目录
Slot Filling with RNN
Elman Network & Jordan Network
Bidirectional RNN
LSTM(Long Short-term Memory)
Example
Learning Target
LSTM
GRU (Gated Recurrent Unit)
More Applications
Many to One
Many to Many
Speech Recognition
Sequence to Sequence Learning
Seq2Seq for Syntatic Parsing
Seq2Seq for Auto-encoder Text
Seq2Seq for Auto-encoder Speech
Attention-based Model
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。
循环神经网络具有记忆性、参数共享并且图灵完备(Turing completeness),因此在对序列的非线性特征进行学习时具有一定优势。
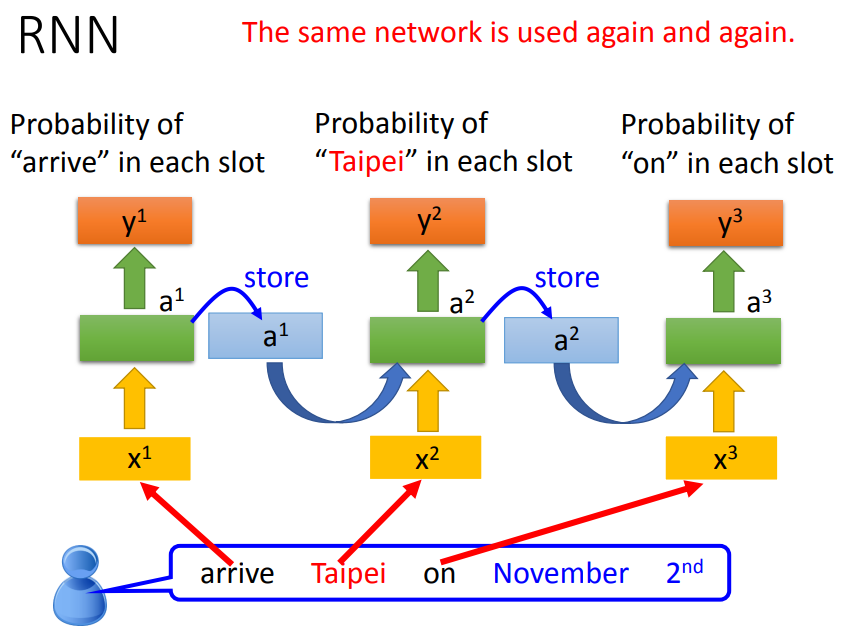
Slot Filling with RNN
第一次输入时,通过隐藏层输出,同时输入会被存放在memory中;当第二次输入时,会经过隐藏层和memory运算后输出,同时memory和输入进行运算并更新memory中的值,以此类推。


即使输入是相同的地点,可以根据前文的“leave”或“arrive”得到不一样的输出。
