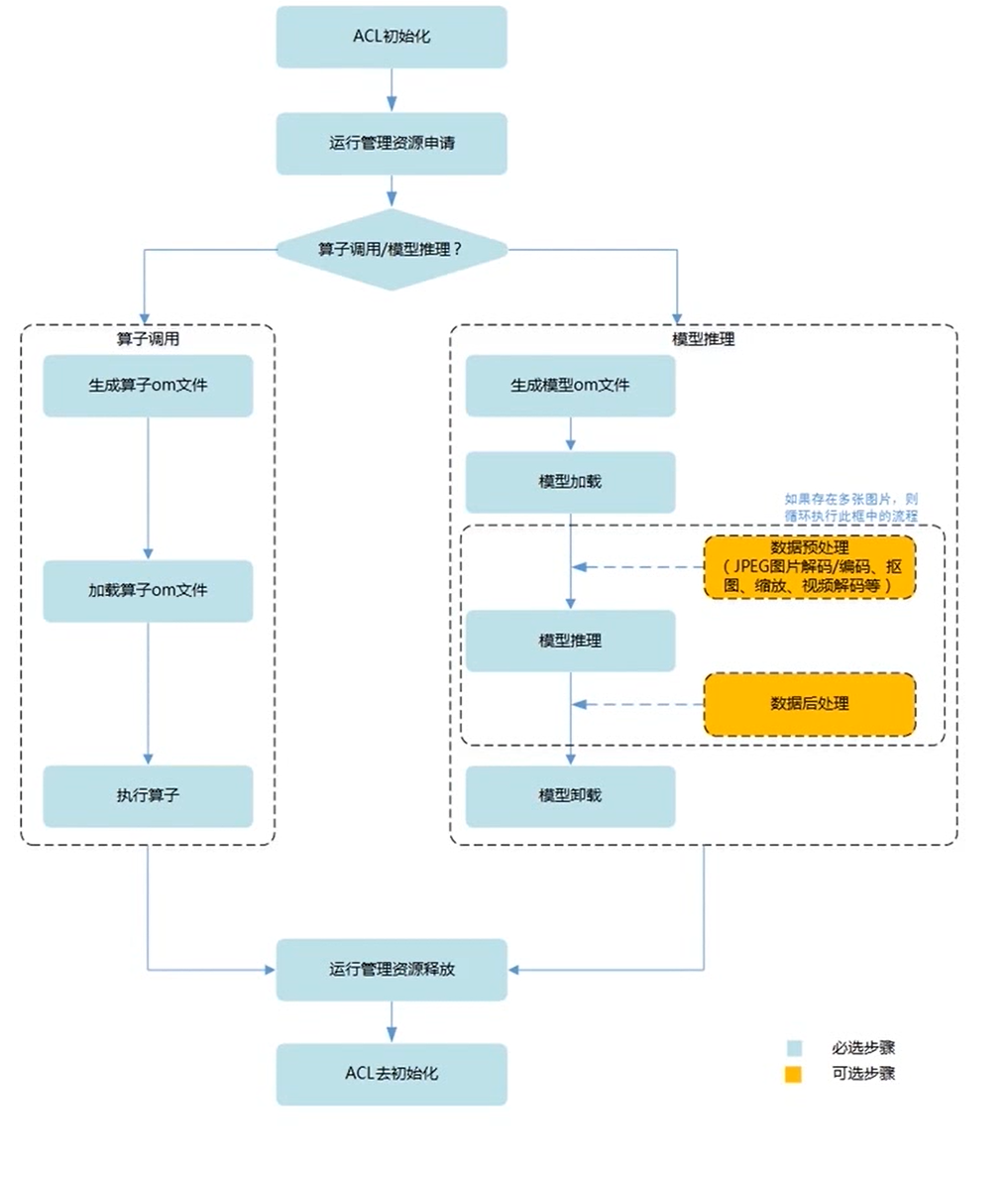
2、mycat的安装及使用
1、mycat的安装
1、环境准备
本次课程使用的虚拟机环境是centos6.5
首先准备四台虚拟机,安装好mysql,方便后续做读写分离和主从复制。
192.168.85.111 node01
192.168.85.112 node02
192.168.85.113 node03
192.168.85.114 node04
安装jdk
使用rpm的方式直接安装jdk,配置好具体的环境变量
2、mycat的安装
从官网下载需要的安装包,并且上传到具体的虚拟机中,我们在使用的时候将包上传到node01这台虚拟机,由node01充当mycat。
下载地址为:http://dl.mycat.org.cn/1.6.7.5/2020-4-10/
解压文件到/usr/local文件夹下
tar -zxvf Mycat-server-1.6.7.5-release-20200422133810-linux.tar.gz -C /usr/local
配置环境变量
vi /etc/profile
添加如下配置信息:
export MYCAT_HOME=/usr/local/mycat
export PATH=$MYCAT_HOME/bin:$PATH:$JAVA_HOME/bin
当执行到这步的时候,其实就可以启动了,但是为了能正确显示出效果,最好修改下mycat的具体配置,让我们能够正常进行访问。
3、配置mycat
进入到/usr/local/mycat/conf目录下,修改该文件夹下的配置文件
1、修改server.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
</user>
</mycat:server>
2、修改schema.xml文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="msb" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.85.111:3306" user="root"
password="123456">
<readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost>
</writeHost>
</dataHost>
</mycat:schema>
4、启动mycat
mycat的启动有两种方式,一种是控制台启动,一种是后台启动,在初学的时候建议大家使用控制台启动的方式,当配置文件写错之后,可以方便的看到错误,及时修改,但是在生产环境中,使用后台启动的方式比较稳妥。
控制台启动:去mycat/bin目录下执行 ./mycat console
后台启动:去mycat/bin目录下执行 ./mycat start
按照如上配置在安装的时候应该不会报错,如果出现错误,根据错误的提示解决即可。
5、登录验证
管理窗口的登录
从另外的虚拟机去登录访问当前mycat,输入如下命令即可
mysql -uroot -p123456 -P 9066 -h 192.168.85.111
此时访问的是mycat的管理窗口,可以通过show @@help查看可以执行的命令
数据窗口的登录
