谷歌CEO桑达尔・皮查伊(Sundar Pichai)亲切地将2023年称为是一个AI busy year,当地时间5月10日,谷歌IO大会上,谷歌大语言模型PaLM 2虽迟但到。作为一个“AI-first”公司,谷歌在Bard聊天机器人爆出事实性错误的之后几个月,终于推出了全新一代大语言模型PaLM 2。

技术报告链接:
https://ai.google/static/documents/palm2techreport.pdf


如果要追溯大语言模型的发展脉络,恐怕还得从2017年谷歌大脑Vaswani等人[1]提出的Transformer架构说起,虽然PaLM 2发布时间相比于OpenAI的GPT-4晚了一点,但是早在2022年4月,谷歌大模型的第一代版本PaLM就已经发布。坐拥互联网全家桶业务的谷歌,为PaLM 2一次性提供了四个不同规模的版本,以适用于各种不同的应用场景,四个版本从小到大分别为Gecko(壁虎)、Otter(水獭)、Bison (野牛)和 Unicorn (独角兽)。其中最轻量的Gecko(壁虎)模型甚至可以在移动端直接部署,并且可以保证非常可靠的运行速度,在离线时也能在手机上稳定运行。

谷歌同时发布了长达92页的PaLM 2技术报告,文中强调,PaLM建立在谷歌在机器学习和可靠性人工智能(responsible AI)领域的突破性研究基础之上。
