目录
- 1 uvm中的学习内容
- 2 类库地图
- 3 工厂机制
- 3.1 工厂的意义
- 3.2 工厂提供的便利
- 3.3 覆盖方法
- 4 核心基类
- 4.1 uvm_object
- 4.2 域的自动化
- 4.3 拷贝(copy)
- 4.4 比较
- 4.5 打印
- 4.6 打包和解包
- 5 phase机制
- 5.1 概述
- 5.2 phase的九个执行机制
- 5.3 UVM仿真顺序
- 6 config机制
- 6.1 概述
- 6.2 interface传递
- 6.3 变量设置
- 6.4 config object机制
- 6.5 总结
- 7 消息管理
- 7.1 概述
- 7.2 消息方法
- 7.3 消息处理
- 7.4 消息宏
- 7.5 消息机制
1 uvm中的学习内容
(1)认识UVM世界的版图(类库)和核心机制
(2)学习核心的UVM组件间和层次构建方式
(3)了解常见的UVM组件间的通信方式
(4)深入UVM测试场景的构成
(5)UVM寄存器模型的应用
2 类库地图
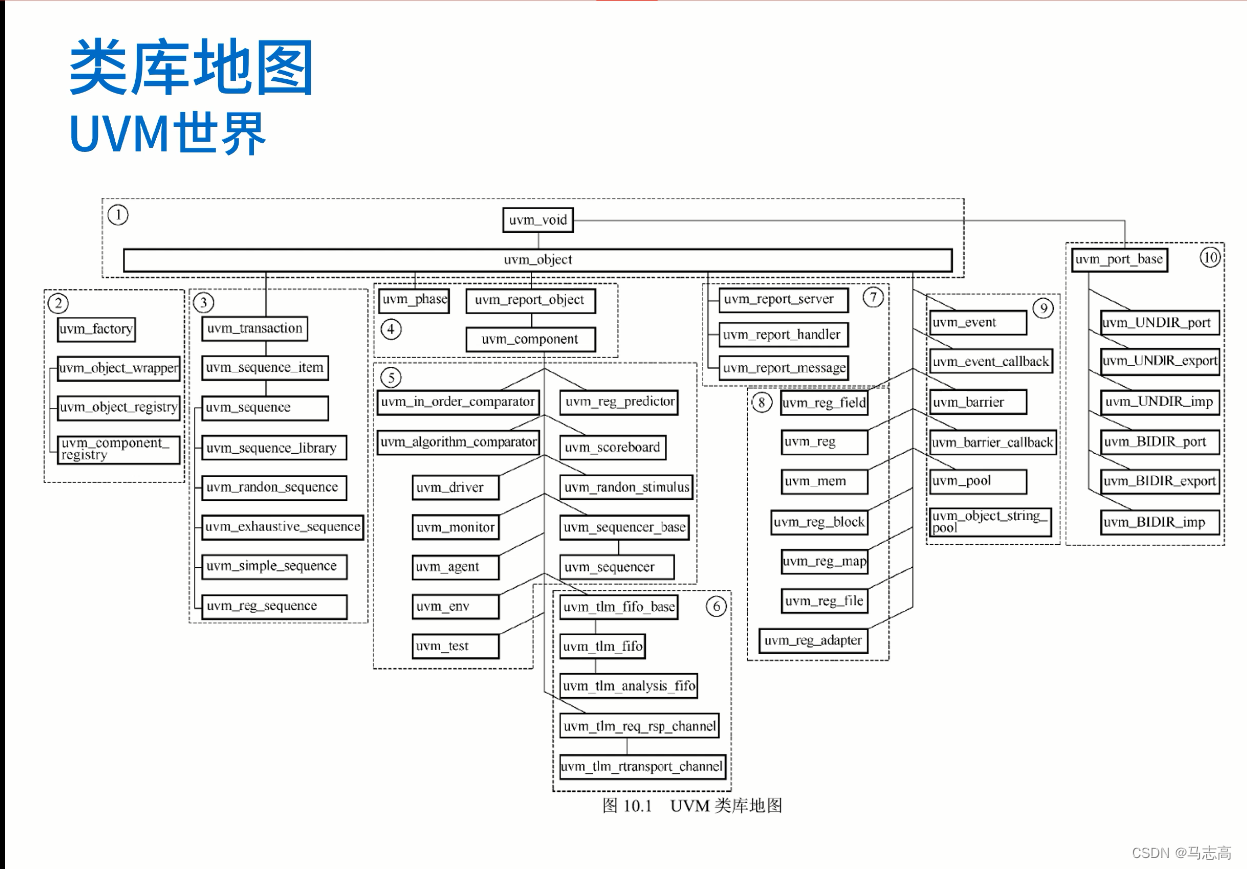
1.核心基类:核心基类提供最底层的支持,包括一些基本的方法,如复制、创建、比较和打印。
2.工厂(factory)类:工厂类提供注册环境组件、创建组件和覆盖组件类型的方法。
3.事务(transaction)和序列(sequence)类:事务类和序列列用来规定在TLM传输管道中的数据类型和数据生成方式。
4.结构创建(structure creation)类;
5.环境组件(environment component)类:环境组件类则是构成环境结构的主要部分。
6.通信管道(channel)类:事务接口类和通信管道类则共同实现组件之间的通信和存储。
7.信息报告(message report)类;
8.寄存器模型(register model)类:用来完成对寄存器和存储的建模、访问和验证。
9.线程同步(thread synchronization)类:线程同步则比sv自身的同步方法更方便,发生同步时可传递更多的信息更多。
10.事务接口(transaction interface)类;
3 工厂机制
3.1 工厂的意义
UVM工厂的存在就是为了更方便地替换验证环境中的实例或已注册的类型,同时工厂的注册机制带来配置的
灵活性。这里的实例或类型替代在UVM中称为覆盖(override),用来替换的对象或者类型应满足注册
(registeration)和多态(polymorphism)的要求。UVM的验证环境分为两部分,一部分构成环境的层
次,这部分代码通过uvm_component类完成,另一部分构成环境的属性(例如配置)和数据传输,这一部分
通过uvm_object类完成。
3.2 工厂提供的便利
1.一般运用factory的步骤为:
(1)定义
(2)注册
(3)构建函数
class comp1 extends uvm_component;//(1)定义
`uvm_component_utils(comp1) //宏定义:(2)注册
function new(string name="comp1",uvm_component parent=null);//(3)构建函数,当uvm_component的时候两个固定参数name和parent,name为class名,parent为上一层,即例化comp1的那一层。
super.new(name,parent);//对父类里面的new函数做了继承
$display($sformatf("%s is created",name));
endfunction:new
function void build_phase(uvm_phase phase);
super.build_phase(phase);
endfunction:build_phase
endclass
class obj1 extends uvm_object;//(1)定义
`uvm_object_utils(obj1)//(2)注册
function new(string name = "obj1");//(3)构建函数,当uvm_object时候只有一个参数name
super.new(name);
$display($sformatf("%s is create",name));
endfunction: new
endclass
comp1 c1,c2; //句柄
obj1 o1,o2; //句柄
initial begin
c1 = new("c1"); //sv方式:new函数创建对象
o1 = new("o1");
c2 = comp1::type_id::create("c2",null); //uvm_component对象创建方式:工厂的方式来创建对象,要求使用工厂这种方式来创建对象
o2 = obj1::type_id::create("o2");//uvm_object对象创建方式
end
2.uvm_coreservice_t类
该类内置了UVM世界核心的组件和方法,它们主要包括
(1)唯一的uvm_factory,该组件用来注册、覆盖和例化
(2)全局的report_server,该组件用来做消息统筹和报告
(3)全局的tr_database,该组件用来记录transaction记录
(4)get_root()方法用来返回当前UVM环境的结构顶层对象
(1)在UVM1.2中,明显的变化是通过uvm_coreservice_t将最重要的机制(也是必须做统一例化处理的组件)都放置在了uvm_coreserice_t类中。
(2)该类并不是uvm_component或者uvm_object,它也并没有例化在UVM环境中,而是独立于UVM环境之外的。uvm_coreservice_t产生factory,factory可以创建component和object类型,所以该类型不是component和object类型。
3.工厂创建component/oject的方法
- 除了使用component/object来创建实例,也可以利用factory来创建
create_component_by_name()
create_component_by_type()
create_object_by_name()
create_object_by_type()
