文章目录
- 什么是LRU?
- 设计思路
- 代码实现
LRU是我在面试过程中遇到的比较多的算法题了,并且我自己的项目中也手写了LRU算法,所以觉得还是有必要掌握一下这个重要的算法的。
什么是LRU?
LRU是一种缓存淘汰策略。
我们知道,计算机的缓存容量有限,如果缓存占用满了,那么我们就需要删除一些旧数据,并且把新数据放进来,那么问题就是,我们应该选择删除什么数据呢?或者说,我们应该使用一种什么样子的策略来删除数据呢?
LRU 缓存淘汰算法就是一种常用策略。LRU 的全称是 Least Recently Used,也叫“最近最少使用”算法,它意味着我们需要删除的数据是那些在最近一段时间内,最少使用的哪些数据,因为它认为在这段时间内使用最频繁的数据还有可能继续被使用,而那些很久没有被使用的数据很可能不会再次被使用。
这就是LRU(Least Recently Used)策略。与此同时还有其他缓存淘汰策略,比如按访问频率(LFU 策略)来淘汰等等,各有应用场景。本文讲解 LRU 算法策略。
并且,我们使用的这种算法,不能因为使用了这种算法,导致降低对缓存这种高速缓冲区的访问速度,因此,我们要求,我们的算法的时间复杂度是O(1)。
也就是我们放入以及查询元素的时间复杂度都必须是O(1)。
设计思路
从上面的对LRU的了解我们可以知道,LRU算法需要满足如下几个要求:
1:首先这个数据结构必须是有时序的,以区分最近使用的和很久没有使用的数据,当容量满了之后,要删除最久未使用的那个元素。
2:要在这个数据结构中快速找到某个 key 是否存在,并返回其对应的 value。
3:每次访问这个数据结构中的某个 key,需要将这个元素变为最近使用的。也就是说,这个数据结构要支持在任意位置快速插入和删除元素。
对于查找,我们知道Hash表的查找速度是很快的,但是并不满足时序问题。
对于任意位置的插入,以及顺序问题,我们可以想到链表,但是链表的访问并不是随机的,是需要顺序遍历的。
所以,我们得让哈希表和链表结合,形成一个新的数据结构,那就是:哈希链表。
这也就是为什么大部分的LRUCache都是直接基于LinkedHashMap了。
当然,面试的时候肯定不允许直接用LinkedHashMap来做LRUCache。
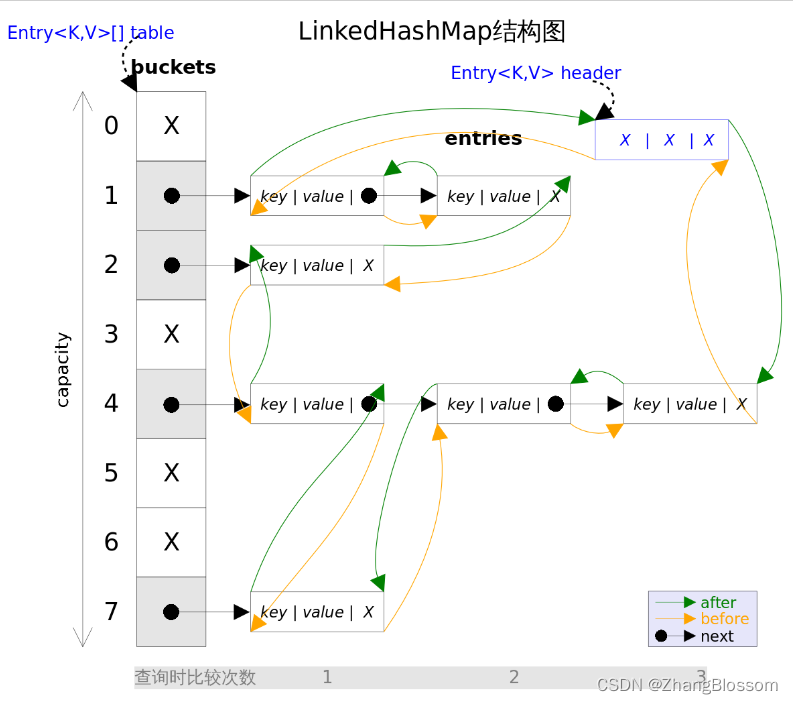
借助这个结构,我们再来分析一下上面的三个条件:
1:如果每次默认从链表尾部添加元素,那么显然越靠近尾部的元素就越是最近使用的。越靠近头部的元素就是越久未使用的。
2:对于某一个 key ,可以通过哈希表快速定位到链表中的节点,从而取得对应的 value。
3:链表显示是支持在任意位置快速插入和删除的,修改指针就行。但是单链表无非按照索引快速访问某一个位置的元素,都是需要遍历链表的,所以这里借助哈希表,可以通过 key,快速的映射到任意一个链表节点,然后进行插入和删除。
一、为什么这里要使用双向链表,而不是单向链表?