在这份技术报告中,谷歌首先致敬了信息论之父克劳德・香农(C.E.Shannon) 在1951年发表的论文《Prediction and Entropy of Printed English》[2],香农在这篇论文中首次提出了可以通过预测文本中的下一个词来估计语言中所含信息的观点,这一观点可以被视为是后来语言建模(language modeling)的核心。报告随后从模型缩放实验、训练数据集构成、性能评估实验和可靠性使用等多个方面对PaLM 2进行了介绍,本文选取了其中几个方面并结合谷歌IO大会上的一些产品亮点进行简要的总结,可以分为以下四个方面:
(1)多语言能力:PaLM 2相比第一代PaLM增加了更多的非英文语料库进行训练,语料语言种类总数超过了100类,为模型提供了非常强大的多语言翻译、理解、推理和生成能力。
(2)模型整体架构的改进:虽然PaLM 2仍然沿用Transformer架构进行训练,但是相比之前仅通过单一的masked语言建模或因果机制建模,PaLM 2引入了更加丰富的预训练目标任务,以帮助模型在多个角度挖掘语义信息。
(3)模型参数规模改进:PaLM 2相比其前代模型PaLM(参数量规模在5400亿左右),参数规模大幅下降,但是在包括翻译、推理和生成等多种任务上的性能都远超过PaLM。此外,谷歌在PaLM 2的训练过程中进行了详细的模型参数缩放规律,这为行业不断扩展大模型规模和代价权衡方面提供了新的宝贵经验。