- 为了避免不必要的麻烦,就使用type_id这种方法,但是其他的方法也需要了解一下。 其他还有一些组件提供的创建方法。
3.3 覆盖方法
1.覆盖机制可以将原来所属的类型替换为另外一个新的类型
2.在覆盖之后,原本用来创建原属性类型的请求,将由工厂来创建新的替换类型。
(1)无需再修改原始代码,继而保证了原来代码的封装性。
(2)新的替换类型必须与被替换类型相兼容,否则稍后的句柄赋值将失效,所以使用继承。
3.做顶层修改时,非常方便!
(1)允许灵活的配置,例如可使用子类来覆盖原本的父类
(2)可使用不同的对象来修改其代码行为
4.要想实现覆盖特性,原有类型和新类型均需要注册
5.当使用create()来创建对象时:
(1)工厂会检查,是否原有类型被覆盖
(2)如果是,那么它会创建一个新类型的对象
(3)如果不是,那么它会创建一个原有类型的对象
6.覆盖发生时,可以使用“类型覆盖”或者“实例覆盖”
(1)类型覆盖指,UVM层次结构下的所有原有类型都被覆盖类型所替换
(2)实例覆盖指,在某些位置中的原有类型会被覆盖类型所替换
7.覆盖方法
(1)类型覆盖:set_type_override()
static_function void set_type_override(uvm_object_wrapper
override_type,bit replace=1);
- uvm_object_wapper override_type
这是什么?并不是某一个具体实例的句柄,实际上是注册过后的某一个类在
工厂中注册时的句柄。怎么找到它呢?就使用new_type::get_type()。
- bit replace = 1
1:如果已经有覆盖的存在,那么新的覆盖会替代旧的覆盖。
0:如果已经有覆盖的存在,那么该覆盖将不会生效。
- set_type_override是一个静态函数
orig_type::type_id::set_type_override(new_type::get_type())
(2)实例名覆盖:set_inst_override()
static function void set_inst_override(uvm_objext_wrapper
override_type,string inst_path,uvm_component parnet=null);
- string inst_path指向的是组件结构的路径字符串
- uvm_component parent = null
如果缺省,表示使用inst_path的内容为绝对路径,
如果有值传递,则使用{parent.get_full_name(),'.',inst_path}
来作为目标路径
- set_type_override是一个静态函数
- orig_type::type_id::set_inst_override(new_type::get_type(),"orig_inst_path")
8.如何使用覆盖相关的函数
- 首先需要知道,有不止一个类提供与覆盖相关的函数,然而名称与参数列表可能各不相同:
- uvm_component::set_(type,inst)_override{_by_type}
- uvm_component_registry::set_{type,inst}_override
- uvm_object_registery::set_{type,inst}_override
- uvm_factory::set_{type,inst}_override
-因此,想要实现类型替换,也有不止一种方式。包括上述给的例子中通过orig_type::type_id来调用覆盖函数,还可以在uvm_component的域中直接调用,或者使用uvm_factory来做覆盖。
9.例子
目的:comp2替代comp1
module factory_override;
import uvm_pkg::*; //vcs中需要编译
`include "uvm_macros.svh" //vcs中需要编译
class comp1 extends uvm_component;//定义
`uvm_component_utils(comp1)//注册
function new(string name= "comp1,uvm_component parnet=null");//构造函数
super.new(name,parnet);
$display($sformatf("comp1::%s is created",name));
endfunction:new
virtual function void hello(string name);
$display($sformatf("comp1::%s said hello!",name));
endfunction
endcalss
class comp2 extends comp1;//定义
`uvm_component_utils(comp2)//注册
function new(string name="comp2",uvm_component parent=null);//构建函数
super.new(name,parent);
$display($sformatf("comp2::%s is created",name));
endfunction:new
function void hello(string name);
$display($sformatf("comp2::%s said hello!",name));
endfunction
endclass
//注意,需要先做覆盖的配置,再做类型的变化
comp1 c1,c2;
initial begin
comp1::type_id::set_type_override(comp2::get_type());//set_type_override覆盖方法
c1 = new("c1");//没有通过工厂创建所以没有调换
c2 = comp1::type_id::create("c2",null);//使用工厂的创建方法有利于使用覆盖
c1.hello("c1");
c2.hello("c2");
end
endmodule
打印信息
comp1::c1 is created
comp1::c2 is created
comp2::c2 is created
comp1::c1 said hello!