从另外的虚拟机去登录访问mycat,输入命令如下:
mysql -uroot -p123456 -P8066 -h 192.168.85.111
当都能够成功的时候以为着mycat已经搭建完成。
2、读写分离
通过mycat和mysql的主从复制配合搭建数据库的读写分离,可以实现mysql的高可用性,下面我们来搭建mysql的读写分离。
1、一主一从(主从复制的原理之前讲解过了,需要的同学自行参阅文档)
1、在node01上修改/etc/my.cnf的文件
#mysql服务唯一id,不同的mysql服务必须拥有全局唯一的id
server-id=1
#启动二进制日期
log-bin=mysql-bin
#设置不要复制的数据库
binlog-ignore-db=mysql
binlog-ignore-db=information-schema
#设置需要复制的数据库
binlog-do-db=msb
#设置binlog的格式
binlog_format=statement
2、在node02上修改/etc/my.cnf文件
#服务器唯一id
server-id=2
#启动中继日志
relay-log=mysql-relay
3、重新启动mysql服务
4、在node01上创建账户并授权slave
grant replication slave on *.* to 'root'@'%' identified by '123456';
--在进行授权的时候,如果提示密码的问题,把密码验证取消
set global validate_password_policy=0;
set global validate_password_length=1;
5、查看master的状态
show master status
6、在node02上配置需要复制的主机
CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=437;
7、启动从服务器复制功能
start slave;
8、查看从服务器状态
show slave status\G
当执行完成之后,会看到两个关键的属性Slave_IO_Running,Slave_SQL_Running,当这两个属性都是yes的时候,表示主从复制已经准备好了,可以进行具体的操作了
2、一主一从验证
下面我们通过实际的操作来验证主从复制是否完成。
--在node01上创建数据库
create database msb;
--在node01上创建具体的表
create table mytbl(id int,name varchar(20));
--在node01上插入数据
insert into mytbl values(1,'zhangsan');
--在node02上验证发现数据已经同步成功,表示主从复制完成
通过mycat实现读写分离
在node01上插入如下sql语句,
-- 把主机名插入数据库中
insert into mytbl values(2,@@hostname);
-- 然后通过mycat进行数据的访问,这个时候大家发现无论怎么查询数据,最终返回的都是node01的数据,为什么呢?
select * from mytbl;
在之前的mycat基本配置中,其实我们已经配置了读写分离,大家还记得readHost和writeHost两个标签吗?