(4)基于PaLM 2的专家模型:谷歌宣布,目前已有超过70个谷歌内部产品团队在使用PaLM 2来构建新产品,目前已经介绍的新产品包括医疗专家模型Med-PaLM 2和安全领域专家模型Sec-PaLM。
一、多语言能力
先前的大型预训练语言模型通常使用以英语文本为主的数据集,PaLM 2在此基础上尝试了一种具有多语言特点的混合预训练数据集模式,其预训练语料库由网络文档、书籍、代码、数学和对话数据等多种类型的数据构成。下表展示了PaLM 2所使用数百种语言占比排名前50的语言分布(其中去除了占比最大的英语)。
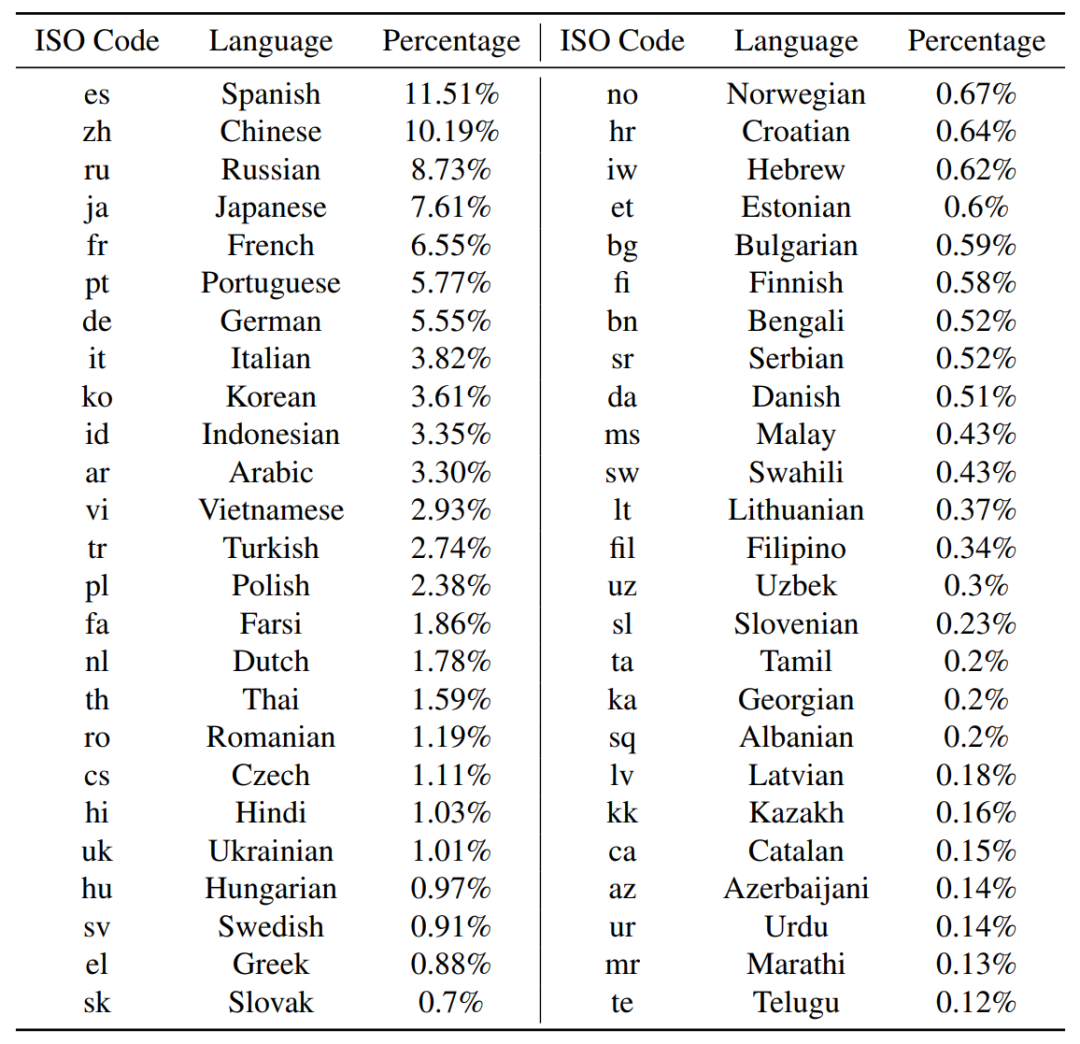
由于该数据集包含有更高比例的非英语数据,这使得PaLM 2在一些多语言任务(例如,翻译和多语言问答)上展现出更优越的性能,同时也不会影响模型在英语语言理解方面的性能。此外我们注意到,除了英语之外,PaLM 2训练使用的西班牙语、汉语和俄语的比例也很高,这有点让人期待谷歌Bard机器人在接入PaLM 2后的中文使用效果。
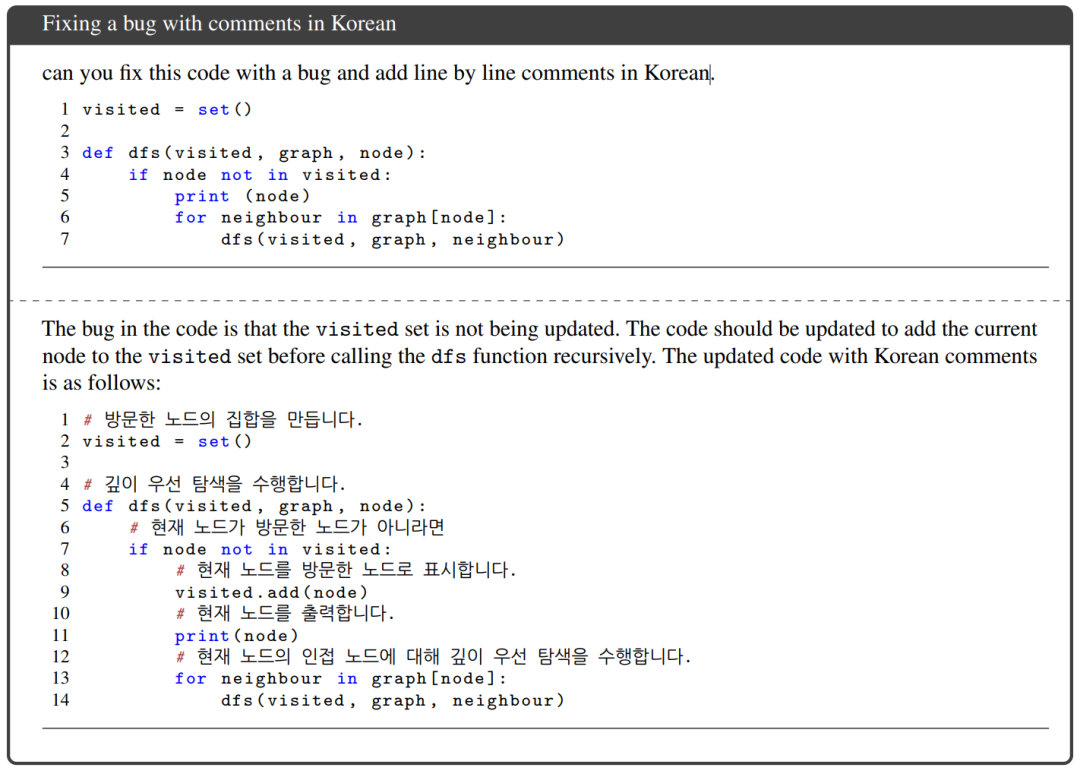
此外PaLM 2的多语言能力并不仅仅局限于简单的语言翻译,它还为我们展现出了大语言模型在跨语言交互和推理方面的强大潜力。例如你可以给定一段代码,让它在解决其中bug的同时为每行代码加上详细的韩语注释。
还可以让PaLM 2通过理解音译文字将所描述的波斯谚语翻译出来。

