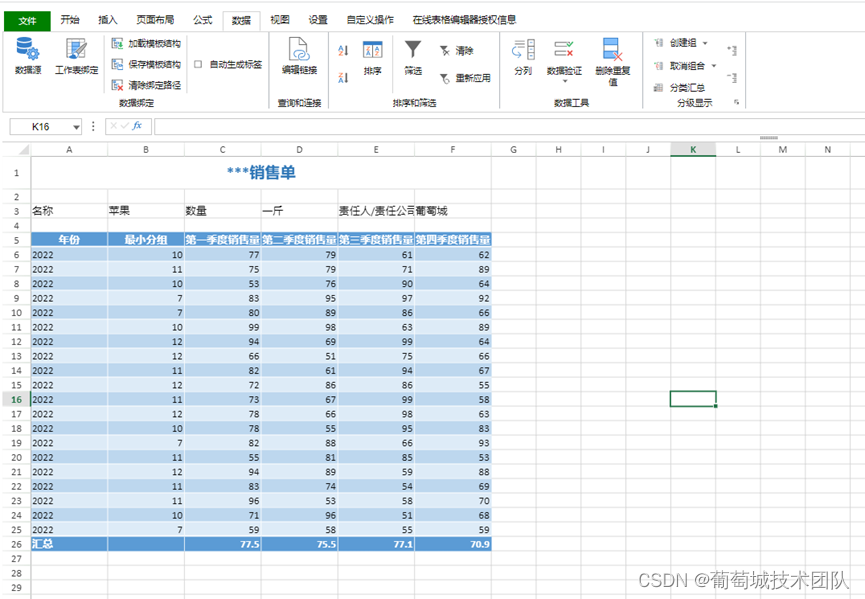
双流JOIN(Regular Join)

Regular Join 就是大家熟知的双流 Join,语法上就是普通的 JOIN 语法。图中案例是通过广告曝光流关联广告点击流将广告数据打宽,打宽后可以进一步计算广告费用。从图中可以看出,曝光流和点击流都会存入 join 节点的 state,join 算子通过关联曝光流和点击流的 state 实现数据打宽。Regular Join 的特点是,任意一侧流都会触发结果的更新,比如案例中的曝光流和点击流。同时 Regular Join 的语法与传统批 SQL 一致,用户学习门槛低。但需要注意的是,Regular join 通过 state 来存储双流已经到达的数据,state 默认永久保留,所以 Regular join 的一个问题是默认情况下 state 会持续增长,一般我们会结合 state TTL 使用。

区间JOIN(Interval Join)
Interval Join 是一条流上需要有时间区间的 join,比如刚刚的广告计费案例中,它有一个非常典型的业务特点在里面,就是点击一般发生在曝光之后的 10 分钟内。因此相对于 Regular Join,我们其实只需要关联这10分钟内的曝光数据,所以 state 不用存储全量的曝光数据,它是在 Regular Join 之上的一种优化。要转成一个 Interval Join,需要在两个流上都定义时间属性字段(如图中的 click_time 和 show_time)。并在 join 条件中定义左右流的时间区间,比如这里我们增加了一个条件:点击时间需要大于等于曝光时间,同时小于等于曝光后 10 分钟。与 Regular Join 相同, Interval Join 任意一条流都会触发结果更新,但相比 Regular Join,Interval Join 最大的优点是 state 可以自动清理,根据时间区间保留数据,state 占用大幅减少。Interval Join 适用于业务有明确的时间区间,比如曝光流关联点击流,点击流关联下单流,下单流关联成交流。