<writeHost host="hostM1" url="192.168.85.111:3306" user="root"
password="123456">
<readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost>
</writeHost>
其实我们已经配置过了这两个标签,默认情况下node01是用来完成写入操作的,node02是用来完成读取操作的,但是刚刚通过我们的验证发现所有的读取都是node01完成的,这是什么原因呢?
原因很简单,就是因为我们在进行配置的时候在 dataHost 标签中缺失了一个非常重要的属性balance,此属性有四个值,用来做负载均衡的,下面我们来详细介绍
1、balance=0 :不开启读写分离机制,所有读操作都发送到当前可用的writehost上
2、balance=1:全部的readhost和stand by writehost参与select 语句的负载均衡,简单的说,当双主双从模式下,其他的节点都参与select语句的负载均衡
3、balance=2:所有读操作都随机的在writehost,readhost上分发
4、balance=3:所有读请求随机的分发到readhost执行,writehost不负担读压力
当了解了这个参数的含义之后,我们可以将此参数设置为2,就能够看到在两个主机上切换执行了。
3、双主双从
在上述的一主一从的架构设计中,很容易出现单点的问题,所以我们要想让生产环境中的配置足够稳定,可以配置双主双从,解决单点的问题。
架构图如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5CcCRe8J-1685017443564)(E:\lian\mycat\image\双主双从.png)] 在此架构中,可以让一台主机用来处理所有写请求,此时,它的从机和备机,以及备机的从机复制所有读请求,当主机宕机之后,另一台主机负责写请求,两台主机互为备机。
主机分布如下:
| 编号 | 角色 | ip | 主机名 |
|---|---|---|---|
| 1 | master1 | 192.168.85.111 | node01 |
| 2 | slave1 | 192.168.85.112 | node02 |
| 3 | master2 | 192.168.85.113 | node03 |
| 4 | slave2 | 192.168.85.114 | node04 |
下面开始搭建双主双从。
1、修改node01上的/etc/my.cnf文件
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=msb
#设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候, 有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1, 取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=1
2、修改node03上的/etc/my.cnf文件
#主服务器唯一ID
server-id=3
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=msb
#设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=2
3、修改node02上的/etc/my.cnf文件
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
4、修改node04上的/etc/my.cnf文件
#从服务器唯一ID
server-id=4
#启用中继日志
relay-log=mysql-relay
5、所有主机重新启动mysql服务
6、在两台主机node01,node03上授权同步命令
GRANT REPLICATION SLAVE ON *.* TO 'root'@'%' IDENTIFIED BY '123456';
7、查看两台主机的状态
show master status;
8、在node02上执行要复制的主机
CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=154;
9、在node04上执行要复制的主机
CHANGE MASTER TO MASTER_HOST='192.168.85.113',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=154;
