文章目录
- 前言
- 一、解决问题
- 二、基本原理
- 三、添加方法
- 四、总结
前言
作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!关注免费领取深度学习算法学习资料!
一、解决问题
FPN旨在与骨干网路输出的多分辨率特征进行信息聚合,它是目标检测非常重要且有效的部件。传统的FPN引入了一个top-down路径融合多尺度特征;PAFPN则在FPN基础上引入了额外的bottom-up路径进行信息聚合,也是YOLO算法的融合方式;BiFPN则移除了仅有一个输入边的节点,并在同级节点之间添加了跳过连接,此前已经进行实现,进行修改,有了一定的效果。💡🎈☁️5. 改进特征融合网络PANET为BIFPN。GiraffeDet所提GFPN提供了另一种对高层与底层信息高效交互的方案。
二、基本原理
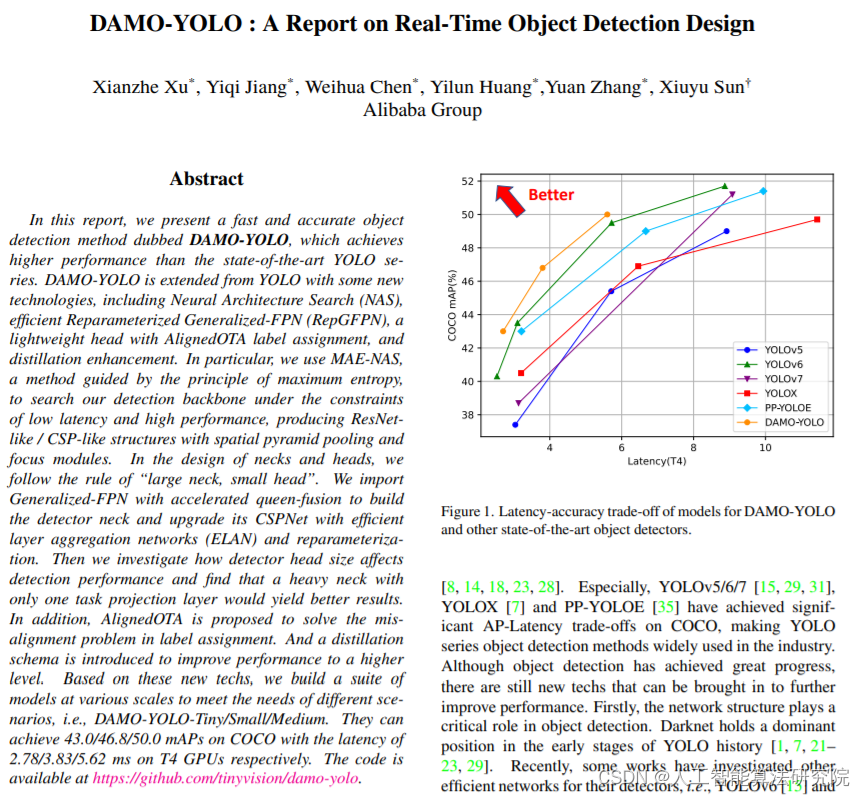
在FPN(Feature Pyramid Network)中,多尺度特征融合旨在对从backbone不同stage输出的特征进行聚合,从而增强输出特征的表达能力,提升模型性能。传统的FPN引入top-to-down的路径来融合多尺度特征。考虑到单向信息流的限制,PAFPN增加了一个额外的自底向上的路径聚合网络,然而增加了计算成本。为了降低计算量,YOLO系列检测网络选择带有CSPNet的PAFPN来融合来自backbone输出的多尺度特征。
我们在ICLR2022的工作GiraffeDet中提出了新颖的Light-Backbone Heavy-Neck结构并达到了SOTA性能,原因在于给出的neck结构GFPN(Generalized FPN)能够充分交换高级语义信息和低级空间信息。在GFPN中,多尺度特征融合发生在前一层和当前层的不同尺度特征中,此外,log_2(n)的跨层连接提供了更有效的信息传输,可以扩展到更深的网络。
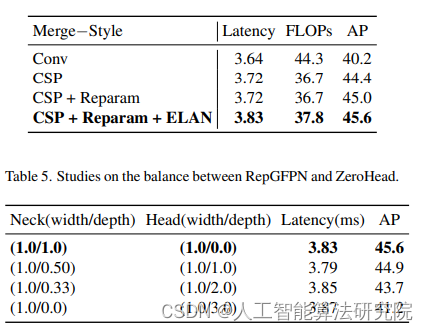
因此,我们尝试将GFPN引入到DAMO-YOLO中,相比于PANet,我们取得了更高的精度,这是在预期之中的。然而与之同时,GFPN带来了模型推理时延的增加,使得精度/时延的权衡并未取得较大的优势。通过对原始GFPN结构的分析,我们将原因归结为以下几个方面:(1)不同尺度特征共享相同通道数,导致难以给出一个最优通道数来保证高层低分辨率特征和低层高分辨率特征具有同样丰富的表达能力;(2)GFPN采用Queen-Fusion强化特征之间的融合,而Queen-Fusion包含大量的上采样和下采样操作来实现不同尺度特征的融合,极大影响推理速度;(3)GFPN中使用的3x3卷积进行跨尺度特征融合的效率不高,不能满足轻量级计算量的需求,需要进一步优化。
直接采用GFPN对YOLO系列方案中的PAFPN进行替换后可以取得更高的性能,但其延迟也变得更高。通过分析,主要原因可以归因到以下几个维度:1.不同尺度的特征具有相同的维度;2.queen融合操作无法满足实时检测模型的需求;3.基于卷积的跨尺度融合不够高效。
三、添加方法
第一步:确定添加的位置,作为即插即用的注意力模块,可以添加到YOLOv7网络中的任何地方。
第二步:common.py构建模块。部分代码如下,关注文章末尾,私信后领取。
待更新
第三步:yolo.py中注册模块。
待更新
第四步:修改yaml文件,将模块后加入该模块。
第五步:将train.py中改为本文的yaml文件即可,开始训练。
四、总结
结 果:本人在遥感数据集上进行实验,有涨点效果。需要请关注留言。
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
YOLO系列算法改进方法 | 目录一览表
💡🎈☁️1. 添加SE注意力机制
💡🎈☁️2.添加CBAM注意力机制
💡🎈☁️3. 添加CoordAtt注意力机制
💡🎈☁️4. 添加ECA通道注意力机制
💡🎈☁️5. 改进特征融合网络PANET为BIFPN