甚至还能让PaLM 2进一步在汉语中寻找与该谚语意思相近的中文谚语,PaLM 2找的非常准确,甚至还对“不经一番寒彻骨,怎得梅花扑鼻香”进行了解释。

二 、模型参数缩放实验
目前各公司在发布自家的Transformer大模型时,基本上都会进行模型参数缩放(Scaling law experiments)实验,目的是为了研究模型训练数据量(D)和模型大小(N)之间的关系,来帮助研究者总结大模型训练经验。
2020年Kaplan等人发表的论文《Scaling laws for neural language models》[3]首次对这些因素进行了研究,并得出了大模型训练基本遵循幂律的经验结论,即模型大小N要比数据量D的扩展速度更快。在此基础上,Hoffmann等人[4]在2022年提出了不同意见,他们认为一味地增加模型参数规模可能并不是大模型训练的最优解,他们通过调整较小模型的超参数发现,模型大小N和数据量D在相同比例扩展的情况下,模型也同样能够达到最佳性能。谷歌在PaLM 2的实验过程中也证实了Hoffmann等人的结论,实验结果如下图所示。

图中横坐标FLOPs代表算力,纵坐标分别为模型最优参数量(左图)和最优参与训练的token数量(右图)。可以看到,模型参数规模和训练数据随着算力同比例增长时,模型性能最佳。这一结论再次表明,盲目的增加参数规模并不是大模型训练的最优解,将更多的精力放在数据清洗和更高效的架构探索可能是未来提升大模型性能的关键。
三 、性能评估结果
谷歌在技术报告中详细介绍了对PaLM 2进行的多项性能评估结果,评估主要涵盖了6项高级任务,包括分类、问答、推理、编码、翻译和自然语言生成,作者团队强调,这6项任务可以体现LLM的核心能力。同时在这6项性能评估时,作者团队都着重将多语言能力和可靠性AI(评估模型潜在的缺陷和风险)作为评估的共同点。
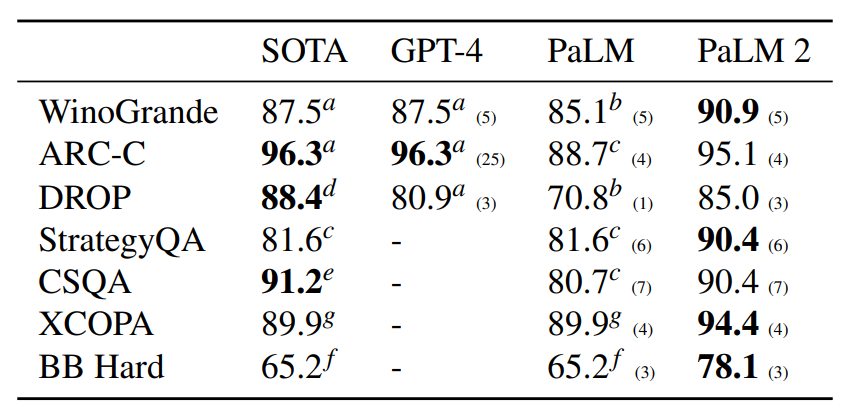
在模型推理能力方面,作者团队主要从两个方面进行评估,首先选取了包括WinoGrande、ARC-C、DROP、StrategyQA、CommonsenseQA、XCOPA和BIG-Bench (BB) Hard在内的多个常识推理数据集,实验结果如下表所示,可以看到PaLM 2在更多的数据集上相比GPT-4具有更准确的推理效果。
另一方面,PaLM 2在数学专业领域的推理能力也相当出色,作者选取了MATH、GSM8K和MGSM作为数学推理评估数据集,其中MATH包含了来自7个数学领域高中竞赛的12,500个问题。实验效果如下,可以看到PaLM 2在MATH数据集上的推理效果同样超过了GPT-4。

此外,作者团队还考虑了PaLM 2在多编程语言生成方面的效果,使用BabelCode来进行评估,它可以将HumanEval代码数据集翻译成各种其他编程语言,包括 C++、Java、Go 等高资源利用语言和Haskell、Julia等低资源利用语言,下图展示了12种语言的生成效果对比。
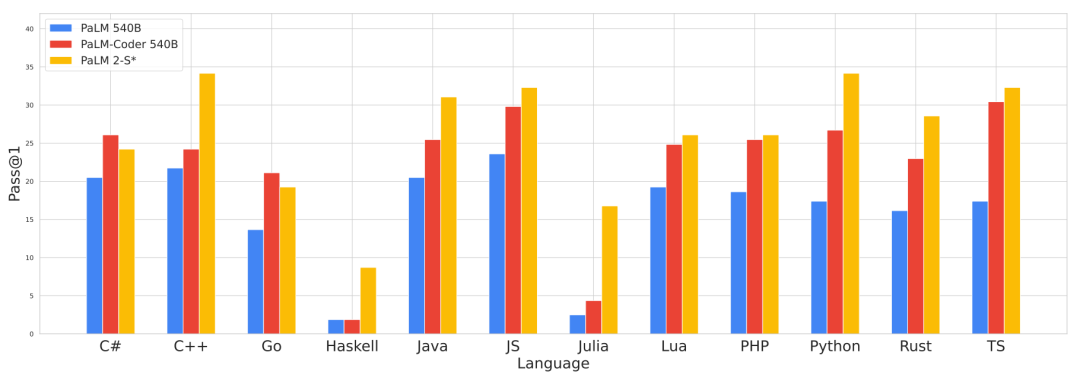
由于PaLM 2训练使用的代码数据集相比前代PaLM的规模更多,因此PaLM 2在这一方面的性能都远超过PaLM。
四、专家模型
随着PaLM 2的发布,我们也可以初探谷歌在大模型业务方面的布局,PaLM 2完全可以作为一个base模型,随后使用众多领域的专家知识进行微调来得到多个不同的专家PaLM 2模型,例如谷歌CEO在IO大会上重点介绍的Med-PaLM 2,就是谷歌在医疗领域进行的尝试。

