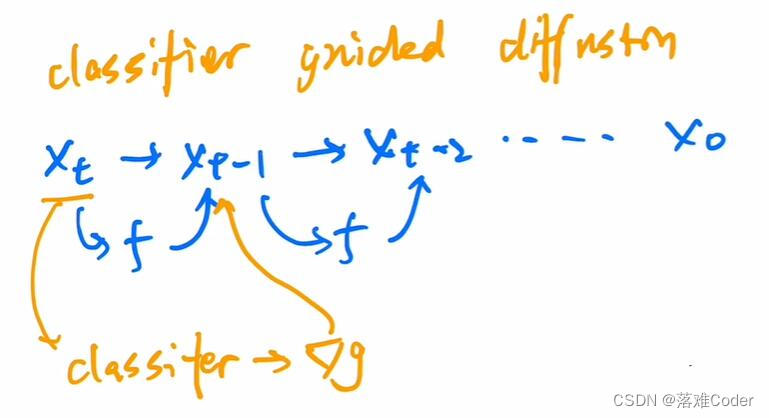
一、flink可识别的source分类
Sources are where your program reads its input from. You can attach a source to your program by using StreamExecutionEnvironment.addSource(sourceFunction). Flink comes with a number of pre-implemented source functions, but you can always write your own custom sources by implementing the SourceFunction for non-parallel sources, or by implementing the ParallelSourceFunction interface or extending the RichParallelSourceFunction for parallel sources.
There are several predefined stream sources accessible from the StreamExecutionEnvironment:
File-based:
-
readTextFile(path)- Reads text files, i.e. files that respect theTextInputFormatspecification, line-by-line and returns them as Strings. -
readFile(fileInputFormat, path)- Reads (once) files as dictated by the specified file input format. -
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)- This is the method called internally by the two previous ones. It reads files in thepathbased on the givenfileInputFormat. Depending on the providedwatchType, this source may periodically monitor (everyintervalms) the path for new data (FileProcessingMode.PROCESS_CONTINUOUSLY), or process once the data currently in the path and exit (FileProcessingMode.PROCESS_ONCE). Using thepathFilter, the user can further exclude files from being processed.IMPLEMENTATION:
Under the hood, Flink splits the file reading process into two sub-tasks, namely directory monitoring and data reading. Each of these sub-tasks is implemented by a separate entity. Monitoring is implemented by a single, non-parallel (parallelism = 1) task, while reading is performed by multiple tasks running in parallel. The parallelism of the latter is equal to the job parallelism. The role of the single monitoring task is to scan the directory (periodically or only once depending on the
watchType), find the files to be processed, divide them in splits, and assign these splits to the downstream readers. The readers are the ones who will read the actual data. Each split is read by only one reader, while a reader can read multiple splits, one-by-one.IMPORTANT NOTES:
-
If the
watchTypeis set toFileProcessingMode.PROCESS_CONTINUOUSLY, when a file is modified, its contents are re-processed entirely. This can break the “exactly-once” semantics, as appending data at the end of a file will lead to all its contents being re-processed. -
If the
watchTypeis set toFileProcessingMode.PROCESS_ONCE, the source scans the path once and exits, without waiting for the readers to finish reading the file contents. Of course the readers will continue reading until all file contents are read. Closing the source leads to no more checkpoints after that point. This may lead to slower recovery after a node failure, as the job will resume reading from the last checkpoint.
-
Socket-based:
socketTextStream- Reads from a socket. Elements can be separated by a delimiter.
Collection-based:
-
fromCollection(Collection)- Creates a data stream from the Java Java.util.Collection. All elements in the collection must be of the same type. -
fromCollection(Iterator, Class)- Creates a data stream from an iterator. The class specifies the data type of the elements returned by the iterator. -
fromElements(T ...)- Creates a data stream from the given sequence of objects. All objects must be of the same type. -
fromParallelCollection(SplittableIterator, Class)- Creates a data stream from an iterator, in parallel. The class specifies the data type of the elements returned by the iterator. -
generateSequence(from, to)- Generates the sequence of numbers in the given interval, in parallel.
Custom:
addSource- Attach a new source function. For example, to read from Apache Kafka you can useaddSource(new FlinkKafkaConsumer08<>(...)). See connectors for more details.