💡🎈☁️6. 增加小目标检测层
💡🎈☁️7. 损失函数改进
💡🎈☁️8. 非极大值抑制NMS算法改进Soft-nms
💡🎈☁️9. 锚框K-Means算法改进K-Means++
💡🎈☁️10. 损失函数改进为SIOU
💡🎈☁️11. 主干网络C3替换为轻量化网络MobileNetV3
💡🎈☁️12. 主干网络C3替换为轻量化网络ShuffleNetV2
💡🎈☁️13. 主干网络C3替换为轻量化网络EfficientNetv2
💡🎈☁️14. 主干网络C3替换为轻量化网络Ghostnet
💡🎈☁️15. 网络轻量化方法深度可分离卷积
💡🎈☁️16. 主干网络C3替换为轻量化网络PP-LCNet
💡🎈☁️17. CNN+Transformer——融合Bottleneck Transformers
💡🎈☁️18. 损失函数改进为Alpha-IoU损失函数
💡🎈☁️19. 非极大值抑制NMS算法改进DIoU NMS
💡🎈☁️20. Involution新神经网络算子引入网络
💡🎈☁️21. CNN+Transformer——主干网络替换为又快又强的轻量化主干EfficientFormer
💡🎈☁️22. 涨点神器——引入递归门控卷积(gnConv)
💡🎈☁️23. 引入SimAM无参数注意力
💡🎈☁️24. 引入量子启发的新型视觉主干模型WaveMLP(可尝试发SCI)
💡🎈☁️25. 引入Swin Transformer
💡🎈☁️26. 改进特征融合网络PANet为ASFF自适应特征融合网络
💡🎈☁️27. 解决小目标问题——校正卷积取代特征提取网络中的常规卷积
💡🎈☁️28. ICLR 2022涨点神器——即插即用的动态卷积ODConv
💡🎈☁️29. 引入Swin Transformer v2.0版本
💡🎈☁️30. 引入10月4号发表最新的Transformer视觉模型MOAT结构
💡🎈☁️31. CrissCrossAttention注意力机制
💡🎈☁️32. 引入SKAttention注意力机制
💡🎈☁️33. 引入GAMAttention注意力机制
💡🎈☁️34. 更换激活函数为FReLU
💡🎈☁️35. 引入S2-MLPv2注意力机制
💡🎈☁️36. 融入NAM注意力机制
💡🎈☁️37. 结合CVPR2022新作ConvNeXt网络
💡🎈☁️38. 引入RepVGG模型结构
💡🎈☁️39. 引入改进遮挡检测的Tri-Layer插件 | BMVC 2022
💡🎈☁️40. 轻量化mobileone主干网络引入
💡🎈☁️41. 引入SPD-Conv处理低分辨率图像和小对象问题
💡🎈☁️42. 引入V7中的ELAN网络
💡🎈☁️43. 结合最新Non-local Networks and Attention结构
💡🎈☁️44. 融入适配GPU的轻量级 G-GhostNet
![[附源码]计算机毕业设计springboot云南美食管理系统](https://img-blog.csdnimg.cn/7971d0b780fd403ab8e344b34c3aac60.png)



![[附源码]计算机毕业设计springboot影评网站系统](https://img-blog.csdnimg.cn/7bd4e66a4d814653b251ea6bdc9449e8.png)

![[附源码]计算机毕业设计springboot医院门诊管理信息系统](https://img-blog.csdnimg.cn/bad87125f56d40d6abda2d284cc72b2c.png)

![[附源码]计算机毕业设计游戏商城平台论文Springboot程序](https://img-blog.csdnimg.cn/6b78cf0aa1414e3d88a0cd288d73a13b.png)
![[附源码]计算机毕业设计springboot线上评分分享平台](https://img-blog.csdnimg.cn/dd8f133beb584a04b4f0c024100aa160.png)