Stable Diffusion 一经发布,就立刻在业界掀起巨大的波浪。我个人后知后觉,直到 Stable Diffusion V1.4 版本发布,才接触 Stable Diffusion (之前使用的是 Disco Diffusion)。这段时间,SD 团队也没闲着,很快就发布了 V2 版本。下面看看 SD V2 版本给我们带来了哪些惊喜。

全新的文本到图像扩散模型
Stable Diffusion 2.0 版本包括使用全新文本编码器 (OpenCLIP) 训练的强大的文本到图像模型,该模型由 LAION 在 Stability AI 的支持下开发,与早期的 V1 版本相比大大提高了生成图像的质量。此版本中的文本到图像模型可以生成默认分辨率为 512x512 像素和 768x768 像素的图像。
这些模型在 Stability AI 的 DeepFloyd 团队创建的 LAION-5B 数据集的美学子集上进行训练,然后使用 LAION 的 NSFW 过滤器进一步过滤以删除成人内容。
某些人可能会有所失望,不能再使用最新模型来生成色图了。
下面是使用 Stable Diffusion 2.0 生成的图像示例,图像分辨率为 768x768。

超分辨率 Upscaler 扩散模型
Stable Diffusion 2.0 还包括一个 Upscaler Diffusion 模型,该模型将图像的分辨率提高了 4 倍。下面是低分辨率生成图像 (128x128) 放大为更高分辨率图像 (512x512) 的示例。

其实在 V1 版本中,也可以引入额外的步骤进行图像放大,所以这一项改进算不上惊喜。当然,现在可以一步到位,Stable Diffusion 2.0 可以生成分辨率为 2048x2048 甚至更高的图像。
深度图像扩散模型
这个称为 depth2img 的模型,实际上就是 V1 之前的图像到图像功能的升级,也是现在网友玩得很嗨的一个功能,也就是使用一张图片作为提示,生成一幅结构类似的作品。
如下图所示,左边的输入图像可以产生几个新图像(右边)。可以看出,右边生成的图像保持输入图像的结构和形状,但内容上又有所不同。

Depth-to-Image 的玩法很多,可以产生出无数看起来与原始图像截然不同,但又相似的“克隆”版本:
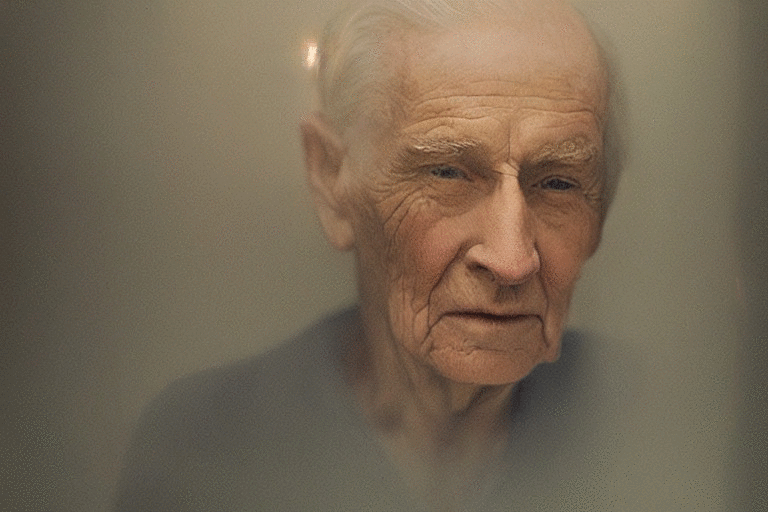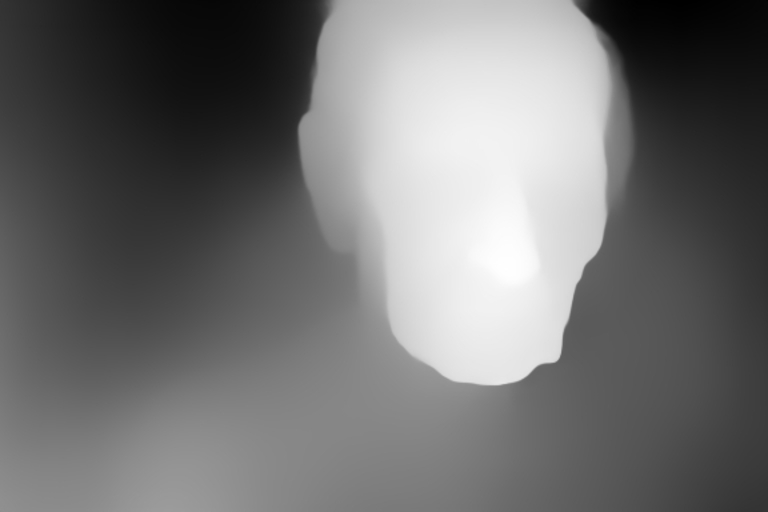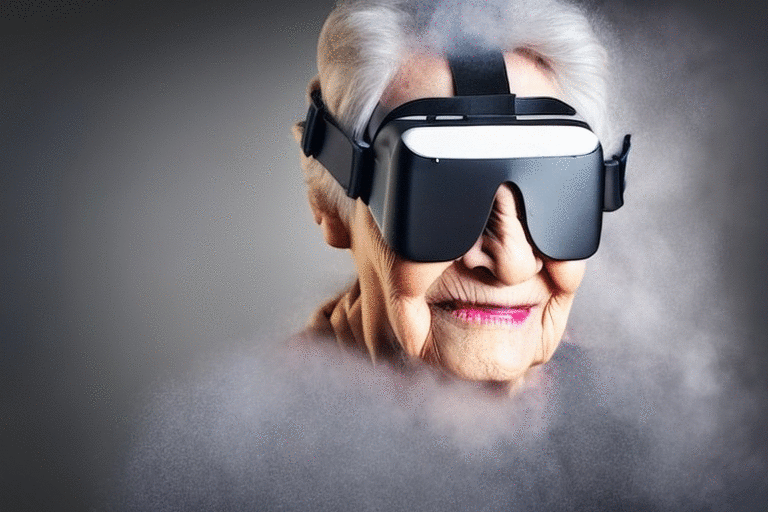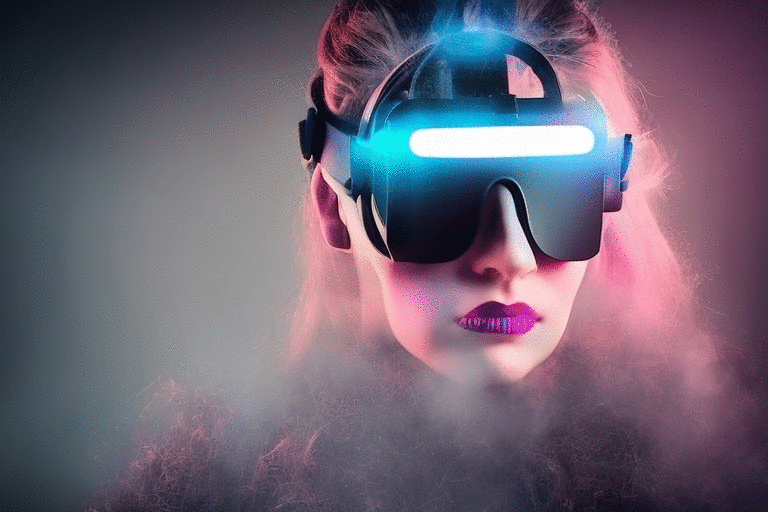
更新修复扩散模型
Stable Diffusion 2.0 还包括一个新的文本引导修复(text-guided inpainting)模型,这也是上一版本的改进。具体说来,就是如果我们对生成作品整体比较满意,但某些部分可能存在瑕疵(比如说眼睛),那我们可以只针对瑕疵的部分进行重新生成,而其它部分保持不变。或者反过来使用,保持某个部分不变,对其它部分重新生成,这样可以得到非常有趣的结果。网上诸多恶搞作品就使用了这种技巧。

小结
一般来说,软件发布的主版本更新,通常意味着重大改进,如果要体验这一功能,请访问官方发布版本:
https://github.com/Stability-AI/StableDiffusion
我之前体验的开源项目 InvokeAI,也开始进行了 V2 模型的支持工作,目前还不够稳定,并没有合并到主分支。
后续我将持续关注 Stable Diffusion 开发方面的进展,希望能使用最新的工具创作出更好的艺术作品,敬请关注。