二、日常常用实战。
2.1 文件集合类读取数据
已上所有加载数据, 大多都能从接口类本身提示中获取格式,进行调用,比如:
-
readTextFile(path)-TextInputFormat逐行读取文本文件,即符合规范的文件,并将其作为字符串返回。 -
readFile(fileInputFormat, path)-根据指定的文件输入格式读取(一次)文件。 -
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)-这是前两个内部调用的方法。它path根据给定的读取文件fileInputFormat。根据提供的内容watchType,此源可以定期(每intervalms)监视路径中的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或处理一次路径中当前的数据并退出(FileProcessingMode.PROCESS_ONCE)。使用pathFilter,用户可以进一步从文件中排除文件。
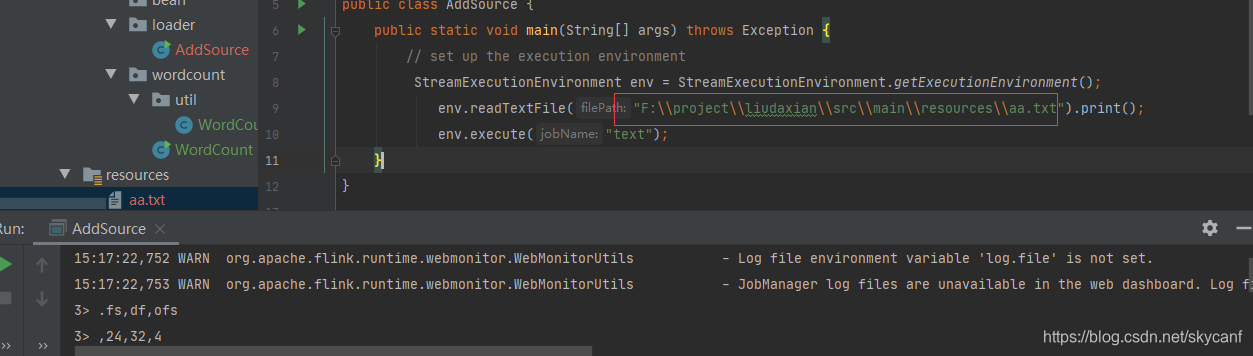
2.2 mysql 读写
flink官网对于上述规定api获取数据之外,其他加载数据方式推荐使用
Custom:
addSource- Attach a new source function. For example, to read from Apache Kafka you can useaddSource(new FlinkKafkaConsumer08<>(...)). See connectors for more details.
如下api,参数为sourcefunction,只要自定义的接口实现即可
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function) {
return addSource(function, "Custom Source");
}SourceFunction接口的实现类如下

接口本身方法如下
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.streaming.api.functions.source;
import org.apache.flink.annotation.Public;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.functions.Function;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.functions.TimestampAssigner;
import org.apache.flink.streaming.api.watermark.Watermark;
import java.io.Serializable;
/**
* Base interface for all stream data sources in Flink. The contract of a stream source
* is the following: When the source should start emitting elements, the {@link #run} method
* is called with a {@link SourceContext} that can be used for emitting elements.
* The run method can run for as long as necessary. The source must, however, react to an
* invocation of {@link #cancel()} by breaking out of its main loop.
*
* <h3>CheckpointedFunction Sources</h3>
*
* <p>Sources that also implement the {@link org.apache.flink.streaming.api.checkpoint.CheckpointedFunction}
* interface must ensure that state checkpointing, updating of internal state and emission of
* elements are not done concurrently. This is achieved by using the provided checkpointing lock
* object to protect update of state and emission of elements in a synchronized block.
*
* <p>This is the basic pattern one should follow when implementing a checkpointed source:
*
* <pre>{@code
* public class ExampleCountSource implements SourceFunction<Long>, CheckpointedFunction {
* private long count = 0L;
* private volatile boolean isRunning = true;
*
* private transient ListState<Long> checkpointedCount;
*
* public void run(SourceContext<T> ctx) {
* while (isRunning && count < 1000) {
* // this synchronized block ensures that state checkpointing,
* // internal state updates and emission of elements are an atomic operation
* synchronized (ctx.getCheckpointLock()) {
* ctx.collect(count);
* count++;
* }
* }
* }
*
* public void cancel() {
* isRunning = false;
* }
*
* public void initializeState(FunctionInitializationContext context) {
* this.checkpointedCount = context
* .getOperatorStateStore()
* .getListState(new ListStateDescriptor<>("count", Long.class));
*
* if (context.isRestored()) {
* for (Long count : this.checkpointedCount.get()) {
* this.count = count;
* }
* }
* }
*
* public void snapshotState(FunctionSnapshotContext context) {
* this.checkpointedCount.clear();
* this.checkpointedCount.add(count);
* }
* }
* }</pre>
*
*
* <h3>Timestamps and watermarks:</h3>
* Sources may assign timestamps to elements and may manually emit watermarks.
* However, these are only interpreted if the streaming program runs on
* {@link TimeCharacteristic#EventTime}. On other time characteristics
* ({@link TimeCharacteristic#IngestionTime} and {@link TimeCharacteristic#ProcessingTime}),
* the watermarks from the source function are ignored.
