一、引言
在该篇文章的引言部分,作者明确阐述了本篇论文的研究目的、问题和方法,并指出了研究的贡献和创新点。以下是具体内容:
- 研究目的:本研究的目的是评估盆腔脂肪肥大的CT成像特征,并探讨其在诊断和管理中的应用价值。
- 研究问题:盆腔脂肪肥大是一种罕见疾病,但其诊断至关重要,因为它可能被误诊为其他盆腔肿块。目前尚未有对该病的CT成像参数进行全面分析的研究。因此,本文旨在进行可靠、准确的CT影像分析,以便有效地管理该病。
- 研究方法:本文使用回顾性病例分析的方法,收集了30例盆腔脂肪肥大病人的CT影像数据,并选取了30例对照组。两位独立的放射学家对所有影像数据进行了详尽全面的CT成像分析,记录了多个影像参数,包括长度、密度、形态特征和增强模式等等。
- 研究贡献和创新点:本文基于全面的CT成像分析提供了可靠的、准确的盆腔脂肪肥大诊断和治疗的新方法。本文提出了新的CT成像分析方法,并建立了相应的参考标准,从而为盆腔脂肪肥大的诊断和治疗提供了信心。此外,本文发现了一些新的、尚未被报道过的盆腔脂肪肥大的形态特征,这些特征将对该病的诊断和治疗产生积极的影响。因此,本文的贡献是建立了一种可靠、有效的CT影像分析方法,为盆腔脂肪肥大的诊断、治疗提供了新的依据,发现了该病的一些新的形态特征,丰富了我们对该病的认识。
二、统计分析案例
2.1 论文思路简析
该论文的设计思路是研究CT成像参数在骶髂部脂肪沉积症(pelvic lipomatosis)的诊断准确性。研究采用了前瞻性研究设计,收集了50例患有骶髂部脂肪沉积症的患者的CT图像和相关病史。同时还选择了50名年龄、性别和体重相似的对照组进行比较。通过对CT图像的分析,研究团队提取了多种成像参数,如脂肪密度、腰椎及骶骨的横截面积和长轴角度等,并进行了相关性和统计分析,以确定哪些参数可以作为骶髂部脂肪沉积症的诊断指标。最后,研究团队评估了这些成像参数的诊断准确性,并与常规诊断方法进行比较。该研究的目的是为临床医生提供更加准确的诊断方法,以便更好地诊治骶髂部脂肪沉积症。
2.2 统计分析过程
2.2.1 统计模块原文描述
All data were analysed by IBM SPSS Statistics Version
23.0 (RRID:SCR_019096) and MedCalc Version 19.0.4
(RRID:SCR_015044). The measurement data, including
PFV, CC/AP, AAP, rLPU, RABS, LABS, DVR and RMI,
are shown as the mean±standard deviation, which was used
to present continuous variables with a normal distribution.
The unpaired t test was performed to compare the signifcant
diferences between PL and controls. Intraclass correlation
efcient (ICC) of PFV was used to show interreader agreement. Binary logistic regression was used in the
combined model of PFV, DVR and rLPU. Receiver
operating characteristic (ROC) curves of PFV, CC/AP, AAP, rLPU, RABS, LABS, DVR, RMI
and the combined model were calculated to refect the sensitivity, specifcity and best threshold.
The area under the ROC curve (AUC) values indicated the diagnostic efciency of each kind of imaging parameter.