comp2::c2 said hello!
10.结果分析
(1)在例化c2之前,首先应该用comp2来替换comp1的类型,只有先完成了类型替换,才可以在后面的例化时由factory选择正确的类型。
(2)上面的例码中较好地反映了一些实际情况,首先在声明c2时,由于验证工程师不知道今后可能存在着覆盖,所以类型为comp1。在后面发生了类型的替换以后,如果原有的代码不做更新 ,那么c2句柄的类型仍然为comp1,却指向了comp2类型的对象。这就要求,comp2应该是comp1的子类,只有这样,句柄指向才是安全合法的。
(3)c2在调用hello()方法时,由于首先是comp1类型,那么会查看comp1::hello(),又由于该方法定义是被指定为虚函数,这就通过了多态性的方法调用,转而调用了comp2::hello()函数。因此,显示的结果也是“comp2::c2 said hello”。
4 核心基类
4.1 uvm_object
- UVM世界中的类最初都是从一个uvm_void根类(root class)继承来的,而实际上这个类并没有成员变量和方法
- uvm_void只是一个虚类(virtual class),还在等待将来继承于它的子类去开垦。在继承于uvm_void的子类中,有两个类,一个为uvm_object类,另外一个为uvm_port_base类。
- 在uvm世界的类库地图中除了事务接口(transaction interface)类继承于uvm_port_base,其它所有的类都是从uvm_object类一步一步继承而来的。
- 从uvm_object提供的方法和相关的宏操作来看,它的核心方法主要提供与数据操作的相关服务:
- Copy
- Clone
- Conmpare
- Pack/Unpack
- 在SV模块的学习中,我们懂得了什么事句柄拷贝和对象拷贝。因此,无论是copy或者clone,都需要确保在操作的过程中,需要有source object和target object。
4.2 域的自动化
- 从UVM通过域的自动化,使得用户在注册UVM类的同时也可以声明今后会参与到对象拷贝、克隆、打印等操
的成员变量。
- 域的自动化解放了verifier的双手,这使得在使用uvm_object提供的一些预定义方法时,非常便捷,而
无需再实现自定义方法。
- 在了解了域的自动化常用的宏之后,用户需要考虑那些成员变量在注册UVM类(`uvm_{component
,object}_utils)的时候,也一并将它们归置到对应的域列表中,以便为稍后的域方法提供可以自动实现
基础。
class box extends uvm_object;//定义
int volume = 120;//变量定义
color_t color = WHITE;
string name = "box";
`uvm_object_utils_begin(box) //注册+域的自动化的声明,使用了宏定义
`uvm_field_int(volume,UVM_ALL_ON)
`uvm_field_enum(color_t,color,UVM_ALL_ON)
`uvm_field_string(name,UVM_ALL_ON)
`uvm_object_utils_end
...//省略了构建函数:new函数
endclass
box b1,b2;
initial begin
b1 = new("box1");
b1.volume = 80;
b1.color = BLACK;
b2 = new();
b2.copy(b1);//复制
b2.name = "box2";
end
- 从这个域的自动化宏的例子来看,在注册box的同时,也声明了将来会参加到uvm_object数据操作的成员
变量。 - 凡是声明了的成员变量,都将在数据操作时自动参与进来。
- 如果有一些数据没有通过域的自动化来声明的话,它们也将不会自动参与到数据的拷贝、打印等操作,
除非用户自己去定义这些数据操作方法。
4.3 拷贝(copy)
- 在uvm的数据操作中,需要对copy和clone加以区分。前者默认已经创建好了对象,只需要对数据进行
拷贝;后者则会自动创建对象并对source object进行数据拷贝,再返回target object句柄。
- 无论是copy或者clone,都需要对数据进行复制。
- 但是如果数据成员包括句柄,那么拷贝的时候,是否拷贝该成员句柄本身,还是也额外创建新的对象,拷
贝该句柄指向的对象?
- 以示例可以看到,在进行copy时,默认进行的是深拷贝(deep copy),即会执行copy()和do_copy()。
class ball extends uvm_object;//定义
int diameter = 10;//变量定义
color_t color = RED
`uvm_object_utils_begin(ball)//注册+域的自动化
`uvm_filed_int(diameter,UVM_DEFAULT)
`uvm_filed_enum(color_t,color,UVM_NOCOPY)
`uvm_object_utils_end
... //省略了构建函数:new函数
function void do_copy(uvm_object rhs);
ball b;
$cast(b,rhs);
$display("ball::do_copy enterd..");
if(b.diameter <= 20)begin
diameter = 20;
end
endfunction
endclass
calss box extends uvm_object;
int volume = 120;
color_t color = WHITE;
string name = "box";
ball b;
`uvm_object_utils_begin(box)
`uvm_filed_int(volume,UVM_ALL_ON)
`uvm_filed_enum(color_t,color,UVM_ALL_ON)
`uvm_filed_string(name,UVM_ALL_ON)
`uvm_filed_object(b,UVM_ALL_ON)
`uvm_object_utils_end
...
