前言
在本系列的第一期我们介绍了图片 AVIF 压缩,作为最前沿的压缩技术,AVIF 确实有着无数的优点。但时代的进步是循序渐进的,在一些较老的终端或设备上,可能短时间内确实无法支持 AVIF 格式,那如何能让这部分业务享受到时代的红利?
对此,数据万象推出了基于最通用的jpg、png、gif等图片格式的压缩能力——图片极智压缩,可以在不改变图片格式的情况下,大幅减小图片大小,并保证图片视觉上的无损查看。
图片压缩与主观视觉
最早期的时候,最先出现的图片压缩算法是无损压缩算法,这些无损压缩算法使用lz77系列的算法来对图像数据做压缩,因此压缩性能有限。
后来有心理视觉研究表示,人眼对图像的主观视觉存在大量的冗余,如果对图片中的一些数据进行改变,但控制信息损失的程度,可以使得人眼对图像的观感几乎不变,因此出现了有损压缩算法。
有损压缩算法,能在人眼主观视觉无损或者损失受控的前提下大幅压缩图片文件体积,主要是利用人眼对不同频率信号的敏感程度差异,通过损失高频信息来减少图片信息量,从而能将图片文件体积压缩到更小。
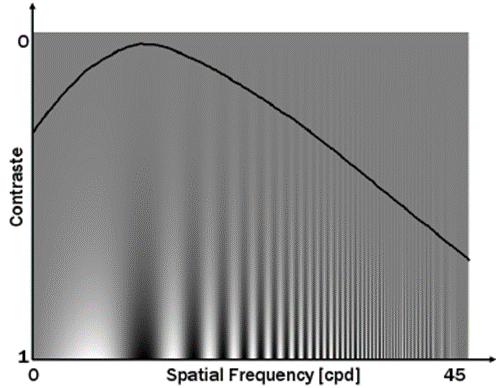
图1. 根据心理视觉研究得到的 CSF 函数坐标图:横轴表示空间频率,纵轴表示敏感度
可见,高频信息频率越高人眼的敏感程度越低。
以有损压缩中的关键步骤 DCT 变换 + 量化为例,将图片按 8x8 做切分并做 DCT 变换,保留不同长度的 DCT 系数再做还原的视觉效果如下:

图2. 最左侧为原图,8x8 的分块做 DCT 变换后共有64个频率系数表示从低频到高频的信息,中间和右图分别为保留低频部分10个系数和1个系数的效果
可见在只保留一个系数的情况下每个 8x8 的分块退化成了纯色块,而在保留10个系数的情况下图像和原图相当接近,可见在损失了大部分高频信息的情况下,图像的主体内容并没有受到大的影响。
人眼对色彩信息的感受存在很多冗余,例如人眼对叠加在黑色背景上的蓝色信号和叠加在黄色背景上面的蓝色信号(黄色+蓝色=白色)敏感度不同,如下图所示:

图3. 左右两边的形状,亮度值完全一致
可以看到,上面右边图的第三行字“你好!”几乎不可见,但对于图像编码中的计算而言两边是一致的,这些不被注意到的信息也会被编码到图像当中,占用文件的体积。因此可以通过滤除非敏感的信息来减少待编码的信息量,达到减小图片文件体积的目的。
图片压缩技术的出发点是降低主观视觉冗余和降低数据冗余,目前的压缩方式基本都会改变图片编码的方式,从而改变图片的格式,通过降低更多的数据冗余来提升压缩能力。
但是在一些较老的终端或设备上,可能短时间内无法支持前沿的图片格式,如何在不改版图片格式的前提下,通过降低主观视觉冗余,实现一定的图片体积节省,正是极智压缩的研究方向。
图片的主观质量
在图像的有损编码中,质量参数控制的其实是图像信息的损失程度,但不同内容的图片在按相同的方式损失信息后的主观质量不同。
正常的编码算法依照质量参数的大小总是优先损失高频信息,而按照 CSF 函数人眼对高低频信息的敏感度并非是完全单调的,因此相同的质量参数无法保证一致的主观质量。