*
* @param <T> The type of the elements produced by this source.
*
* @see org.apache.flink.streaming.api.TimeCharacteristic
*/
@Public
public interface SourceFunction<T> extends Function, Serializable {
/**
* Starts the source. Implementations can use the {@link SourceContext} emit
* elements.
*
* <p>Sources that implement {@link org.apache.flink.streaming.api.checkpoint.CheckpointedFunction}
* must lock on the checkpoint lock (using a synchronized block) before updating internal
* state and emitting elements, to make both an atomic operation:
*
* <pre>{@code
* public class ExampleCountSource implements SourceFunction<Long>, CheckpointedFunction {
* private long count = 0L;
* private volatile boolean isRunning = true;
*
* private transient ListState<Long> checkpointedCount;
*
* public void run(SourceContext<T> ctx) {
* while (isRunning && count < 1000) {
* // this synchronized block ensures that state checkpointing,
* // internal state updates and emission of elements are an atomic operation
* synchronized (ctx.getCheckpointLock()) {
* ctx.collect(count);
* count++;
* }
* }
* }
*
* public void cancel() {
* isRunning = false;
* }
*
* public void initializeState(FunctionInitializationContext context) {
* this.checkpointedCount = context
* .getOperatorStateStore()
* .getListState(new ListStateDescriptor<>("count", Long.class));
*
* if (context.isRestored()) {
* for (Long count : this.checkpointedCount.get()) {
* this.count = count;
* }
* }
* }
*
* public void snapshotState(FunctionSnapshotContext context) {
* this.checkpointedCount.clear();
* this.checkpointedCount.add(count);
* }
* }
* }</pre>
*
* @param ctx The context to emit elements to and for accessing locks.
*/
void run(SourceContext<T> ctx) throws Exception;
/**
* Cancels the source. Most sources will have a while loop inside the
* {@link #run(SourceContext)} method. The implementation needs to ensure that the
* source will break out of that loop after this method is called.
*
* <p>A typical pattern is to have an {@code "volatile boolean isRunning"} flag that is set to
* {@code false} in this method. That flag is checked in the loop condition.
*
* <p>When a source is canceled, the executing thread will also be interrupted
* (via {@link Thread#interrupt()}). The interruption happens strictly after this
* method has been called, so any interruption handler can rely on the fact that
* this method has completed. It is good practice to make any flags altered by
* this method "volatile", in order to guarantee the visibility of the effects of
* this method to any interruption handler.
*/
void cancel();
// ------------------------------------------------------------------------
// source context
// ------------------------------------------------------------------------
/**
* Interface that source functions use to emit elements, and possibly watermarks.
*
* @param <T> The type of the elements produced by the source.
*/
@Public // Interface might be extended in the future with additional methods.
interface SourceContext<T> {
/**
* Emits one element from the source, without attaching a timestamp. In most cases,
* this is the default way of emitting elements.
*
* <p>The timestamp that the element will get assigned depends on the time characteristic of
* the streaming program:
* <ul>
* <li>On {@link TimeCharacteristic#ProcessingTime}, the element has no timestamp.</li>
* <li>On {@link TimeCharacteristic#IngestionTime}, the element gets the system's
* current time as the timestamp.</li>
* <li>On {@link TimeCharacteristic#EventTime}, the element will have no timestamp initially.
* It needs to get a timestamp (via a {@link TimestampAssigner}) before any time-dependent
* operation (like time windows).</li>
* </ul>
*
* @param element The element to emit
*/
void collect(T element);
/**
* Emits one element from the source, and attaches the given timestamp. This method
* is relevant for programs using {@link TimeCharacteristic#EventTime}, where the
* sources assign timestamps themselves, rather than relying on a {@link TimestampAssigner}
* on the stream.
*
* <p>On certain time characteristics, this timestamp may be ignored or overwritten.
* This allows programs to switch between the different time characteristics and behaviors
* without changing the code of the source functions.
* <ul>
* <li>On {@link TimeCharacteristic#ProcessingTime}, the timestamp will be ignored,
* because processing time never works with element timestamps.</li>
* <li>On {@link TimeCharacteristic#IngestionTime}, the timestamp is overwritten with the
* system's current time, to realize proper ingestion time semantics.</li>
* <li>On {@link TimeCharacteristic#EventTime}, the timestamp will be used.</li>
* </ul>
*
* @param element The element to emit
* @param timestamp The timestamp in milliseconds since the Epoch
*/
@PublicEvolving
void collectWithTimestamp(T element, long timestamp);
/**
* Emits the given {@link Watermark}. A Watermark of value {@code t} declares that no
* elements with a timestamp {@code t' <= t} will occur any more. If further such
* elements will be emitted, those elements are considered <i>late</i>.
