1、Hadoop数据压缩
1.1 概述
1、压缩的好处和坏处
(1)优点:减少磁盘IO、减少磁盘储存空间
(2)缺点:增加CPU开销
2、压缩原则
(1)运算密集型的Job,少用压缩
(2)IO密集型的Job,多用压缩
1.2 MR支持的压缩编码
1、压缩算法对比介绍
| 压缩格式 | Hadoop自带? | 算法 | 文件扩展名 | 是否可切片 | 换成压缩格式后,原来的程序是否需要修改 |
|---|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要按安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 是,直接使用 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
2、压缩性能的比较
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
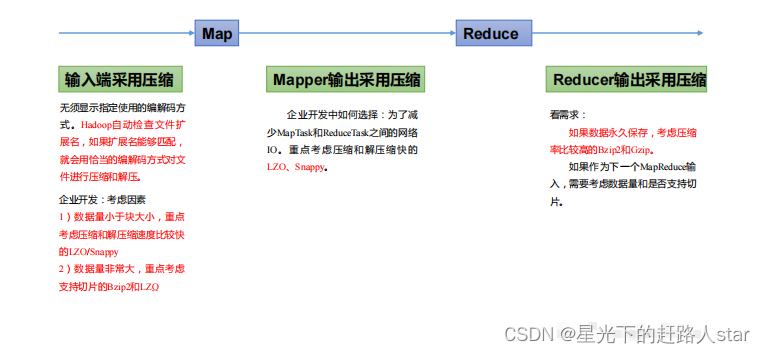
1.3、压缩方式选择
重点考虑:压缩?解压缩速度、压缩率(压缩后储存大小)、压缩后是否可以支持切片
(1)Gzip压缩
优点:压缩率比较高
缺点:不支持Spilt;压缩/解压速度一般
(2)Bzip压缩
优点:压缩率高,支持Spilt
缺点:压缩/解压速度慢
(3)LZO压缩
优点:压缩/解压速度比较快;支持Spilt
缺点:压缩率一般;想支持切片需要额外创建索引
(4)Snappy压缩
优点:压缩和解压速度快
缺点:不支持Spilt;压缩率一般
(5)压缩位置选择
压缩可以在MapReduce作用的任意阶段启用。
1.4、压缩参数配置
(1)为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
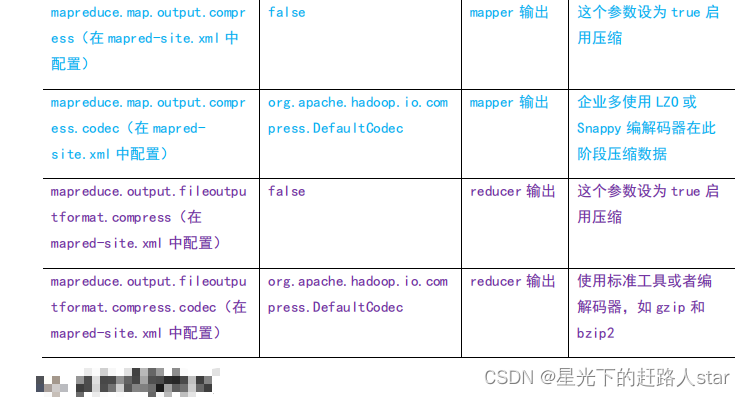
(2)要在Hadoop中启用压缩,可以配置如下参数

1.5 压缩案例实操
1.5.1 Map输出端采用压缩
即使你的MapReduce的输入和输出文件都是未压缩文件,你任然可以对Map任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到Reduce节点,对其压缩可以提高很多性能,这些工作只有设置两个属性即可,我们来看下代码怎么设置。
用wordcount举例子
1、给大家提供的 Hadoop 源码支持的压缩格式有:BZip2Codec、DefaultCodec
(1)Driver类
package org.example._12yasuo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @ClassName WordCountDriver
* @Description TODO
* @Author Zouhuiming
* @Date 2023/5/19 11:29
* @Version 1.0
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1、获取job
Configuration configuration=new Configuration();
//开启map段输出压缩
configuration.setBoolean("mapreduce.map.output.compress.codec", true);
configuration.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class,CompressionCodec.class);
Job job=Job.getInstance(configuration);
//2、设置jar包路径
job.setJarByClass(WordCountDriver.class);
//3、关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
//4、设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5、设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6、设置输入路径和输出路径
FileInputFormat.addInputPath(job,new Path("E:\\testCSDN\\input"));
FileOutputFormat.setOutputPath(job,new Path("E:\\testCSDN\\output1"));
//7、提交job
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
(2)Mapper和Reducer保持不变
1.5.2 Reduce输出端采用压缩
1、Driver
package org.example._13yasuo1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.bzip2.Bzip2Compressor;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @ClassName WordCountDriver
* @Description TODO
* @Author Zouhuiming
* @Date 2023/5/19 11:29
* @Version 1.0
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1、获取job
Configuration configuration=new Configuration();
Job job=Job.getInstance(configuration);
//2、设置jar包路径
job.setJarByClass(WordCountDriver.class);
//3、关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
//4、设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5、设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6、设置输入路径和输出路径
FileInputFormat.addInputPath(job,new Path("E:\\testCSDN\\input"));
FileOutputFormat.setOutputPath(job,new Path("E:\\testCSDN\\output2"));
//设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job,true);
//设置压缩方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
//7、提交job
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
(2)Mapper和Reducer类保持不变