Categorical variables, such as bladder shape, cystitis glandularis and hydronephrosis,
are presented as counts and frequencies, and chi-square tests were used to detect their diferences.2.2.2 统计模块译文
所有数据都是使用IBM SPSS Statistics版本23.0(RRID:SCR_019096)和MedCalc版本19.0.4(RRID:SCR_015044)进行分析的。测量数据,包括PFV,CC/AP,AAP,rLPU,RABS,LABS,DVR和RMI,以均值±标准偏差的形式呈现,该形式用于呈现具有正态分布的连续变量。未配对t检验用于比较PL和控制组之间的显著差异。PFV的ICC用于显示读者间一致性。联合模型中使用二元 logistic 回归分析PFV、DVR和rLPU。计算PFV、CC/AP、AAP、rLPU、RABS、LABS、DVR、RMI和联合模型的受试者工作特征曲线(ROC)以反映敏感性、特异性和最佳阈值。ROC曲线下面积(AUC)值表示每种成像参数的诊断效率。如膀胱形状,腺性囊性炎和肾积水等分类变量则以计数和频率呈现,卡方检验则用于检测它们的差异。
2.2.3 分析过程解析

该篇文献采纳了100例数据,其中50例阳性,50例是非阳性的。通过3D建模获取脂肪体积参数,对此做了读者间差异检验(ICC),首先我们先要对数据进行正态性检验,符合正态性的我们使用t检验来验证正常组和患病组之间是否存在差异,并进行ROC分析,选取其中表现优秀的组合成二元回归模型做分析。其中膀胱形状做方差分析膀胱形状,腺性囊性炎和肾积水等分类变量则以计数和频率呈现,卡方检验则用于检测它们的差异。
三、结果呈现
3.1 三线表和ROC曲线

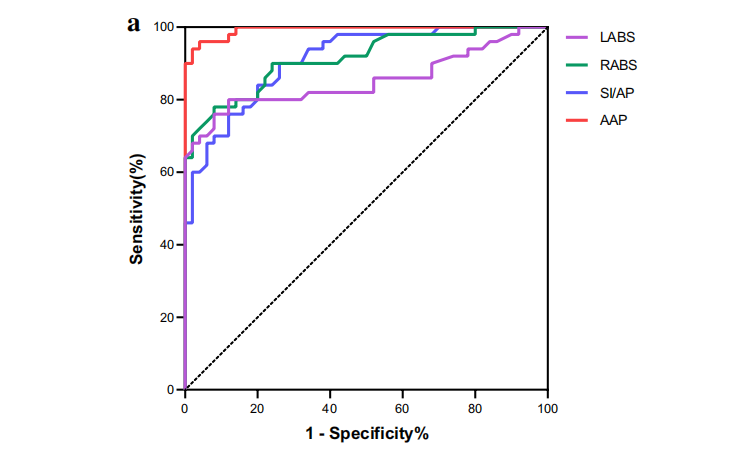
PFV表现出了高敏感度(80%)和特异度(82%),可用于诊断盆腔脂肪病。对膀胱和直肠S形结肠的一系列形态指标进行了测量,构建了它们的ROC曲线,并检测了它们的敏感度和特异度。AAP显示出最高的敏感度,并对PL的预测具有高度的特异性,其次是组合模型。考虑到AAP是一个容易受膀胱充盈影响的不稳定参数,我们将三个参数DVR、PFV和rLPU结合在一个logistic模型中(AUC=0.965)。这三个指标在所分析的指标中相对稳定,而其他指标则或多或少地受膀胱充盈的影响。从前列腺中央隆起到直肠前壁的距离(DVR)相对稳定。一方面,前列腺中央隆起的位置相对固定。另一方面,PL患者的直肠主要是在横向直径上受到压缩,所以直肠前壁的位置受其充盈状态的影响较小,相对固定。盆腔脂肪体积(PFV)是由3D建模软件计算的定量指标,具有良好的重复性。相对后尿道的长度(rLPU)也相对稳定,由于膀胱颈和耻骨联合的位置相对固定。
3.2 列线图
 在三个独立变量中,DVR具有最大的系数和对总分数的最大影响力,而rLPU对结果的影响最小。PFV、DVR和rLPU的值分别对应于图表上的尺度刻度。将每个变量的分数加起来,可以得到总分数,并用于预测PL的概率。总分数越高,PL的概率越高。这个计算尺可以为医生和患者提供一种可视化和方便的预测工具,根据总分数所对应的风险,可以预测PL的概率。
在三个独立变量中,DVR具有最大的系数和对总分数的最大影响力,而rLPU对结果的影响最小。PFV、DVR和rLPU的值分别对应于图表上的尺度刻度。将每个变量的分数加起来,可以得到总分数,并用于预测PL的概率。总分数越高,PL的概率越高。这个计算尺可以为医生和患者提供一种可视化和方便的预测工具,根据总分数所对应的风险,可以预测PL的概率。
四、方法和图例再现
接下来我们将使用引入R语言中的一个数据集iris,模拟和在现论文中的分析过程和展示图例。
# 代码
library(MASS)
data(Pima.tr)
head(Pima.tr)
# 执行结果
npreg glu bp skin bmi ped age type
1 5 86 68 28 30.2 0.364 24 No
2 7 195 70 33 25.1 0.163 55 Yes
3 5 77 82 41 35.8 0.156 35 No
4 0 165 76 43 47.9 0.259 26 No
5 0 107 60 25 26.4 0.133 23 No
6 5 97 76 27 35.6 0.378 52 Yes
4.1 正态性检验
使用for循环对Pima.tr数据集中所有数值型变量进行Shapiro-Wilk检验,并输出检验结果。
vars <- colnames(Pima.tr)[-9]
for (v in vars) {
test_result <- shapiro.test(Pima.tr[[v]])
cat(v, "\tW statistic:", test_result$statistic, "\tp-value:", test_result$p.value, "\n")