10、启动两个从机的slave并且查看状态,当看到两个参数都是yes的时候表示成功
start slave;
show slave status;
11、完成node01跟node03的相互复制
--在node01上执行
CHANGE MASTER TO MASTER_HOST='192.168.85.113',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=442;
--开启slave
start slave
--查看状态
show slave status\G
--在node03上执行
CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000002',MASTER_LOG_POS=442;
--开启slave
start slave
--查看状态
show slave status\G
4、双主双从验证
在node01上执行如下sql语句:
create database msb;
create table mytbl(id int,name varchar(20));
insert into mytbl values(1,'zhangsan');
--完成上述命令之后可以去其他机器验证是否同步成功
当上述操作完成之后,我们可以验证mycat的读写分离,此时我们需要进行重新的配置,修改schema.xml文件。
在当前mysql架构中,我们使用的是双主双从的架构,因此可以将balance设置为1
除此之外我们需要注意,还需要了解一些参数:
参数writeType,表示写操作发送到哪台机器,此参数有两个值可以进行设置:
writeType=0:所有写操作都发送到配置的第一个writeHost,第一个挂了切换到还生存的第二个
writeType=1:所有写操作都随机的发送到配置的writehost中,1.5之后废弃,
需要注意的是:writehost重新启动之后以切换后的为准,切换记录在配置文件dnindex.properties中
参数switchType:表示如何进行切换:
switchType=1:默认值,自动切换
switchType=-1:表示不自动切换
switchType=2:基于mysql主从同步的状态决定是否切换
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="msb" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.85.111:3306" user="root"
password="123456">
<readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost>
</writeHost>
<writeHost host="hostM2" url="192.168.85.113:3306" user="root"
password="123456">
<readHost host="hostS2" url="192.168.85.114:3306" user="root" password="123456"></readHost>
</writeHost>
</dataHost>
</mycat:schema>
下面开始进行读写分离的验证
--插入以下语句,使数据不一致
insert into mytbl values(2,@@hostname);
--通过查询mycat表中的数据,发现查询到的结果在node02,node03,node04之间切换,符合正常情况
select * from mytbl;
--停止node01的mysql服务
service mysqld stop
--重新插入语句
insert into mytbl values(3,@@hostname);
--开启node01的mysql服务
service mysqld start
--执行相同的查询语句,此时发现在noede01,node02,node04之间切换,符合情况
通过上述的验证,我们可以得到一个结论,node01,node03互做备机,负责写的宕机切换,其他机器充作读请求的响应。
做到此处,希望大家能够思考一个问题,在上述我们做的读写分离操作,其实都是基于主从复制的,也就是数据同步,但是在生产环境中会存在很多种情况造成主从复制延迟问题,那么我们应该如何解决延迟问题,这是一个值得思考的问题,到底如何解决呢?
3、数据切分
数据切分指的是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库上面,以达到分散单台设备负载的效果。