*
* <p>This method is only relevant when running on {@link TimeCharacteristic#EventTime}.
* On {@link TimeCharacteristic#ProcessingTime},Watermarks will be ignored. On
* {@link TimeCharacteristic#IngestionTime}, the Watermarks will be replaced by the
* automatic ingestion time watermarks.
*
* @param mark The Watermark to emit
*/
@PublicEvolving
void emitWatermark(Watermark mark);
/**
* Marks the source to be temporarily idle. This tells the system that this source will
* temporarily stop emitting records and watermarks for an indefinite amount of time. This
* is only relevant when running on {@link TimeCharacteristic#IngestionTime} and
* {@link TimeCharacteristic#EventTime}, allowing downstream tasks to advance their
* watermarks without the need to wait for watermarks from this source while it is idle.
*
* <p>Source functions should make a best effort to call this method as soon as they
* acknowledge themselves to be idle. The system will consider the source to resume activity
* again once {@link SourceContext#collect(T)}, {@link SourceContext#collectWithTimestamp(T, long)},
* or {@link SourceContext#emitWatermark(Watermark)} is called to emit elements or watermarks from the source.
*/
@PublicEvolving
void markAsTemporarilyIdle();
/**
* Returns the checkpoint lock. Please refer to the class-level comment in
* {@link SourceFunction} for details about how to write a consistent checkpointed
* source.
*
* @return The object to use as the lock
*/
Object getCheckpointLock();
/**
* This method is called by the system to shut down the context.
*/
void close();
}
}
自定义方式实现run方法 皆可以自己mock数据
比如以下:
public class SourceFromMySQL extends RichSourceFunction<Student> {
PreparedStatement ps;
private Connection connection;
/**
* open() 方法中建立连接,这样不用每次 invoke 的时候都要建立连接和释放连接。
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = MySQLUtil.getConnection("com.mysql.jdbc.Driver",
"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8",
"root",
"123456");
String sql = "select * from Student;";
ps = this.connection.prepareStatement(sql);
}
/**
* 程序执行完毕就可以进行,关闭连接和释放资源的动作了
*
* @throws Exception
*/
@Override
public void close() throws Exception {
super.close();
if (connection != null) { //关闭连接和释放资源
connection.close();
}
if (ps != null) {
ps.close();
}
}
/**
* DataStream 调用一次 run() 方法用来获取数据
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Student> ctx) throws Exception {
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
Student student = new Student(
resultSet.getInt("id"),
resultSet.getString("name").trim(),
resultSet.getString("password").trim(),
resultSet.getInt("age"));
ctx.collect(student);
}
}
@Override
public void cancel() {
}
}
util bean
public class Student {
public int id;
public String name;
public String password;
public int age;
}
public class MySQLUtil {
public static Connection getConnection(String driver, String url, String user, String password) {
Connection con = null;
try {
Class.forName(driver);
//注意,这里替换成你自己的mysql 数据库路径和用户名、密码
con = DriverManager.getConnection(url, user, password);
} catch (Exception e) {
System.out.println("-----------mysql get connection has exception , msg = "+ e.getMessage());
}
return con;
}
}
main方法调用
public class MySQLUtil {
public static Connection getConnection(String driver, String url, String user, String password) {
Connection con = null;
try {
Class.forName(driver);
//注意,这里替换成你自己的mysql 数据库路径和用户名、密码
con = DriverManager.getConnection(url, user, password);
} catch (Exception e) {
System.out.println("-----------mysql get connection has exception , msg = "+ e.getMessage());
}
return con;
}
}![[附源码]计算机毕业设计游戏商城平台论文Springboot程序](https://img-blog.csdnimg.cn/6b78cf0aa1414e3d88a0cd288d73a13b.png)
![[附源码]计算机毕业设计springboot线上评分分享平台](https://img-blog.csdnimg.cn/dd8f133beb584a04b4f0c024100aa160.png)





![[附源码]计算机毕业设计springboot疫情物资管理系统](https://img-blog.csdnimg.cn/aa1d05036a5a480cb327b537ca122d9a.png)

![[附源码]Python计算机毕业设计Django茂名特产销售商城网站](https://img-blog.csdnimg.cn/6ffe9a19a2484de2a8f9dcaa8f492322.png)
![[Java安全]—再探Filter内存马](https://img-blog.csdnimg.cn/img_convert/1509903dfabbad47c0833af53a44fc92.png)
![[Python私活案例]24行代码,轻松赚取400元,运用Selenium爬取39万条数据](https://img-blog.csdnimg.cn/img_convert/72dff3caf8ea5bfb18b5d65186900045.png)