🙈作者简介:练习时长两年半的Java up主
🙉个人主页:程序员老茶
🙊 ps:点赞👍是免费的,却可以让写博客的作者开兴好久好久😎
📚系列专栏:Java全栈,计算机系列(火速更新中)
💭 格言:种一棵树最好的时间是十年前,其次是现在
🏡动动小手,点个关注不迷路,感谢宝子们一键三连
目录
- 课程名:Java
- 内容/作用:知识点/设计/实验/作业/练习
- 学习:Docker容器技术
- Docker容器技术
- 容器技术入门
- 环境安装和部署
- 从虚拟机到容器
- 容器工作机制简述
- 容器与镜像
- 初识容器镜像
- 镜像结构介绍
- 构建镜像
- 发布镜像到远程仓库
- 实战:使用IDEA构建SpringBoot程序镜像
- 容器网络管理
- 容器网络类型
- 用户自定义网络
- 容器间网络
- 容器外部网络
- 容器存储管理
- 容器持久化存储
- 容器数据共享
- 容器资源管理
- 容器控制操作
- 物理资源管理
- 容器监控
- 单机容器编排
- 快速开始
- 部署完整项目
- 总结
课程名:Java
内容/作用:知识点/设计/实验/作业/练习
学习:Docker容器技术
Docker容器技术
Docker是一门平台级别的技术,涉及的范围很广,所以,在开始之前,请确保你完成:Java SpringBoot 篇(推荐完成SpringCloud篇再来)视频教程及之前全部路线,否则学习会非常吃力,另外推荐额外掌握:《计算机网络》、《操作系统》相关知识。学一样东西不能完全靠记忆来完成,而是需要结合自己所学的基础知识加以理解,一般来说,单凭记忆能够掌握的东西往往是最廉价的。
Docker官网:https://www.docker.com
课前准备:配置2C2G以上Linux服务器一台,云服务器、虚拟机均可。
容器技术入门
随着时代的发展,Docker也逐渐走上了历史舞台,曾经我们想要安装一套环境,需要花费一下午甚至一整天来配置和安装各个部分(比如运行我们自己的SpringBoot应用程序,可能需要安装数据库、安装Redis、安装MQ等,各种各样的环境光是安装就要花费很多时间,真的是搞得心态爆炸),而有了Docker之后,我们的程序和环境部署就变得非常简单了,我们只需要将这些环境一起打包成一个镜像。而到服务器上部署时,可以直接下载镜像实现一键部署,是不是很方便?
包括我们在学习SpringCloud需要配置的各种组件,可能在自己电脑的环境中运行会遇到各种各样的问题(可能由于电脑上各种环境没配置,导致无法运行),而现在只需要下载镜像就能直接运行,所有的环境全部在镜像中配置完成,开箱即用。
真的有这么神奇吗?我们来试试看。
环境安装和部署
首先我们还是先将Docker环境搭建好(建议和我同一个环境,不然出了问题只能自己想办法了),这里我们使用:
- Ubuntu 22.04 操作系统
Docker分为免费的CE(Community Edition)社区版本和EE(Enterprise Edition)企业级付费版本,所以我们这里选择docker-ce进行安装。官方安装文档:https://docs.docker.com/engine/install/ubuntu/
首先安装一些工具:
sudo apt-get install ca-certificates curl gnupg lsb-release
不过在Ubuntu22.04已经默认安装好了。接着安装官方的GPG key:
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
最后将Docker的库添加到apt资源列表中:
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
接着我们更新一次apt:
sudo apt update
最后安装Docker CE版本:
sudo apt install docker-ce
等待安装完成就可以了:
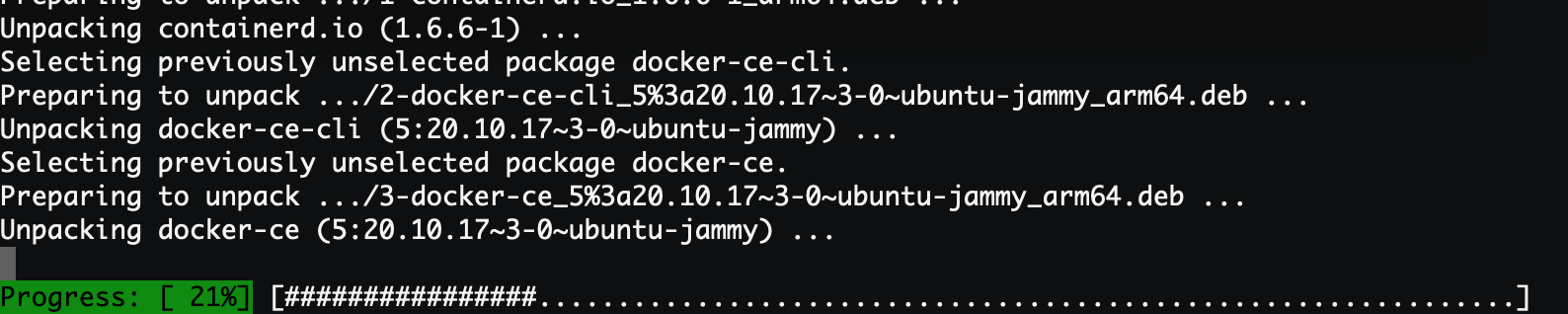

可以看到安装成功后版本是20.10.17,当然可能你们安装的时候就是更新的版本了。最后我们将当前用户添加到docker用户组中,不然每次使用docker命令都需要sudo执行,很麻烦:
sudo usermod -aG docker <用户名>
配置好后,我们先退出SSH终端,然后重新连接就可以生效了。
这样我们Docker 的学习环境就配置好了,现在我们就尝试通过Docker来部署一个Nginx服务器试试看,使用很简单,只需要一个命令就可以了(当然现在看不懂没关系,我们后面会细嗦):
sudo docker run -d -p 80:80 nginx
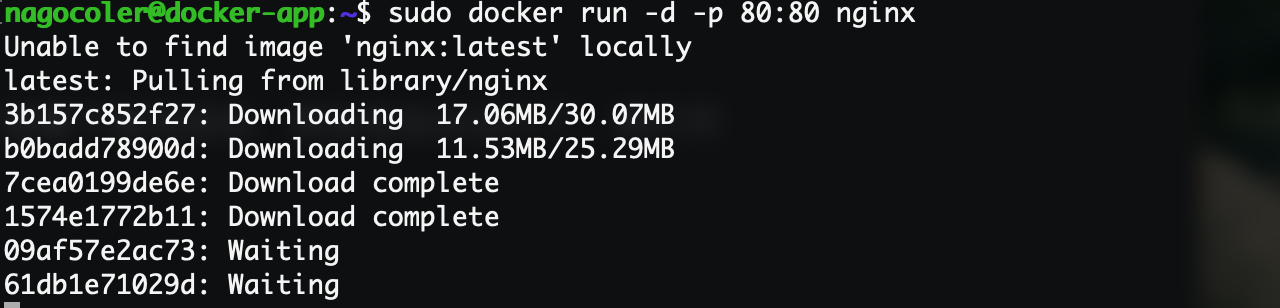
首选它会从镜像仓库中下载对应的镜像,国内访问速度还行,不需要单独配置镜像源。接着下载完成后,就会在后台运行了,我们可以使用浏览器访问试试看:

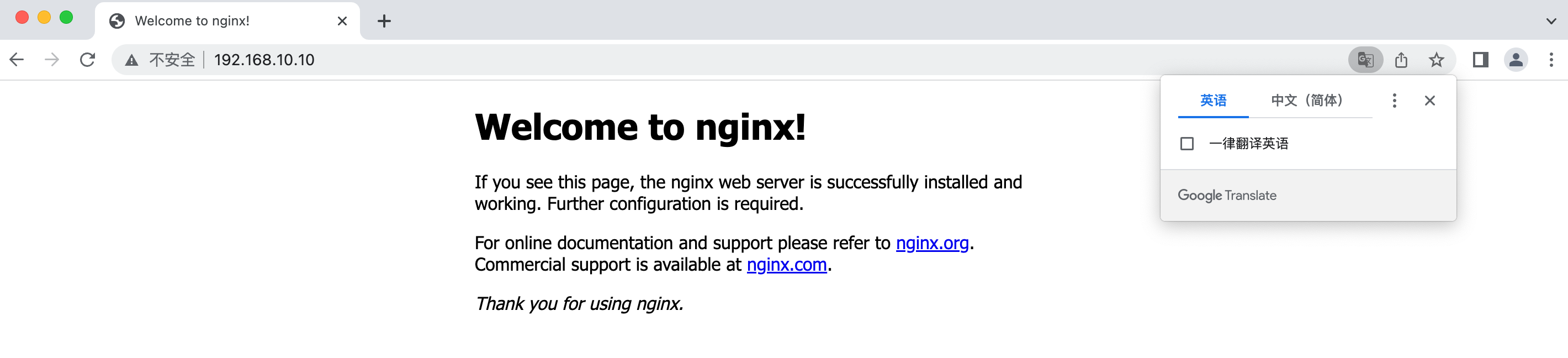
可以看到,Nginx服务器已经成功部署了,但是实际上我们并没有在Ubuntu中安装Nginx,而是通过Docker运行的镜像来进行服务器搭建的,是不是感觉玩法挺新奇的。除了Nginx这种简单的应用之外,我们还可以通过Docker来部署复杂应用,之后我们都会一一进行讲解的。
从虚拟机到容器
前面我们成功安装了Docker学习环境,以及浅尝了一下Docker为我们带来的应用快速部署。在正式进入学习之前,我们就先从Docker的发展开始说起。
在Docker出现之前,虚拟化技术可以说是占据了主导地位。首先我们来谈谈为什么会出现虚拟化技术,我们知道在企业中服务器可以说是必不可少的一种硬件设施了,服务器也是电脑,但是不像我们的家用电脑,服务器的配置是非常高的,我们家用电脑的CPU可能最高配也就20核了,内存很少有超过128G的电脑,64G内存的家用电脑可以算奢侈了。而服务器不一样,服务器级别的CPU动辄12核,甚至服务器还能同时安装多块CPU,能直接堆到好几十核:

我们家用级CPU一般是AMD的锐龙系列和Intel的酷睿系列(比如i3 i5 i7 i9),而服务器CPU一般是Intel的志强(Xeno)系列,这种CPU的特点就是核心数非常多:

并且服务器CPU相比家用CPU的功耗也会更大,因此服务器CPU的发热量非常高,如果你有幸去过机房,你会听见散热风扇猛烈转动的声音(但是服务器CPU的频率没有家用级CPU高,一般大型游戏要求的是高频率而不是核心数,而且功耗也比较大,所以并不适合做家用电脑,所以以后在网上买台式机,看到什么“i9级”CPU千万别买,是这些黑心商家把国外服务器上淘汰下来的服务器CPU(洋垃圾)装成电脑卖给你,所以会很便宜,同时核心数又能媲美i9,所以还是一分钱一分货实在)
服务器无论是CPU资源还是内存资源都远超家用电脑,而我们编写的Java后端项目,最后都会运行在这些服务器上,不过有一个问题,服务器既然有这么丰富的硬件资源,就跑咱们这一个小Java后端,是不是有点核弹炸蚊子的感觉了?可能顶多就用了服务器5%的硬件资源,服务器这么牛就运行个这也太浪费了吧。
所以,为了解决这种资源利用率只有5%-15%的情况,咱们能不能想个办法,把这一台服务器分成多个小服务器使用,每个小服务器只分配一部分的资源,比如分一个小服务器出去,只给2个CPU核心和4G内存。但是由于设计上的问题,我们的电脑只能同时运行一个操作系统,那么怎么办呢?此时虚拟化技术就开始兴起了。
虚拟化使用软件来模拟硬件并创建虚拟计算机系统。这样一来,企业便可以在单台服务器上运行多个虚拟系统,也就是运行多个操作系统和应用,而这可以实现规模经济以及提高效益。比如我们电脑上经常使用的VMware就是一种民用级虚拟化软件:

我们可以使用VMware来创建虚拟机,这些虚拟机实际上都是基于我们当前系统上的VMware软件来运行的,当然VMware也有服务器专用的虚拟化软件,有了虚拟化之后,我们的服务器就像这样:
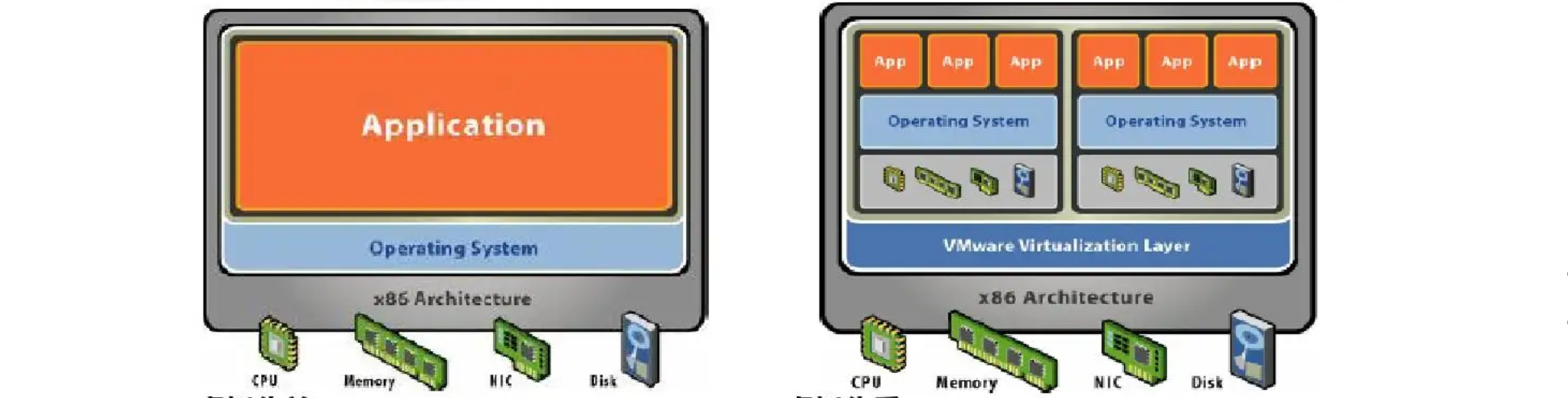
相当于通过虚拟机模拟了很多来电脑出来,这样我们就可以在划分出来的多台虚拟机上分别安装系统和部署我们的应用程序了,并且我们可以自由分配硬件资源,合理地使用。一般在企业中,不同的应用程序可能会被分别部署到各个服务器上,隔离开来,此时使用虚拟机就非常适合。
实际上我们在什么腾讯云、阿里云租的云服务器,都是经过虚拟化技术划分出来的虚拟机而已。
那么,既然虚拟机都这么方便了,容器又是怎么杀出一条血路的呢?我们先来看看什么是容器。
容器和虚拟机比较类似,都可以为应用提供封装和隔离,都是软件,但是容器中的应用运行是寄托于宿主操作系统的,实际上依然是在直接使用操作系统的资源,当然应用程序之间环境依然是隔离的,而虚拟机则是完全模拟一台真正的电脑出来,直接就是两台不同的电脑。
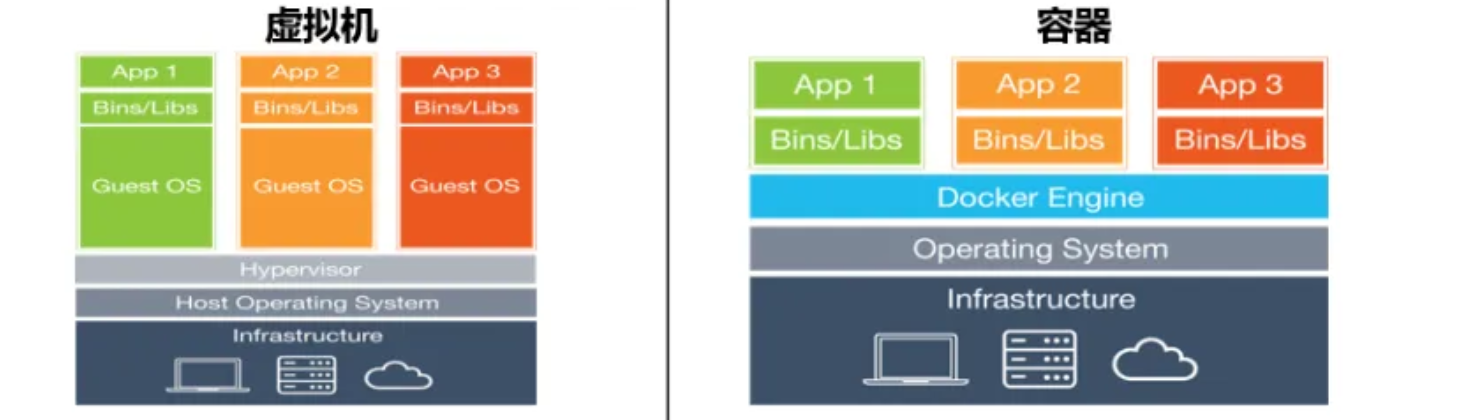
因此容器相比虚拟机就简单多了,并且启动速度也会快很多,开销小了不少。
不过容器火的根本原因还是它的集装箱思想,我们知道,如果我们要写一个比如论坛、电商这类的Java项目,那么数据库、消息队列、缓存这类中间件是必不可少的,因此我们如果想要将一个服务部署到服务器,那么实际上还要提前准备好各种各样的环境,先安装好MySQL、Redis、RabbitMQ等应用,配置好了环境,再将我们的Java应用程序启动,整个流程下来,光是配置环境就要浪费大量的时间,如果是大型的分布式项目,可能要部署很多台机器,那岂不是我们得一个一个来?项目上个线就要花几天时间,显然是很荒唐的。
而容器可以打包整个环境,比较MySQL、Redis等以及我们的Java应用程序,可以被一起打包为一个镜像,当我们需要部署服务时,只需要像我们之前那样,直接下载镜像运行即可,不需要再进行额外的配置了,整个镜像中环境是已经配置好的状态,开箱即用。

而我们要重点介绍的就是Docker了,可以看到它的图标就是一只鲸鱼,鲸鱼的上面是很多个集装箱,每个集装箱就是我们的整个环境+应用程序,Docker可以将任何应用及其依赖打包为一个轻量级,可移植,自包含的容器,容器可以运行在几乎所有的操作系统上。
容器工作机制简述
我们先来看看Docker的整体架构:
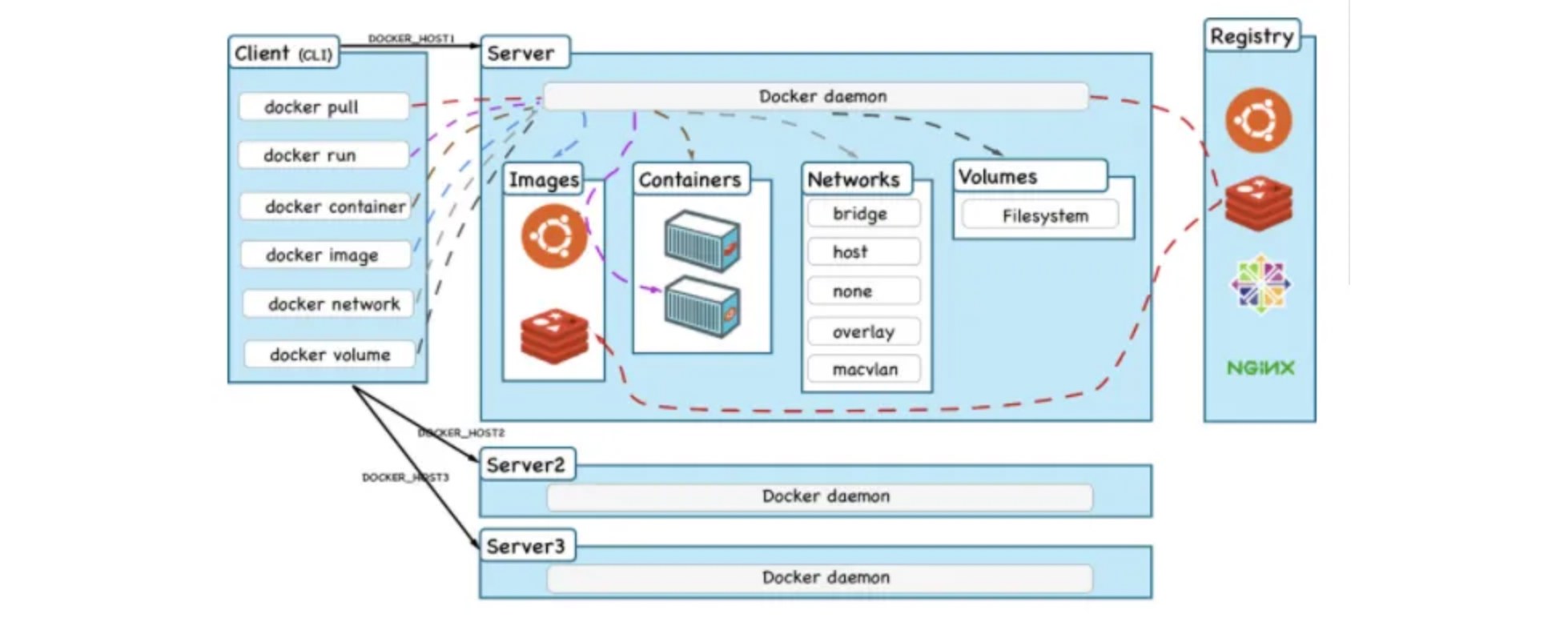
实际上分为三个部分:
- Docker 客户端:也就是我们之前使用的docker命令,都是在客户端上执行的,操作会发送到服务端上处理。
- Docker 服务端:服务端就是启动容器的主体了,一般是作为服务在后台运行,支持远程连接。
- Registry:是存放Docker镜像的仓库,跟Maven一样,也可以分公有和私有仓库,镜像可以从仓库下载到本地存放。
当我们需要在服务器上部署一个已经打包好的应用和环境,我们只需要下载打包好的镜像就可以了,我们前面执行了:
sudo docker run -d -p 80:80 nginx
实际上这个命令输入之后:
- Docker客户端将操作发送给服务端,告诉服务端我们要运行nginx这个镜像。
- Docker服务端先看看本地有没有这个镜像,发现没有。
- 接着只能从公共仓库Docker Hub去查找下载镜像了。
- 下载完成,镜像成功保存到本地。
- Docker服务端加载Nginx镜像,启动容器开始正常运行(注意容器和其他容器之间,和外部之间,都是隔离的,互不影响)
所以,整个流程中,Docker就像是一搜运输船,镜像就像是集装箱,通过运输船将世界各地的货物送往我们的港口,货物到达港口后,Docker并不关心集装箱里面的是什么,只需要创建容器开箱即用就可以了。相比我们传统的手动安装配置环境,不知道方便了几个层次。
不过容器依然是寄托于宿主主机的运行的,所以一般在生产环境下,都是通过虚拟化先创建多台主机,然后再到各个虚拟机中部署Docker,这样的话,运维效率就大大提升了。
从下一章开始,我们就正式地来学习一下Docker的各种操作。
容器与镜像
要启动容器最关键的就是镜像,我们来看看镜像相关的介绍。
初识容器镜像
首先我们来了解一下镜像的相关操作,比如现在我们希望把某个镜像从仓库下载到本地,这里使用官方的hello-world镜像:
docker pull hello-world
只需要输入pull命令,就可以直接下载到指定的镜像了:

可以看到对上面一行有一句Using default tag,实际上一个镜像的名称是由两部分组成的,一个是repository,还有一个是tag,一般情况下约定repository就是镜像名称,tag作为版本,默认为latest,表示最新版本。所以指定版本运行的话:
docker pull 名称:版本
之后为了教学方便,我们就直接使用默认的tag,不去指定版本了。
镜像下载之后会存放在本地,要启动这个镜像的容器,实际上就像我们之前那样,输入run命令就可以了:
docker run hello-world
当然如果仅仅是只想创建而不想马上运行的话,可以使用create命令:
docker create hello-world
可以看到成功启动了:
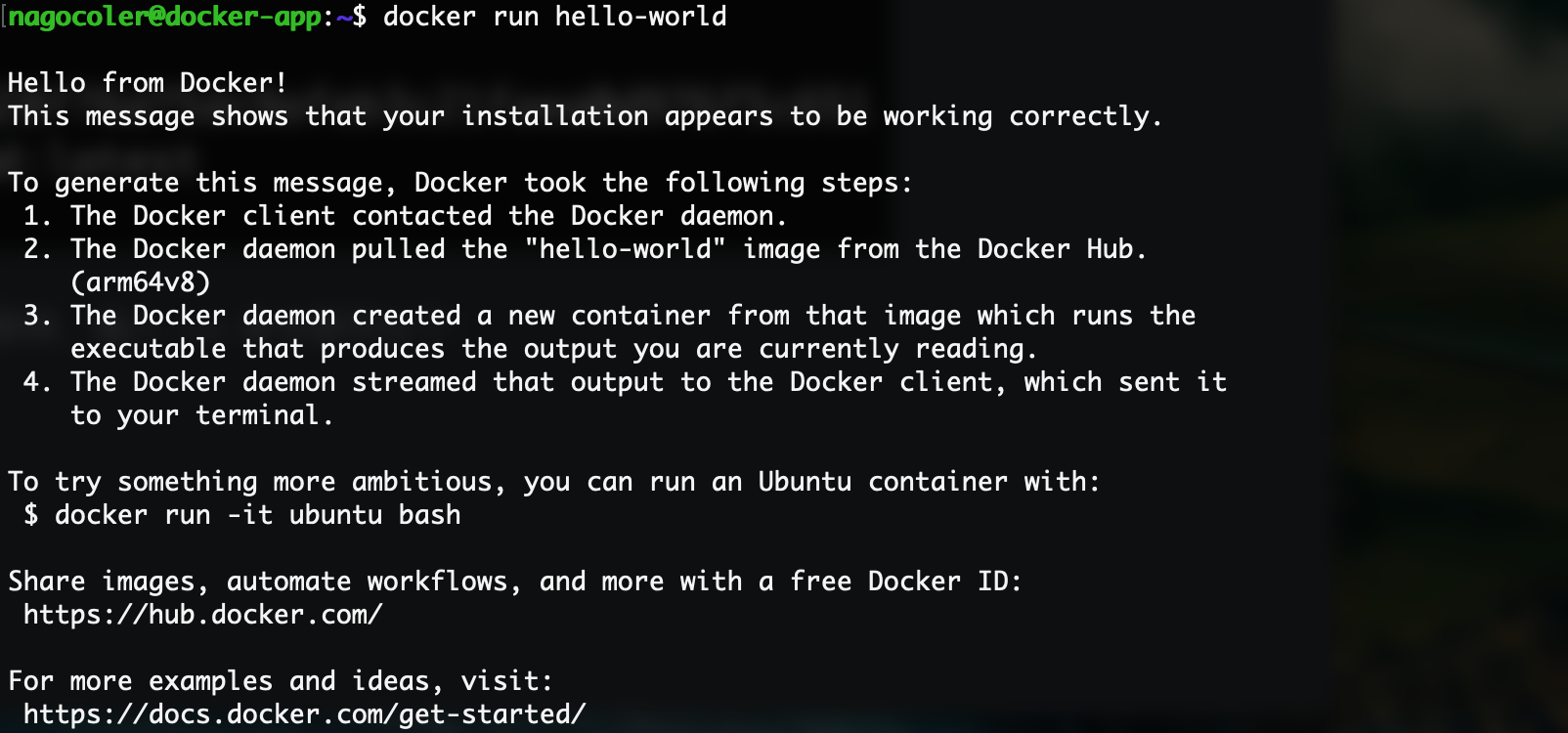
启动之后,会使用当前镜像自动创建一个容器,我们可以输入ps命令来查看当前容器的容器列表:
docker ps -a
注意后面要加一个-a表示查看所有容器(其他选项可以使用-h查看),如果不加的话,只会显示当前正在运行的容器,而HelloWorld是一次性的不是Nginx那样的常驻程序,所以容器启动打印了上面的内容之后,容器就停止运行了:

可以看到容器列表中有我们刚刚创建的hello-world以及我们之前创建的nginx(注意同一个镜像可以创建多个容器),每个容器都有一个随机生成的容器ID写在最前面,后面是容器的创建时间以及当前的运行状态,最后一列是容器的名称,在创建容器时,名称可以由我们指定也可以自动生成,这里就是自动生成的。
我们可以手动指定名称启动,在使用run命令时,添加--name参数即可:
docker run --name=lbwnb hello-world

我们可以手动开启处于停止状态的容器:
docker start <容器名称/容器ID>
注意启动的对象我们要填写容器的ID或是容器的名称才可以,容器ID比较长,可以不写全只写一半,但是你要保证你输入的不完全容器ID是唯一的。

如果想要停止容器直接输入stop命令就可以了:
docker stop <容器名称/容器ID>
或是重启:
docker restart <容器名称/容器ID>

如果我们不需要使用容器了,那么可以将容器删除,但是注意只有容器处于非运行状态时才可以删除:
docker rm <容器名称/容器ID>
当然如果我们希望容器在停止后自动删除,我们可以在运行时添加--rm参数:
docker run --rm 镜像名称

删除后,容器将不复存在,当没有任何关于nginx的容器之后,我们可以删除nginx的本地镜像:
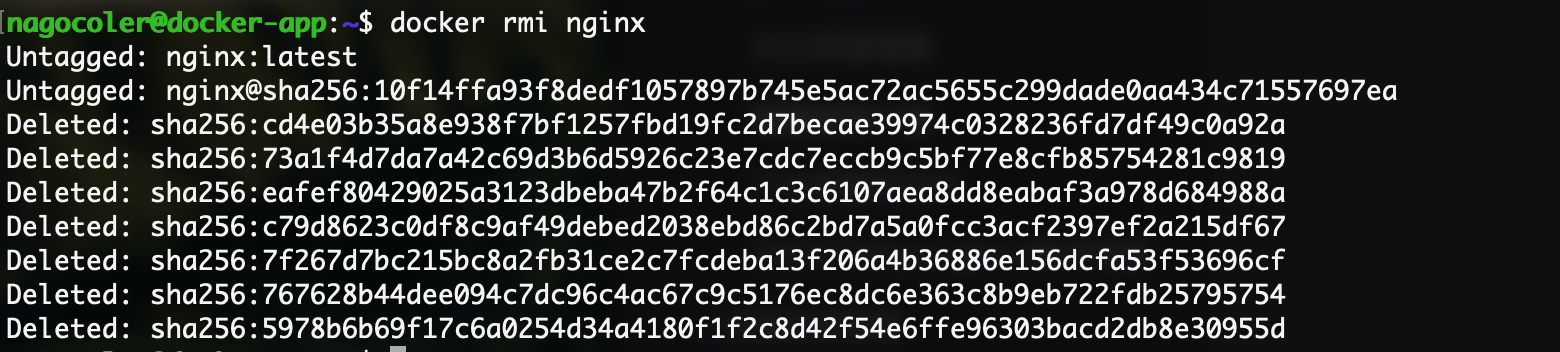
我们可以使用images命令来检查一下当前本地有那些镜像:
docker images

至此,我们已经了解了Docker的简单使用,在后面的学习中,我们还会继续认识更多的玩法。
镜像结构介绍
前面我们了解了Docker的相关基本操作,实际上容器的基石就是镜像,有了镜像才能创建对应的容器实例,那么我们就先从镜像的基本结构开始说起,我们来看看镜像到底是个什么样的存在。
我们在打包项目时,实际上往往需要一个基本的操作系统环境,这样我们才可以在这个操作系统上安装各种依赖软件,比如数据库、缓存等,像这种基本的系统镜像,我们称为base镜像,我们的项目之后都会基于base镜像进行打包,当然也可以不需要base镜像,仅仅是基于当前操作系统去执行简单的命令,比如我们之前使用的hello-world就是。
一般base镜像就是各个Linux操作系统的发行版,比如我们正在使用的Ubuntu,还有CentOS、Kali等等。这里我们就下载一下CentOS的base镜像:
docker pull centos
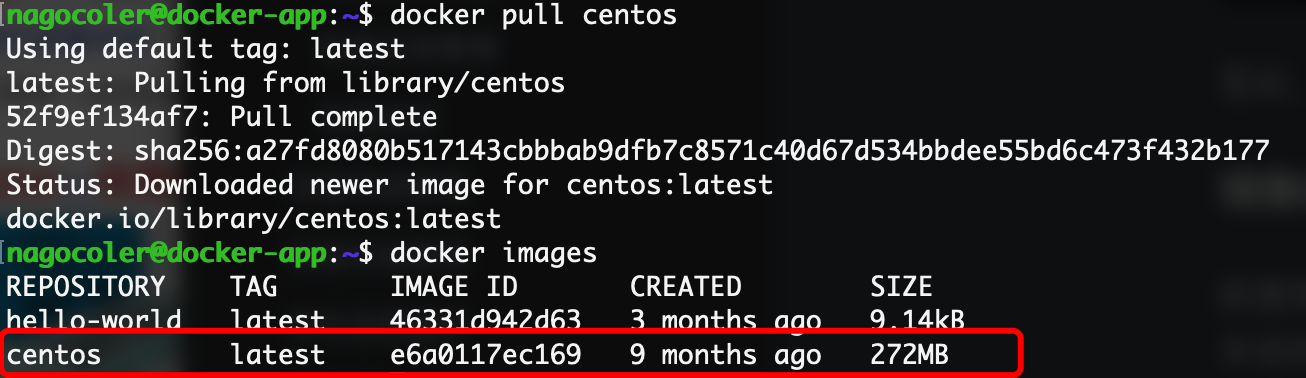
可以看到,CentOS的base镜像就已经下载完成,不像我们使用完整系统一样,base镜像的CentOS省去了内核,所以大小只有272M,这里需要解释一下base镜像的机制:

Linux操作体系由内核空间和用户空间组成,其中内核空间就是整个Linux系统的核心,Linux启动后首先会加bootfs文件系统,加载完成后会自动卸载掉,之后会加载用户空间的文件系统,这一层是我们自己可以进行操作的部分:
- bootfs包含了BootLoader和Linux内核,用户是不能对这层作任何修改的,在内核启动之后,bootfs会自动卸载。
- rootfs则包含了系统上的常见的目录结构,包括
/dev、/proc、/bin等等以及一些基本的文件和命令,也就是我们进入系统之后能够操作的整个文件系统,包括我们在Ubuntu下使用的apt和CentOS下使用的yum,都是用户空间上的。
base镜像底层会直接使用宿主主机的内核,也就是说你的Ubuntu内核版本是多少,那么base镜像中的CentOS内核版本就是多少,而rootfs则可以在不同的容器中运行多种不同的版本。所以,base镜像实际上只有CentOS的rootfs,因此只有300M大小左右,当然,CentOS里面包含多种基础的软件,还是比较臃肿的,而某些操作系统的base镜像甚至都不到10M。
使用uname命令可以查看当前内核版本:

因此,Docker能够同时模拟多种Linux操作系统环境,就不足为奇了,我们可以尝试启动一下刚刚下载的base镜像:
docker run -it centos
注意这里需要添加-it参数进行启动,其中-i表示在容器上打开一个标准的输入接口,-t表示分配一个伪tty设备,可以支持终端登录,一般这两个是一起使用,否则base容器启动后就自动停止了。

可以看到使用ls命令能够查看所有根目录下的文件,不过很多命令都没有,连clear都没有,我们来看看内核版本:

可以看到内核版本是一样的(这也是缺点所在,如果软件对内核版本有要求的话,那么此时使用Docker就直接寄了),我们输入exit就可以退出容器终端了,可以看到退出后容器也停止了:

当然我们也可以再次启动,注意启动的时候要加上-i才能进入到容器进行交互,否则会在后台运行:

基于base镜像,我们就可以在这基础上安装各种各样的软件的了,几乎所有的镜像都是通过在base镜像的基础上安装和配置需要的软件构建出来的:
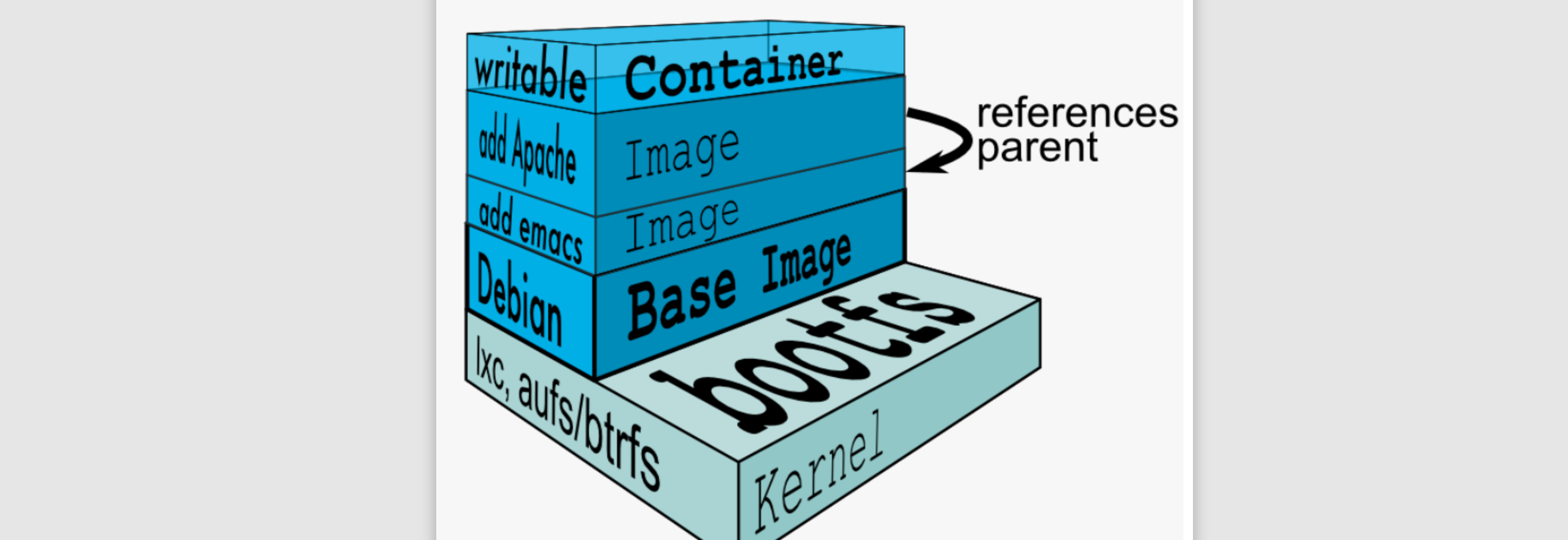
每安装一个软件,就在base镜像上一层层叠加上去,采用的是一种分层的结构,这样多个容器都可以将这些不同的层次自由拼装,比如现在好几个容器都需要使用CentOS的base镜像,而上面运行的软件不同,此时分层结构就很爽了,我们只需要在本地保存一份base镜像,就可以给多个不同的容器拼装使用,是不是感觉很灵活?
我们看到除了这些软件之外,最上层还有一个可写容器层,这个是干嘛的呢,为什么要放在最上面?
我们知道,所有的镜像会叠起来组成一个统一的文件系统,如果不同层中存在相同位置的文件,那么上层的会覆盖掉下层的文件,最终我们看到的是一个叠加之后的文件系统。当我们需要修改容器中的文件时,实际上并不会对镜像进行直接修改,而是在最顶上的容器层(最上面一般称为容器层,下面都是镜像层)进行修改,不会影响到下面的镜像,否则镜像就很难实现多个容器共享了。所以各个操作如下:
- 文件读取:要读取一个文件,Docker会最上层往下依次寻找,找到后则打开文件。
- 文件创建和修改:创建新文件会直接添加到容器层中,修改文件会从上往下依次寻找各个镜像中的文件,如果找到,则将其复制到容器层,再进行修改。
- 删除文件:删除文件也会从上往下依次寻找各个镜像中的文件,一旦找到,并不会直接删除镜像中的文件,而是在容器层标记这个删除操作。
也就是说,我们对整个容器内的文件进行的操作,几乎都是在最上面的容器层进行的,我们是无法干涉到下面所有的镜像层文件的,这样就很好地保护了镜像的完整性,才能实现多个容器共享使用。
构建镜像
前面我们已经了解了Docker镜像的结构,实际上所有常用的应用程序都有对应的镜像,我们只需要下载这些镜像然后就可以使用了,而不需要自己去手动安装,顶多需要进行一些特别的配置。当然要是遇到某些冷门的应用,可能没有提供镜像,这时就要我们手动去安装,接着我们就来看看如何构建我们自己的Docker镜像。构建镜像有两种方式,一种是使用commit命令来完成,还有一种是使用Dockerfile来完成,我们先来看第一种。
这里我们就做一个简单的例子,比如我们现在想要在Ubuntu的base镜像中安装Java环境,并将其打包为新的镜像(这个新的镜像就是一个包含Java环境的Ubuntu系统镜像)
咱们先启动Ubuntu镜像,然后使用yum命令(跟apt比较类似)来安装Java环境,首先是run命令:
docker pull ubuntu

