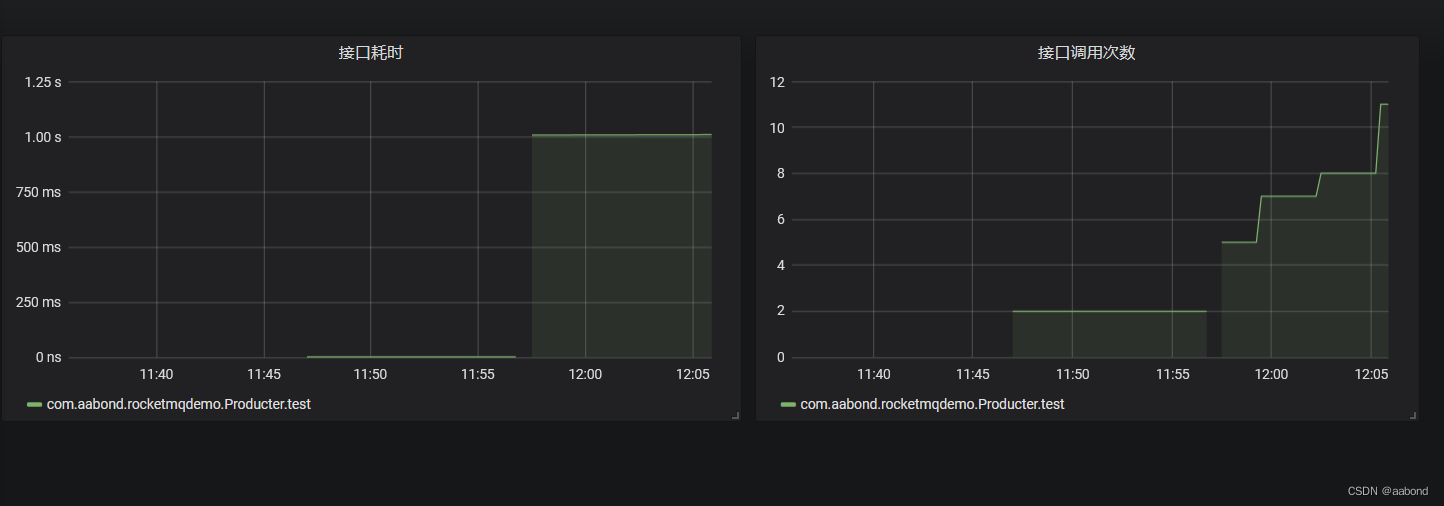
如标题所示,本博客主要讲述
void ORBextractor::ComputeKeyPointsOctTree(vector<vector<KeyPoint>> &allKeypoints){}函数中maxY = iniY + hCell + 6 为怎么是+6而不是+3?
为了连续性,会介绍一下ComputeKeyPointsOctTree函数,参考博客:参考链接
(如果对这个函数很熟悉,可以直接跳到第二部分)
一: ComputeKeyPointsOctTree函数介绍
1.这个函数要做什么
将每层图像金字塔图像分成一个个小块、并对对每一块用FAST算法提取特征点,由于提取的特征点数目肯定很多,我们需要按照ORBExtrator构造函数中要求的每层应该提取的特征点数目进行特征点筛选并分散特征点(离散化特征点并让特征点分布均匀),得到最终所有图像金字塔提取到的关键点,并且求出这些特征点的角度信息。
我们定义了双层的vector容器存储所有的特征点,注意此处为二维的vector,第一维存储的是金字塔的层数,第二维存储的是那一层金字塔图像里提取的所有特征点。
