源自:指挥与控制学报
作者:林萌龙, 陈涛, 任棒棒, 张萌萌, 陈洪辉
摘 要



1 背景
1.1 集中式决策VS分布式决策



1.2 多智能体强化学习



2 问题描述

2.1 场景描述


2.2 状态空间、动作空间与奖励函数设计




3 基于MADDPG算法的作战体系任务分配模型



3.1 基于MADDPG任务分配算法框架

3.2 Actor网络结构



3.3 Critic网络结构



4 实验
4.1 对比算法设置

4.2 实验环境


4.3 实验结果分析

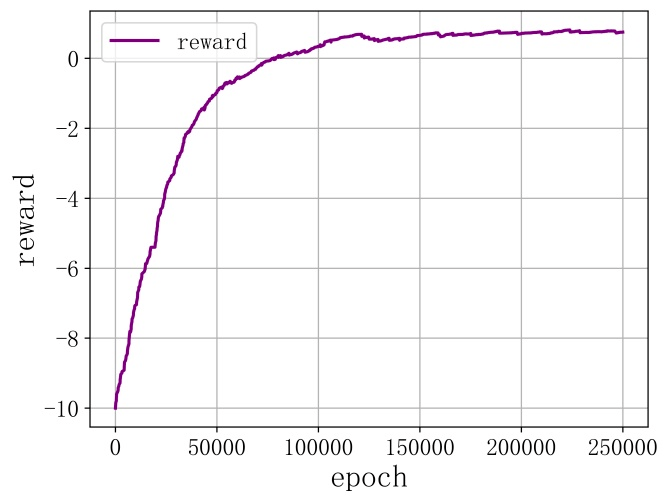

5 结论

声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。