目录
Mapping 映射
复杂数据类型
Mapping 映射

精确匹配
必须和对应字段值安全一致才可查出
全文检索
缩写搜索全程、格式转换 大小写 同义词

全文检索核心原理
分词,初步的倒排索引的建立
重建倒排索引
时态转换、重复数的转换、同义词的转换、大小写的转换
分词器 analyzer
对单词:切分词语、正规化操作
目的是为了:Recall 召回率 增加返回结果
实现步骤:
1.Character 文本分词预处理解析内容
2.tokenizer 分词
3.token filter :过滤掉无用此内容加转化标准化词
如中文了的呢 是无用词
建立倒排索引
内置分词器
更多分词器可去官网查看
Standard analyzer 标准分词器 standard
Simple analyzer 简单分词器
特定语言分词器

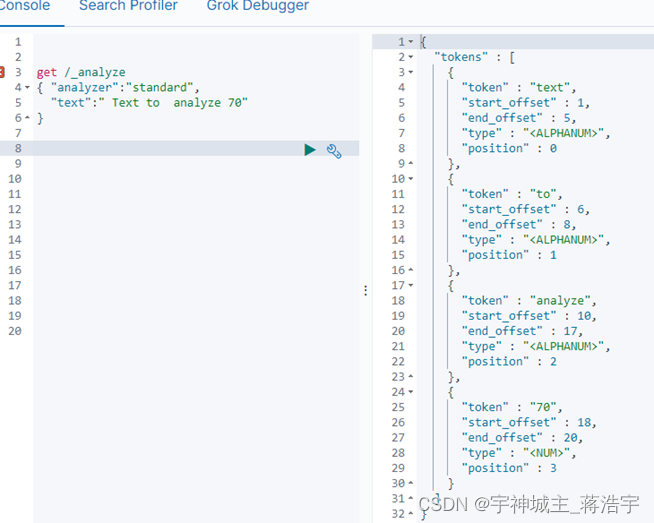
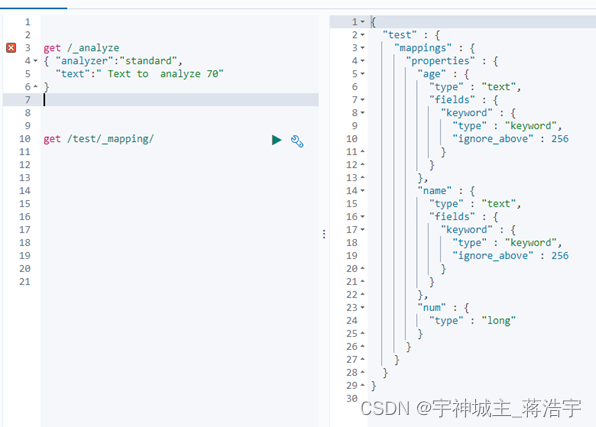
测试分词器
get /_analyze
{ "analyzer":"standard",
"text":" Text to analyze 70"
}
Mapping回顾总结