接着启动:

直接使用apt命令来安装Java环境,在这之前先更新一下,因为是最小安装所以本地没有任何软件包:

接着输入:
apt install openjdk-8-jdk
等待安装完成:

这样,我们就完成了对Java环境的安装了,接着我们就可以退出这个镜像然后将其构建为新的镜像:

使用commit命令可以将容器保存为新的镜像:
docker commit 容器名称/ID 新的镜像名称


可以看到安装了软件之后的镜像大小比我们原有的大小大得多,这样我们就可以通过这个镜像来直接启动一个带Java环境的Ubuntu操作系统容器了。不过这种方式虽然自定义度很高,但是Docker官方并不推荐,这样的话使用者并不知道镜像是如何构建出来的,是否里面带了后门都不知道,并且这样去构建效率太低了,如果要同时构建多种操作系统的镜像岂不是要一个一个去敲?我们作为普通用户实际上采用Dokcerfile的方式会更好一些。
我们来看看如何使用Dockerfile的形式创建一个带Java环境的Ubuntu系统镜像。首先直接新建一个名为Dockerfile的文件:
touch Dockerfile
接着我们来进行编辑,Dockerfile内部需要我们编写多种指令来告诉Docker我们的镜像的相关信息:
FROM <基础镜像>
首先我们需要使用FROM指令来选择当前镜像的基础镜像(必须以这个指令开始),这里我们直接使用ubuntu作为基础镜像即可,当然如果不需要任何基础镜像的话,直接使用scratch表示从零开始构建,这里就不演示了。
基础镜像设定完成之后,我们就需要在容器中运行命令来安装Java环境了,这里需要使用RUN指令:
RUN apt update
RUN apt install -y openjdk-8-jdk
每条指令执行之后,都会生成一个新的镜像层。
OK,现在我们的Dockerfile就编写完成了,只需要完成一次构建即可:
docker build -t <镜像名称> <构建目录>
执行后,Docker会在构建目录中寻找Dockerfile文件,然后开始依次执行Dockerfile中的指令:
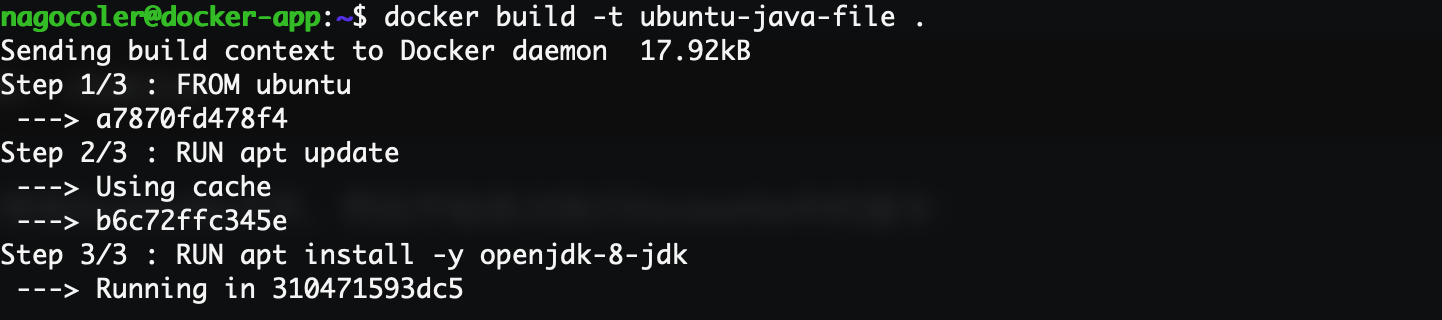
构建过程的每一步都非常清晰地列出来了,一共三条指令对应三步依次进行,我们稍微等待一段时间进行安装,安装过程中所以的日志信息会直接打印到控制台(注意Docker镜像构建有缓存机制,就算你现在中途退出了,然后重新进行构建,也会直接将之前已经构建好的每一层镜像,直接拿来用,除非修改了Dockerfile文件重新构建,只要某一层发生变化其上层的构建缓存都会失效,当然包括pull时也会有类似的机制)

最后成功安装,会出现在本地:

可以看到安装出来的大小跟我们之前的是一样的,因为做的事情是一模一样的。我们可以使用history命令来查看构建历史:

可以看到最上面两层是我们通过使用apt命令生成的内容,就直接作为当前镜像中的两层镜像,每层镜像都有一个自己的ID,不同的镜像大小也不一样。而我们手动通过commit命令来生成的镜像没有这个记录:

如果遇到镜像ID为missing的一般是从Docker Hub中下载的镜像会有这个问题,但是问题不大。用我们自己构建的镜像来创建容器就可以直接体验带Java环境的容器了:

有关Dockerfile的其他命令,我们还会在后续的学习中逐步认识。
发布镜像到远程仓库
前面我们学习了如何构建一个Docker镜像,我们可以将自己的镜像发布到Docker Hub中,就像Git远程仓库一样,我们可以将自己的镜像上传到这里:https://hub.docker.com/repositories,没有账号的先去进行注册。

点击右上角的创建仓库,然后填写信息:
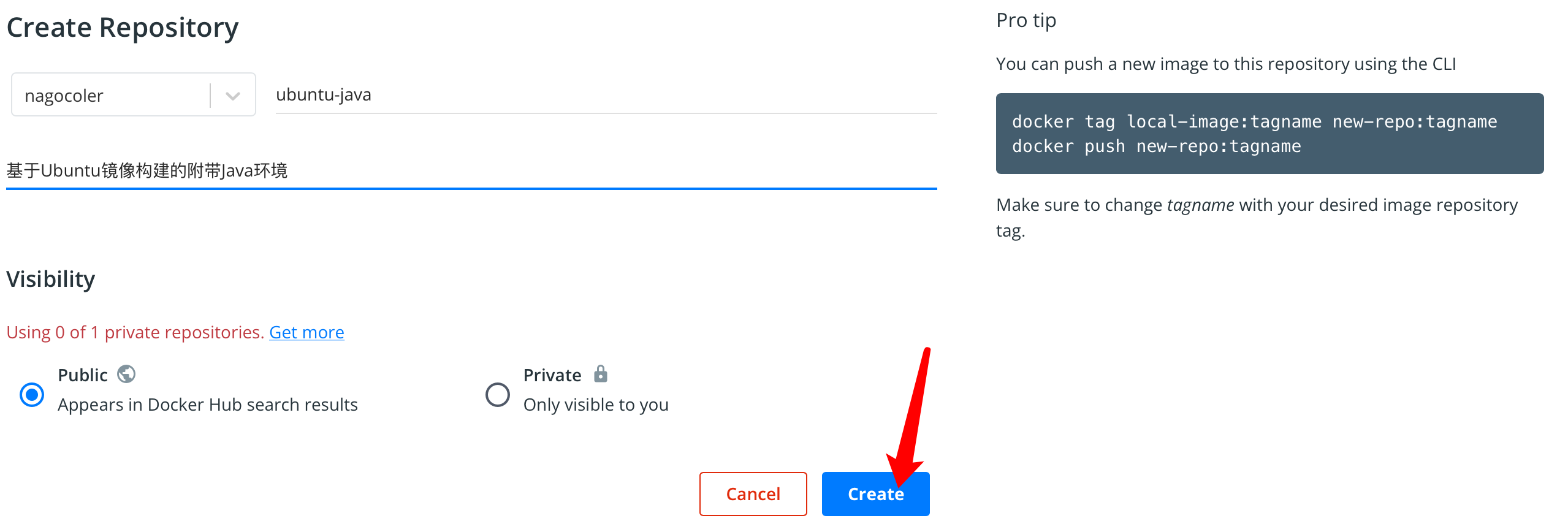
创建完成后,我们就有了一个公共的镜像仓库,我们可以将本地的镜像上传了,上传之前我们需要将镜像名称修改得规范一点,这里使用tag命令来重新打标签:
docker tag ubuntu-java-file:latest 用户名/仓库名称:版本
这里我们将版本改成1.0版本吧,不用默认的latest了。

修改完成后,会创建一个新的本地镜像,名称就是我们自己定义的了。接着我们需在本地登录一下:

登录成功后我们就可以上传了:
docker push nagocoler/ubuntu-java:1.0

哈哈,500M的东西传上去,还是有点压力的,如果实在太慢各位可以重新做一个简单点的镜像。上传完成后,打开仓库,可以看到已经有一个1.0版本了:
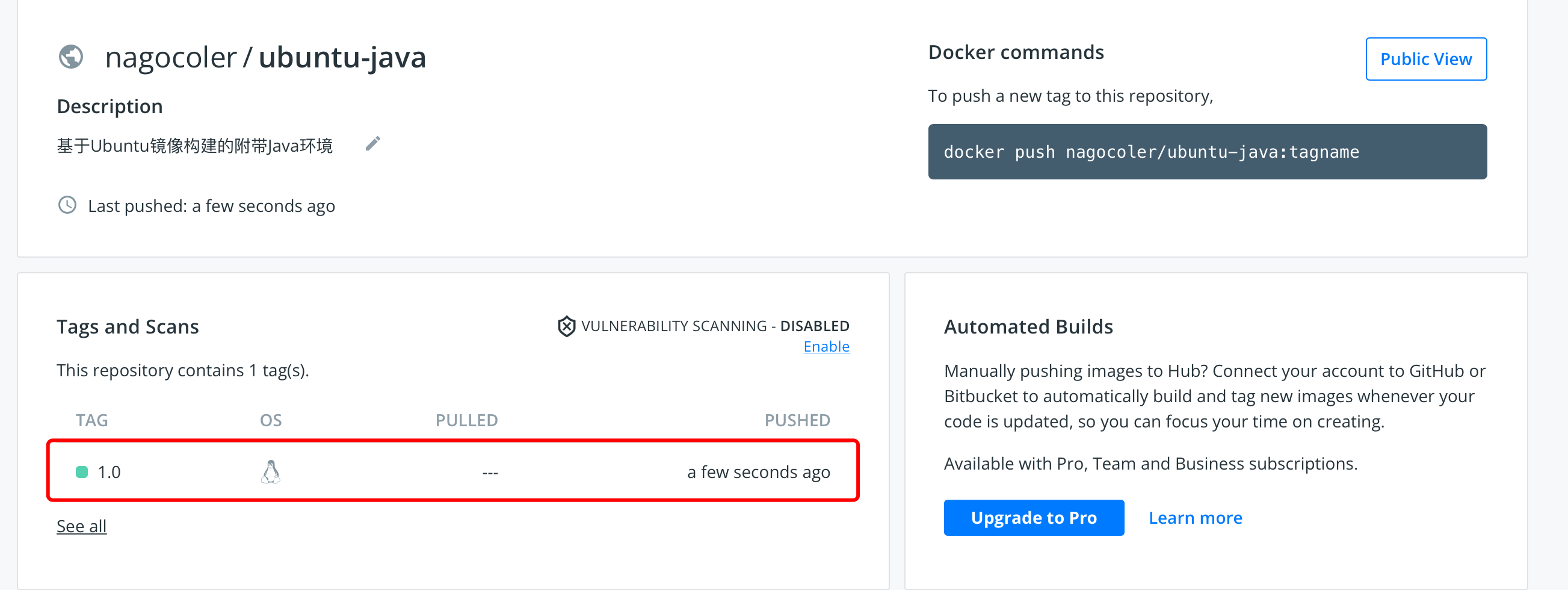

注意公共仓库是可以被搜索和下载的,所以我们这里把本地的镜像全部删掉,去下载我们刚刚上传好的镜像。这里我们先搜索一下,搜索使用search命令即可:
docker search nagocoler/ubuntu-java