}输出结果为:
preg W statistic: 0.9400804 p-value: 5.301407e-15
plas W statistic: 0.9542823 p-value: 7.115389e-12
pres W statistic: 0.937386 p-value: 2.990018e-15
skin W statistic: 0.9189663 p-value: 9.013598e-18
insu W statistic: 0.6710282 p-value: 1.051259e-31
mass W statistic: 0.9691707 p-value: 1.462652e-08
pedi W statistic: 0.7838287 p-value: 1.630291e-27
age W statistic: 0.9829034 p-value: 0.01013013 所有参数的结果p值均小于0.05,全部不符合正态性检验。
4.2 非配对t检验
这个是要符合正态性检验才能使用的,没办法,这个数据集没有符合的,先就假设所有参数都符合。
# 对所有参数进行非配对t检验
param_names <- colnames(Pima.tr)[,7]
t_test_results <- list()
for (i in seq_along(param_names)) {
p1 <- Pima.tr[Pima.tr$type == "Yes", param_names[i]]
p2 <- Pima.tr[Pima.tr$type == "No", param_names[i]]
t_result <- t.test(p1, p2)
t_test_results[[i]] <- t_result$p.value
}
# 输出检验结果
for (i in seq_along(param_names)) {
cat("Variable:", param_names[i], "\n")
cat(" Group1: Yes, Group2: No\t\t", "p-value:", t_test_results[[i]][1], "\n")
}
输出结果为:
Variable: npreg
Group1: Yes, Group2: No p-value: 0.0005685465
Variable: glu
Group1: Yes, Group2: No p-value: 2.080652e-11
Variable: bp
Group1: Yes, Group2: No p-value: 0.003664884
Variable: skin
Group1: Yes, Group2: No p-value: 0.00110362
Variable: bmi
Group1: Yes, Group2: No p-value: 1.188172e-05
Variable: ped
Group1: Yes, Group2: No p-value: 0.00811046
Variable: age
Group1: Yes, Group2: No p-value: 8.10605e-07
Variable: type
Error in t_test_results[[i]]
所有参数均有统计学意义,太多了,随便挑三个做RCO曲线。正常情况下,所有的有统计学意义的都要做ROC分析。
4.3 ROC分析
library(pROC)
roc1 <- roc(Pima.tr$type ~ Pima.tr$skin)
roc1$auc # AUC
ci.auc(roc1) # 95%可信区间
coords(roc1,"best",transpose = FALSE) # 敏感度 特异度 截断值
roc2 <- roc(type ~ ped,data = Pima.tr)
roc2$auc # AUC
ci.auc(roc2) # 95%可信区间
coords(roc2,"best",transpose = FALSE) # 敏感度 特异度 截断值
roc3 <- roc(type ~ age,data = Pima.tr)
roc2$auc # AUC
ci.auc(roc3) # 95%可信区间
coords(roc3,"best",transpose = FALSE) # 敏感度 特异度 截断值
# 绘制ROC曲线
plot(roc1,col="red",legacy.axes=T)
plot(roc2,col="blue",legacy.axes=T,add=TRUE)
plot(roc3,col="green",legacy.axes=T,add=TRUE)
legend("bottomright", legend = c("skin", "ped","age"), col = c("red", "blue","green"),
lty = 1, lwd = 2, box.lty = 0)输出结果:
Area under the curve: 0.6472