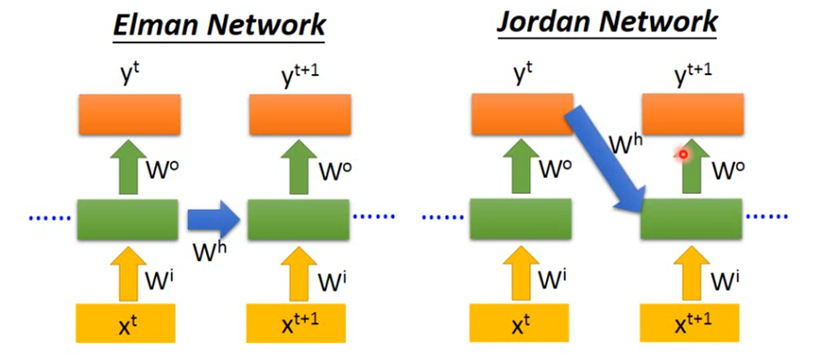
Elman Network & Jordan Network
Elman Network:将hidden layer的输出保存在memory里。
Jordan Network:将整个neural network的输出保存在memory里。
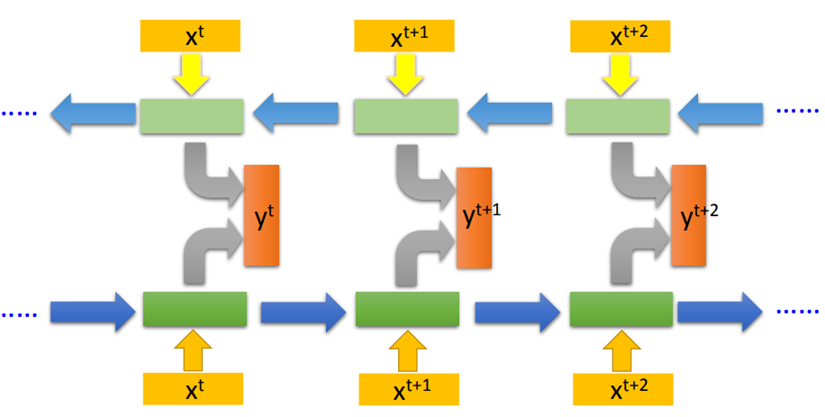
Bidirectional RNN
RNN 还可以是双向的,可以同时训练一对正向和反向的RNN,把它们对应的hidden layer 拿出来,都接给一个output layer。使用双向RNN的好处是,在产生输出的时候,它能够看到比较广的范围。
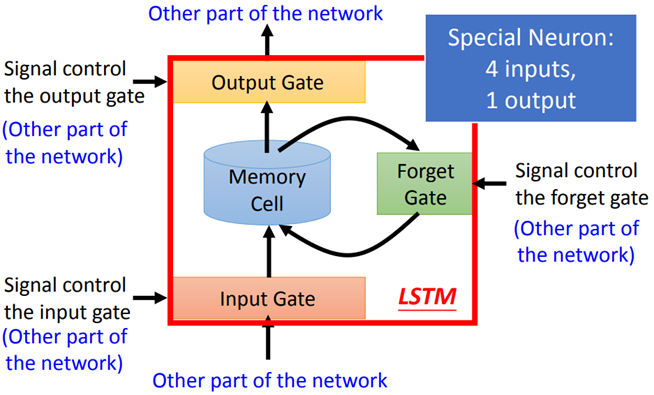
LSTM(Long Short-term Memory)
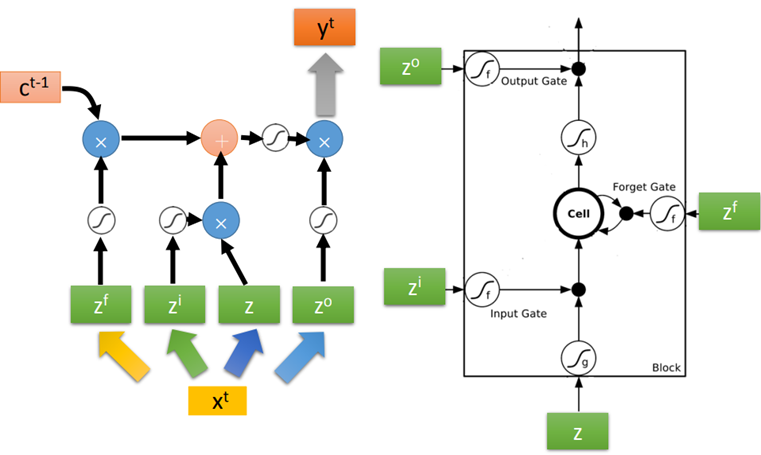
LSTM有三个gate:input gate、output gate和forget gate。整个LSTM可以看做是4个input,1个output:
Input: 想要被存到memory cell里的值以及三个gate的控制信号。
Output:想要从memory cell中被读取的值。

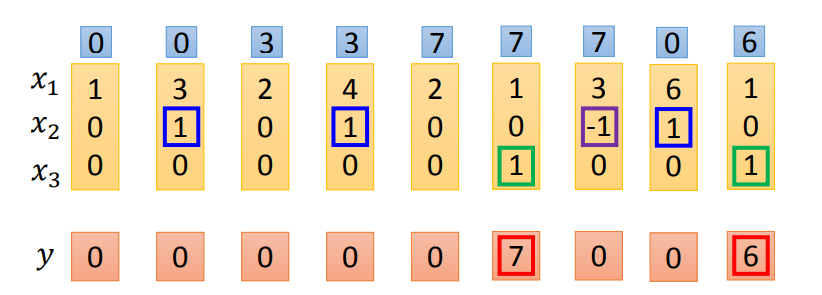
Example
当x2=1,把x1的值写入memory;当x2=-1,将memory的数值清零;当x3=1,将memory的值输出。