我们在找到了节点,需要删除节点的时候,如果使用单向链表的话,后驱节点的指针是直接能拿到的,但是这里要求时间复杂度是O(1),要能够直接获取到前驱节点的指针,那么只能使用双向链表。
二、哈希表里面已经保存了 key ,那么链表中为什么还要存储 key 和 value 呢,只存入 value 不就行了?
当我们在删除节点的时候,除了需要删除链表中的节点,还需要删除hash表中的节点,删除哈希表需要知道key,那么这个key从哪里来?那只能从节点里来,所以在节点里key和value都需要存(在删除链表中节点的方法里需要return key,具体见下面的代码)。
代码实现
代码实现
package com.base.learn.cache;
import java.util.HashMap;
/**
* @author: 张锦标
* @date: 2023/5/26 12:32
* LRUCache类
*/
public class LRUCache<V> {
private HashMap<String,Node<V>> map = new HashMap<>();
private Integer limit ;
private Node<V> head;
private Node<V> end;
public LRUCache(Integer limit) {
this.limit = limit;
}
public V get(String key){
//1:从map中获取,如果没有获取到,那么返回null
Node<V> node = map.get(key);
if (node==null){
return null;
}
//2:获取到了,需要将当前节点移动到链表尾部
removeNodeToTail(node);
return node.value;
}
private void removeNodeToTail(Node<V> node) {
//如果已经是队尾的节点无需移动
if (node == end) {
return;
}
//先从原位置删掉
removeNode(node);
//放到链尾
addNodeToTail(node);
}
/**
* 将当前节点放入到链表尾部
* @param node 要放入到链表尾部的节点
*/
private void addNodeToTail(Node<V> node) {
if (end != null) {
end.next = node;
node.pre = end;
node.next = null;
}
end = node;
if (head == null) {
head = node;
}
}
/**
* 删除链表中的节点
* @param node 要删除的节点
* @return 返回被删除的节点对应的key
*/
private String removeNode(Node<V> node) {
if (node == head && node == end) {
//移除唯一的节点
head = null;
end = null;
} else if (node == end) {
//移除尾节点
end = end.pre;
end.next = null;
} else if (node == head) {
//移除头节点
head = head.next;
head.pre = null;
} else {
//移除中间节点
node.pre.next = node.next;
node.next.pre = node.pre;
}
return node.key;
}
public void put(String key,V value){
Node<V> node = map.get(key);
if (node != null) {
//节点已存在更新里面的值
node.value = value;
//移动到链尾
removeNodeToTail(node);
} else {
//不存在,首先判断容量,容量满的情况下先删除不常用的,然后插入新节点,容量不满的情况下直接插入
if (map.size() >= limit) {
//从链表中移除最不常用的
String oldKey = removeNode(head);
//从hashmap中移除
map.remove(oldKey);
}
node = new Node(key, value);
//添加到链尾
addNodeToTail(node);
//添加到hashmap
map.put(key, node);
}
}
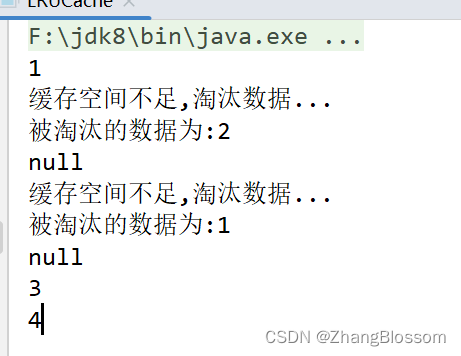
public static void main(String[] args) {
LRUCache<String> cache = new LRUCache(2);
cache.put("1", "1");
cache.put("2", "2");
System.out.println(cache.get("1"));
cache.put("3", "3");
System.out.println(cache.get("2"));
cache.put("4", "4");
System.out.println(cache.get("1"));
System.out.println(cache.get("3"));
System.out.println(cache.get("4"));
}
}
class Node<V>{
public Node pre;
public Node next;
public String key;
public V value;
public Node(String key, V value) {
this.key = key;
this.value = value;
}
}

![[已解决] 决定系数R2为何为负 from sklearn.metrics import r2_score](https://img-blog.csdnimg.cn/14a86e054d2d4f65bf377e1238b482a1.png)