endclass
box b1,b2;
initial begin
b1 = new("box1");//创建
b1.volume = 80;//修改值
b1.color = BLACK;
b1.b.color = WHITE;
b2 = new();
b2.copy(b1);//拷贝
b2.name = "box2";
$display("%s",b1.sprint());
$display("%s",b2.sprint());
end
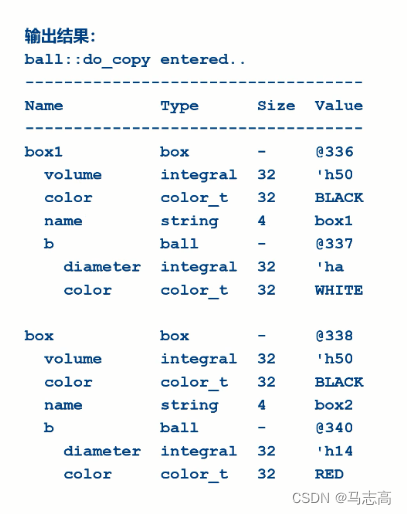
分析:
- 新添加的一个类ball,并且在box中例化了一个ball的对象。在拷贝过程中,box的其他成员都正常拷贝
了,但对于box::b拷贝则通过了ball的深拷贝方式进行。
- 即先执行自动拷贝copy(),来拷贝运行拷贝的域,由于ball::color不允许拷贝,所以只拷贝了ball::
diameter。
- 接下来,再执行do_copy()函数,这个函数是需要用户定义的回调函数(callback function),即在
copy()执行完后会执行do_copy()。
- 如果用户没有定义该函数,那么则不会执行额外的数据操作。
- 从ball::do_copy()函数可以看到,如果被拷贝对象的diameter小于20,那么则将自身的diameter设置
因此,最后对象b2.b的成员与b1.b的成员数值不同。
浅拷贝与深拷贝的理解:
原文链接:https://blog.csdn.net/Bunny9__/article/details/123438753
浅拷贝即句柄拷贝,只拷贝对象中的数据变量,比如数组、句柄,但是它不复制对象,只复制了句柄,对于对象中的数据操作(一般为任务和函数)和其中定义的其他类的句柄,采用类似“引用”的方式,浅拷贝前后共用同一内存空间;
深拷贝即对象拷贝,对对象中的所有成员变量(包括数据变量、数据操作和其他句柄)统一分配新的内存空间
4.4 比较
function bit compare(uvm_object rhs,uvm_comparer comparer = null);
- 默认情况下,如果不对比较的情况作出额外配置,用户可以在调用compare()方法时,省略第二项参数,
即采用默认的比较配置。
- 比较方法经常会在两个数据中进行。例如从generator产生的一个transaction(数据类),和在设计输
出上捕捉的transaction(数据类),如果他们为同一种类型,除了可以自定义数据来比较之外,也可以直接
使用uvm_object::compare()函数来实现数据比较和消息打印。
class box extends uvm_object;
int volume = 120;
color_t color = WHITE;
string name = "box";
`uvm_object_utils_begin(box)
...
`uvm_object_utils_end
...
endclass
box b1,b2;
initial begin
b1 = new("box1");
b1.volume = 80;
b1.color = BLACK;
b2 = new("box2");
b2.volume = 90;
if(!b2.compare(b1))begin
`uvm_info("COMPARE","b2 compared with b1 failure",UVM_LOW)
end
else begin
`uvm_info("COMPARE","b2 compare with b1 success",UVM_LOW)
end
end
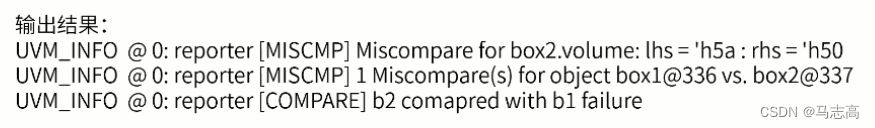
输出结果显示volume的值不一样,但是b1和b2不仅仅是volume不一样,color也不一样,但是没有显示,原因是:uvm的比较发生错误即刻返回。
在uvm_pkg中例话了不少全局对象,而在本节中我们会使用到的全局配置对象包括uvm_default_comparer,uvm_default_pinter和uvm_default_packer。
如果用户不想使用默认的比较配置,而是想直接对比较进行设定,可以考虑创建一个uvm_comparer对象,或者修改全局的uvm_comparer对象。
但是是不可以去自己创建uvm_factory的。
4.5 打印
-
打印方法是核心基类提供的另外一种便于开发和调试的功能。
-
通过field automatic,使得声明之后的各个成员域会在调用uvm_object::print()函数时自动打印出来
-
相比于在仿真中设置断点,逐步调试,打印是另外一种调试方式。它的好处在于可以让仿真继续进行,会在最终回顾执行过程中,从全局理解执行的轨迹和逻辑。
-
代码例子
class box extends uvm_object;
int volume = 120;
color_t color = WHTTE;
string name = "box";
`uvm_object_utils_begin(box)
...