下图是单个LSTM的运算情景
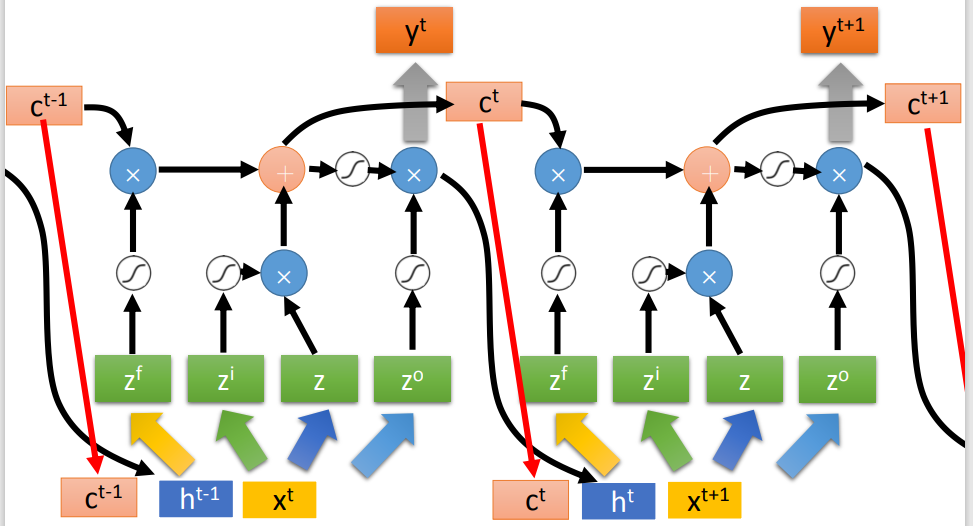
下图是同一个LSTM在两个相邻时间点上的情况
Learning Target
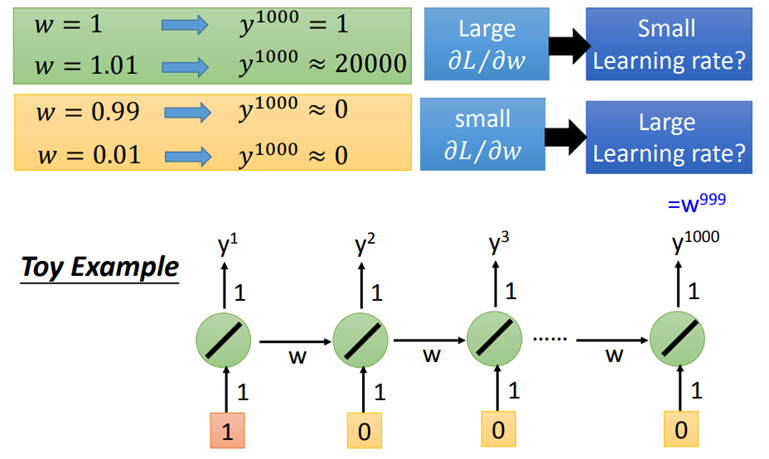
RNN的损失函数就是输出yi与对label之间的交叉熵,对于RNN的训练也是采用梯度下降的方法,为了计算方便,采取了Backpropagation through time,简称BPTT算法。但是,RNN训练并不容易。因为RNN的Error Surface在某些地方非常平坦,在某些地方又非常的陡峭。这就会导致loss有时会剧烈变化。想要解决这个问题,可以采用Clipping方法,当gradient即将大于某个threshold的时候,就让它停止增长。
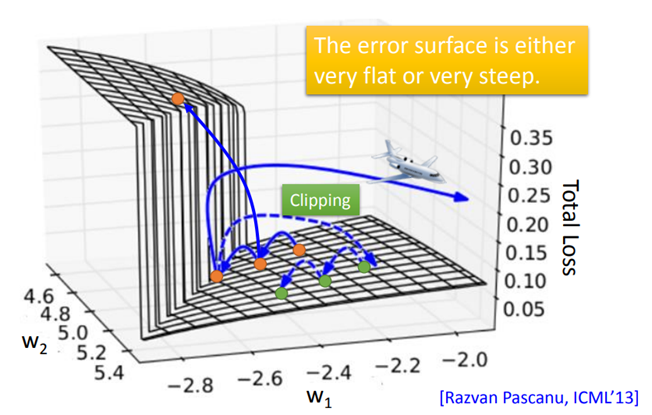
从下图可知,RNN的Error Surface中的“悬崖”出现的原因是,关于memory的参数w的作用随着时间增加不断增强,导致RNN出现梯度消失或梯度爆炸的问题。
LSTM
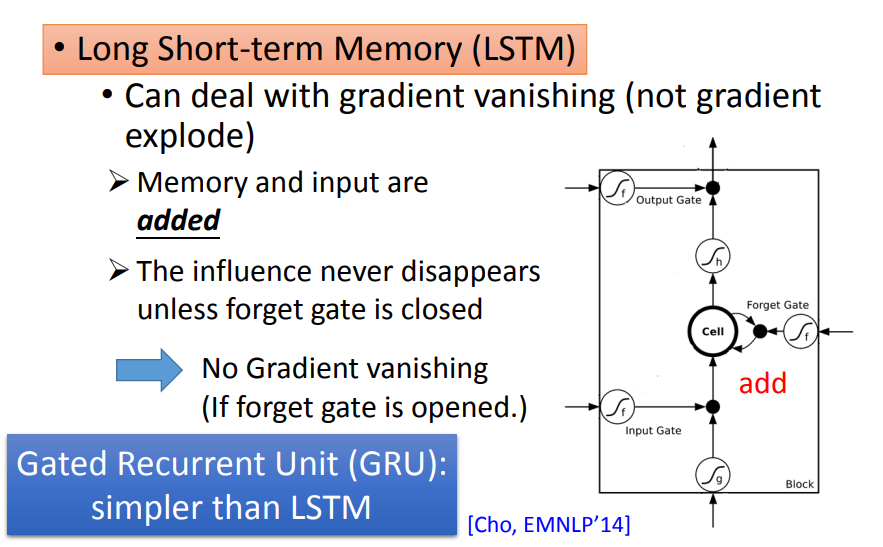
LSTM会删除error surface上那些比较平坦的地方,从而解决梯度消失的问题,但它无法处理那些崎岖的部分,因而也就无法解决梯度爆炸的问题,所以,训练LSTM时需要将学习率调得特别小。
在RNN中,每个时间点memory中的旧值都会被新值覆盖,导致w对memory的影响每次都被清除,进而引发梯度消失。