vector < vector<KeyPoint> > allKeypoints;
然后我们调用函数使用四叉树的方式计算每层图像的特征点并进行分配。回忆一下,我们是要将配置文件规定的特征点数目分配到各个金字塔层中,我们在上篇文章已经讲述了怎么把nFeatures个特征点分配到nLevels中,然而只是规定了数目,具体怎么分布没定,再通俗易懂的说,上一步(下面链接)我们只是创建了金字塔规定了每层金字塔分配多少,但它还是个空金字塔,这个函数我们将此空金字塔填满!ORB-SLAM2 ---- ORBextractor::ComputePyramid函数_Courage2022的博客-CSDN博客
2.循环变量的定义及三层循环
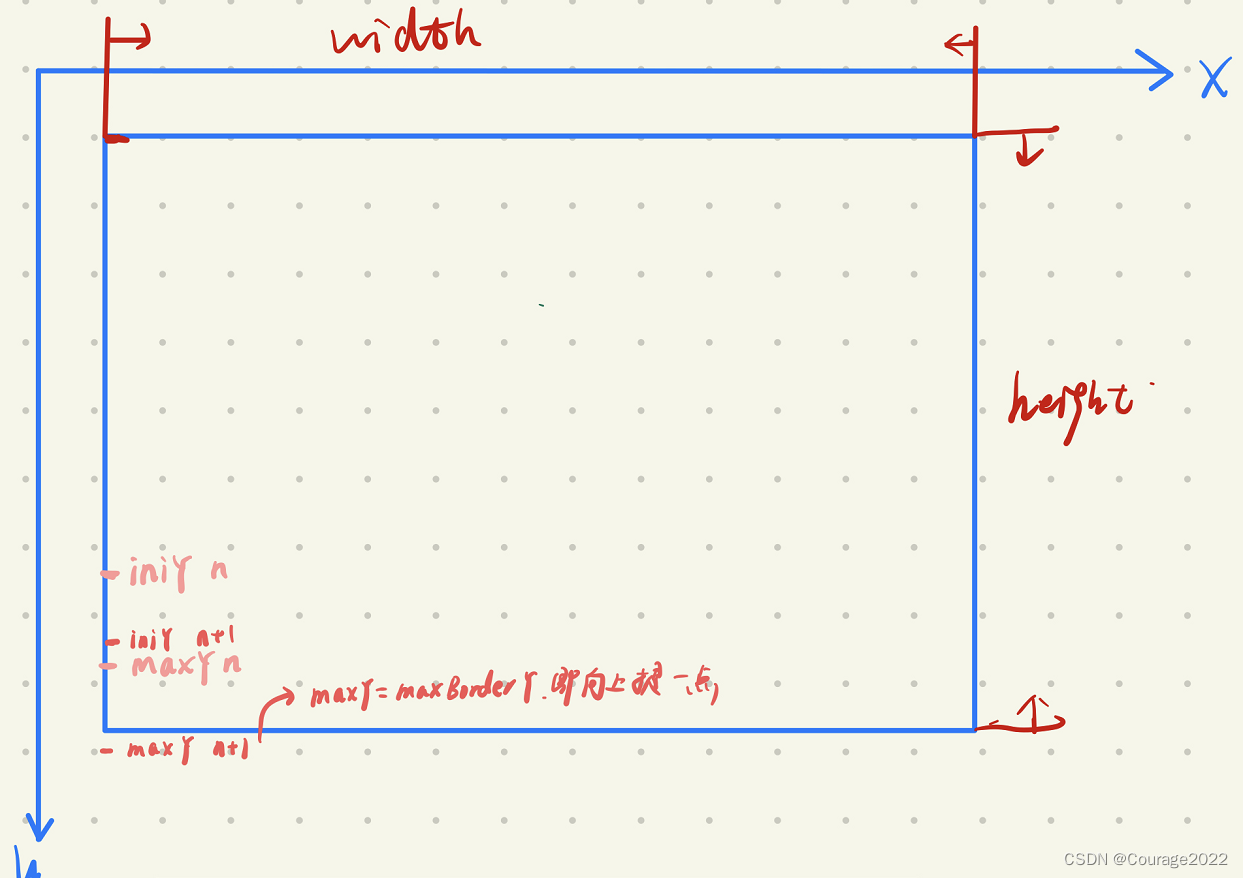
2.1 level循环的minBorderX、minBorderY、maxBorderX、maxBorderY
我们定义了第一层(对图像金字塔的每一个level )循环变量minBorderX、minBorderY、maxBorderX、maxBorderY,如下图所示:
因此图像的坐标边界就是原图像扩充了3个像素值,为什么扩充像素值上篇文章我已经说过,不再赘述!