endclass
box b1;
uvm_table_printer local_printer;
initial begin
b1 = new("box1");
local_printer = new();
$display("default table printer format");//不同的打印形式
b1.print();
$display("default line printer format");//不同的打印形式
uvm_default_printer = uvm_default_line_printer;
b1.print();
$display("default tree printer format");//不同的打印形式
uvm_default_printer = uvm_default_line_printer;
b1.print();
$display("customized pinter format");//不同的打印形式
local_printer.knobs.full_name = 1;
b1.print(local_printer);
end
4.6 打包和解包
function int pack (ref bit bitstream[],input uvm_packer packer=null);
function int unpack (ref bit bitstream[],input uvm_packer packer=null);
5 phase机制
5.1 概述
SV的验证环境构建中,我们可以发现,传统的硬件设计模型在仿真开始前,已经完成例化和连接了;而SV的软件部分对象例化则需要在仿真开始后执行。虽然对象例化通过调用结构函数new()来实现,但是单单通过new()函数无法解决一个重要问题,那就是验证环境在实现层次化时,如何保证例化的先后关系,以及各个组件在例化后的连接。引入phase机制,通过该机制我们清晰地将UVM仿真阶段层次。
phase机制理解起来比较简单,如果把验证平台的不同的companont理解成一个班级里上课的同学,那么虽然不同的同学每节课写作业有快有慢,但是他们都整齐划一的按照上课的时间,下课的时间,共享一个作息表。UVM极简教程
5.2 phase的九个执行机制
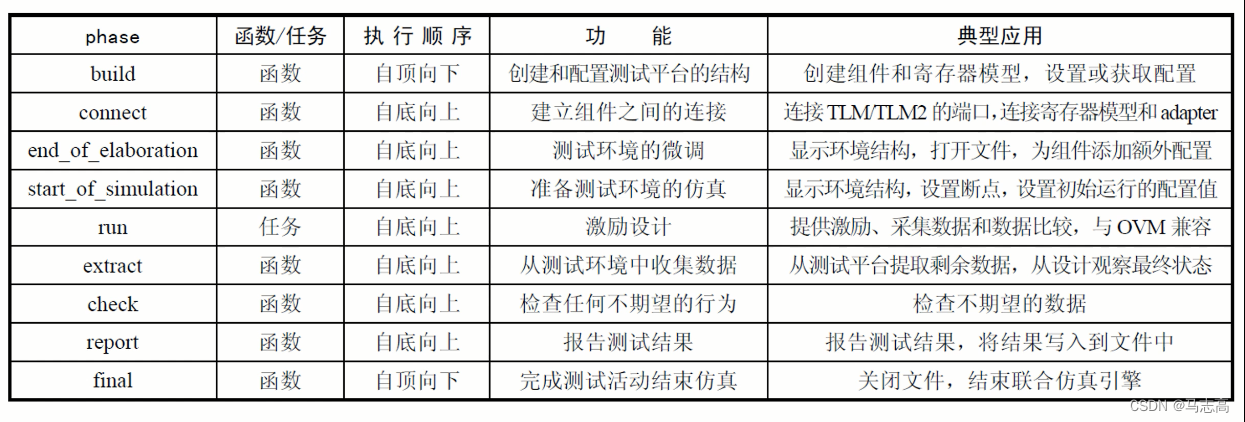
- 主要使用的为build,connect,run,report这四种类型。
- 只有一个任务,其他皆为函数,函数需要立即做返回。
- 如果暂时抛开phase的机制剖析,对于UVM组件的开发者而言,他们主要关心各个phase的先后执行顺序。
- 在定义了各个phase虚方法后,UVM环境会按照phase的顺序分别调用这些方法。
- 上面的九个phase对于一个测试环境的生命周期而言,是有固定的先后执行顺序的;同时对于同一个phase中的组件,执行也会按照层次的顺序或者自顶向下、或者自底向上来执行。
- 对于build phase,执行顺序按照自顶向下,这符合验证建设的逻辑。因为只有先例话高层组件,才会创建空间来容纳底层组件。
- 只有uvm_component及其继承于uvm_compoent的子列,才会按照phase机制将上面的九个phase先后执行完毕。
- 在run_phase中,用户如果要完成测试,通常需要组织下面的激励序列:
(1)上电
(2)复位
(3)寄存器配置
(4)发送主要测试内容
(5)等待DUT完成测试
class subcomp extends uvm_component;
`uvm_compoent_utils(subcomp)
function new(string name,uvm_component parent);
super.new(name,parent);
endfunction
function void build_phase(uvm_phase phase);
`uvm_info("build_phase","",UVM_LOW)
endfunction
function void connect_phase(uvm_phase phase);
`uvm_info("connect_phase","",UVM_LOW)
endfunction
...
task run_phase(uvm_phase phase);
`uvm_info("run_phase","",UV_LOW)
endtask
function void report_phase(uvm_phase phase)
`uvm_info("report_phase","",UVM_LOW)
endfunction
...
endclass
5.3 UVM仿真顺序
- UVM仿真开始
要在仿真开始时建立验证环境,有以下几种方式
- 可以通过全局函数run_tset
- 如果没有任何参数传递给run_test(),那么用户可以在仿真时通过传递参数+UVM_TESTNAME=<test_name>,来指定仿真时调用的uvm_test。
无论哪一种方式,都需要在顶层调用全局函数run_test()。
- UVM“世界”的诞生
//run_test的源码
task run test(string test_name="");
uvm_root top;
uvm_coreservice_t cs;
cs = uvm_coreservice_t::get();
top = cs.get_root();
top.run_test(test_name);
endtask
- UVM顶层类uvm_root。该类也继承于uvm_component它也是uvm_component,它也是UVM环境结构中的一员,而它可以作为顶层结构类。
- 它提供了一些像run_set()的这种方法,来充当了UVM世界中和核心角色。
- 在uvm_pkg中,有且只有一个顶层类uvm_root所例化的对象,即uvm_top。
- uvm_top承担的核心职责包括
- 作为隐形的uvm世界顶层,任何其它的组件实例都在它之下,通过创建组件时指定parent来构成层次。
- 如果parent设定为null,那么它将作为uvm_top的子组件。
- phase控制。控制所有组件的phase顺序
- 索引功能。通过层次名称来索引组件实例。
- 报告配置。通过uvm_top来全局配置报告的繁简度(verbosity)
- 全局报告设备。由于可以全局访问到uvm_top实例,因此uvm报告设备在组件内部和组件外部都可以访问
通过uvm_top调用方法run_test(test_name),uvm_top做了如下的初始化:
- 得到正确的test_name
- 初始化objection机制,控制仿真退出
- 创建uvm_test_op实例
- 调用phase控制方法,安排所有组件的phase方法执行顺序
- 等待所有phase执行结束,关闭phase控制进程
- 报告综合和结束仿真
- UVM-1.1之后,结束仿真的机制有且只有一种,那就是利用objection挂机机制来控制仿真结束。
- uvm_objection类提供了一种所有component和sequence共享的计数器。如果所有组件挂起objection,
那么它还应该记得落下objection
- 参与到objection机制中的参与组件,可以独立的各自挂起objection,来防止run phase退出。但是
只有这些组件都落下objection后,uvm_objection共享的counter共享counter才会变为0,这意味
run phase退出的条件满足,因此可以退出run phase。
- UVM仿真结束
- 对于uvm_objection类,用来反停止的控制方法包括:
- raise_objection(uvm_objection obj = null,string description = "",int count = 1)挂机