我们可以使用pull命令将其下载下来:
docker pull nagocoler/ubuntu-java:1.0

上传之后的镜像是被压缩过的,所以下载的内容就比较少一些。运行试试看:
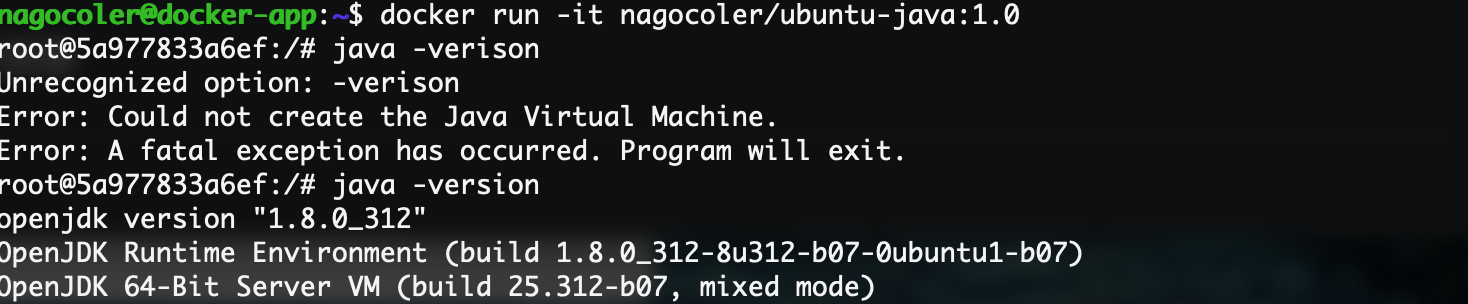
当然各位也可以让自己的同学或是在其他机器上尝试下载自己的镜像,看看是不是都可以正常运行。
Docker Hub也可以自行搭建私服,但是这里就不多做介绍了,至此,有关容器和镜像的一些基本操作就讲解得差不多了。
实战:使用IDEA构建SpringBoot程序镜像
这里我们创建一个新的SpringBoot项目,现在我们希望能够使用Docker快速地将我们的SpringBoot项目部署到安装了Docker的服务器上,我们就可以将其打包为一个Docker镜像。
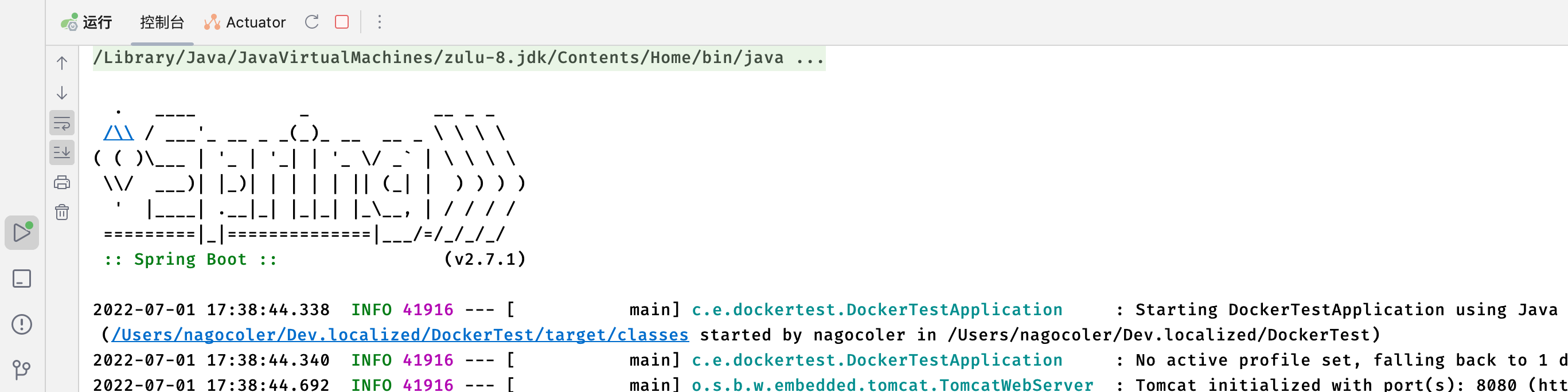
先创建好一个项目让它跑起来,可以正常运行就没问题了,接着我们需要将其打包为Docker镜像,这里创建一个新的Dockerfile:
FROM ubuntu
RUN apt update && apt install -y openjdk-8-jdk
首先还是基于ubuntu构建一个带Java环境的系统镜像,接着我们先将其连接到我们的Docker服务器进行构建,由于IDEA自带了Docker插件,所以我们直接点击左上角的运行按钮,选择第二项 “为Dockerfile构建镜像”:

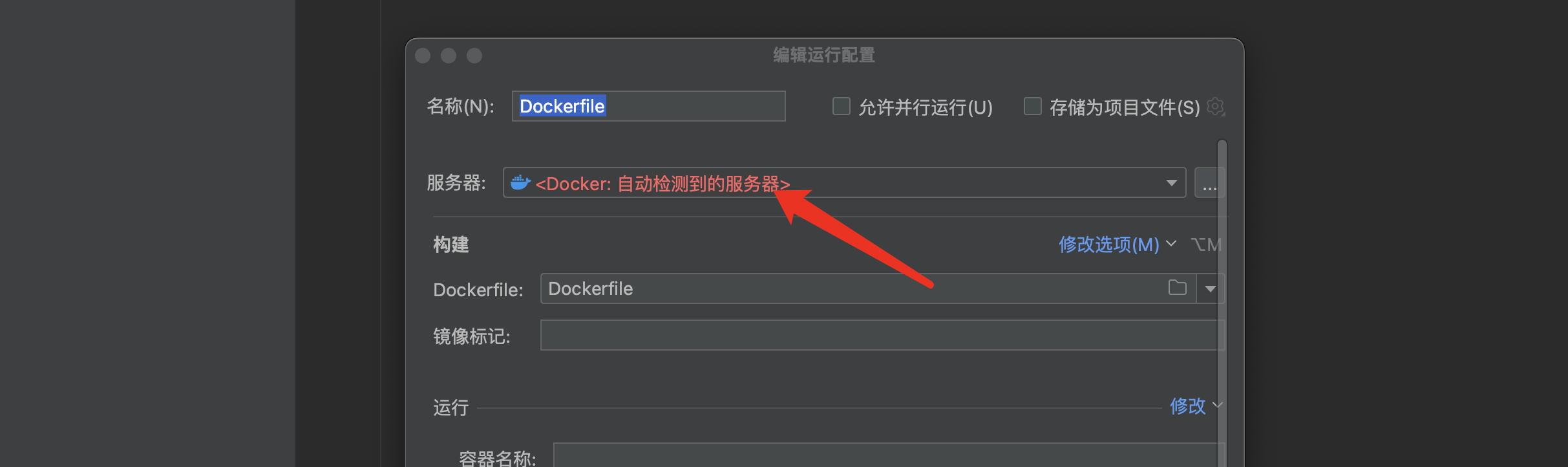
这里需要配置Docker的服务器,也就是我们在Ubuntu服务器安装的Docker,这里我们填写服务器相关信息,我们首选需要去修改一下Docker的一些配置,开启远程客户端访问:
sudo vim /etc/systemd/system/multi-user.target.wants/docker.service
打开后,添加高亮部分:

修改完成后,重启Docker服务,如果是云服务器,记得开启2375 TCP连接端口:
sudo systemctl daemon-reload
sudo systemctl restart docker.service
现在接着在IDEA中进行配置:
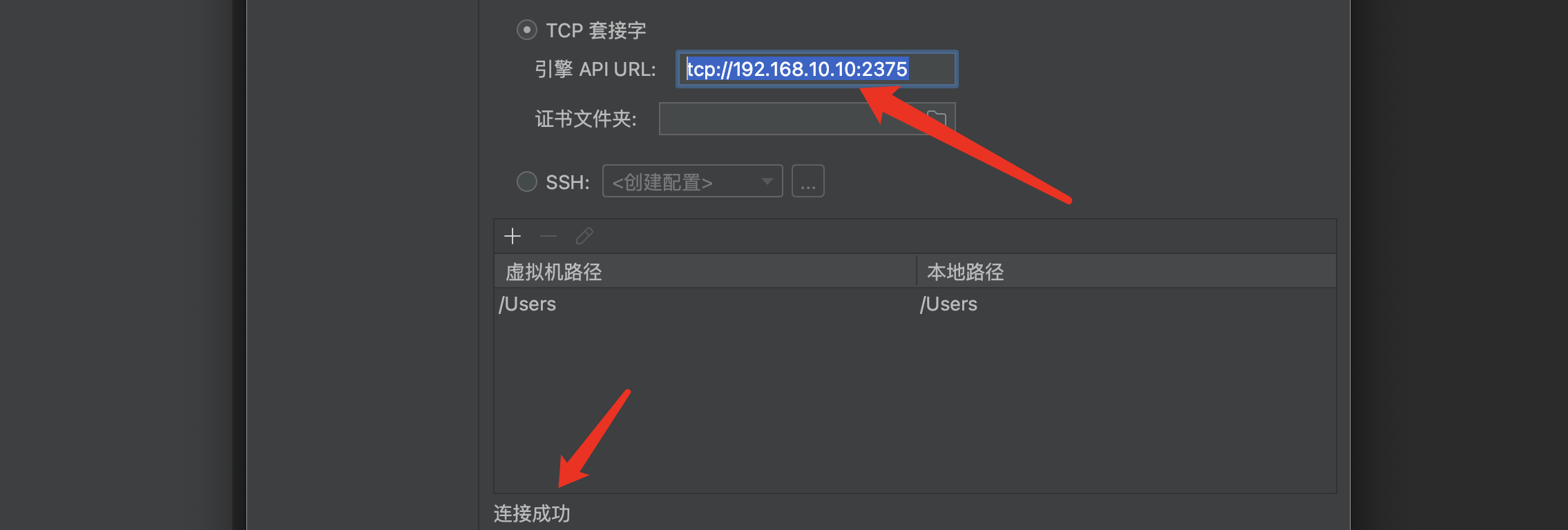
在引擎API URL处填写我们Docker服务器的IP地址:
tcp://IP:2375
显示连接成功后,表示配置正确,点击保存即可,接着就开始在我们的Docker服务器上进行构建了:
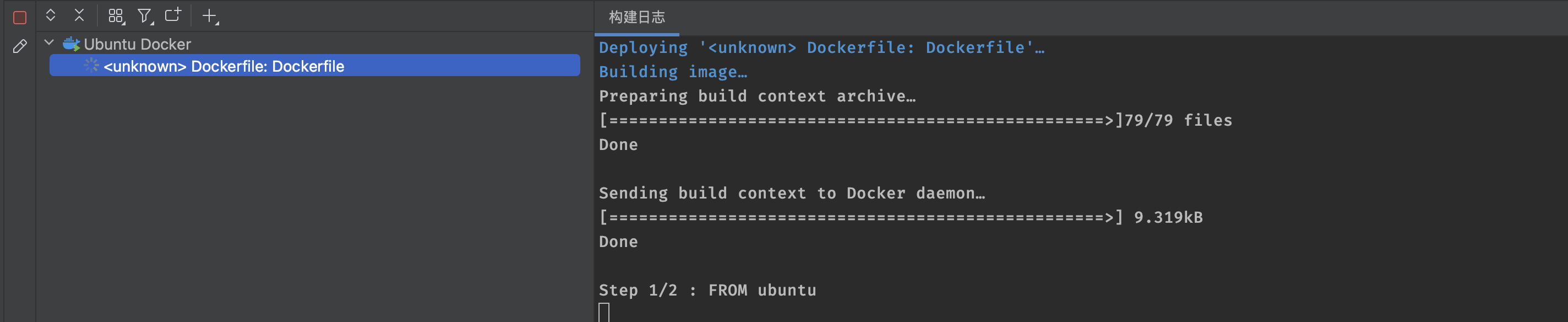
最后成功构建:

可以看到,Docker服务器上已经有了我们刚刚构建好的镜像:

不过名称没有指定,这里我们重新配置一下:
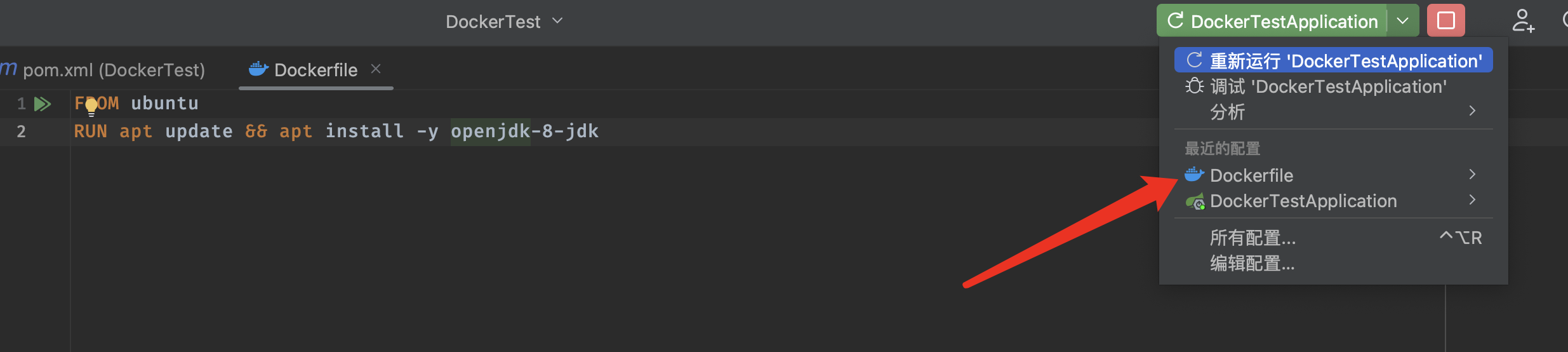

重新进行构建,就是我们自定义的名称了:


我们来创建一个容器试试看:

