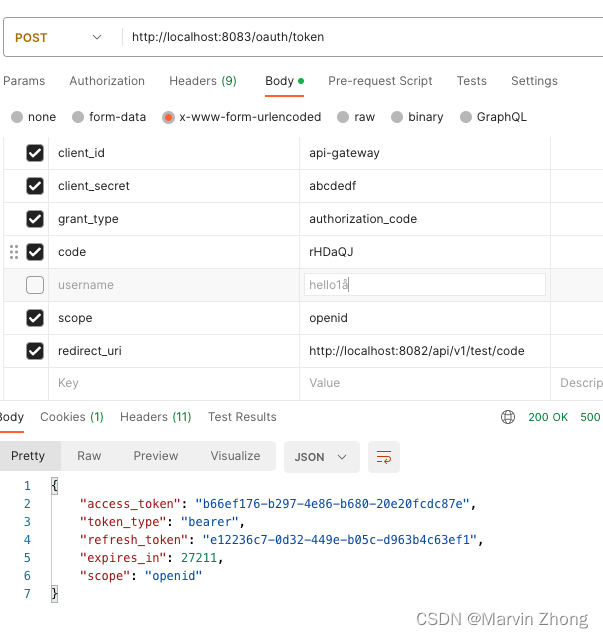
作者 | 张曦
一、openfaas产品背景
在云服务架构发展之初,这个方向上的思路是使开发者不需要关心搭建和管理后端应用程序。这里并没有提及无服务器这个概念,而是指后端基础设施由第三方来托管,需要的基础架构组建均以服务的形式提供,比如数据库、消息队列和认证服务等。
但亚马逊在2014年发布AWS Lambda时,为在云中运行的应用程序带来了一个新的系统架构思路,即不需要在服务器上部署等待HTTP请求或API调用的进程。Lambda提供了一个事件触发的机制及框架,当收到用户请求时触发一个事件,在一个AWS server上执行用户注册的功能(通常只是一个函数,业界一般称这种类型的服务为FaaS)。
当前,提供FaaS服务的云服务厂商除AWS外,还有Google Cloud(alpha)、Microsoft Azuze、IBM OpenWhisk等。国内的云服务提供商如阿里云 FC、百度云CFC、腾讯云SCF。比较受欢迎的开源架构有OpenFaaS、Knative、OpenWhisk等。
二、项目业务背景
阿拉丁是百度搜索平台的产品,一般位于百度搜索结果页的首位,是百度搜索满足用户搜索需求闭环的卡片式产品。离线任务提供高质量的结构化数据,在线server优化搜索出卡策略,从而将高品质的搜索结果呈现给用户,最大程度的满足用户的搜索体验以及需求。在线server部署在百度搜索业务线的机器上,由百度搜索业务线统一管理分配资源和保证业务稳定性。离线任务需业务方自行管理。
离线数据源的产出分为两种方案,定时读取数据库进行版本diff后,拼接结构化数据发送至搜索业务线的消息队列节点,或者pm提交物料数据触发建库任务生成全量静态数据,等待搜索spider定时抓取建库,同时,离线方案也提供在线入口用于实时干预数据、物料管理等功能。原方案是将所有脚本部署在业务方物理机上,定时任务由百度内部noah平台托管,支持配置运行时间间隔、运行指令,然后定时触发指令运行。对于手动触发类任务,在同一台物理机上部署了http server,通过接收http请求,然后到脚本目录下执行cmd指令实现,这种方式造成了机器资源的浪费。原上线方案还存在另一个问题,通过将发布包拷贝到物理机部署的方式,较为繁琐,而且没有上线记录,当出现问题不利于尽快回滚止损。
三、思路与目标
从业务上来看,需要有两个功能点,定时运行脚本,还能支持传入文件流并触发脚本运行。为了节省机器预算成本,使用百度智能云bcc虚机,为了保证脚本运行的稳定性,避免机器故障导致脚本全部无法运行的情况发生,容器化部署脚本,基于faas的思路,把脚本任务放入函数中封装为一个云函数,支持定时任务、http请求触发脚本运行。
考虑到百度智能云bcc虚机上可以部署cce Kubernetes集群,调研基于Kubernetes的Faas开源项目用于二次开发。目前主流Faas开源架构有OpenFaaS,Knative,OpenWhisk等,这三个框架的对比如下:

对比后发现Knative更适合定位于创建、部署和管理无服务器工作负载的平台,需要独立管理容器基础设施,从配置和维护的角度来看,比较复杂且不是面对最终用户,所以暂时先不考虑。OpenFaaS和OpenWhisk对比,OpenWhisk利用的底层组件多于OpenFaas,从运维和部署OpenWhisk来看增加了一定的复杂性,且OpenWhisk基于scale实现,如果需要二次开发,需重新入手一门新语言。而openfaas主要利用了promethus、alertmanager用于动态扩缩容,技术栈为与我们日常开发语言一致,所以最终方案选择了openfaas。
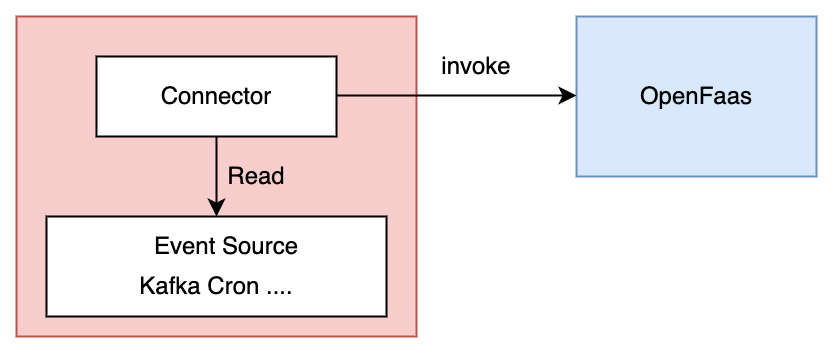
而且openfaas还支持event connectors的调用方式,调用方式如下图所示,和AWS Lambda的功能类似,方便与其他生态系统集成。目前官方已支持了Cron connector、MQTT connector、NATS connector等连接器,我们定时任务就依赖于Cron connector实现。在使用上先在集群中部署对应的connector,然后在打包云函数用的yaml中annotations属性上,加上connector指定要加的内容即可根据时间触发对应的云函数。
四、整体架构
4.1 架构设计
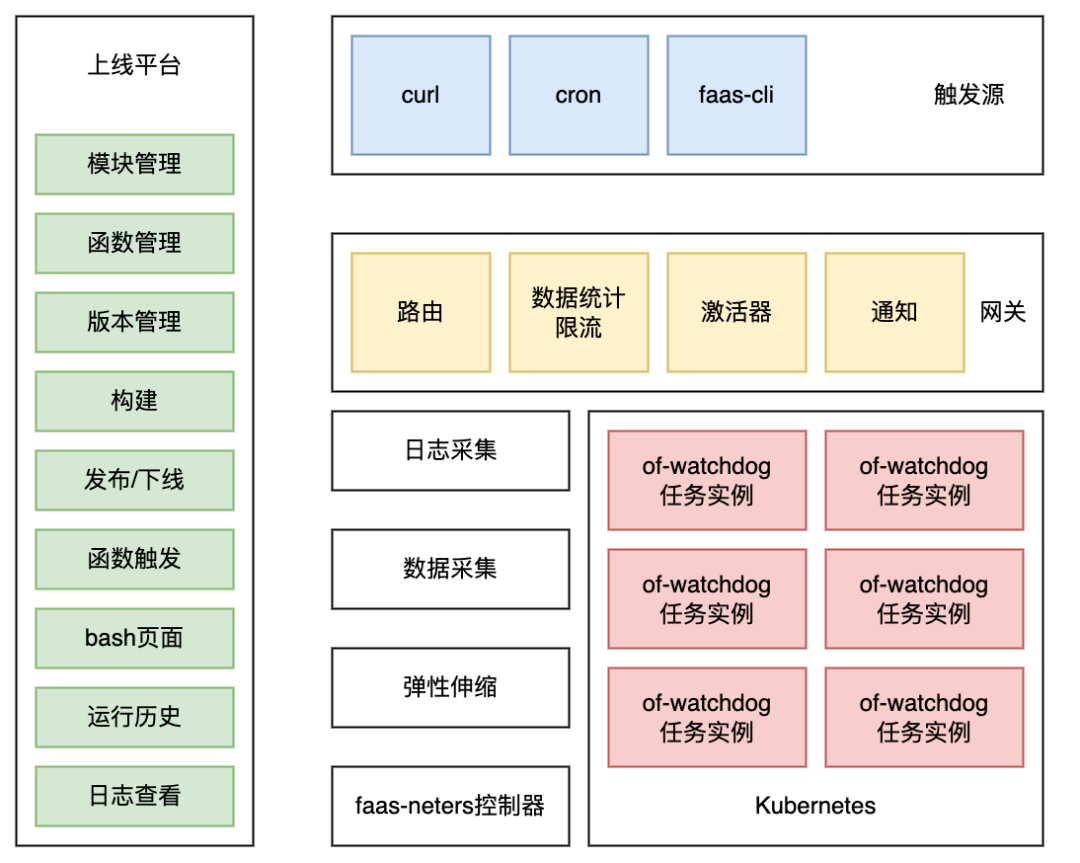
在整体的架构上,任务由事件(http请求、定时器、faas客户端操作)触发,openfaas平台内会根据流量的特征路由到具体任务实例,触发任务执行,任务执行原理是of-watchdog将请求参数封装为stdin去执行cmd指令触发任务运行,等待任务执行完成从stdout中取到数据返回结果。
整体架构主要由以下几个核心部分组成:
网关:核心能力是负责对接外部触发源,将流量路由到具体任务实例上去执行;网关还负责统计各个任务的流量信息,为弹性伸缩模块提供数据支撑,同时也可以根据配置的任务并发度进行限流处理;网关也会同步任务运行状态、运行历史等信息,在任务执行失败后,通知到任务负责人。
弹性伸缩:核心能力是负责任务实例的弹性伸缩,根据任务运行的流量数据、资源阈值配置计算函数目标实例个数,协调资源,然后借助Kubernetes的资源控制能力,调整函数实例的个数。
数据采集:采集网关对外暴露的流量数据,以及任务实例的资源使用量,作为弹性伸缩的判断依据。
日志采集:采集任务实例中的日志并落盘,方便业务方排查任务运行中出现的问题。
控制器:核心能力是负责Kubernetes CRD(Custom Resource Definition)的控制逻辑实现。
任务实例:当网关流量路由过来,会在任务实例内执行相应的脚本代码逻辑。
上线平台:面向用户使用的平台,负责函数的构建、版本、发布以及一些函数元信息的管理,同时支持查看函数运行时日志和执行历史。
4.2 流程设计
脚本整体生命周期如图中所示,有以下四个阶段:发布版本、构建、部署、伸缩。
发布版本:发布待上线版本,指定待打包脚本代码目录。
构建:将代码还有配置的定时任务等相关信息,一起打包生成镜像,用于后续的部署工作。
部署:将镜像部署到Kubernetes集群中。
伸缩:根据集群中任务实例的流量以及负载等信息,来进行实例的弹性扩缩容。
五、机器资源利用率提升
提升机器资源利用率,通过动态的为任务实例分配资源去实现。当离线任务处于不工作的状态下,可以把对应的实例数缩减为0分配给其他有需要的实例,对流量超过并发度配置或者资源使用超过阈值限制的任务实例进行扩实例操作,使用尽可能少的机器去承载更多的脚本离线服务。
在离线任务上线前,会对任务进行注册,选择任务分类,任务可分为同步触发(需等待返回结果)、定时触发、异步调用(不等待脚本结果直接返回)这三种类型。
5.1 同步触发型任务
同步触发型任务主要是用于实时干预线上数据,或操作物料数据入库,它的特点需等待返回结果确保操作成功,且可能会有连续多次操作。在上面三种类型任务中,这种类型的任务优先级是最高的,不会将其缩减到0实例。
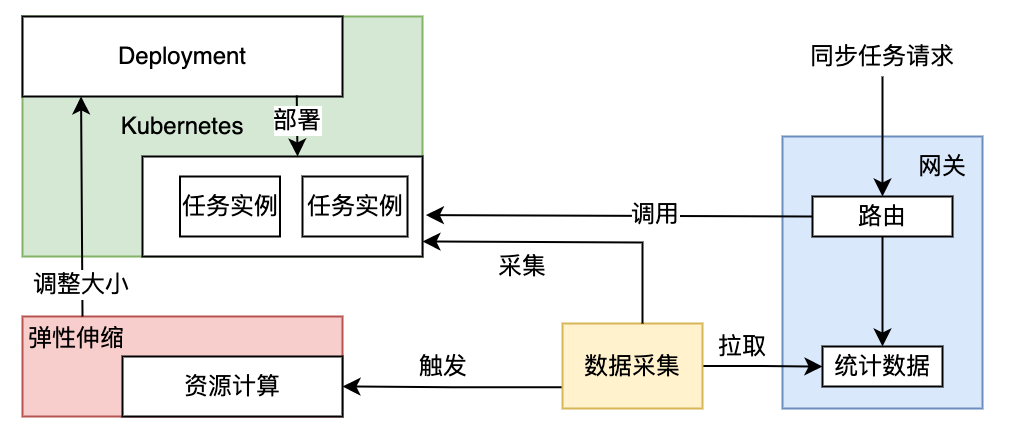
同步任务弹性伸缩流程如上图所示,在任务监控过程中,通过拉取网关数据获取流量任务情况,pod资源则是promethus配置cadvisor数据源获取,如果发现网关收到大量429状态码(流量超过并发度配置),或者发现资源使用超过报警阈值(阈值设置为上线平台配置的资源最大值的80%),会对这些任务实例进行扩容。在扩容过程中如果发现机器资源不够,会按照定时任务、异步调用任务的先后顺序去找未运行的任务缩减实例数,在缩减定时任务时会根据最近一次任务执行时间,由远及近的将任务实例缩减至0节约资源。反之,对同步触发类型的任务资源使用率很低的情况,根据并发度配置去适当的缩减资源。
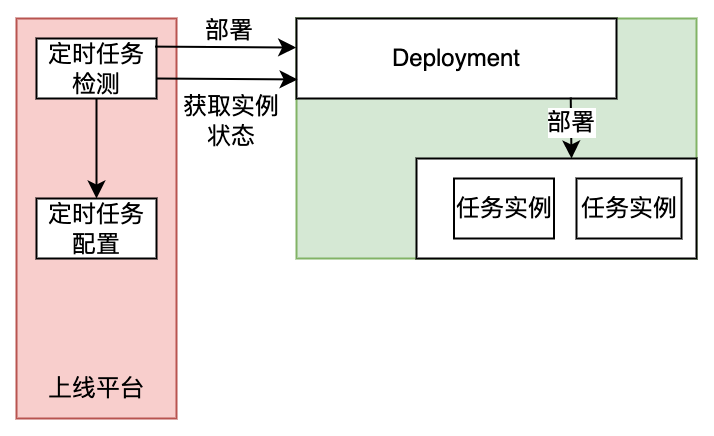
5.2 定时任务
定时任务主要应用于全量建库场景,在指定的时间开始运行,属于可预期的任务类型,极端情况下任务实例只需要在指定时间存在即可。
定时任务的触发基于cron-connector,但是在规定时间保证对应的任务实例存在则由后台任务负责,定时运行查看未来的一段时间内对应任务的实例是否存在,如果不存在的话执行部署操作,同时注册回调查看任务实例部署状态,因为机器资源不足等原因导致实例数没有达到预期数,触发报警通知到系统运维人员。
5.3 异步调用任务
异步任务主要应用于运行时间较长、不需要及时获取返回结果的情况,这类任务对生效时间不敏感,完全可以延迟一分钟用于部署实例再触发任务执行,但由于异步任务由人工触发,不可预测触发时间,所以在弹性伸缩需要缩容时还是会优先考虑定时任务。
异步调用任务,如果实例被缩减到0后,触发任务执行,网关内的激活器模块会先将请求信息存储,然后通过暴露metrics信息,触发流量大于总并发度(实例数*配置并发度)的报警,实现重新部署。网关进行轮训等待实例部署成功后将请求回放重试,如果规定时间内实例数仍为0,报警通知到系统运维人员。
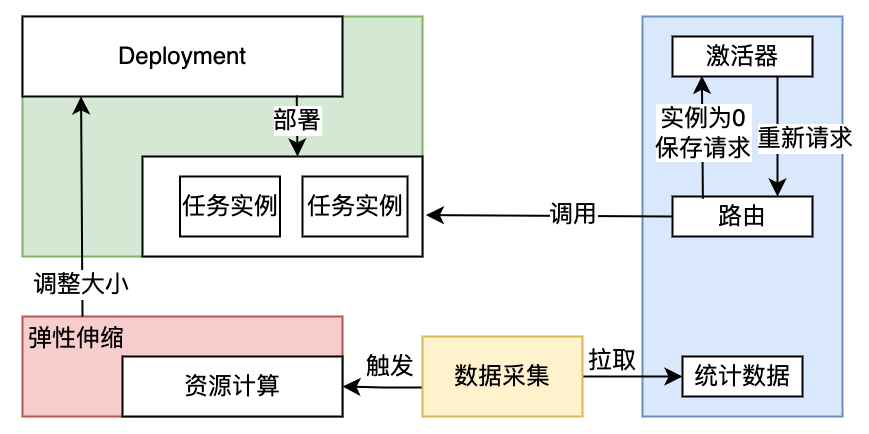
六、稳定性保障
6.1 网关稳定性保障
所有的函数流量都需要经过网关服务,因此事件网关的可用性尤为重要。首先对网关做了主备处理,当主节点出问题时立刻启用备节点。通过为了减轻网关的压力,通过限流和异步化两个手段,尽可能减小网关请求下游的资源消耗。网关也能很好的保护下游业务实例,支持在上线平台配置任务实例降级,直接返回降级数据,也支持干预限制异常的流量访问,保证下游任务实例的正常运行。
6.2 资源监控、报警
基于promethus对所有的任务实例进行了监控,遇到实例重启、资源超过阈值等情况通过alertmanager发消息通知到系统运维工作人员。当任务运行失败也会发消息到任务负责人。同时将promethus数据输出给grafana,支持可视化查看实例资源情况,也支持在上线平台查看任务运行历史、运行时长等基本信息。
6.3 日志采集、留存