维表JOIN(Temporal join)
Temporal join (时态表关联) 是最常用的数据打宽方式,它常用来做我们 熟 知 的 维 表 J o i n 。 在 语 法 上 , 它 需 要 一 个 显 式 的 F O R SYSTEM_TIME AS OF 语句。它与 Regular Join 以及 Interval Join 最大的区别就是,维度数据的变化不会触发结果更新,所以主流关联上的维度数据不会再改变。Flink 支持非常丰富的 Temporal join 功能,包括关联 lookup DB,关联 changelog,关联 Hive 表。在以前,大家熟知的维表 join 一般都是关联一个可以查询的数据库,因为维度数据在数据库里面,但实际上维度数据可能有多种物理形态,比如 binlog 形式,或者定期同步到 Hive 中变成了 Hive 分区表的形式。在 Flink 1.12 中,现在已经支持关联这两种新的维表形态。
Lookup DB
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OR22UIe2-1685065370914)(
)]
Temporal Join Lookup DB 是最常见的维表 Join 方式,比如在用户点击流关联用户画像的案例中,用户点击流在 Kafka 中,用户实时画像存放在 HBase 数据库中,每个点击事件通过查询并关联 HBase 中的用户实时画像完成数据打宽。Temporal Join Lookup DB 的特点是,维表的更新不会触发结果的更新,维度数据存放在数据库中,适用于实时性要求较高的场景,使用时我们一般会开启 Async IO 和内存 cache 提升查询效率。
Changelog Stream
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l7r30TYG-1685065370914)(C:\Users\ambit\AppData\Roaming\Typora\typora-user-images\image-20230313000417185.png)] 针对这类场景,Flink 1.12 支持了 Temporal Join Changelog,通过从 changelog在 Flink state 中物化出维表来实现维表关联。刚刚的场景有了更简洁的解决方案,我们可以通过 Flink CDC connector 把直播间数据库表的 changelog 同步到 Kafka 中,注意我们看下右边这段 SQL,我们用了 upsert-kafka connector 来将 MySQL binlog 写入了 Kafka,也就是 Kafka 中存放了直播间变更数据的 upsert 流。然后我们将互动数据 temporal join 这个直播间 upsert 流,便实现了直播数据打宽的功能。
注意我们这里 FOR SYSTEM_TIME AS OF 不是跟一个 processing time,而是左流的 event time,它的含义是去关联这个 event time 时刻 的 直 播 间 数 据 , 同 时 我 们 在 直 播 间 u p s e r t 流 上 也 定 义 了 watermark,所以 temporal join changelog 在执行上会做 watermark 等待和对齐,保证关联上精确版本的结果,从而解决先前方案中关联不上的问题。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-88ZIsnqa-1685065370914)(
)]
我们详细解释下 temporal join changelog 的过程,左流是互动流数据,右流是直播间 changelog。直播间 changelog 会物化到右流的维表 state 中,state 相当于一个多版本的数据库镜像, 主流互动数据会暂时缓存在左流的 state 中,等到 watermark 到达对齐后再去查维表 state 中的数据。比如现在互动流和直播流的 watermark 都到了10:01分,互动流的这条 10:01 分评论数据就会去查询维表 state,并关联上 103 房间的信息。当 10:05 这条评论数据到来时,它不会马上输出,不然就会关联上空的房间信息。它会一直等待,等到左右两流的 watermark 都到 10:05 后,才会去关联维表 state 中的数据并输出。这个时候,它能关联上准确的 104 房间信息。
总结下,Temporal Join Changelog 的特点是实时性高,因为是按照 event time 做的版本关联,所以能关联上精确版本的信息,且维表会做 watermark 对齐等待,使得用户可以通过 watermark 控制迟到的维表数。Temporal Join Changelog 中的维表数据都是存放在 temporal join 节点的 state 中,读取非常高效,就像是一个本地的 Redis 一样,用户不再需要维护额外的 Redis 组件。
Hive
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rSTwtf0M-1685065370915)(
)]
在数仓场景中,Hive 的使用是非常广泛的,Flink 与 Hive 的集成非常友好,现在已经支持 Temporal Join Hive 分区表和非分区表。我们举个典型的关联 Hive 分区表的案例:订单流关联店铺数据。店铺数据一般是变化比较缓慢的,所以业务方一般会按天全量同步店铺表到 Hive 分区中,每天会产生一个新分区,每个分区是当天全量的店铺数据。
为了关联这种 Hive 数据,只需我们在创建 Hive 分区表时指定右侧这两个 红 圈 中 的 参 数 , 便 能 实 现 自 动 关 联 H i v e 最 新 分 区 功 能 ,partition.include = latestb 表示只读取 Hive 最新分区,partition name 表示选择最新分区时按分区名的字母序排序。到 10 月 3 号的时候,Hive 中已经产生了 10 月 2 号的新分区, Flink 监控到新分区后,就会重新加载10月2号的数据到 cache 中并替换掉10月1号的数据作为最新的维表。之后的订单流数据关联上的都是 cache 10 月 2 号分区的数据。Temporal join Hive 的特点是可以自动关联 Hive 最新分区,适用于维表缓慢更新,高吞吐的业务场景。