在LSTM中,每个时间点memory里的旧值都会通过激活函数与新值相加,只有在forget gate被关闭时w对memory的影响才会被清除。
GRU (Gated Recurrent Unit)
GRU最大的优势就是简单(只有两个门),计算开销小,更加适用于大规模数据集。GRU会把input gate和forget gate连起来,当forget gate把memory里的值清空时,input gate才会打开,再放入新的值。
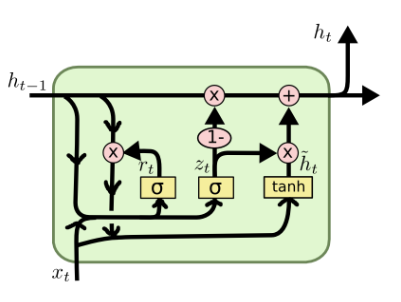
其中 rt表示重置门(reset gate),zt表示更新门(update gate)。
此外,还有很多技术可以用来处理梯度消失的问题,比如Clockwise RNN、SCRN等
More Applications
Many to One
输入是1个vector sequence,输出是1个vector。
- Sentiment Analysis:我们可以把某影片相关的文章爬下来,并分析其正面情绪or负面情绪。
Key Term Extraction:输入是1篇文章等,输出是几个关键词。
Many to Many
输入和输出都是sequence,但输出更短。
Speech Recognition
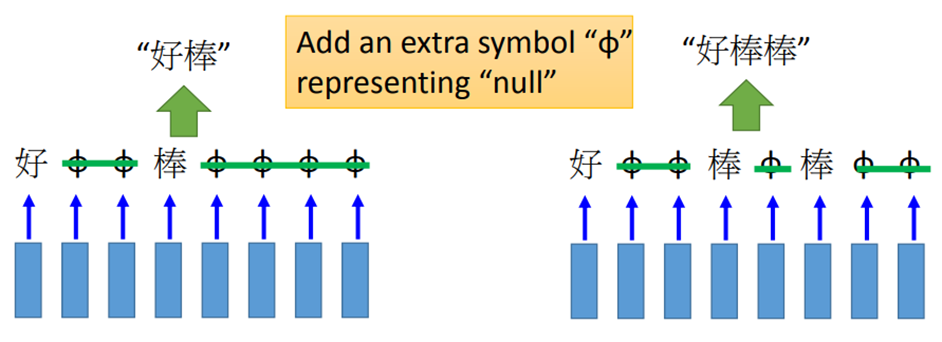
输入是一段声音信号,每隔一小段时间就用1个vector来表示。但“好棒”和“好棒棒”实际上是不一样的,如何区分呢?需要用到CTC算法,它的基本思想是,输出不只是字符,还要填充NULL,输出的时候去掉NULL就可以得到连词的效果