往es 插入数据 es 会自动建立索引,同时建立对应的mapping动态映射
Mapping中定义类每个 字段的数据类型
不同的数据类型有不同的检索方式 全文检索 准确检索
准确的值倒排索引会全值进入,全文检索,会先分词,再到倒排索引分别检索
Es 还可以自己建立mapping 动态映射,索引行为、分词器等
核心数据类型
String 、byte、short number object geo-print/素组等、更多的看官方文档
动态映射推测规则
True -》boolean
123 -> long
“xxx” - > text/keyword
2019-01-01 -> date
查看 mapping
Get /text/_mapping
手动创建索引映射(定义分词器、数据类型、时间格式化)
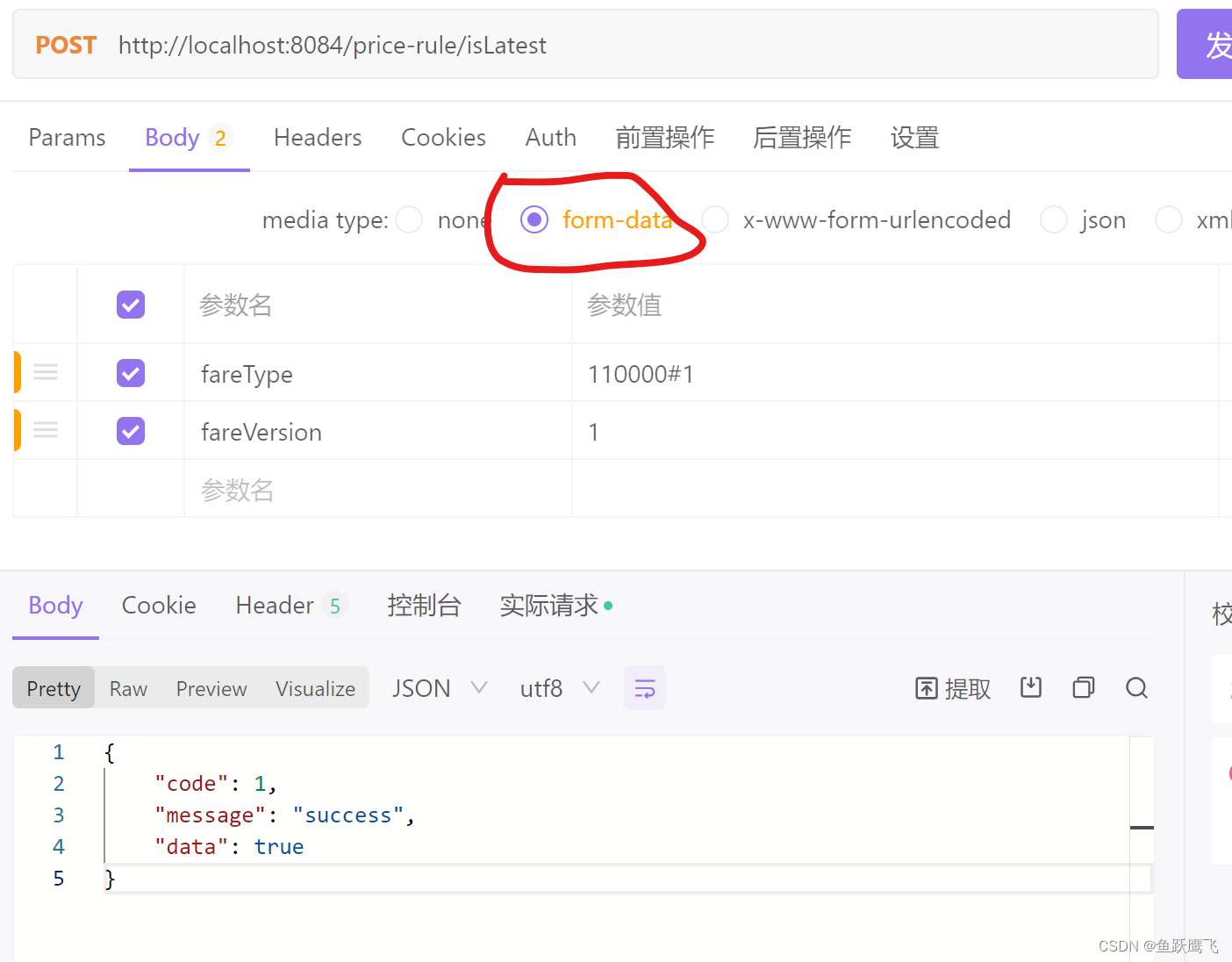
| delete book put book #keyword 不进行分词准确查询 put book/_mapping { "properties":{ "name":{ "type":"text", "analyzer":"english", "search_analyzer":"english" },"pic":{ "type":"keyword" },"timestamp":{ "type":"date", "format":"yyyy-MM-dd" } } } put /book/_doc/4 {"name":"text hello word","pic":"998s" ,"timestamp":"2023-02-01" } get /book/_doc/3 get /book/_search?q=name:text |
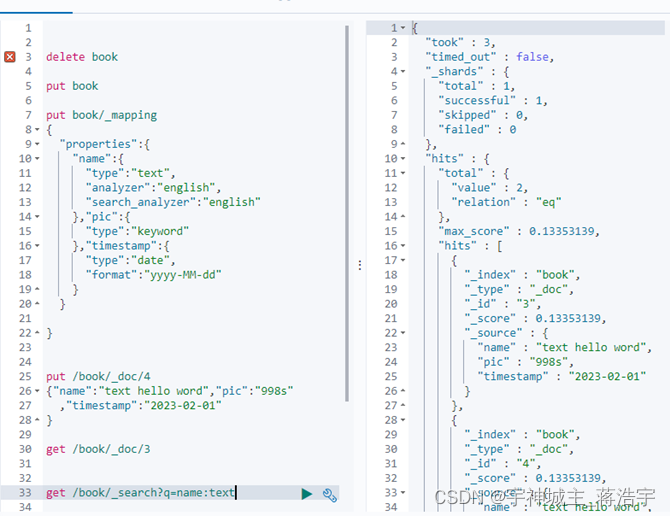
新增映射mapping
| put book/_mapping { "properties":{ "new_filed":{ "type":"text" } } } |
复杂数据类型
数组

空数据
对象


ok
持续更新









![[PyTorch][chapter 35][经典卷积神经网络-1 ]](https://img-blog.csdnimg.cn/4002b385d3834ee9b8c9d8cadacfcecb.png)