数据的切分根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表来切分到不同的数据库之上,这种切可以称之为数据的垂直切分或者纵向切分,另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库上面,这种切分称之为数据的水平切分或者横向切分。
垂直切分的最大特点就是 规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也很小,拆分规则也会比较简单清晰。
水平切分与垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表明来拆分更为复杂,后期的数据维护也会更为复杂一些。
1、垂直切分
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者压力分担到不同的库上面。
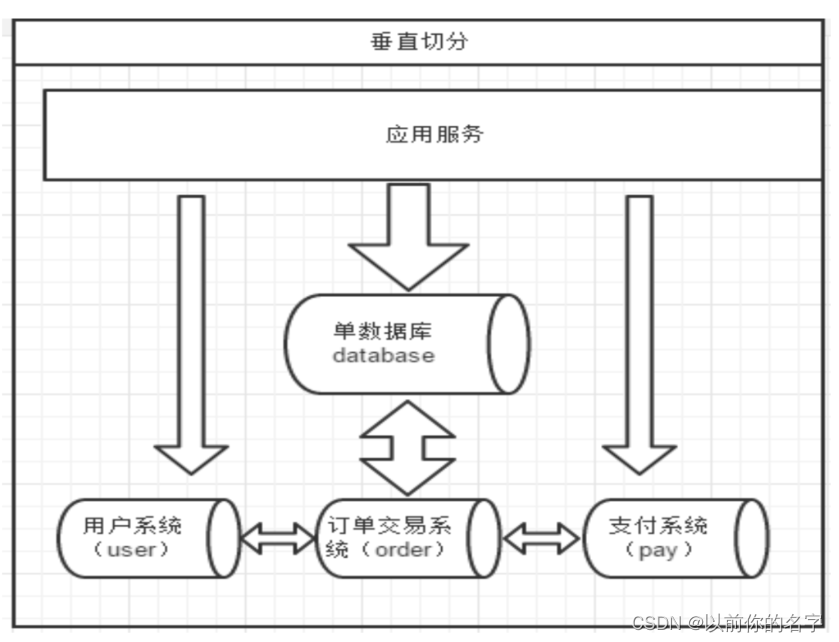
如上图所示,一个系统被切分成了用户系统、订单交易、支付系统等多个库。
一个架构设计较好的应用系统,其总体功能肯定是又多个功能模块所组成的。而每一个功能模块所需要的数据对应到数据库中就是一个或者多个表。而在架构设计中,各个功能模块相关质检的交互点越统一越少,系统的耦合度就越低,系统各个模块的维护性以及扩展性也就越好。这样的系统,实现数据的垂直切分也就越容易。
但是往往系统中有些表难以做到完全的独立,存在着跨库join的情况,对于这类的表,就需要去做平衡,是数据让步业务,共用一个数据源还是分成多个库,业务之间通过接口来做调用。在系统初期,数据量比较少,或者资源有限的情况下,会选择共用数据源,但是当数据发展到一定规模,负载很大的情况下就必须要做分割。
一般来讲业务存在着复杂join的场景是难以切分的,往往业务独立的易于切分。如何切分,切分到何种程度是考验技术架构的一个难题。下面来分析下垂直切分的优缺点:
优点:
1、拆分后业务清晰,拆分规则明确
2、系统之间整合或扩展容易
3、数据维护简单
缺点:
1、部分业务表无法实现join,只能通过接口方式解决,提高了系统复杂度
2、受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高
3、事务处理复杂
2、水平切分
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,
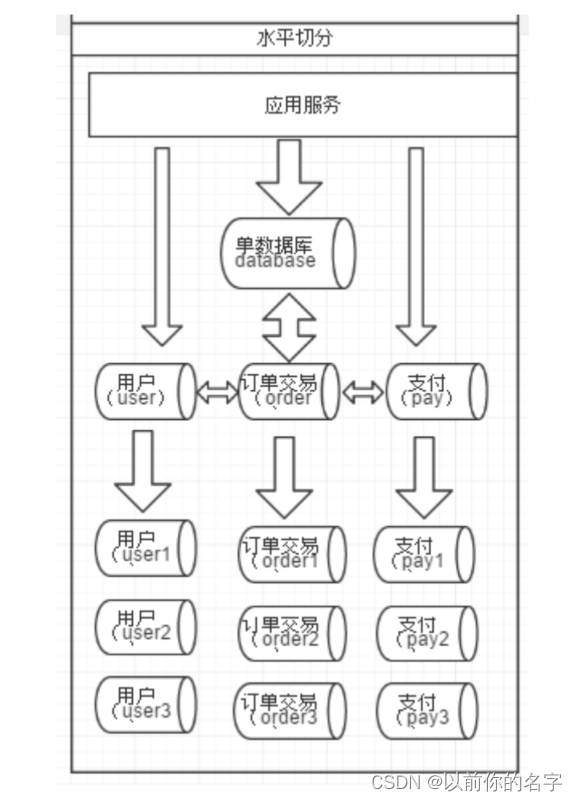
拆分数据就需要定义分片规则。关系型数据库是行列的二维模型,拆分的第一原则是找到拆分维度。比如从会员的角度来分析,商户订单交易类系统中查询会员某天某月某个订单,那么就需要按照会员结合日期来拆分,不同的数据按照会员id做分组,这样所有的数据查询join都会在单库内解决;如果从商户的角度来讲,要查询某个商家某天所有的订单数,就需要按照商户id做拆分;但是如果系统既想按照会员拆分,又想按照商家数据拆分,就会有一定的困难,需要综合考虑找到合适的分片。
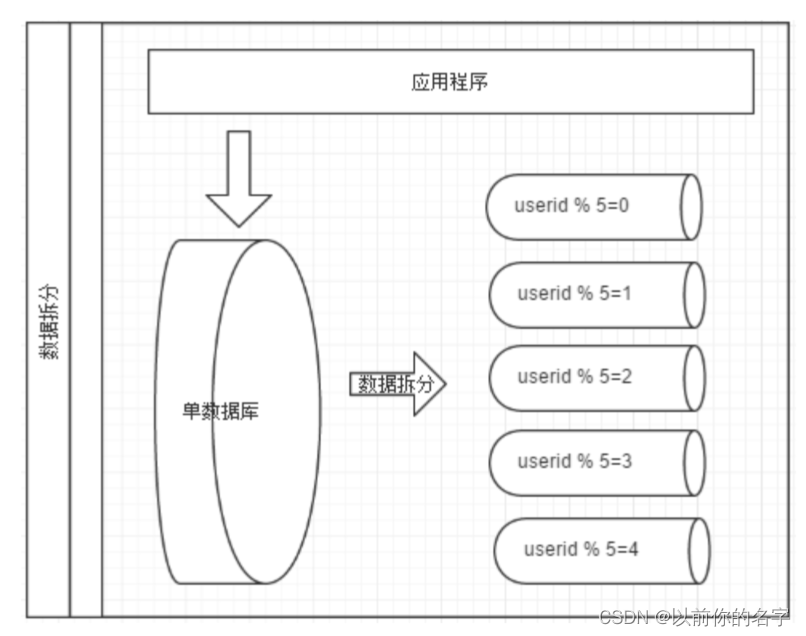
几种典型的分片规则包括:
1、按照用户id取模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中;
2、按照日期,将不同月甚至日的数据分散到不同的库中;
3、按照某个特定的字段求模,或者根据特定范围段分散到不同的库中。
如图,切分原则都是根据业务找到适合的切分规则分散到不同的库,下图是用用户id求模的案例:
数据做完了水平拆分之后也是有优缺点的。
优点:
1、拆分规则抽象好,join操作基本可以数据库做;
2、不存在单库大数据,高并发的性能瓶颈;
3、应用端改造较少;
4、提高了系统的稳定性跟负载能力
缺点:
1、拆分规则难以抽象
2、分片事务一致性难以解决
3、数据多次扩展跟维护量极大
4、跨库join性能较差
3、总结
我们刚刚讲解了数据切分的两种方式,会发现每种方式都有自己的缺点,但是他们之间有共同的缺点,分别是:
1、引入了分布式事务的问题
2、跨节点join的问题
3、跨节点合并排序分页的问题
4、多数据源管理的问题
针对数据源管理,目前主要有两种思路:
1、客户端模式,在每个应用程序模块中配置管理自己需要的一个或多个数据源,直接访问各个数据库,在模块内完成数据的整合
2、通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;
在实际的生产环境中,我们都会选择第二种方案来解决问题,尤其是系统不断变得庞大复杂的时候,其实这是非常正确的,虽然短期内付出的成本可能会比较大,但是对整个系统的扩展性来说,是非常有帮助的。
mycat通过数据切分解决传统数据库的缺陷,又有了nosql易于扩展的优点。通过中间代理层规避了多数据源的数据问题,对应用完全透明,同时对数据切分后存在的问题,也做了解决方案。
mycat在做数据切分的时候应该尽可能的遵循以下原则,当然这也是经验之谈,最终的落地实现还是要看具体的应用场景在做具体的分析
第一原则:能不切分尽量不要切分
第二原则:如果要切分一定要选择合适的切分规则,提前规划好
第三原则:数据切分尽量通过数据冗余或表分组来降低跨库join的可能
第四原则:由于数据库中间件对数据join实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表join。
4、mycat的配置文件讲解
在之前的操作中,我们已经做了部分文件的配置,但是具体的属性并没有讲解,下面我们讲解下每一个配置文件具体的属性以及相关的基本配置。
1、搞定schema.xml文件
schema.xml作为mycat中重要地配置文件之一,管理者mycat的逻辑库、表、分片规则、DataNode以及DataSource。
1、schema标签
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema>
schema标签用于定义mycat实例中的逻辑库,mycat可以有多个逻辑库,每个逻辑库都有自己相关的配置,可以使用schema标签来划分这些不同的逻辑库。如果不配置schame,那么所有的表配置都将属于同一个默认的逻辑库。
**dataNode:**该属性用于绑定逻辑库到某个具体的database上。
**checkSQLschema:**当该值为true时,如果执行select * from TESTDB.user,那么mycat会将语句修改为select * from user,即把表示schema的字符去掉,避免发送到后端数据库执行时报错。
**sqlMaxLimit:**当该值设置为某个数值的时候,每次执行的sql语句,如果没有加上limit语句,mycat也会自动加上对应的值。例如,当设置值为100的时候,那么select * from user的效果跟执行select * from user limit 100相同。如果不设置该值的话,mycat默认会把所有的数据信息都查询出来,造成过多的输出,所以,还是建议设置一个具体的值,以减少过多的数据返回。当然sql语句中可以显式的制定limit的大小,不受该属性的约束。
2、table标签
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" ></table>
table标签定义了mycat中的逻辑表,所有需要拆分的表都需要在这个标签中定义。
**name:**定义逻辑表的表名,这个名字就如同创建表的时候指定的表名一样,同个schema标签中定义的名字必须唯一。
**dataNode:**定义这个逻辑表所属的dataNode,该属性的值需要和dataNode标签中的name属性值对应,如果需要定义的dn过多,可以使用如下方法减少配置:
<table name="travelrecord" dataNode="multipleDn$0-99,multipleDn2$100-199" rule="auto-shardinglong" ></table>
<dataNode name="multipleDn$0-99" dataHost="localhost1" database="db$0-99" ></dataNode>
<dataNode name="multipleDn2$100-199" dataHost="localhost1" database=" db$100-199" ></dataNode>
**rule:**该属性用于指定逻辑表要使用的规则名字,规则名字在rule.xml中定义,必须与tableRule标签中的name属性值一一对应
**ruleRequired:**该属性用于指定表是否绑定分片规则,如果配置为true,但没有配置具体rule的话,程序会报错。
**primaryKey:**该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就会发送查询语句到所有配置的DN上,如果使用改属性配置真实表的主键。那么mycat会缓存主键与具体DN的信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句到具体的DN,但是尽管配置改属性,如果缓存没有命中的话,还是会发送语句给具体的DN来获得数据
**type:**该属性定义了逻辑表的类型,目前逻辑表只有全局表和普通表两种类型。对应的配置:
全局表:global
普通表:不指定该值为global的所有表
**autoIncrement:**mysql 对非自增长主键,使用 last_insert_id()是不会返回结果的,只会返回 0。所以,只有定义了自增长主键的表才可以用 last_insert_id()返回主键值。mycat 目前提供了自增长主键功能,但是如果对应的 mysql 节点上数据表,没有定义 auto_increment,那么在 mycat 层调用 last_insert_id()也是不会返回结果的。由于 insert 操作的时候没有带入分片键, mycat 会先取下这个表对应的全局序列,然后赋值给分片键。 这样才能正常的插入到数据库中,最后使用 last_insert_id()才会返回插入的分片键值。如果要使用这个功能最好配合使用数据库模式的全局序列。使用 autoIncrement=“true” 指定这个表有使用自增长主键,这样 mycat 才会不抛出分片键找不到的异常。使用 autoIncrement=“false” 来禁用这个功能,当然你也可以直接删除掉这个属性。默认就是禁用的。
**needAddLimit:**指定表是否需要自动的在每个语句后面加上limit限制。由于使用了分库分表,数据量有时会特别巨大。这时候执行查询语句,如果恰巧又忘记了加上数量限制的话,那么查询所有的数据出来,就会执行很久的时间,所以mycat自动为我们加上了limit 100。当前如果语句中又limit,那么就不会添加了。
3、childTable标签
childTable标签用于定义ER分片的子表。通过标签上的属性与父表进行关联。
**name:**定义子表的表名
**joinKey:**插入子表的时候会使用这个列的值查找父表存储的数据节点
**parentKey:**属性指定的值一般为与父表建立关联关系的列名。程序首先获取joinkey的值,再通过parentKey属性指定的列名产生查询语句,通过执行该语句得到父表存储再哪个分片上,从而确定子表存储的位置。
**primaryKey:**跟table标签所描述相同
**needAddLimit:**跟table标签所描述相同
4、dataNode标签
<dataNode name="dn1" dataHost="lch3307" database="db1" ></dataNode>
dataNode标签定义了mycat中的数据节点,也就是我们通常说的数据分片,一个dataNode标签就是一个独立的数据分片。
**name:**定义数据节点的名字,这个名字需要是唯一的,我们需要再table标签上应用这个名字,来建立表与分片对应的关系
**dataHost:**该属性用于定义该分片属于哪个数据库实例,属性值是引用dataHost标签上定义的name属性。
**database:**该属性用于定义该分片属性哪个具体数据库实力上的具体库,
5、dataHost标签
该标签定义了具体的数据库实例、读写分离配置和心跳语句
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<!-- <readHost host="hostS1" url="localhost:3306" user="root" password="123456"
/> -->
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
**name:**唯一标识dataHost标签,供上层的标签使用
**maxcon:**指定每个读写实例连接池的最大连接
**mincon:**指定每个读写实例连接连接池的最小链接,初始化连接池的大小
**balance:**负载均衡类型:
0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
1:全部的readHost和stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡
2:所有读操作都随机的再writeHost、readHost上分发
3:所有读请求随机的分发到writeHost对应readHost执行,writeHost不负担读压力,在之后的版本中失效。
**writeType:**写类型
writeType=0:所有的写操作发送到配置的第一个writeHost,第一个挂了切换到还生存的第二个writeHost,重启之后以切换后的为准,切换记录保存在配置文件 dnindex.properties
writeType=1:所有写操作都随机的发送到配置的writeHost,1.5以后废弃不推荐
**dbType:**指定后端连接的数据库类型,如MySQL,mongodb,oracle
**dbDriver:**指定连接后端数据库使用的Driver,目前可选的值有native和JDBC。使用native的话,因为这个值执行的是二进制的mysql协议,所以可以使用mysql和maridb,其他类型的数据库则需要使用JDBC驱动来支持。
**switchType:**是否进行主从切换
-1:表示不自动切换
1:默认值,自动切换
2:基于mysql主从同步的状态决定是否切换
6、heartbeat标签
这个标签指明用于和后端数据库进行心跳检测的语句。
2、搞定server.xml文件
server.xml几乎保存了所有mycat需要的系统配置信息。
<user name="test">
<property name="password">test</property>
<property name="schemas">TESTDB</property>
<property name="schemas">TESTDB</property>
<property name="schemas">TESTDB</property>
<property name="schemas">TESTDB</property>
<privileges check="false">
<schema name="TESTDB" dml="0010" showTables="custome/mysql">
<table name="tbl_user" dml="0110"></table>
<table name="tbl_dynamic" dml="1111"></table>
</schema>
</privileges>
</user>
server.xml中的标签本就不多,这个标签主要用于定义登录mycat的用户和权限。
property标签用来声明具体的属性值,name用来指定用户名,password用来修改密码,readonly用来限制用户是否是只读的,schemas用来控制用户课访问的schema,如果有多个的话,用逗号分隔
privileges标签是对用户的schema及下级的table进行精细化的DML控制,privileges节点的check属性适用于标识是否开启DML权限检查,默认false标识不检查,当然不配置等同于不检查
在进行检查的时候,是通过四个二进制位来标识的,insert,update,select,delete按照顺序标识,0表示未检查,1表示要检查
system标签表示系统的相关属性:
| 属性 | 含义 | 备注 |
|---|---|---|
| charset | 字符集设置 | utf8,utf8mb4 |
| defaultSqlParser | 指定的默认解析器 | druidparser,fdbparser(1.4之后作废) |
| processors | 系统可用的线程数, | 默认为机器CPU核心线程数 |
| processorBufferChunk | 每次分配socket direct buffer的大小 | 默认是4096个字节 |
| processorExecutor | 指定NIOProcessor共享的businessExecutor固定线程池大小,mycat在处理异步逻辑的时候会把任务提交到这个线程池中 | |
| sequnceHandlerType | mycat全局序列的类型 | 0为本地文件,1为数据库方式,2为时间戳方式,3为分布式ZK ID生成器,4为zk递增id生成 |
3、rule.xml
rule.xml里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同,这个文件里面主要有tableRule和function这两个标签。
1、tableRule
这个标签被用来定义表规则,定义的表规则在schema.xml文件中
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
name属性指定唯一的名字,用来标识不同的表规则
内嵌的rule标签则指定对物理表中的哪一列进行拆分和使用什么路由算法
columns内指定要拆分的列的名字
algorithm使用function标签中的那么属性,连接表规则和具体路由算法。当然,多个表规则可以连接到同一个路由算法上。
2、function
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
name指定算法的名字
class指定路由算法具体的类名字
property为具体算法需要用到的一些属性






![[黑盾CTF 2023] secret_message 复现](https://img-blog.csdnimg.cn/ce77087f9c8b4ed2b832ecb9436daf02.png)