objection
- drop_objection(uvm_objection obj = null,string description = "",int count = 1)落下
objection
- set_drain_time(uvm_objection obj = null,time drain)设置退出时间
- 对着几种方法,在实际应用中的建议有:
- 对于component()而言,用户可以在run_phase()中使用
- 用户最好为description字符串参数提供说明,这有利于后期的调试。
- 对于uvm_top或者uvm_test_top应该尽可能少地使用set_drain_time()。
- uvm_pkg::uvm_test_done实例会在test1的run_phase()执行完毕之后,才会退出run phase。
- 这得益于test1::run_phase()在仿真一开始就挂起了objection,而在执行完毕之后才落下了objection
这时uvm_pkg::uvm_test_done认为run phase已经可以退出,进而转向下一个extract phase。
- 直到退出所有phase之后,UVM进入了报告总结阶段。
- 那么如果没有挂机objection,UVM仿真会怎么样呢?直接进入下一个phase。
6 config机制
6.1 概述
- 在验证环境的创建过程build phase中,除了组件的实例化,配置也是必不可少的。
- 为了验证环境的复用性,通过外部的参数配置,使得环境在创建时可以根据不同参数来选择创建的组件类型、组件实例数目、组件之间的连接以及组件的运行模式等。
- 在更细致的环境调节(environment tuning)中有更多的多变量需要配置,例如for-loop的阈值、字符串名称、随机变量的生成比重等。
- 比起重新编译来调节变量,如果在仿真中可以通过变量设置来修改环境,那么久更灵活了,而UVM config机制正提供了这样的便捷。
- 在UVM提供了uvm_config_db配置类以及集中方便的变量设置方法俩实现仿真时的环境控制,常见的uvm_config_db类的使用方式包括。
(1)传递vritual interface到环境中
(2)设置单一变量值,例如int、string、enum等
(3)传递配置对象(config object)到环境
uvm_config_db#(T)::set(uvm_component cntct,string inst_name,string field_name,T value);
uvm_config_db#(T)::get(uvm_component cntxt,string inst_name,string field_name,inout T value);
//T为参数类,set为顶层放进去,get为底层拿出来 uvm_component为句柄,string1为实例字符串,string2为变量名称,T value为实际值。
6.2 interface传递
- interface传递可以更好地解决了连接硬件世界和软件世界。
- 而在之前SV验证模块中,虽然SV可以通过层次化的interface的索引来完成了传递,但是这种方式不利于软件环境的封装和复用。
- UVM的uvm_config_db使得接口的传递和获取彻底分离开来。(可以实现任何层次之间的传递)
- 在实现接口传递的过程中需要注意:
- 接口传递应该发生在run_test()之前。这保证了在进入build phase之前,virtual interface已经被传递到uvm_config_db中。
- 用户应当把interface与virtual interface的声明区分开来,在传递过程中的类型应当为virtual interface,即实际接口的句柄。
interface intf1; //interface的定义
logic enable = 0;
endinterface
class comp1 extends uvm_component; //定义
`uvm_component_utils(comp1) //注册
virtual intf1 vif;
...
function void build_phase(uvm_phase phase);
if(!uvm_config_db#(virtual intf1)::get(this,"","vif",vif))begin//this 表示句柄为c1,路径为uvm_test/test1/c1,vif表示获得的数值
`uvm_errer("GETVIF","no virtual interface is assgined")
end
`uvm_info("SETVAL",$sformatf("vif.enable is %b before set",vif.enable),UVM_LOW)
vif.enable = 1;
`uvm_info("SETVAL",$sformatf("vif.enable is %b after set",vif.enable),UVM_LOW)
endfunction
endclass
calss test1 extends uvm_test;
`uvm_component_utils(test1)
comp1 c1;
...
endclass
intf1 intf();
initial begin
uvm_config_db#(virtual intf1)::set(uvm_root::get(),"uvm_test_top.c1","vif",intf);//get和set相对应
run_test("test1");
end
UVM_INFO @ 0:reporter [RNTST] Running test test1...
UVM_INFO @ 0:uvm_test_top.c1 [SETVAL] vif.enable is 0 before set
UVM_INFO @ 0:uvm_test_top.c1 [SETVAL] vif.enable is 1 after set
//set和get的路径,类型都需要保持一致
6.3 变量设置
在各个test中,可以在build phase对底层组件的变量加以配置,进而在环境例化之前完成配置,使得环境可以按照预期运行。
class comp1 extends uvm_component;
`uvm_component_utils(comp1)
int vall = 1;
string str1 = "null";
...
function void build_phase(uvm_phase phase);
`uvm_info("SETVAL",$sformatf("vall is %d before get",vall),UVM_LOW)
`uvm_info("SETVAL",$sformatf("str1 is %s before get",str1),UVM_LOW)
uvm_config_db#(int)::get(this,"","vall",vall);//前三个表示层次关系
uvm_config_db#(string)::get(this,"","str1",str1);
`uvm_info("SETVAL".$sformatf("vall is %d after get",vall),UVM_LOW)
`uvm_info("SETVAL",$sformatf("str1 is %s after get",str1),UVM_LOW)
endfunction
endclass
class test1 extends uvm_test;
`uvm_component_utils(test1)
comp1 c1;
...