图4. 左右两张图片使用同样的 jpeg 编码质量,但内容简单的图像(右)主观质量更高
通常来说质量参数越高损失程度相对越小,因此为了保证不出现低主观质量的图片,需要对所有图片设置较高的编码质量参数,从而使得大量图片高于目标主观质量,导致图片文件大小产生了冗余。若能根据图片内容自适应编码质量参数,将能保证一致的主观质量的同时,控制图片文件的大小。
因此,通过前处理技术滤除人眼相对不敏感的信息,以及对不同内容图像自适应编码参数,可以有效地减小图片文件的体积。
极智压缩技术原理
1、设计主观质量评价模型
极智压缩的开发需要依赖主观质量数据集,我们认为当前的公开数据集在数据规模和标注质量上均有较多改进空间,因此自建了大规模、高质量的主观质量数据集。总共采集100万条公开图像数据,并在色彩、纹理复杂度等客观维度上对数据做均衡,使多个客观维度上的数据分布尽量平坦,筛选后形成20万条待标注数据。在人工标注环节,通过控制标注硬件环境、让标注人员在标注前学习样例、连续标注一定量后强制休息来保证标注质量。并且在待标注数据中埋入测试数据桩,再对标注后的数据进行清洗,剔除掉异常的标注数据。最终形成超过500万人次标注记录的高质量人工标注数据集。
由于人眼主观视觉的复杂性,传统的单一维度质量指标难以与人工标注值相吻合。因此当前业界的方向是综合多个维度的指标来对人工标注值做拟合,或者直接使用深度学习的方法。深度学习方法理论上能拟合复杂的函数,适合用来模拟人眼对图像质量做打分。我们基于图像的分类模型,改进了数据预处理流程、视觉注意力机制和模型训练策略等,反复迭代后形成了主观质量评价模型。
为了考察自研模型的先进性,我们使用自研模型的网络在 KonIQ-10K 和 SPAQ 公开数据集上分别做训练并与多个公开方法做了比较,从结果来看自研模型的表现超越了公开的 SOTA 模型。

图5. 自研模型在 KonIQ-10K 和 SPAQ 公开数据集上的结果
在自建的人工标注主观质量数据集上训练后达到了0.939的PLCC。使用该模型制作主观质量评价工具来驱动极智压缩算法的设计开发,保证了极智压缩的效果。
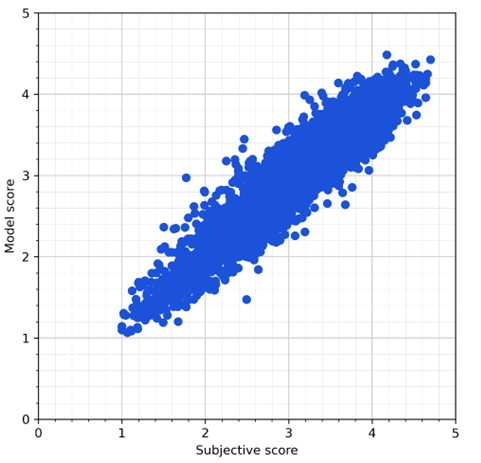
图6. PLCC 0.939
2、 去噪、色彩量化等前处理技术
通过前处理技术滤除人眼主观不敏感的高、低频信息以及相对冗余的色彩信息,使得同样的编码质量参数下输出的图像体积减小,并且保持主观质量基本不变。即使对PNG/GIF这样的无损编码格式也能使用处理技术减少信息量,来降低图片文件体积。
例如 JPEG 等有损压缩格式,噪点水平会对文件大小造成很大影响,大多数时候噪点是图像中的干扰因素,并且人眼对噪点不敏感,因此可以对图像做适当的去噪处理,可以降低编码后的文件大小;而对于 GIF/PNG 这样的无损压缩格式,色彩数量对文件大小会造成很大影响,如果去除一些人眼相对不敏感的色彩则能大幅降低编码后的文件大小。
通过对处理前后的图像使用主观质量工具进行评分,控制评分的差异可以避免处理算法过度损伤主观质量。
如下所示,原图和处理后的图像相比,虽然色彩的数量大幅下降了99%,但在观感以及主观质量工具的评分上是非常接近的。