[注]:这里的小黑色方块表示图像,红色方块表示在图像基础上向外扩展了3个像素值,为的是在图像边界的像素也有机会提取到关键点。
2.2 level循环的vToDistributeKeys、width 、height、nCols、nRows、wCell、hCell
[注]:这里的width 、height为上图红色方块的;nCols、nRows表示图像块cell在行,和列上分别有多少个;wCell、hCell图像块cell所占的像素行数和列数。
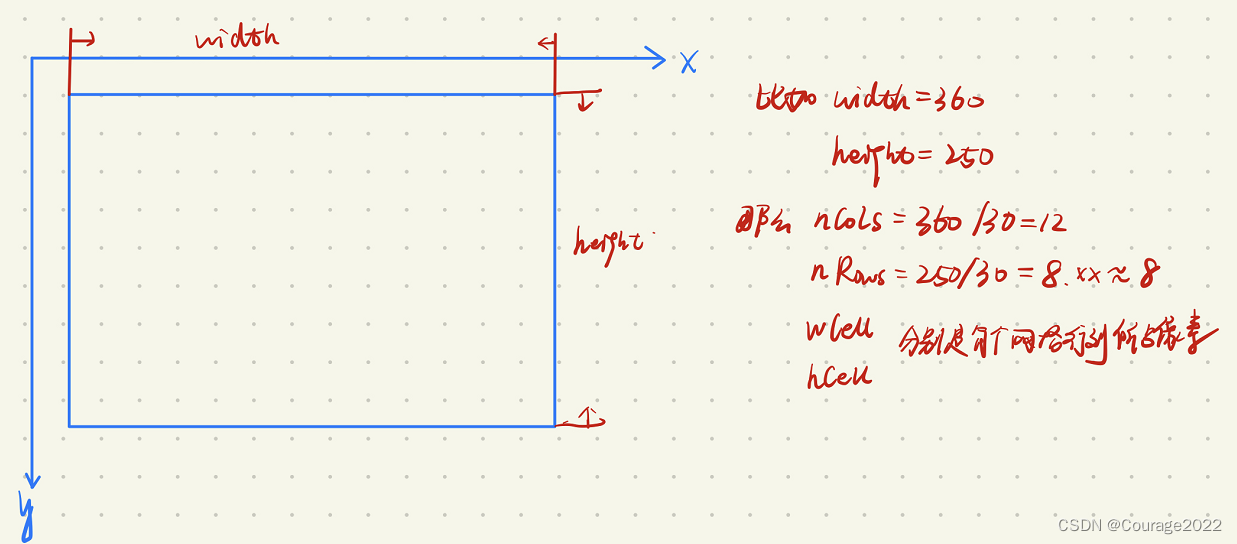
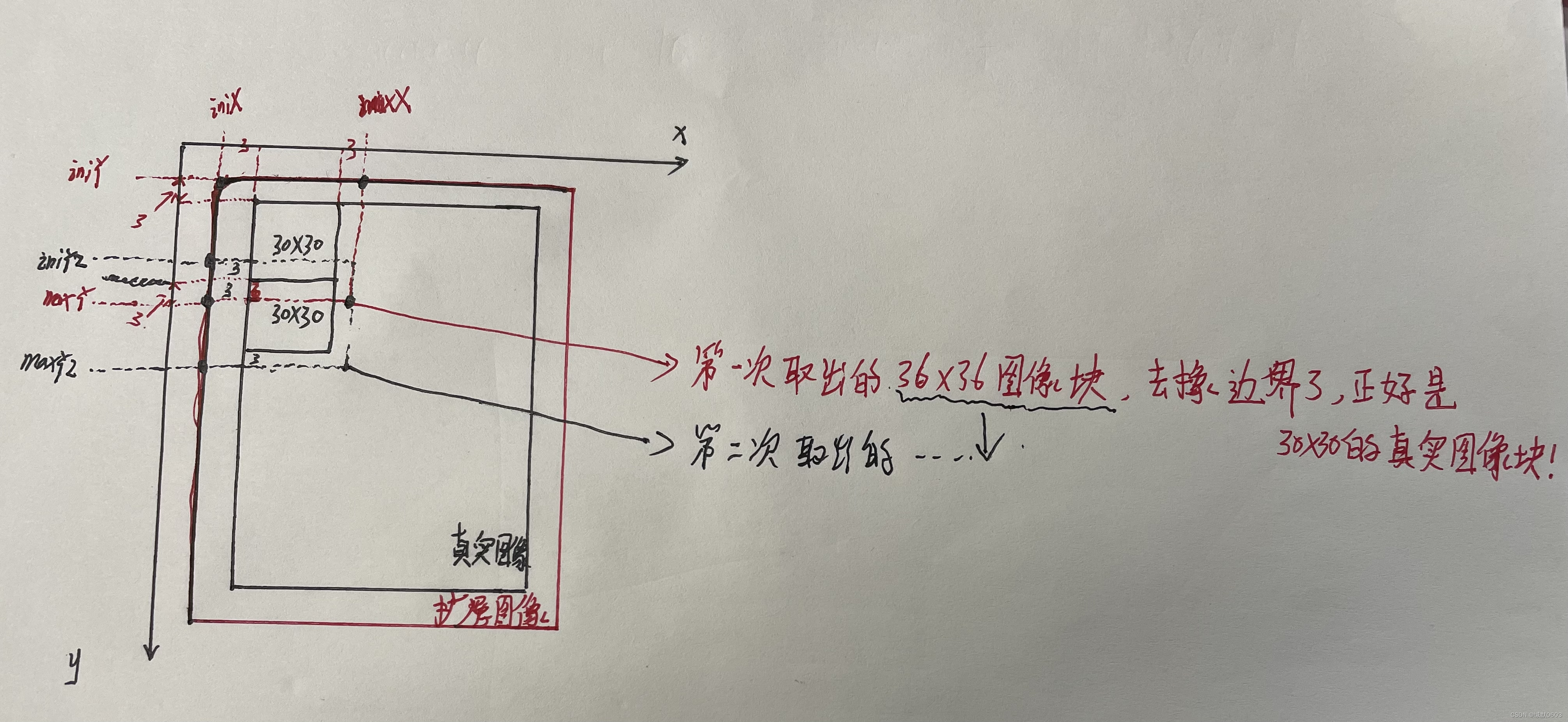
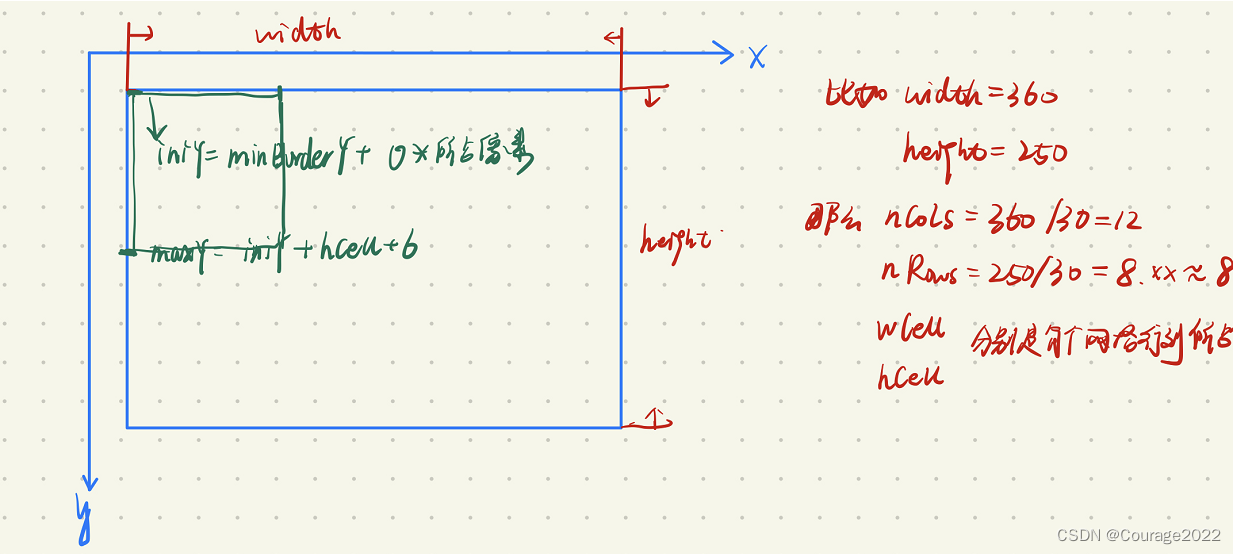
2.3 第二层第三层遍历中的iniX、maxX、iniY、maxY
假设我们第一次循环,各变量如下图所示:
那为什么要加6呢?还是因为边缘匹配特征点的缘故,我们在图像外面加个3像素的壳子、确保边缘的部分可以提取出特征点! (这里是参考博客里的解释,我觉得不是很清晰,解释这里就是写这篇博客的目的,下面讲)
3.三个循环做了什么
第一层for循环:算出每一层的循环遍变量、供下面两层使用
第二层for循环:对每一行进行遍历,算出初始与最大行坐标,上一层的maxY和下一层的iniY如图所示,这样是因为有6的缘故。