function void build_phase(uvm_phase phase);
uvm_config_db#(int)::set(this,"c1","vall",100);
uvm_config_db#(string)::set(this,"c1","str1","comp1");
c1 = comp1::type_id::create("c1",this);//先做set再做创建
endfunction
endclass
输出结果
UVM_INFO @ 0 : uvm_test_top.c1 [SETVAL] vall is 1 before get
UVM_INFO @ 0 : uvm_test_top.c1 [SETVAL] str1 is null before get
UVM_INFO @ 0 : uvm_tets_top.c1 [SETVAL] vall is 100 after get
UVM_INFO @ 0 : UVM_TEST_TOP.C1 [setval] str1 is comp1 after get
6.4 config object机制
- 在test配置中,需要配置的参数不只是数量多,而且可能还分属于不同的组件。
- 那么如果对这么多层次中的变量做出类似上面的变量设置,那么需要更多的代码,容易出错还不易于复用,升值底层组件的变量被删除后,也无法通过uvm_config_db::set()得知配置是否成功。
- 然后如果将每个组件中的变量加以整合,首先放置到一个uvm_object中,再对中心化的配置对象进行传递,那么将会更有利于整体环境的修改维护。
class config1 extends uvm_object;
int vall = 1;
int str1 = "null";
`uvm_object_utils(config1)
...
endclass
class comp1 extends uvm_component;
`uvm_component_utils(comp1)
config1 cfg;
...
function void build_phase(uvm_phase phase);
`uvm_object tmp;
uvm_config_db# (uvm_object)::get(this,"","cfg",tmp);
void'($cast(cfg,tmp));
`uvm_info("SETVAL",$sformatf("cfg.vall is %d after get",cfg.vall),UVM_LOW)
`uvm_info("SETVAL",$sformatf("cfg.str1 is %s after get",cfg.str1),UVM_LOW)
endfunction
endclass
class test1 extends uvm_test;
`uvm_component_utils(test1)
comp1 c1,c2;
config1 cfg1,cfg2;
...
function void build_phase(uvm_phase phase);
cfg1 = config1::type_id::create("cfg1");
cfg2 = config1::type_id::create("cfg2");
cfg1.val1 = 30;
cfg1.str1 = "c1";
cfg2.val1 = 50;
cfg2.str1 = "c2";
uvm_config_db#(uvm_object)::set(this,"c1","cfg",cfg1);
uvm_config_db#(uvm_object)::set(this,"c2","cfg",cfg2);
c1 = comp1::type_id::create("c1",this);
c2 = comp1::type_id::create("c2",this);
endfunction
endclass
输出结果为:
UVM_INFO @ 0:uvm_test_top.c1 [SETVAL] cfg.vall is 30 after get
UVM_INFO @ 0:uvm_test_top.c1 [SETVAL] cfg.str1 is c1 after get
UVM_INFO @ 0:uvm_test_top.c2 [SETVAL] cfg.vall is 50 after get
UVM_INFO @ 0:uvm_test_top.c2 [SETVAL] cfg.str1 is c2 after get
6.5 总结
- 在使用uvm_config_db::set()/get()时,实际发生了这些后台操作:
- uvm_config_db::set()通过层次和变量名,将这些信息放置到uvm_pkg唯一的全局变量uvm_pkg::uvm_resources。
- 全局变量uvm_resources用来存储和释放配置资源信息(resource information)。uvm_resources是uvm_resource_pool类的全局唯一实例,该实例中有两个resource数组用来存放配置信息,这两个数组中一个由层次名字索引,一个由类型索引,通过这两个关联数组可以存放通过层次配置的信息。
- 同时,底层组件也可以通过层次或者类型来取得来自高层的配置信息。这种方式使信息的配置和获取得到剥离,便于调试复用。
- 在使用uvm_config_db::get()方法时,通过传递的参数构成索引层次,然后在uvm_resource已有的配置信息池中索引该配置,如果索引到,方法返回1,否则返回0。
7 消息管理
7.1 概述
- 在一个号的验证系统应该具有消息管理特性,它们是:
- 通过一个标准化的方式打印信息
- 过滤(重要级别)信息
- 打印通道
- 这些特性在UVM中均有支持,UVM提供了一系列丰富的类和方法来生成和过滤消息:
- 消息方法
- 消息处理
- 消息机制
7.2 消息方法
- 在UVM环境中或者环境外,只要有引入uvm_pkg,均可以通过下面的方法来按照消息的严重级别和冗余度来打印消息。
function void uvm_report_info(string id,string message,int verbosity = UVM_MEDIUM, string filename = "",int line = 0);
function void uvm_report_warning(string id,string message,int verbosity = UVM_MEDIUM,string filename = "", int line = 0);
function void uvm_report_error(string id, string message, int verbosity = UVM_LOW, string filename = "", int line = 0);
function void uvm_report_fatal(string id, string message, int verbosity = UVM_NONE, string filename = "", int line = 0);
- 四个消息函数有若干共同的信息,它们是严重级别(severity)、冗余度(verbosity)、消息ID、消息、消息、文件名和行号:
- 严重级别:从函数名本身也可以得出,这四个严重级别分别是UVM_INFO、UVM_WARNING、UVM_ERROR、UVM_FATAL。不同的严重激烈在打印消息中也会有不同的指示来区别,同时仿真器对于不同严重级别消息的处理方式也不一样。例如对于UVM_FATAL的消息,默认情况下仿真会停止。