图7. 原图(左)包含46752种色彩,质量工具评分为6.17;处理后的图(右)只有256种色彩,质量工具评分为6.0
3、根据输入图像的主观质量智能选择编码参数
在有可靠的主观质量评分工具的情况下,可以使用搜索的方式,即先使用默认的编码参数做编码,再根据主观质量工具评分来调整编码参数,重复这个过程最终找到与预期质量对应的编码参数,但这样会做多次编码和评分,消耗大量的算力并且时延较大。所以最合理的方式是使用预测的方式,根据输入的图像直接得到合适的编码参数。这里我们设计算法分析输入图像的画面复杂度、编码损伤程度以及对图像做前面提到的主观质量评分,使用这些特征,通过深度网络学习到内容特征与合适编码参数间的关系,从而做到图像编码参数的智能选择。使用预测的参数编码图像的主观质量工具评分与预期分数的差异小于0.5的概率超过了95%。
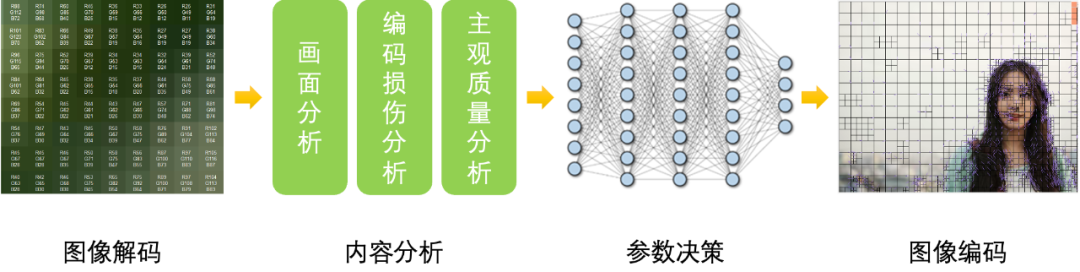
图8. 编码参数自适应流程
极智压缩图片效果对比

图9. jpg 原图(上)2.3MB;jpg 极智压缩图(下)1.2MB

图10. png 原图(左)1.4MB;png 极智压缩图(右)0.6MB
从上面的示例图可以看到,在经过压缩后,图片原有尺寸均不变的情况下,压缩后图片几乎可以跟原图无缝衔接,在体积均减小了约50%,压缩效果非常显著。
数据万象图片极智压缩的使用方法
图片极智压缩与 COS 进行了深度的集成,可在服务开启后,直接访问原图链接,不加任务处理参数即可获取到压缩后图片。
使用前提条件
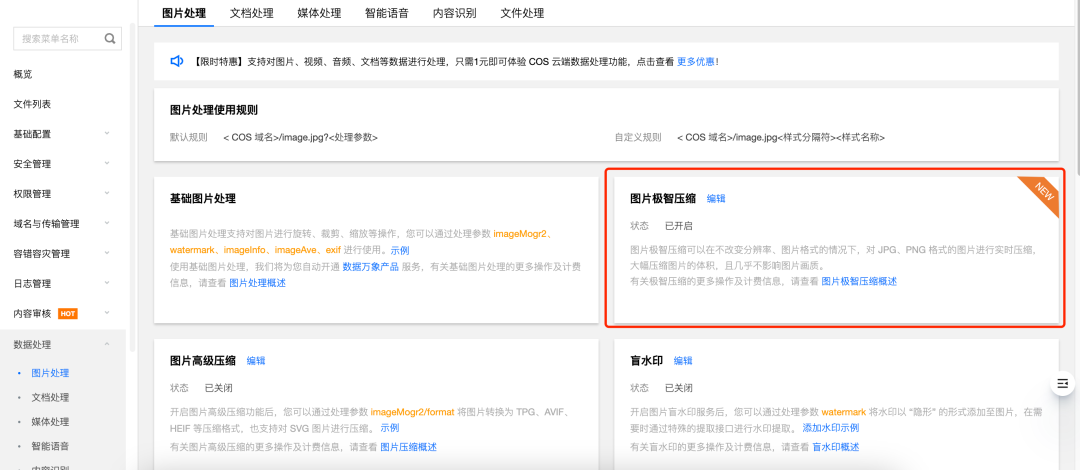
需要先开通数据万象图片极智压缩功能,您需要在已绑定数据万象服务的存储桶中,开启图片极智压缩功能。
注意事项:当前极智压缩仅支持在上海和北京地域的存储桶开通使用。
操作指引
1. 登录对象存储控制台,选择指定存储桶(北京或上海地域的),然后选择界面左边红框内“数据处理”,再选择“图片处理”,找到图片极智压缩,然后点击编辑,开通后保存即可。
2. 选择该存储桶的一张图片,复制图片链接,比如:https://XXXXXXX-1250000000.cos.ap-shanghai.myqcloud.com/test.png
3. 直接访问图片链接,即可获取压缩后的图片。
展望与总结
与先进的 AVIF 压缩相比,极智压缩解决了图片在较老终端访问的兼容性问题,除了提高图片传播下载的效率,还可以在保证极高压缩性能的基础上保留更多的图像细节,大大提升用户体验。
后续我们将进一步改进图像处理算法,挖掘更多视觉冗余,同时结合视觉 ROI 特性,通过适当抹除低关注区域的信息在同等主观质量下,使图片体积变得更小。
赶快来使用腾讯云吧,将图片存储在腾讯云 COS,通过数据万象将业务图片进行无感知的压缩!