95% CI: 0.5693-0.725 (DeLong)
threshold specificity sensitivity
1 22.5 0.3939394 0.8970588
Area under the curve: 0.6253
95% CI: 0.5439-0.7066 (DeLong)
threshold specificity sensitivity
1 0.3425 0.5530303 0.7058824
Area under the curve: 0.6253
95% CI: 0.6588-0.8079 (DeLong)
threshold specificity sensitivity
1 28.5 0.6666667 0.7647059
4.4 读者间差异ICC
这个需要两个或者多个读者对同一个指标做评判才可演示。目前只能自造数据了。
install.packages("irr")
library(irr)
# 创建两个随机数据
set.seed(123)
data1 <- rnorm(10, mean = 5, sd = 2)
data2 <- rnorm(10, mean = 5, sd = 2)
# 将数据放入数据框
df <- data.frame(data1, data2)
head(df)
# 计算ICC
icc(df, type = "agreement", unit = "single")结果展示
data1 data2
1 3.879049 7.448164
2 4.539645 5.719628
3 8.117417 5.801543
4 5.141017 5.221365
5 5.258575 3.888318
6 8.430130 8.573826
Single Score Intraclass Correlation
Model: oneway
Type : agreement
Subjects = 10
Raters = 2
ICC(1) = 0.602
F-Test, H0: r0 = 0 ; H1: r0 > 0
F(9,10) = 4.03 , p = 0.0203
95%-Confidence Interval for ICC Population Values:
0.032 < ICC < 0.8824.5 二元逻辑回归
library(rms)
library(MASS)
# 运行二元逻辑回归模型
ddist <- datadist(Pima.tr)
options(datadist = "ddist")
fit <- lrm(type ~ skin+ped+age, data = Pima.tr)
summary(fit)
# 画出列线图
nomo <- nomogram(fit)
plot(nomo, cex.axis = 0.8)结果展示:
Effects Response : type
Factor Low High Diff. Effect S.E. Lower 0.95 Upper 0.95
skin 20.7500 36.000 15.2500 0.49841 0.24489 0.018433 0.97839
Odds Ratio 20.7500 36.000 15.2500 1.64610 NA 1.018600 2.66020
ped 0.2535 0.616 0.3625 0.63049 0.20904 0.220770 1.04020
Odds Ratio 0.2535 0.616 0.3625 1.87850 NA 1.247000 2.82980
age 23.0000 39.250 16.2500 1.20180 0.25737 0.697340 1.70620
Odds Ratio 23.0000 39.250 16.2500 3.32600 NA 2.008400 5.50820 
4.6 卡方检验
data <- Pima.tr
# 添加一个是否超重的参数
data$over_weight[data$bmi >= 30] <- 1
data$over_weight[data$bmi < 30] <- 0
columns <- c('bmi','type')
subset <- data[columns]
tbl <- table(subset)
chisq.test(tbl)
结果展示:
Pearson's Chi-squared test
data: tbl
X-squared = 123.35, df = 119, p-value = 0.3738五、邀请词
至此为止,所有的统计方法和画图代码均已复刻出来。如果你有什么想要我分析和复刻的论文,请关注点赞私信我,我来给你复现出来。欢迎加入医疗统计联盟,一起分享一起学习。向着SCI出发吧。 ✔






![[已解决] 决定系数R2为何为负 from sklearn.metrics import r2_score](https://img-blog.csdnimg.cn/14a86e054d2d4f65bf377e1238b482a1.png)