- 消息ID:该ID可以是任意的字符串,用来标记信息。这个标记会同消息本身打印出来,同时不同的标记也可以用来进行消息处理。
- 消息:即消息文本的主体。
- 冗余度:冗余度与消息处理中的过滤直接相关。冗余度的设置如果低于过滤的开关,那么该消息会打印出来,否则不会打印出来,但是无论信息是否会被打印出来,这斗鱼对消息采取的措施没有关系,例如仿真停止。
- 文件名和行号:这些信息用来提供信息发生时所在的文件和行号。用户可以使用默认值,而UVM后台会自动填补它们原本的文件名和行号,同时也在打印时将文件名和行号输出。
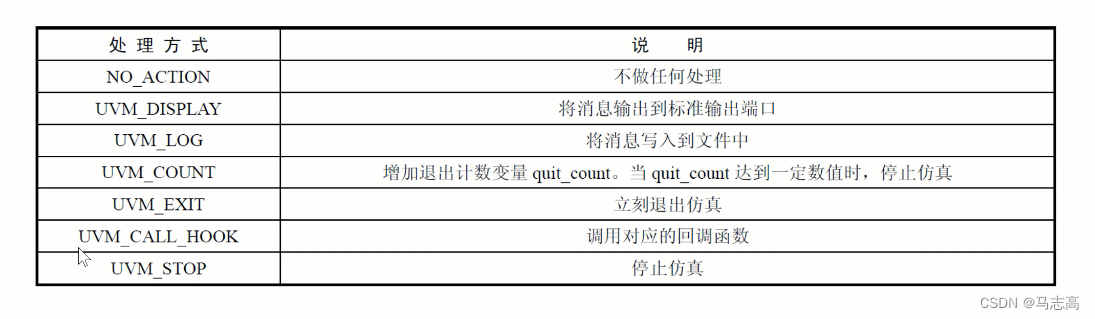
7.3 消息处理
- 与每一条消息对应的是如何处理这些消息。通常情况下,消息处理的方法是同消息的严重级别相对应的。如果用户有额外的需求,也可以修改对各个严重级别的消息处理方式。
- 而不同的严重级别消息,用户可以使用默认的消息处理方式。

7.4 消息宏
- 如果要做自定义的消息处理方式,用户可以通过uvm_report_object类提供的方法进行配置。
- uvm_report_object类是间于uvm_object类于uvm_component类之间的中间类,它的主要功能是完善消息打印和管理。
- UVM也提供了一些宏来对应上面的消息方法,用户也可以使用这些宏来处理消息。

7.5 消息机制
- 消息处理是由uvm_report_handler类来完成的,而每一个uvm_report_object类中都有一个uvm_report_handler实例。
- 上面的uvm_report_object消息处理方法或者uvm_component消息处理方法,都是针对这些uvm_report_handler做出的配置。
- 除了上面的常见的方法,用户还可以做出更高级的消息控制。例如,当UVM_ERROR出现之后,仿真默认会停止,这是由于默认了UVM_ERROR的处理方式使UVM_count数量达到上限(默认为1),即停止仿真。可以通过set_max_quit_count来修改UVM_COUNT值。
回调函数
- 消息用户处理信息时还希望做出额外的处理,这时回调函数就显得很有必要了,uvm_report_object类提供下面的回调函数满足用户更多的需求:
- function bit report_hook(string id, string message, int verbosity, string filename, int line);
- function bit report_info_hook(string id, string message, int verbosity, string filename, int line)
- function bit report_warning_hook(string id, string message, int verbosity, string filename, int line)
- function bit report_error_hook(string if, string message, int verbosity, string filename, int line);
- function bit report_fatal_hook(string id, string message, int verbosity, string filename, int line);
class test1 extends uvm_test;
integer f;
`uvm_componet_utils(test1)
...
function void build_phase(uvm_phase phase);
set_report_severity_action(UVM_ERROR,UVM_DISPLAY | UVM_CALL_HOOK);
set_report_verbosity_level(UVM_LOW);
endfunction
task run_phase(vum_phase phase);
uvm_report_info("RUN","info1",UVM_MEDIUM);
uvm_report_info("RUN","info2",UVM_LOW);
uvm_report_warning("RUN","warning1",UVM_LOW);
uvm_report_error("RUN","error1",UVM_LOW);
uvm_report_error("RUN","error2",UVM_HIGH);
uvm_report_error("RUN","error3",UVM_LOW);
endtask
function void report_phase(uvm_phase phase);
$fclose(f);
endfunction
function it report_hook(string id,string message,int verbosity, string filename, int line);
uvm_report_info("RPTHOOK",$sformatf("%s:%s",id, message),UVM_LOW);
return 1;
endfunction
function bit report_error_hook(string id,string message,int verbosity,string filename,int line);
uvm_report_info("ERRHOOK",$sformatf("%s : %s",id,message),UVM_LOW);
return 1;
endfunction
endclass
- report_hook()函数通过结合消息管理时的UVM_CALL_HOOK参数,结合用户自定义的回调函数,就可以实现更丰富的配置。
- 这样用户在调用回调函数时,首先会调用report_hook()函数,接下来才按照severity级别来选择更细致的回调函数report_SEVERITY_hook()。
- 默认情况下,report_hook()函数返回值为1,进而转入severity hook函数。
- 如果report_hook()函数由用户自定义且返回0的话,那么后续report_SEVERITY_hook()函数不会执行。
- 除了每一个uvm_report_object中都内置一个uvm_report_handler实例之外,所有的uvm_report_handler实质也都依赖于uvm_pkg中,uvm_report_sever的唯一实例,但是该实例并没有作为全局变量,直接暴露给用户,需要用户自行调用uvm_report_sever::get_sever()方法来获取。
- uvm_report_sever是一个全局的消息处理设别,用来处理从所有uvm_report_handler中产生的消息。这个唯一的report sever之所以没有暴露在uvm_pkg中供用户使用,一个原因在与对消息的处理方式。


![[附源码]计算机毕业设计springboot云南美食管理系统](https://img-blog.csdnimg.cn/7971d0b780fd403ab8e344b34c3aac60.png)



![[附源码]计算机毕业设计springboot影评网站系统](https://img-blog.csdnimg.cn/7bd4e66a4d814653b251ea6bdc9449e8.png)

![[附源码]计算机毕业设计springboot医院门诊管理信息系统](https://img-blog.csdnimg.cn/bad87125f56d40d6abda2d284cc72b2c.png)