此外,如果初始化的iniY大于边界-3,说明已经超过图像边界了,为什么是-3呢,因为我们用FAST提取关键点时为了避免边界无法提取的情况,要在外面加上个半径为3的外壳,这也是为什么加6的原因。如果iniY大于边界-3的话,那就说明壳子到边界了。
此外,如果该网格的最大Y坐标超越了边界坐标,就让最大的Y坐标变成边界坐标。
列的遍历也是如此。
在最内层循环中,我们用一个容器vector<cv::KeyPoint> vKeysCell存储当前网格提取出的特征点。调用opencv的内置函数提取特征点。

二:maxY = iniY + hCell + 6 为怎么是+6而不是+3?
先看代码:
// 计算进行特征点提取的图像区域尺寸
const float width = (maxBorderX - minBorderX);
const float height = (maxBorderY - minBorderY);上面两行代码表示的是上面提到的红色方块,即真实图像边界扩展来3个像素边界的图像(后续成为:扩展图像)。然后对扩展图像分块:
// 计算网格在当前层的图像有的行数和列数
const int nCols = width / W;
const int nRows = height / W;
// 计算每个图像网格所占的像素行数和列数
const int wCell = ceil(width / nCols);
const int hCell = ceil(height / nRows);随后两个for循环就是对图像块的个数进行遍历:
// 开始遍历图像网格,还是以行开始遍历的
for (int i = 0; i < nRows; i++)
{
const float iniY = minBorderY + i * hCell;
float maxY = iniY + hCell + 6;
// 开始列的遍历
for (int j = 0; j < nCols; j++)
{
...
}
}解释:
按照这个代码流程,很容易让人误解为将扩展图像分为30x30的小图像块,并且分别对小图像块提取关键点...,这样想就一直不明白+6的意思了...
因为FAST提取关键点时为了避免边界无法提取的情况,要在外面加上个半径为3的外壳,所以 送入FAST()函数中的图像块大小为36x36。这就是+6的目的是,为了保证,在FAST()函数中参与提取关键点的是每个30x30的真实图像的图像块。
如果这样写代码:将真实图像分为30x30的图像块,对每个图像块都扩展一次3个像素的边界,然后送入FAST()函数中提取关键点,就不会误解了,但是会更多消耗计算资源。这就是+6的目的了
图片示例: