数据结构
- 串
- KMP算法
- 树
- 二叉树
- 二叉树的基本概念
- 二叉树的遍历(!非递归实现)
- 先序遍历
- 中序遍历
- 后序遍历(🔸非递归实现)
- 🔶线索二叉树
- 找先序遍历的前驱节点(🔸)和后继节点
- 找中序遍历的前驱节点和后继节点
- 找后序遍历的前驱节点和后继节点(🔸)
- 树、森林
- 树的存储结构
- 双亲表示法
- 孩子表示法
- 孩子兄弟表示法
- 树与森林的遍历
- 树的应用——并查集
- 二叉树的应用
- 二叉查找树(BST)
- 平衡二叉树(🔸代码的实现)
- 哈夫曼树与哈夫曼编码(代码待补充
- 图论
- 图的基本概念
- 图的存储结构
- 邻接矩阵
- 邻接表
- 图的遍历
- BFS广度优先搜索
- DFS深度优先搜索
- 习题中的一些问题
- 选择题
- 如何判断无相图G是否为一棵树?
- 如何判断有向图中是否存在由顶点v到顶点w的路径?
- 输出图G从顶点v到顶点w的所有简单路径
- 图的应用
- ①最小生成树
- Prim(普里姆)算法
- Kruskal(克鲁斯卡尔)算法
- ②最短路径
- Dijkstra(迪杰斯特拉)算法
- Floyd(佛洛依德)算法
- ③拓扑排序
- ④关键路径
- 查找
- 线性结构下的查找
- 顺序查找
- 折半查找
- 分块查找
- 树型结构下的查找
- 二叉排序树
- 二叉平衡树
- B树、B+树
- 散列结构下的查找
- 散列表
- 性能分析
- 冲突处理(开放定址法、拉链法)
- 效率指标
- 查找成功的ASL
- 查找失败的ASL
- 排序
- 内部排序
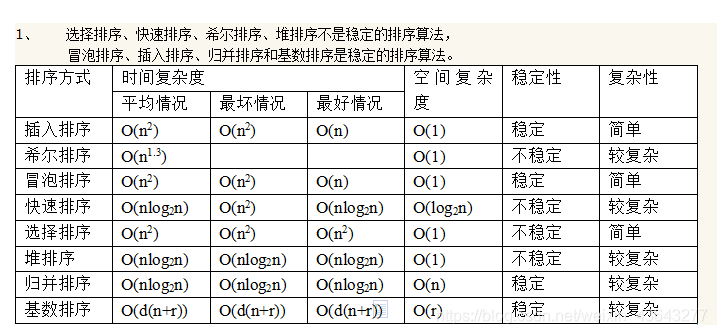
- O(n^2)
- 冒泡排序
- 插入排序
- 选择排序
- 希尔排序
- O(nlogn)
- 归并排序
- 快速排序
- 堆排序
- O(n)
- 基数排序
- 内部排序效益总结
- 外部排序
串
KMP算法
树
二叉树
二叉树的基本概念
- 二叉树高度的公式是怎么推导而来的
二叉树的遍历(!非递归实现)
先序遍历
中序遍历
后序遍历(🔸非递归实现)
🔶线索二叉树
- 线索二叉树的存储结构
typedef struct ThreadNode{
ElemType data;
struct ThreadNode *lchild, *rchild;
int ltag, rtag; //如果xtag为0,则xchild指向实际的孩子;如果xtag为1,则xchild指向前驱or后继。
}
找先序遍历的前驱节点(🔸)和后继节点
- 先序遍历的第一个结点——根节点本身
- 🔶先序遍历的最后一个结点
Thread *Lastnode(ThreadNode *p){
while( (p->ltag == 0 && p->lchild != NULL) || (p->rtag == 0 && p->rchild != NULL) ){
while(p->rtag == 0 && p->rchild != NULL) p = p->rchild;
if(p->ltag == 0 && p->lchild != NULL) p = p->lchild;
}
return p;
}
- 结点p在先序遍历中的前驱(需要定位到p结点的父结点f【用三叉链表】)——以**
f->lchild为根节点**的二叉树,进行先序遍历的最后一个结点,则是p的先序前驱- 特殊情况:p本身是整棵二叉树的根节点,则没有前驱
//三叉链表
typedef struct TriTNode
{
int data;
struct TriTNode *lchild, *rchild;
int ltag,rtag;
struct TriTnode *parent; //多出一个域指向父结点
}TriTNode,*TriTree;
//略
- 结点p在先序遍历中的后继——结点p是否存在左孩子,分两种情况讨论:
- 【根p,左,右】->【根p ,【根,左,右】,右】,即p先序的后继是其左子树的根,也就是左孩子p->lchild
- 左孩子不存在【根p,右】->【根p,【根,左,右】】,即p先序的后继是其右子树的根,也就是右孩子p->rchild
Thread *Nextnode(ThreadNode *p){
if(p->rtag == 0 && p->rchild != NULL){
if(p->ltag == 0 && p->lchild){ //左孩子存在
return p->lchild;
}
}
//(左孩子不存在) or (p->rtag == 1)
return p->rchild; //不论是有实际的右孩子,还是指向后继,只要没有实际的左孩子,都是直接返回p->rchild
}
找中序遍历的前驱节点和后继节点
- 中序遍历的第一个节点——根节点的最左下结点(不一定是叶节点,因为它有可能有右孩子)
ThreadNode *Firstnode(ThreadNode *p){
while(p->ltag==0) //左孩子存在,则一直往左下
p = p->lchild;
return p;
}
- 中序遍历的最后一个节点——根节点的最右下结点(不一定是叶节点)
ThreadNode *Lastnode(ThreadNode *p){
while(p->rtag == 0){
p = p->rchild;
}
return p;
}
- 结点p在中序遍历中的前驱**(CodeLine3)**
ThreadNode *Prenode(ThreadNode *p){
if(p->ltag == 0){ //lchild指向的是实际的左孩子
return Lastnode(p->lchild); //前驱是 左子树中最右下的结点,即以结点p左孩子为根节点,找 Lastnode(p->lchild)
}
return p->rchild;
}
- 结点p在中序遍历中的后继**(CodeLine3)**
1 ThreadNode *Nextnode(ThreadNode *p){
2 if(p->rtag == 0){ //rchild指向的是实际的右孩子
3 return Firstnode(p->rchild); //后继是 右子树中最左下的结点,即以结点p的右孩子为根节点,找 Firstnode(p->rchild)
4 }
5 return p->rchild;
6 }
找后序遍历的前驱节点和后继节点(🔸)
- 🔶后序遍历中的第一个结点——与找先序遍历的最后一个结点类似
Thread *Firstnode(ThreadNode *p){
while( (p->ltag == 0 && p->lchild != NULL) || (p->rtag == 0 && p->rchild != NULL) ){
while(p->ltag == 0 && p->lchild != NULL) p = p->lchild;
if(p->rtag == 0 && p->rchild != NULL) p = p->rchild;
}
return p;
}
- 后序遍历中的最后一个结点——根节点自己
- 结点p在后序遍历的前驱——分情况右孩子是否存在:
- 右孩子存在:【左,右,根p】->【左,【左右根】,根p】
- 右孩子不存在:【左,根p】->【【左右根】,根p】
Thread *Prenode(ThreadNode *p){
if(p->ltag == 0 && p->lchild != NULL){
if(p->rtag == 0 && p->rchild){ //右孩子存在
return p->rchild;
}
}
//(右孩子不存在) or (p->ltag == 1)
return p->lchild; //不论是有实际的左孩子,还是指向前驱,只要没有实际的右孩子,都是直接返回p->lchild
}
- 结点p在后序遍历的后继——需要借助三叉链表找到父结点f
- 特殊情况:p本身是整棵二叉树的根节点,则没有后继
- 结点p是父结点f的右孩子,即【左,右p,根f】,则p的后继是父结点
- 结点p是父结点f的左孩子,即【左p,右,根f】,则需要进一步讨论:
- 父结点f 仅存在左孩子p,即【左p,根f】,则p的后继是父结点
- 父结点f 既存在左孩子p又存在右孩子,即【左p,右,根f】->【左p,【左,右,根】,根f】,则p的后继为
Firstnode(f->rchild)
树、森林
树的存储结构
双亲表示法
孩子表示法
孩子兄弟表示法
树与森林的遍历
树的应用——并查集
二叉树的应用
二叉查找树(BST)
平衡二叉树(🔸代码的实现)
- 平衡二叉树的查找长度为O(log2n)
- 平衡因子:左子树高度-右子树高度
- 如何旋转详见【P177-P178】
- LL平衡旋转
- RR平衡旋转
- LR平衡旋转
- RL平衡旋转
哈夫曼树与哈夫曼编码(代码待补充
- 带权路径长度(WPL)——求和(所有叶子结点的权值*其叶子结点对应的路径长度)
- 路径长度:根节点到结点中的边数
- 画哈夫曼树——每次找权值最小的两个根节点,分别充当左右孩子,组合成为一颗新的二叉树树
- 新的二叉树根节点的权值=左子树根节点权值+右子树根节点权值
- 代码实现
图论
图的基本概念
- 图G=(V,E),其中V(Vertex)表示非空顶点集,E(Edge)表示边的集合。
- 简单图——满足①不存在重复边;②不存在顶点自己到自己的边,则称之为简单图。数据结构中仅仅讨论简单图,不讨论多重图。
- 完全图(简单完全图)
- 无向完全图——设图顶点数为n(n>0),则边数为 n(n-1)/2 的图称之为无向完全图。换一种说法就是,任意两个顶点之间都有一条直接相连的边。
- 有向完全图——设图顶点数为n(n>0),则边数为 n(n-1) 的图称之为有向完全图。换一种说法就是,任意两个顶点之间都有两条方向相反的边。
- 子图——若有两个图G1和G2,G2顶点集V2是G1顶点集V1的子集,且G2边集E2是G1边集E1的子集,则称G2是G1的子图。
- 生成子图——若在上述子图的基础上顶点集相同,即V1=V2,则称G2是G1的生成子图。
- 💢注意——不是任何V1和E1的子集都能构成G1的子图,因为首先要看V2和E2能否构成图。例如,V1={1,2},E2={(1,2)},而V2={1},E2{(1,2)}是不构成图的。
- 连通、连通图和连通分量(仅适用于无向图)
- 无向图的顶点间是否连通——若从顶点v到顶点w有路径存在,则称v和W是连通的。
- 连通图、非连通图——若图G任意两个顶点都是连通的,则称图G是连通图,否则称为非连通图。
- 连通分量——无向图中的极大连通子图称之为连通分量。
- 性质:如果一个图有n个顶点,但是只有小于n-1条边,则它一定是非连通图。
- 强连通、强连通图和强连通图(仅适用于有向图)
- 有向图的顶点之间是否强连通——若从顶点v到顶点w和从顶点w到顶点v都有路径存在,则称v和W是强连通的。
- 强连通图、非强连通图——若图G任意两个顶点都是强连通的,则称图G是强连通图,否则称为非强连通图。
- 强连通分量——有向图中的极大强连通子图称之为强连通分量。
- 性质:如果一个图有n个顶点,但是只有小于n条边,则它一定是非强连通图。
- 连通图的生成树——包含图中全部顶点的一个极小连通子图,即边数最少。
- 顶点的度、入度和出度
- 无向图,顶点v的度是指依附于顶点v的边的条数
图的存储结构
邻接矩阵
typedef char VertexType;
typedef int EdgeType;
typedef struct{
VertexType Vex[MaxVertexNum];
EdgeType Edge[MaxVertexNum][MaxVertextNum];
int vexnum,arcnum;
}MGragh;
邻接表
#define MaxVertexNum 100
typedef struct ArcNode{
int adjvex;
Struct ArcNode* next;
}ArcNode;
typedef struct VNode{
Vertex data;
ArcNode *first;
}VNode;
typedef struct{
VNode* vertices = new VNode[MaxVertexNum];
int vexnum,arcmun;
}ALGragh;
图的遍历
BFS广度优先搜索
bool visited[MAX_VERTEX_NUM];
queue <int> Q;
bool BFSTraverse(Gragh G){
for(int i=0; i<G.vexmun; i++){
visited[i] = False;
}
//统计连通分量,加一个变量。
//int componentNum = 0;
for(int i = 0; i<G.vexnum; ++i){
if(!visited[i]) BFS(G,i);
//componentNum++;
}
//cout<<"连通分量数量:"<<componentNum<<endl;
}
//邻接矩阵
//邻接矩阵下的-BFS广度优先搜索-时间复杂度:O(V^2)
//邻接矩阵下的空间复杂度:O(|V|)
void BFS(Graph G, int v){
visited[v] = True;
Q.push(v);
while(!Q.empty()){
int temp = Q.front();
Q.pop();
for(int i = 0; i<G.vexnum; i++){
if(G.Edge[temp][i] && !visited[i]){
visited[i] = True; //访问v
Q.push(i);
}
}
}
}
//邻接表
//邻接表下的-BFS广度优先搜索-时间复杂度:O(|V|+|E|),
//时间复杂度解释————查找所有顶点的邻接顶点花费的时间为O(|E|),访问所有顶点花费的时间O(|V|),相加得结果。
//邻接表下的空间复杂度:O(|V|)
//代码实现所用邻接表接口:
//int FirstNeighbor(G,x){},求图中顶点x的第一个邻接顶点,如果存在则返回该顶点编号,如果该顶点本身不存在or该顶点不存在任何邻接顶点,则返回-1
//int NextNeighbor(G,x,y){},求图中顶点x的邻接顶点y之后的下一个邻接顶点,如果存在则返回该顶点编号
void BFS(Graph G, int v){
visited[v] = True;
Q.push(v);
while(!Q.empty()){
int temp = Q.front();
Q.pop();
for(int i = FirstNeighbor(G,temp); i>=0 ; i = NextNeighbor(G,temp,i)){
if(!visited[i]){
visited[i] = True; //访问v
Q.push(i);
}
}
}
}
DFS深度优先搜索
bool visited[MAX_VERTEX_NUM];
stack <int> S;
bool DFSTraverse(Gragh G){
for(int i=0; i<G.vexmun; i++){
visited[i] = False;
}
//统计连通分量,加一个变量。
//int componentNum = 0;
for(int i = 0; i<G.vexnum; ++i){
if(!visited[i]) DFS(G,i);
//componentNum++;
}
//cout<<"连通分量数量:"<<componentNum<<endl;
}
//邻接表-递归法
//邻接表下的-DFS深度优先搜索-时间复杂度:O(|V|+|E|)
//邻接表下的空间复杂度:O(|V|)
void DFS(Graph G, int v){
visited[v] = True;
for(int i = FirstNeighbor(G,v); w>=0; i=NextNeighbor(G,v,w)){
if(!visited[i]) DFS(G,i);
}
}
//邻接表-迭代法
void DFS(Graph G, int v){
visited[v] = True;
S.push(v);
while(!S.empty()){
int temp = S.top();
for(int i = FirstNeighbor(G,temp); i>=0; ){
if(!visited[i]){
S.push(i);
visited[i] = True;
temp = i;
i = FirstNeighbor(G,i);
}
else i = NextNeighbor(G,temp,i);
}
S.pop();
}
}
习题中的一些问题
选择题
- 【P219选择T1】当各边的权值相等时,BFS广度优先搜索可以解决单源最短路径问题
- 【P219选择T1】判断有向图中是否存在回路,除了可以利用拓扑排序外,还可以利用DFS深度优先搜索。
- 如果遍历的有向图无环,并在出栈时打印所有出栈顶点序号,这样得到的顶点序列是逆拓扑排序。
如何判断无相图G是否为一棵树?
- 判断条件:图G要满足是有n-1条边的连通图。
- 具体实现思路:可以采用深度优先搜索,在遍历时统计可能访问到的顶点个数和边的条数,如果能实现一次
void DFS(Gragh G, int v){}就能访问到n个顶点和n-1条边,则可以断定此图G为一棵树。 - 代码实现记录顶点数和边数:
bool visited[MAX_VERTEX_NUM];
bool isTree(Gragh& G){
//初始化visited数组,全部赋值False
for(int i = 1; i<=G.vexnum; i++) visited[i] = False;
//记录遍历中的边数和顶点数,而建立的变量
int Vnum = 0,Enum = 0;
DFS(G,1,Vnum,Enum); //把以上两个变量传入
if(Vnum==G.vexnum &&& Enum==G.vexnum-1) return True;
return False
}
void DFS(Graph G, int v; int &Vnum; int &Enum){
visited[v] = True;
Vnum++; //!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
int temp = FirstNeighbor(G,v);
while(temp>=0){
Enum++; //边数在找到一个连接的邻接顶点后,加加!!!!!!!!!!
if(!visited[w]) DFS(G,temp,Vnum,Enum);
temp = NextNeighbor(G,v,temp);
}
}
如何判断有向图中是否存在由顶点v到顶点w的路径?
- 调用以
DFS(G,v)或者BFS(G,v),执行结束后判断return visited[w],如果True,则存在,如果False,则不存在。
输出图G从顶点v到顶点w的所有简单路径
- 【P225】
图的应用
①最小生成树
- 对于带权值的连通无向图G,生成树的不同,代表每棵树的总权值也可能不同,称权值最小的生成树为最小生成树。
- Prim算法和Kruskal算法都是基于贪心算法的策略。
Prim(普里姆)算法
- 加点
- Prim和Dijkstra有些类似
- 时间复杂度——O(|V|^2)
- 空间复杂度——O(|E|)
- 适用于求解边稠密的图
Kruskal(克鲁斯卡尔)算法
- 加边
- 采用堆来存放边的集合
- 时间复杂度——O(|E|log|E|)
- 适用于边稀疏而顶点较多
②最短路径
Dijkstra(迪杰斯特拉)算法
- 从某一个特定顶点到其他所有顶点的最短路径
- 算法时间复杂度:O(|V|^2)
void ShortestPath_DIJ(AMGraph G, int v0){
//用Dijkstra算法求有向网G的v0顶点到其余顶点的最短路径(邻接矩阵)
/*初始化
D[],记录其他顶点到V0的距离,每一轮都会更新,并选出一个最小的Vi,令S[i]=true;
S[],
Path[],记录最短路径中顶点i的前驱顶点
三个辅助数组*/
n=G.vexnum; //n为G中顶点的个数
for(v = 0; v<n; ++v){ //n个顶点依次初始化
S[v] = false; //S初始为空集
D[v] = G.arcs[v0][v]; //将v0到各个终点的最短路径长度初始化
if(D[v]< MaxInt) Path [v]=v0; //v0和v之间有弧,将v的前驱置为v0
else Path [v]=-1; //如果v0和v之间无弧,则将v的前驱置为-1
}//for-end
S[v0]=true; //将v0加入S
D[v0]=0; //源点到源点的距离为0
/*―开始主循环,每次求得v0到某个顶点v的最短路径,将v加到S集―*/
for(i=1;i<n; ++i){ //对其余n−1个顶点,依次进行计算
min= MaxInt;
for(w=0;w<n; ++w)
if(!S[w]&&D[w]<min){ //选择一条当前的最短路径,终点为v
v=w;
min=D[w];
}
S[v]=true; //将v加入S,即修改S[v]
for(w=0;w<n; ++w) //更新从v0出发到集合V−S上所有顶点的最短路径长度
if(!S[w] && (D[v]+G.arcs[v][w] < D[w]) ){
D[w]=D[v]+G.arcs[v][w]; //更新D[w]
Path[w]b=v; //更改w的前驱为v
}//if-end
}//for-end
}//ShortestPath_DIJ-end
Floyd(佛洛依德)算法
- 各个不同顶点之间的最短路径
Path[i][j]和最短路径长度A[i][j] - 算法时间复杂度:O(|V|^3)
/*初始化
A[][],A(k)[i][j]表示顶点i到顶点j的经过不大于k的顶点的最短路径长度
Path[][],Path(n)[i][j]表示顶点i到顶点j的最短路径中j的前驱顶点;
cost[][]即邻接矩阵
*/
for(i=1;i<=n;i++)
for(j=1;j<=n;j++){
A[i][j]=cost[i][j];
if(cost[i][j]< MAX ) Path[i][j]=i;
else Path[i][j]=0;
}//for-end
/*k轮双层for循环,不断更新A(k)[][]和Path(k)[][]*/
for(k=1;k<=n;k++)
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if( A[i][j]> A[i][k]+ A[k][j] ){
A[i][j]= A[i][k]+ A[k][j];
Path[i][j]= Path[k][j] ;
}
- 从顶点 i 到顶点 j 的最短路径
void pathPrint(int m, int n, int Path[][]){
stack <int> pathStack;
pathStack.push(n);
for(int j = n; Path[m][j] != m; j = Path[m][j]) pathStack.push(Path[m][j]);
//打印最短路径
print(m);
while(!pathStack.empty()) print(pathStack.pop());
}
③拓扑排序
- AOV网:若用DAG图表示一个工程,其顶点表示活动,用有向边<Vi,Vj>表示活动Vi必须先于活动Vj进行的这样一种关系,则将这种有向图称为顶点表示活动的网络,记为AOV网。
- 拓扑排序:在图论中,有一个有向无环图的顶点组成的序列,满足①每个顶点仅出现一次;②顶点A若在序列中排在顶点B 的前面,则图中不存在从顶点B到顶点A的路径;这两个条件,则称该图为一个拓扑排序。
stack <int> S; //栈,用于存储入度为0的顶点
int indegree[G.vexnum]; //记录每个顶点的入度
int count = 0; //计数,记录当前已经输出的顶点数
while(!S.empty()){
}
//循环结束后,如果count等于G.vexnum,则该图是拓扑排序(该图没有环)
//如果count < G.vexnum,则该图不是拓扑排序(该图存在环)
- 以上算法的时间复杂度:
- 邻接表:O(|V| + |E|)
- 邻接矩阵:O(|V|^2)
④关键路径
查找
-
经常对查找表做的操作有:
- ①所查的元素是否存在
- ②检索满足条件的某个特定数据元素的属性(下标之类的?)
- ③在查找表中插入一个数据元素
- ④从查找表中删除某个数据元素
-
静态查找:对查找表的操作仅涉及以上的①和②,适合静态查找的有顺序查找、折半查找、散列查找
-
动态查找:需要对查找表进行动态的插入与删除操作,适合动态查找的有二叉排序树查找(改进:二叉平衡树、B树)、散列查找
-
关键字:能唯一标识一个数据元素的数据项的值
-
平均查找长度(ASL):求和(查找某个元素的概率*查找某个元素需要的比较次数),一般认为每一个数据元素的查找概率相等,均为1/n
线性结构下的查找
顺序查找
- 哨兵——
ST.elem[0] = key,引入它的mu1
折半查找
分块查找
- 分块原则:查找表长度为n,则将查找表均分为b块,每一块分 s=根号n 个记录
- 若对索引表采用折半查找,则平均查找长度ASL= 取上整(log2(b+1)) + (s+1)/2
树型结构下的查找
二叉排序树
二叉平衡树
B树、B+树
散列结构下的查找
散列表
性能分析
冲突处理(开放定址法、拉链法)
效率指标
查找成功的ASL
查找失败的ASL
排序
内部排序
O(n^2)
冒泡排序
//升序
void BubbleSort(ElemType A[], int len){
for(int i = 0; i<len; i++){
//本趟是否进行了交换,有交换则赋值为true,然后继续进行下一趟;没有交换则排序结束
bool flag = false;
for(int j = 0; j<len-i; j++){
if(A[j]>A[j+1]){
swap(A,j,j+1);
flag = true;
}//if-end
}//2for-end
if(!flag) break;
}//1for-end
}
插入排序
- 直接插入
| 有序序列A[1…i-1] | | A[i] | | 无序序列A[i+1…n] |
|---|
//A[0]作为插入排序暂存元素的位置,当作哨兵。
//实际数组的位置为1~n,实际数组长度为n-1。
void InsertSort(ElemType A[], int len){
for(int i = 2; i<=len; i++){
if(A[i] < A[i-1]){
A[0] = A[i]; //设置哨兵
for(int j = i-1; A[0]<A[j]; j--) A[j+1] = A[j]; //注意内层for循环的结束条件是元素与哨兵的比较
A[j+1] = A[0];
}
}
}
- 折半插入排序
void InsertSort(ElemType A[], int len){
}
选择排序
- 思想,每次(第i趟)选择一个待排序序列n-i+1个元素中最小的元素,作为有序子序列的第i个元素。
void SelectSort(ElemType A[], int len){
for(int i = 0; i<len-1; i++){
int min = i; //min记录最小元素的下标
for(int j = i+1; j<len; j++){
if(A[j]<A[min]) min = j;
}
if(min != i) swap(A,i,min); //注意这个判断if
}
}
void swap(ElemType A[], int a, int b){
ElemType temp = A[a];
A[a] = A[b];
A[b] = temp;
}
希尔排序
//A[0]作为二三层for循环的插入排序暂存元素的位置,但不是哨兵。
//实际数组的位置为1~n,实际数组长度为n-1。
void ShellSort(ElemType A[], int n){
for(int stepLen = n/2; stepLen>=1; stepLen/=2){
//第一层for循环用于控制步长stepLen的长度
for(int i = stepLen+1; i<=n; ++i){
//第二层for循环相当于插入排序的外层循环
//i首先指向待排序序列的第二个元素,因为插入排序中第一个元素自己相当于一个有序数组
if(A[i] < A[i-stepLen]){
for(int j = i-stepLen; j>0 && A[0] <A[j]; j -= stepLen){
//第三层for循环相当于插入排序的内层循环
A[j+stepLen] = A[j];
}//3for-end
A[j+stepLen] = A[0];
}//if-end
}//2for-end
}//1for-end
}//ShellSort-end
O(nlogn)
归并排序
void MergeSort(ElemType A[], int low, int high){
if(low<high){
//int mid = (high-low+1)/2; 要的是mid的index!!所以应该是加法后除以2
int mid = (low+high)/2;
MergeSort(A,low,mid);
MergeSort(A,mid+1,high);
Merge(A,low,mid,high);
}
}
void Merge(ElemType A[], int low, int mid, int high){
//需要建立一个辅助数组,本可以只建立high-low+1这么长的数组即可,但是为了统一与A的下标,所以建立与A一样大的数组
ElemType *B = new ElemType[sizeof(A)];
//先把A的全部复制到B
for(int i = low; i<=high; i++) B[i]=A[i];
//两个有序合并成一个有序!!!
for(int i = low, j = mid+1, k = low; i<=mid && j<=high; k++){
if(B[i]<=B[j]){
//选出当前两个有序表中较小的元素,将其放到A
//这里如果写成 if(B[i]<B[j]),则该算法就不稳定了
A[k] = B[i];
i++;
}
else{
A[k] = B[j];
j++;
}
}//for-end
while(i<=mid) {A[k] = B[i]; i++; k++; } //可以简写成-> while(i<=mid) A[k++] = B[i++];
while(j<=high) {A[k] = B[j]; j++; k++; } //可以简写成-> while(j<=high) A[k++] = B[j++];
}
快速排序
void QuickSort(ElemType A[], int low, int high){
if(low<high){
int pivotIndex = Partition(A,low,high);
QuickSort(A,low,piovtIndex-1);
QuickSort(A,piovtIndex+1,high);
}
}
int Partition(ElemType A[], int low, int high){
int piovt = A[low];
while(low<high){
while(low<high && A[high]>=piovt) high--;
A[low] = A[high];
while(low<high && A[low]>=piovt) low++;
A[high] = A[low];
}//while-end
A[low] = piovt;
return low;
}
//或许Partition函数这样写也是一样的,且更容易理解
int Partition(ElemType A[], int low, int high){
while(low<high){
while(low<high && A[high]>=A[low]) high--;
swap(ElemType A[],low,high);
while(low<high && A[high]>=A[low]) low++;
swap(ElemType A[],low,high)
}//while-end
return low;
}
void swap(ElemType A[], int a, int b){
ElemType temp = A[a];
A[a] = A[b];
A[b] = temp;
}
堆排序
//A[0]作为插入排序暂存元素的位置,不是哨兵。
//实际数组的位置为1~n,实际数组长度为len=n-1。
//建立初始堆
void BuildMaxHeap(ElemType A[],int len){
for(int i = len/2; i>0; i--){
HeadAdjust(A,i,len);
}
}
void HeadAdjust(ElemType A[], int k, int len){
A[0] = A[k];
for(int i = 2*k; i<=len; i *= 2){
if(i<len && A[i=1]>A[i]){
i++;
}
else if(A[0]>A[i]) break;
else{
A[k] = A[i];
k = i;
}
}
A[k] = A[0]; //被筛选的节点放入最终位置
}
//堆排序
void HeapSort(ElemType A[], int len){
BuildMaxHeap(A,len);
for(int i = 1; i<=len; i++){
swap(A,1,len+1-i);
HeadAdjust(A,1,len-i);
}
}
void swap(ElemType A[], int a, int b){
ElemType temp = A[a];
A[a] = A[b];
A[b] = temp;
}
O(n)
基数排序
内部排序效益总结






![[附源码]计算机毕业设计springboot校园快递柜存取件系统](https://img-blog.csdnimg.cn/a9db337c85ae4d49b3ce70a868dd0052.png)