Sequence to Sequence Learning
在Seq2Seq中,RNN的输入输出都是sequence,但是长度不同。
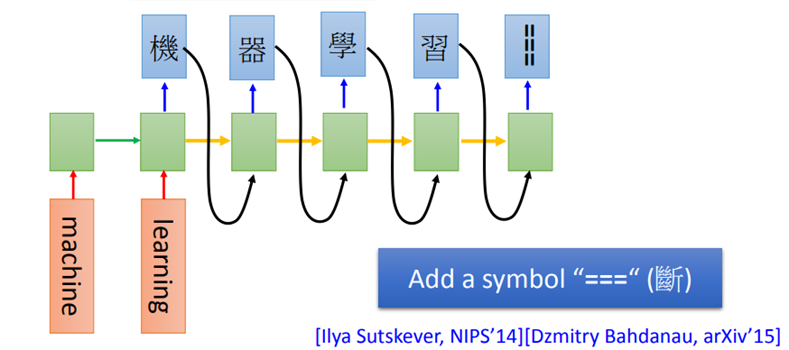
比如现在要做机器翻译,将英文的word sequence翻译成中文的character sequence。如果想要停止,就把可以多加一个叫做“断”的symbol “===”,当输出到这个symbol时,机器就停止输出。
Seq2Seq for Syntatic Parsing
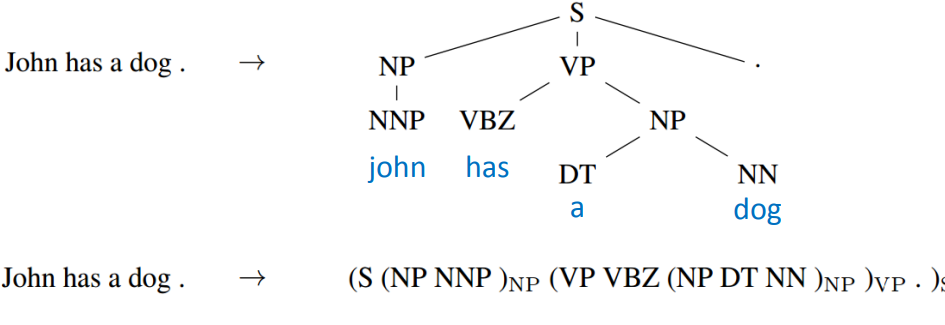
Seq2Seq还可以用在句法解析上,让机器看一个句子,它可以自动生成树状的语法结构图。
Seq2Seq for Auto-encoder Text
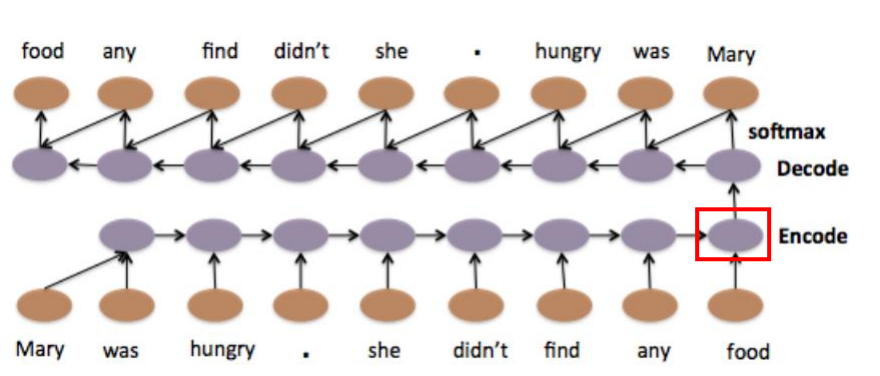
考虑了语序的情况下,把文章编码成vector,只需要把RNN当做编码器和解码器即可。
Seq2Seq for Auto-encoder Speech
Seq2Seq autoencoder还可以用在语音处理上,它可以把一段语音信号编码成vector。
Attention-based Model
除了RNN之外,Attention-based Model也用到了memory的思想。机器会有自己的记忆池,神经网络通过操控读写头去读或者写指定位置的信息,这个过程跟图灵机很像,因此也被称为Neural Turing Machine。