由于任务实例受弹性伸缩影响,可能会被重新部署,这将导致旧实例的日志会无法被找回,在任务实例中部署filebeat将日志文件导出,实现日志文件的持久化,同时支持在上线平台查看历史日志。在上线平台也可以登录到任务实例中查看实时日志排查问题,通过上线平台实现用户权限管理,限制用户只能登录有权限的任务实例,做到任务实例管理隔离。
6.4 bns服务稳定性保障
bns百度命名服务,可以理解为百度内部的dns服务,实现原理是在解析bns地址时,请求百度机器上的bns-agent获取注册的服务地址。考虑到节约资源使用,在我们的任务实例中是没有部署bns-agent的,所以一般会请求远程的bns-agent服务,但后来发现会偶现连接超时问题,影响了任务的稳定性。因此考虑了三种方案:
方案1,任务实例中挂载bns服务,然后在实例启动命令中拉起bns服务;
方案2,参考dns原理,制定bns域规则,在coredns遇到bns域的域名时,转发给宿主机的agent服务,agent服务需要将bns-agent封装一层,能解析dns请求,转换为bns请求,从bns-agent获取机器ip,封装回dns协议格式回包;
方案3,基于百度内部go服务架构,支持注入bns-host环境变量,指定本地bns服务地址。可以利用这种方式将本地服务地址指向宿主机的bns-agent服务,遇到bns请求时转给宿主机agent服务解析。
最终选择了方案3,对比其他两个方案,方案1稳定性较差,方案2工作量较为复杂。通过修改faas-neters源代码,向Kubernetes中写入env环境变量实现,解决了bns解析不稳定的问题。
七、项目总结
通过上线平台管理脚本任务,上线流程更加规范,同时记录了每次上线机器,能更快的定位是否是上线引入的问题,方便快速回滚。各个脚本任务都是隔离的状态,避免因为修改了公共方法导致大量脚本无法使用的情况发生,并且一个实例中的日志都由该任务产出,查看日志更具有针对性。
最终搭建上线平台和运行脚本使用的机器资源为原物理机cpu资源的14%、内存资源的8%,大大节省了机器资源。如果还想进一步节省资源,可以将不需要同时启动且低频运行的定时类任务部署在同个实例中,共用机器资源的同时,节约了频繁弹性伸缩带来的性能损耗。
---------- END ----------
推荐阅读【技术加油站】系列:
百度工程师移动开发避坑指南——Swift语言篇
百度工程师移动开发避坑指南——内存泄漏篇
百度工程师教你玩转设计模式(装饰器模式)
揭秘百度智能测试在测试定位领域实践
百度工程师教你玩转设计模式(适配器模式)
揭秘百度智能测试在测试评估领域实践