Med-PaLM 2由谷歌具有医学知识的健康研究团队训练,她可以回答患者的问题并从海量的医学语料中总结出专业的医疗知识,Med-PaLM 2还是目前第一个在美国医疗执照考试上达到“专家”水平的大语言模型。
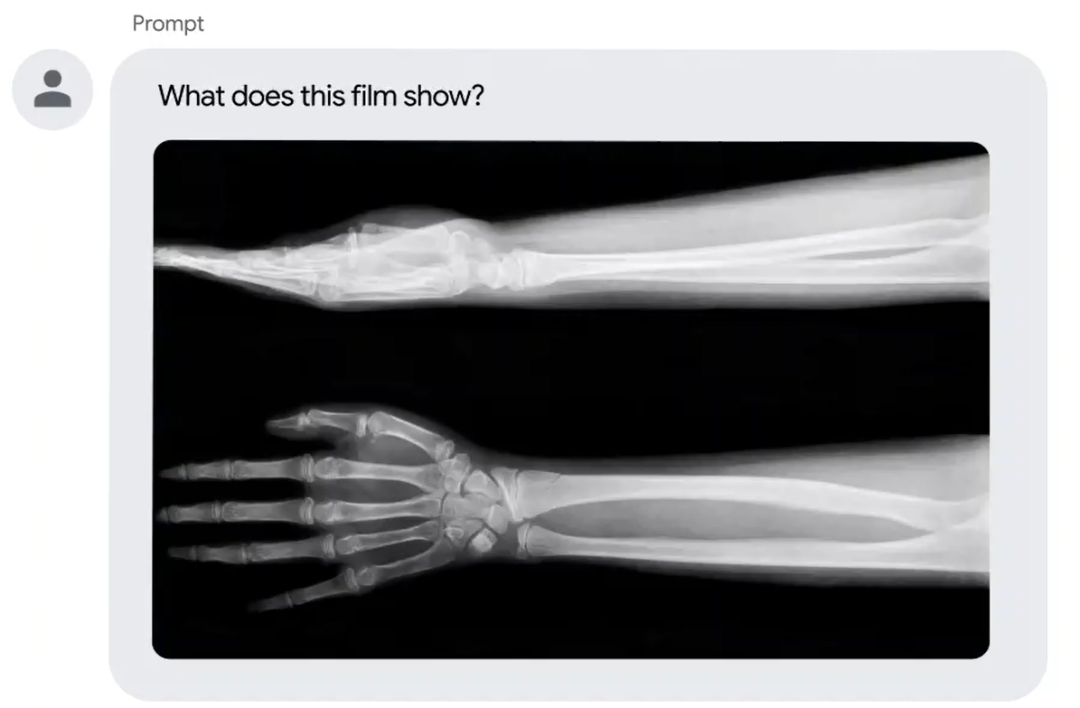
此外,谷歌还考虑在Med-PaLM 2上加入多模态功能(例如输入X光片)以便模型能够整合更多维度的医疗信息,来得到更准确的医学专业回答。
五 、贡献名单
同OpenAI发布GPT-4时一样,谷歌也在技术报告中罗列了PaLM 2的研发团队组织架构和成员名单,研发团队规模相当庞大,成员多达上百位,这里我们只展示了其中的一部分。

整体工程由大模型训练、架构设计、预训练数据收集、模型评估、可靠性AI、微调、优化、部署等多个团队参与。
六 、总结
作为谷歌的下一代大型语言模型,PaLM 2的发布备受关注,本文从PaLM 2的几个创新方面进行了简单的总结,PaLM 2相比前代模型在高级推理任务上面有了显著的进步,尤其是在代码生成、数学推理以及多语言能力方面。此外谷歌也对大模型训练缩放方面进行了研究,证明了通过对模型数据集配置和架构选择等方面进行改进,完全可以在一定的参数规模内提升大模型的性能。PaLM 2的入场,使得最近的大模型竞争更加激烈和精彩,作为大模型技术的见证者和参与者,我们期待着更多更好的大模型早日到来。
参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Go ez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[2] Shannon, C. E. Prediction and entropy of printed english. Bell System Technical Journal, 30(1):50–64, 1951. doi: https://doi.org/10.1002/j.1538-7305.1951.tb01366.x.
[3] Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
[4] Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., et al. Training compute-optimal large language models. NeurIPS, 2022.
作者:seven_
Illustration by IconScout Store from IconScout
点击阅读原文