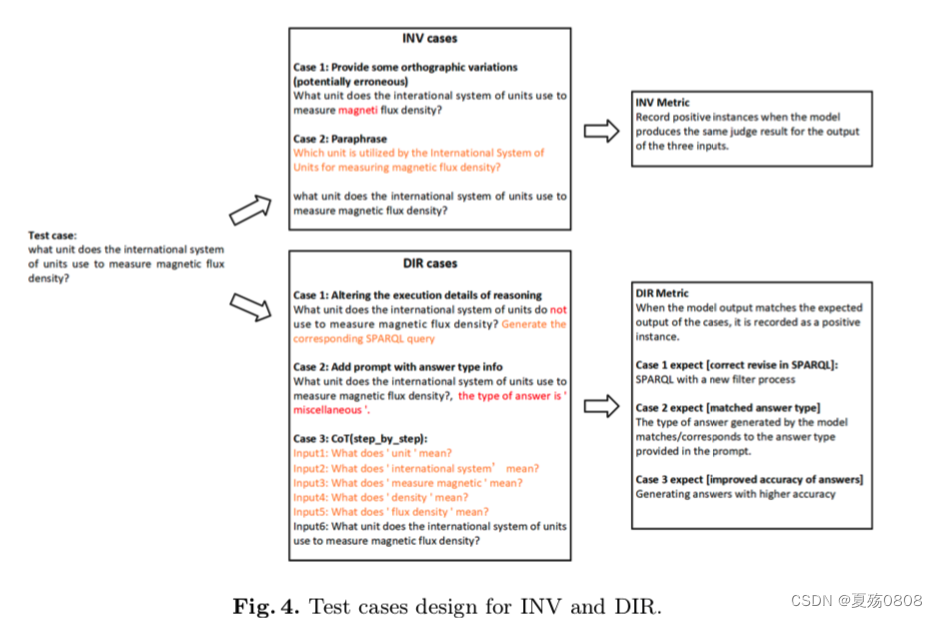
仿照了checklist的指标:MFT、INV、DIR。
MFT示例如下图(SetOperation和Counting的例子不都一样???)

INV:本文通过随机把句子中的词拼错、同义词改写
DIR:首先,替换了问题中与推理相关的短语,要求模型使用 SPARQL 查询生成答案,以观察 ChatGPT 输出中的逻辑操作是否与给出的修改相对应。其次,将包含答案类型的提示添加到输入中,以检查 ChatGPT 是否可以根据提示控制输出答案类型。第三,从CoT中得到启发,使用通用的多轮提示重写让Chat-GPT通过“逐步”过程获得答案的测试用例,以观察ChatGPT对不同类型问题的CoT提示的敏感性.












![[PyTorch][chapter 35][经典卷积神经网络-1 ]](https://img-blog.csdnimg.cn/4002b385d3834ee9b8c9d8cadacfcecb.png)