好了,现在基本环境搭建好了,我们接着就需要将我们的SpringBoot项目打包然后再容器启动时运行了,打开Maven执行打包命令:
接着我们需要编辑Dockerfile,将我们构建好的jar包放进去:
COPY target/DockerTest-0.0.1-SNAPSHOT.jar app.jar
这里需要使用COPY命令来将文件拷贝到镜像中,第一个参数是我们要拷贝的本地文件,第二个参数是存放在Docker镜像中的文件位置,由于还没有学习存储管理,这里我们直接输入app.jar直接保存在默认路径即可。
接着我们就需要指定在启动时运行我们的Java程序,这里使用CMD命令来完成:
FROM ubuntu
RUN apt update && apt install -y openjdk-8-jdk
COPY target/DockerTest-0.0.1-SNAPSHOT.jar app.jar
CMD java -jar app.jar
# EXPOSE 8080
CMD命令可以设定容器启动后执行的命令,EXPOSE可以指定容器需要暴露的端口,但是现在我们还没有学习网络相关的知识,所以暂时不使用,这里指定为我们启动Java项目的命令。配置完成后,重新构建:

可以看到历史中已经出现新的步骤了:

接着启动我们的镜像,我们可以直接在IDEA中进行操作,不用再去敲命令了,有点累:
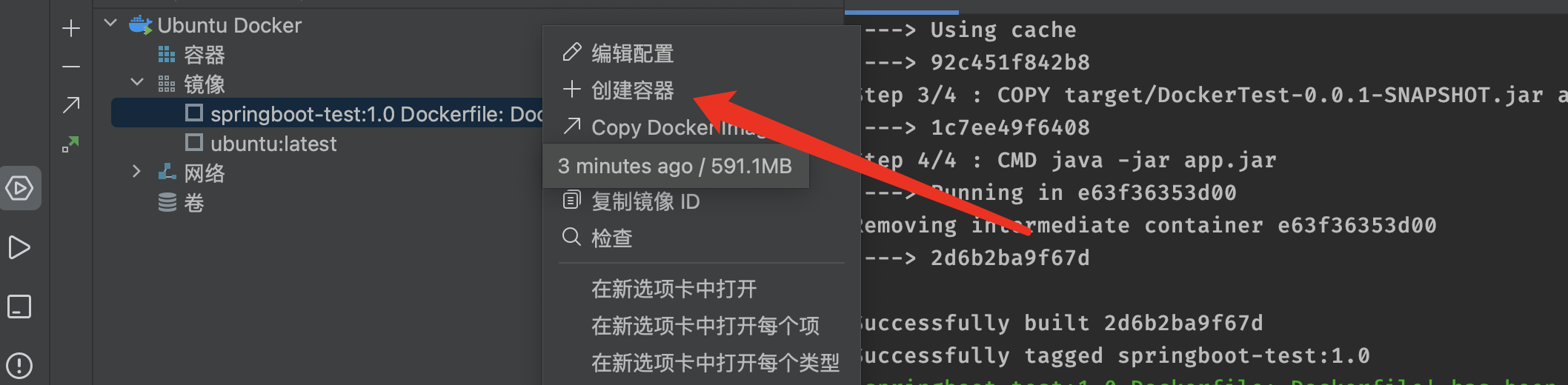
启动后可以在右侧看到容器启动的日志信息:

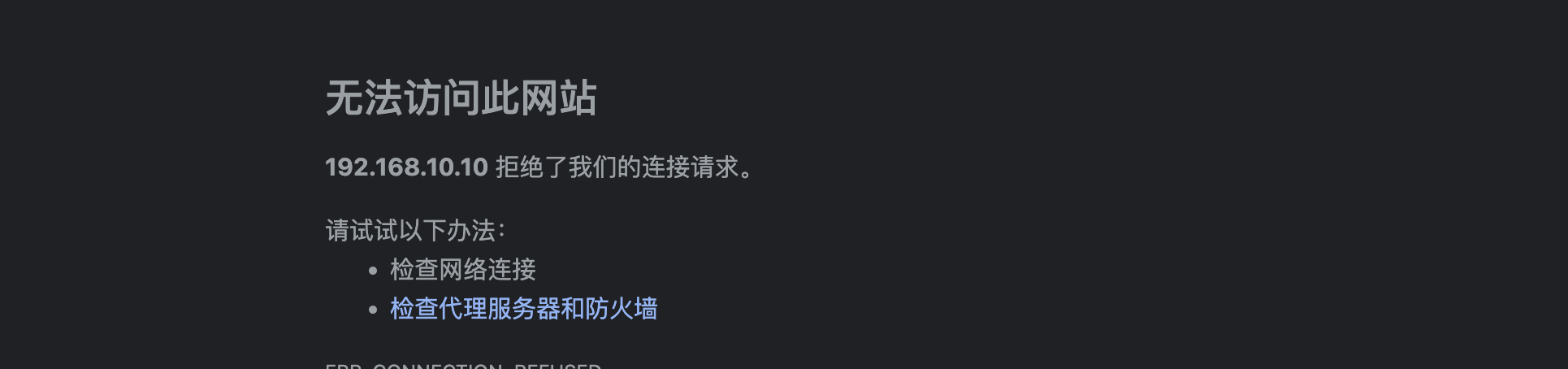
但是我们发现启动之后并不能直接访问,这是为什么呢?这是因为容器内部的网络和外部网络是隔离的,我们如果想要访问容器内的服务器,需要将对应端口绑定到宿主机上,让宿主主机也开启这个端口,这样才能连接到容器内:
docker run -p 8080:8080 -d springboot-test:1.0
这里-p表示端口绑定,将Docker容器内的端口绑定到宿主机的端口上,这样就可以通过宿主的8080端口访问到容器的8080端口了(有关容器网络管理我们还会在后面进行详细介绍),-d参数表示后台运行,当然直接在IDEA中配置也是可以的:

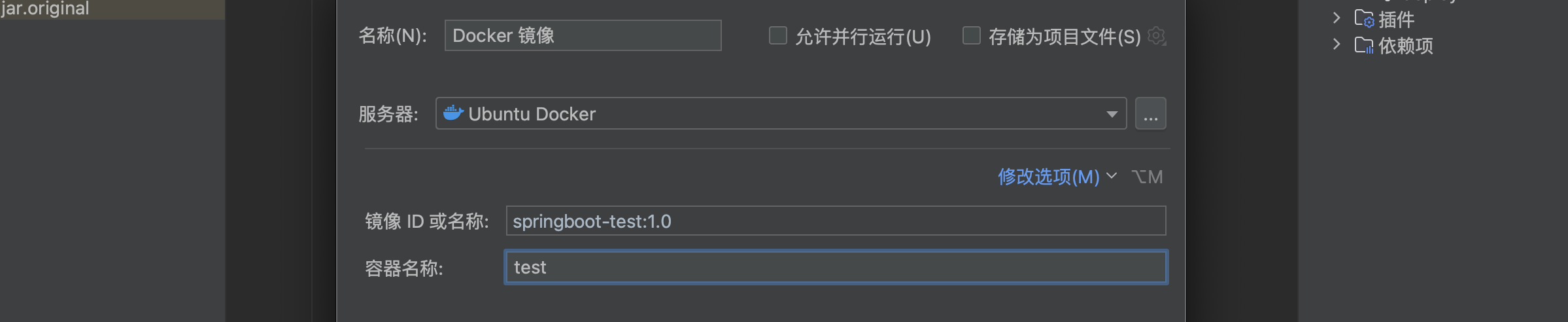
配置好后,点击重新创建容器:

重新运行后,我们就可以成功访问到容器中运行的SpringBoot项目了:
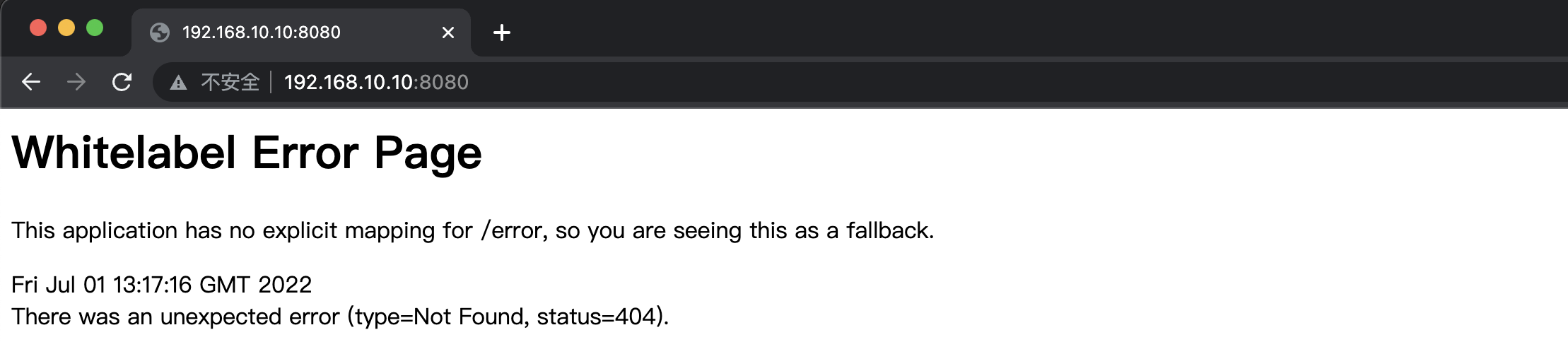
当然,为了以后方便使用,我们可以直接将其推送到Docker Hub中,这里我们还是创建一个新的公开仓库:

这次我们就使用IDEA来演示直接进行镜像的上传,直接点击:
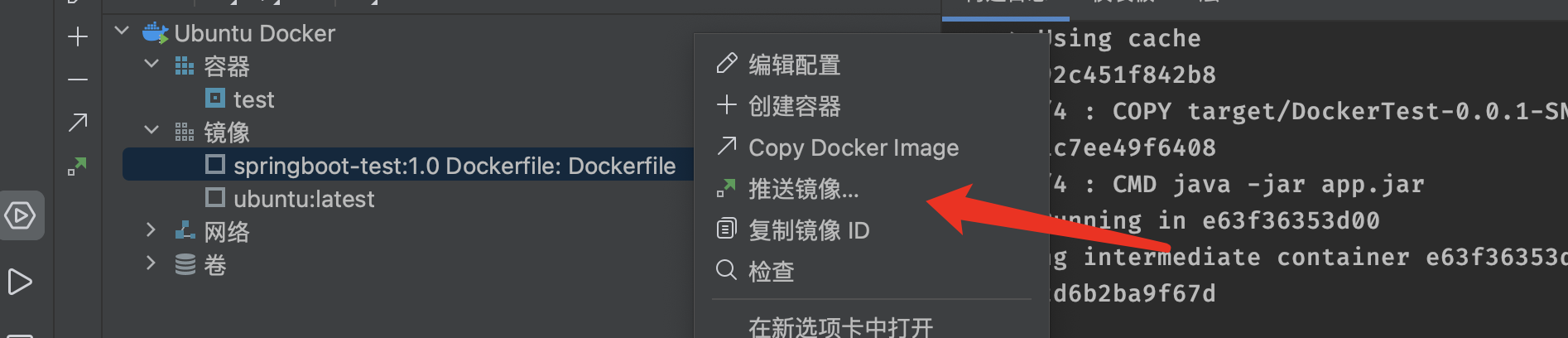
接着我们需要配置一下我们的Docker Hub相关信息:
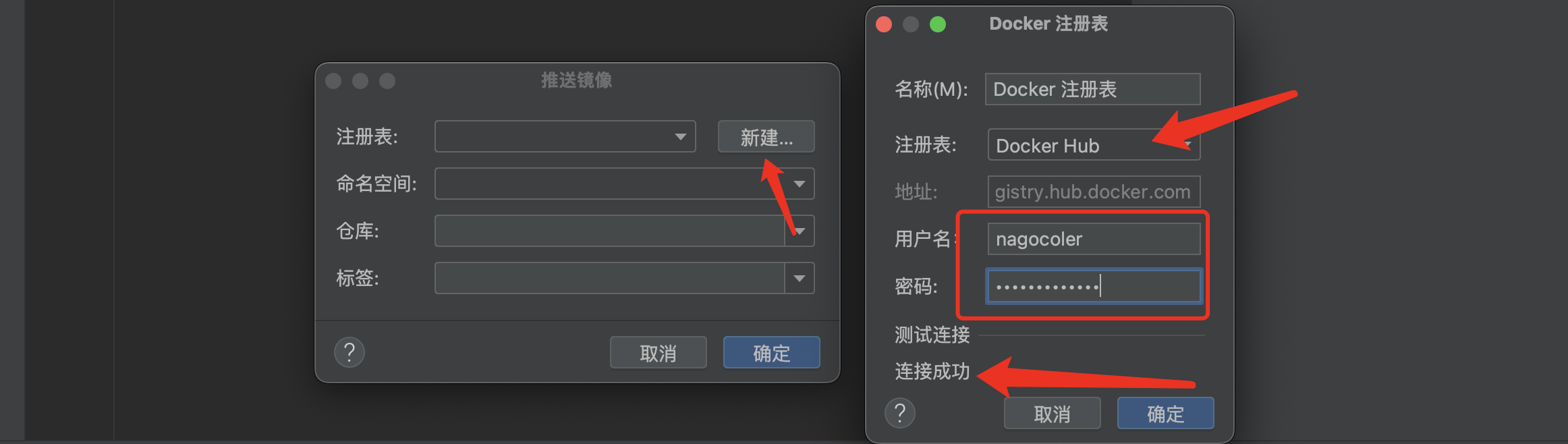
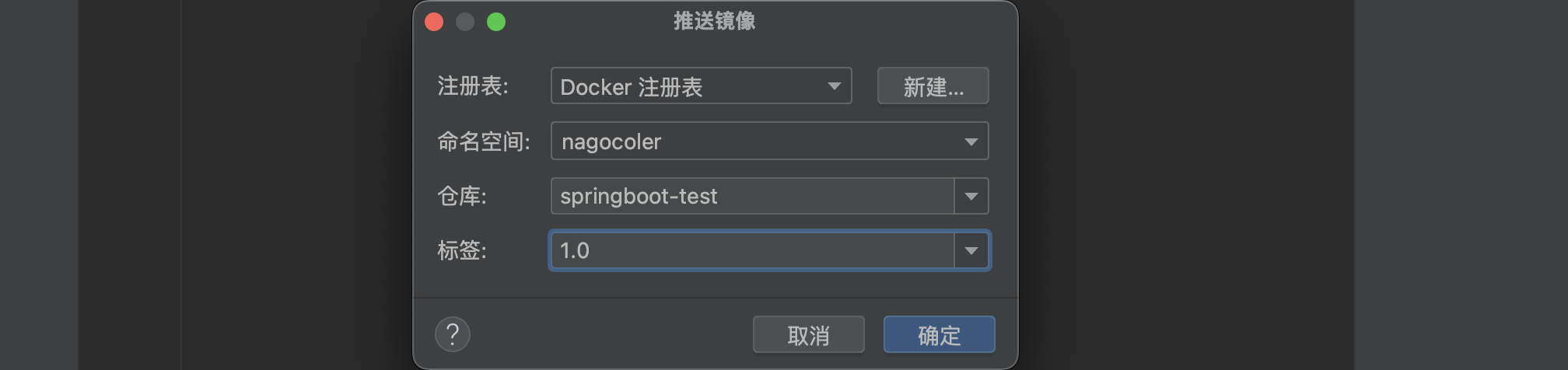
OK,远程镜像仓库配置完成,直接推送即可,等待推送完成。
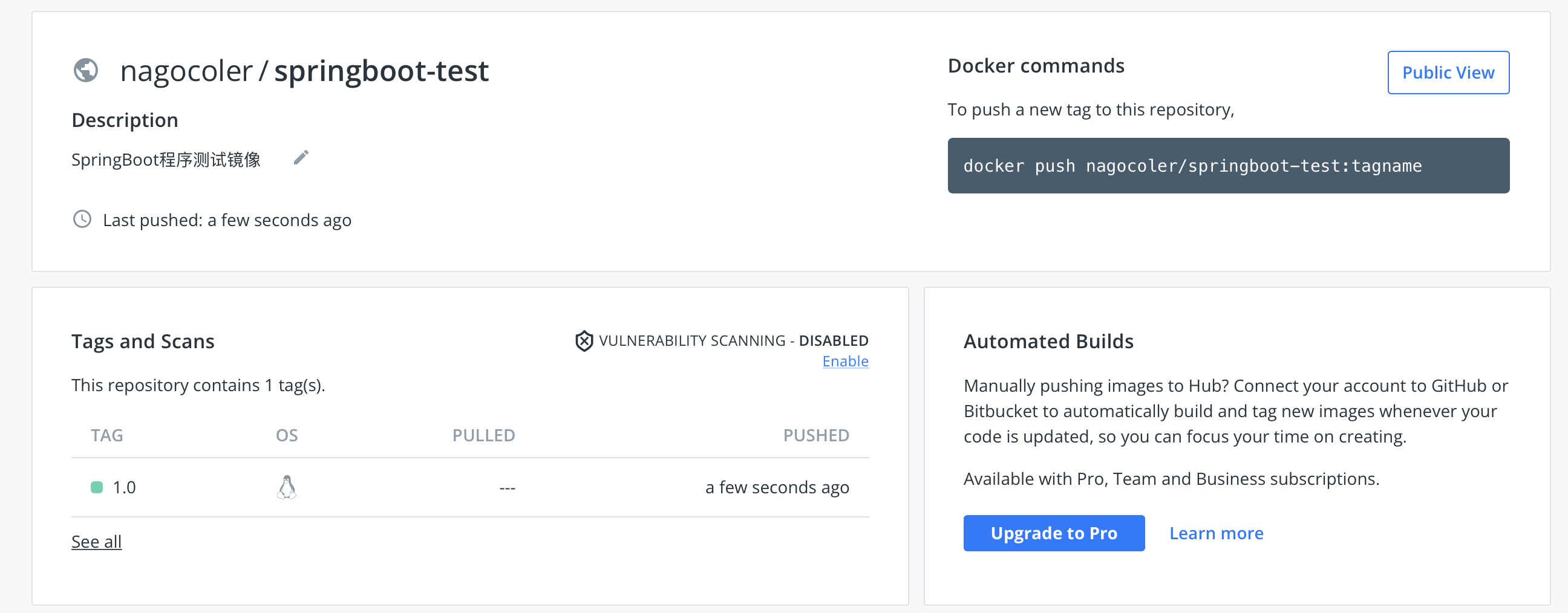
可以看到远程仓库中已经出现了我们的镜像,然后IDEA中也可以同步看到:

这样,我们就完成了使用IDEA将SpringBoot项目打包为Docker镜像。
容器网络管理
**注意:**本小节学习需要掌握部分《计算机网络》课程中的知识。
前面我们学习了容器和镜像的一些基本操作,了解了如何通过镜像创建容器、然后自己构建容器,以及远程仓库推送等,这一部分我们接着来讨论容器的网络管理。
容器网络类型
Docker在安装后,会在我们的主机上创建三个网络,使用network ls命令来查看:
docker network ls

可以看到默认情况下有bridge、host、none这三种网络类型(其实有点像虚拟机的网络配置,也是分桥接、共享网络之类的),我们先来依次介绍一下,在开始之前我们先构建一个镜像,默认的ubuntu镜像由于啥软件都没有,所以我们把一会网络要用到的先提前装好:
docker run -it ubuntu
apt update
apt install net-tools iputils-ping curl
这样就安装好了,我们直接退出然后将其构建为新的镜像:
docker commit lucid_sammet ubuntu-net

OK,一会我们就可以使用了。
-
**none网络:**这个网络除了有一个本地环回网络之外,就没有其他的网络了,我们可以在创建容器时指定这个网络。
这里使用
--network参数来指定网络:docker run -it --network=none ubuntu-net进入之后,我们可以直接查看一下当前的网络:
ifconfig可以看到只有一个本地环回
lo网络设备:
所以这个容器是无法连接到互联网的:

“真”单机运行,可以说是绝对的安全,没人能访问进去,存点密码这些还是不错的。
-
**bridge网络:**容器默认使用的网络类型,这是桥接网络,也是应用最广泛的网络类型:
实际上我们在宿主主机上查看网络信息,会发现有一个名为docker0的网络设备:
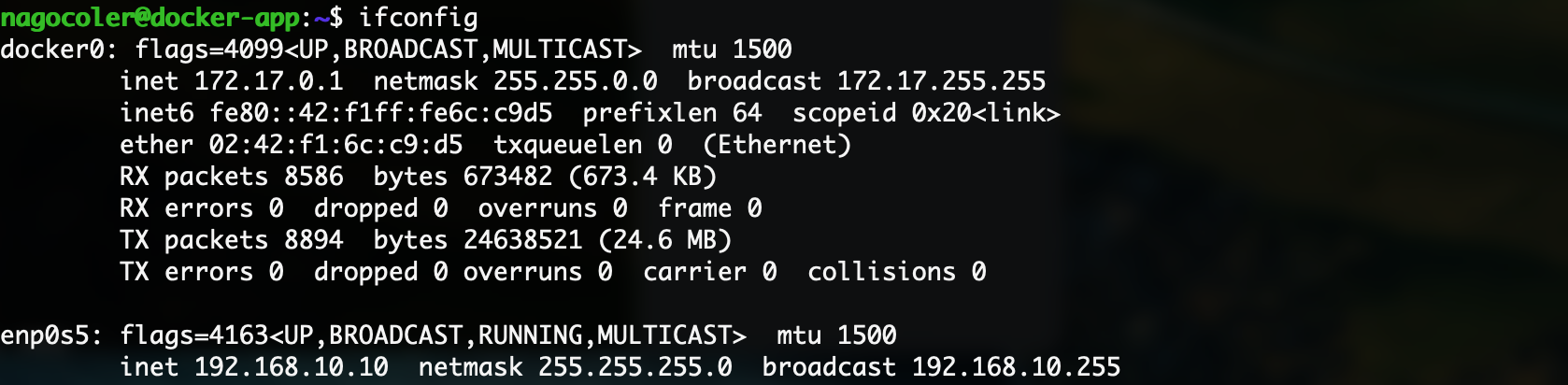
这个网络设备是Docker安装时自动创建的虚拟设备,它有什么用呢?我们可以来看一下默认创建的容器内部的情况:
docker run -it ubuntu-net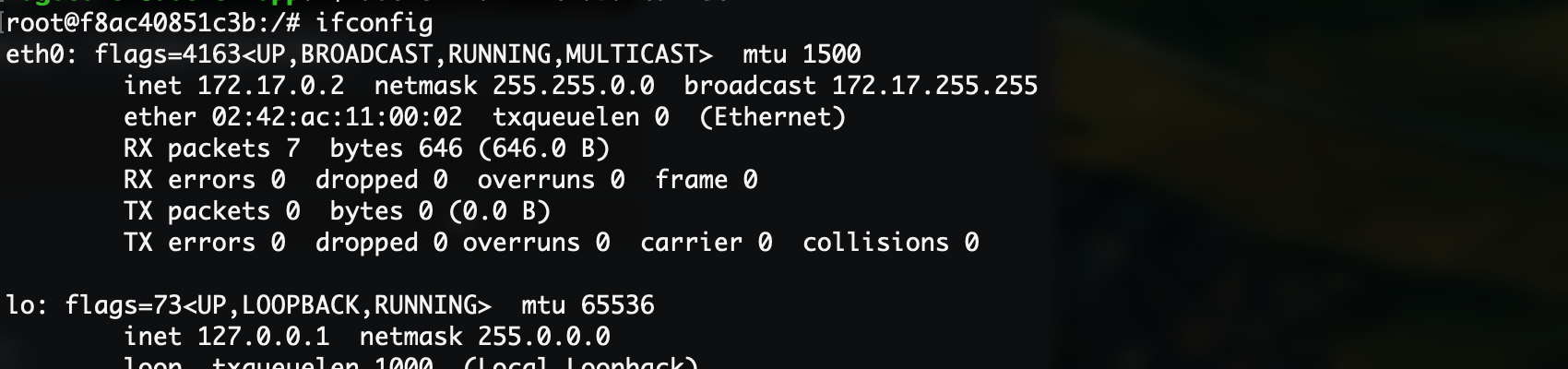
可以看到容器的网络接口地址为172.17.0.2,实际上这是Docker创建的虚拟网络,就像容器单独插了一根虚拟的网线,连接到Docker创建的虚拟网络上,而docker0网络实际上作为一个桥接的角色,一头是自己的虚拟子网,另一头是宿主主机的网络。
网络拓扑类似于下面这样:
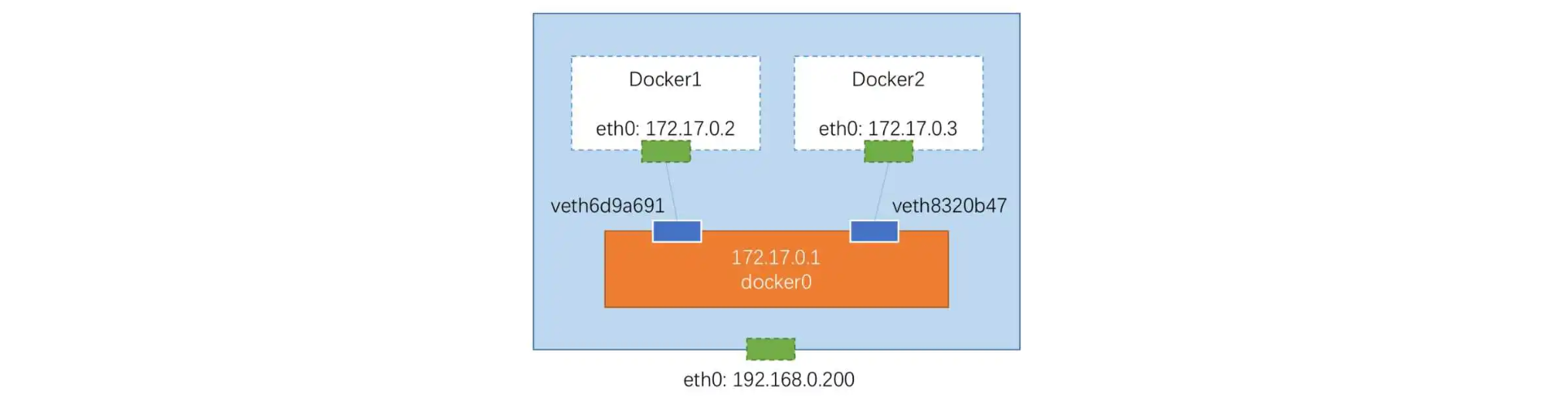
通过添加这样的网桥,我们就可以对容器的网络进行管理和控制,我们可以使用
network inspect命令来查看docker0网桥的配置信息:docker network inspect bridge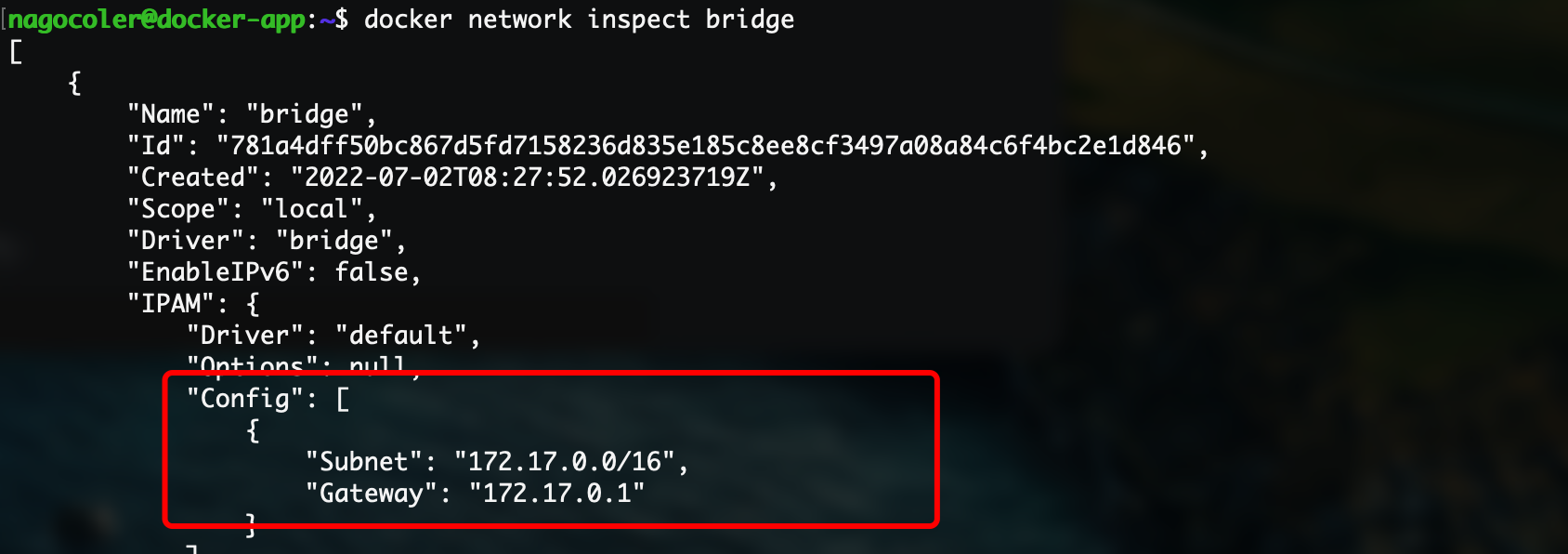
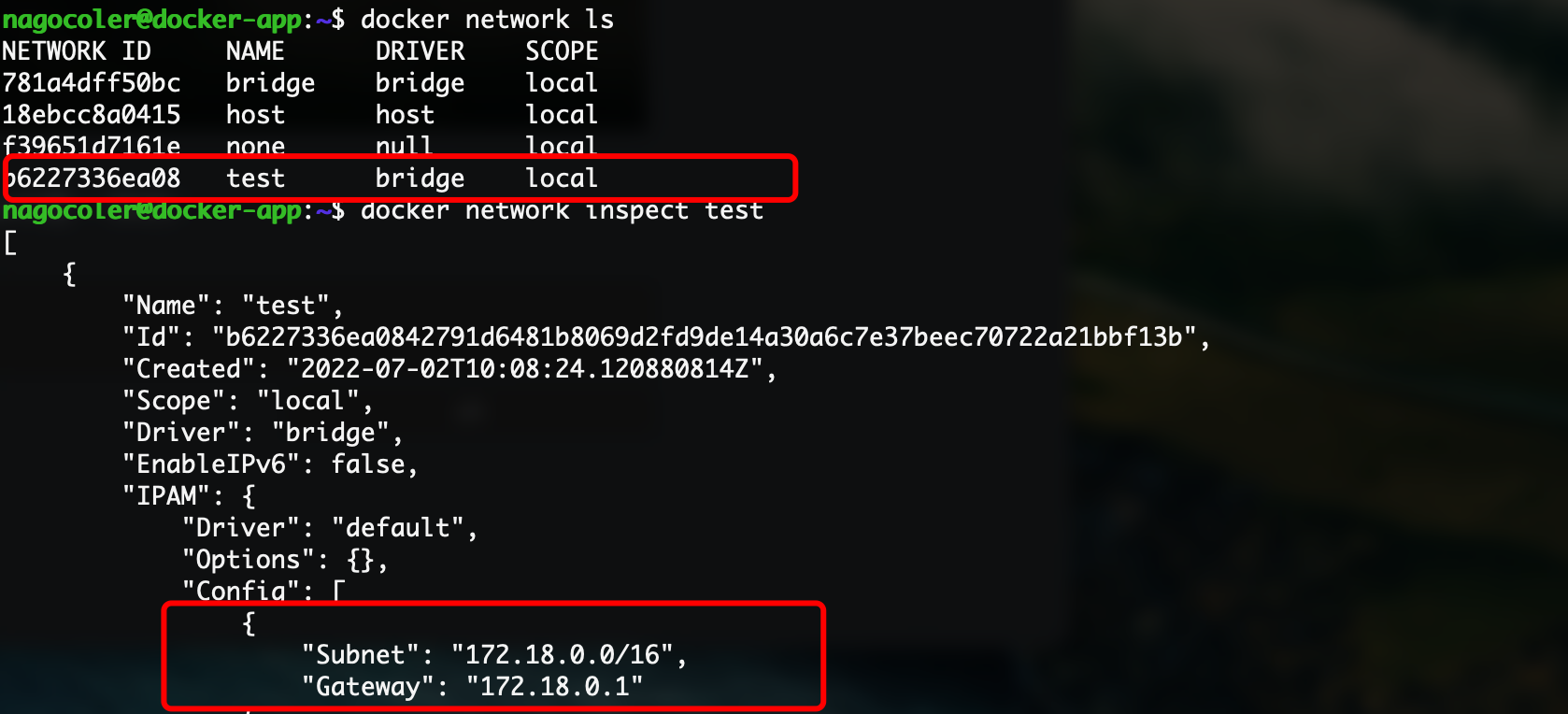
这里的配置的子网是172.17.0.0,子网掩码是255.255.0.0,网关是172.17.0.1,也就是docker0这个虚拟网络设备,所以我们上面创建的容器就是这个子网内分配的地址172.17.0.2了。
之后我们还会讲解如何管理和控制容器网络。
-
**host网络:**当容器连接到此网络后,会共享宿主主机的网络,网络配置也是完全一样的:
docker run -it --network=host ubuntu-net可以看到网络列表和宿主主机的列表是一样的,不知道各位有没有注意到,连hostname都是和外面一模一样的:
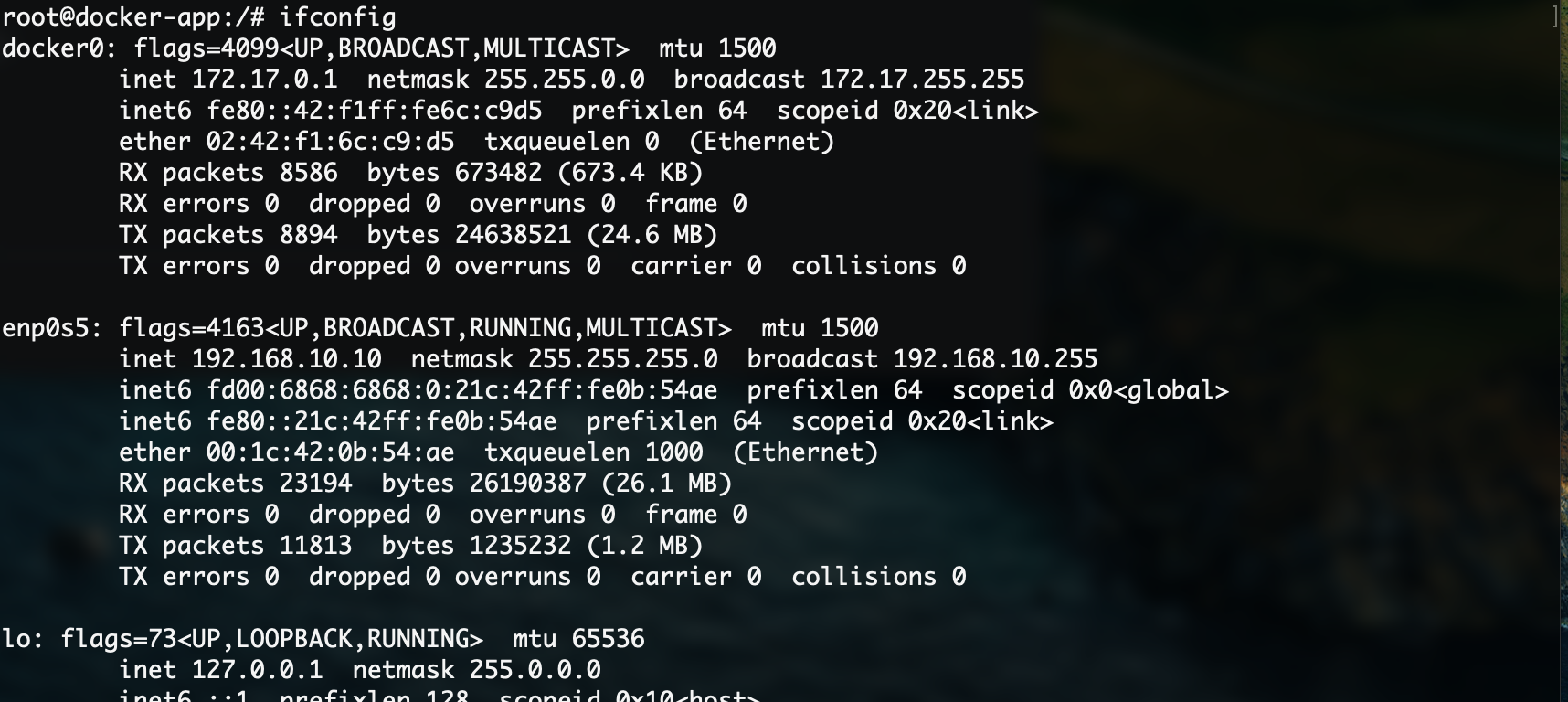
只要宿主主机能连接到互联网,容器内部也是可以直接使用的:

这样的话,直接使用宿主的网络,传输性能基本没有什么折损,而且我们可以直接开放端口等,不需要进行任何的桥接:
apt install -y systemctl nginx systemctl start nginx安装Nginx之后直接就可以访问了,不需要开放什么端口:
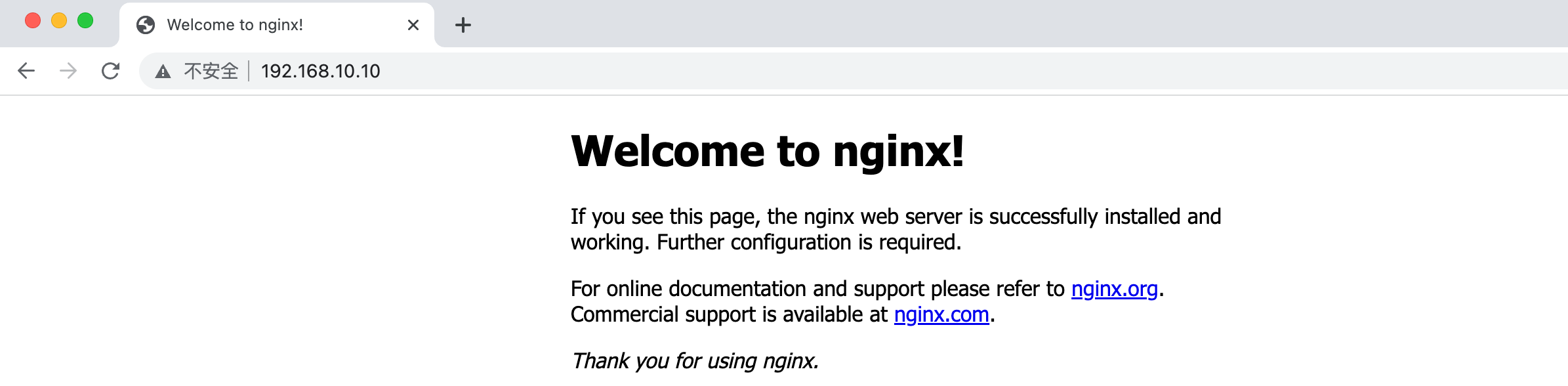
相比桥接网络就方便得多了。
我们可以根据实际情况,来合理地选择这三种网络使用。
用户自定义网络
除了前面我们介绍的三种网络之外,我们也可以自定义自己的网络,让容器连接到这个网络。
Docker默认提供三种网络驱动:bridge、overlay、macvlan,不同的驱动对应着不同的网络设备驱动,实现的功能也不一样,比如bridge类型的,其实就和我们前面介绍的桥接网络是一样的。
我们可以使用network create来试试看:
docker network create --driver bridge test
这里我们创建了一个桥接网络,名称为test:

可以看到新增了一个网络设备,这个就是一会负责我们容器网络的网关了,和之前的docker0是一样的:
docker network inspect test
这里我们创建一个新的容器,使用此网络:
docker run -it --network=test ubuntu-net

成功得到分配的IP地址,是在这个网络内的,注意不同的网络之间是隔离的,我们可以再创建一个容器试试看:

可以看到不同的网络是相互隔离的,无法进行通信,当然我们也为此容器连接到另一个容器所属的网络下:
docker network connect test 容器ID/名称

这样就连接了一个新的网络:
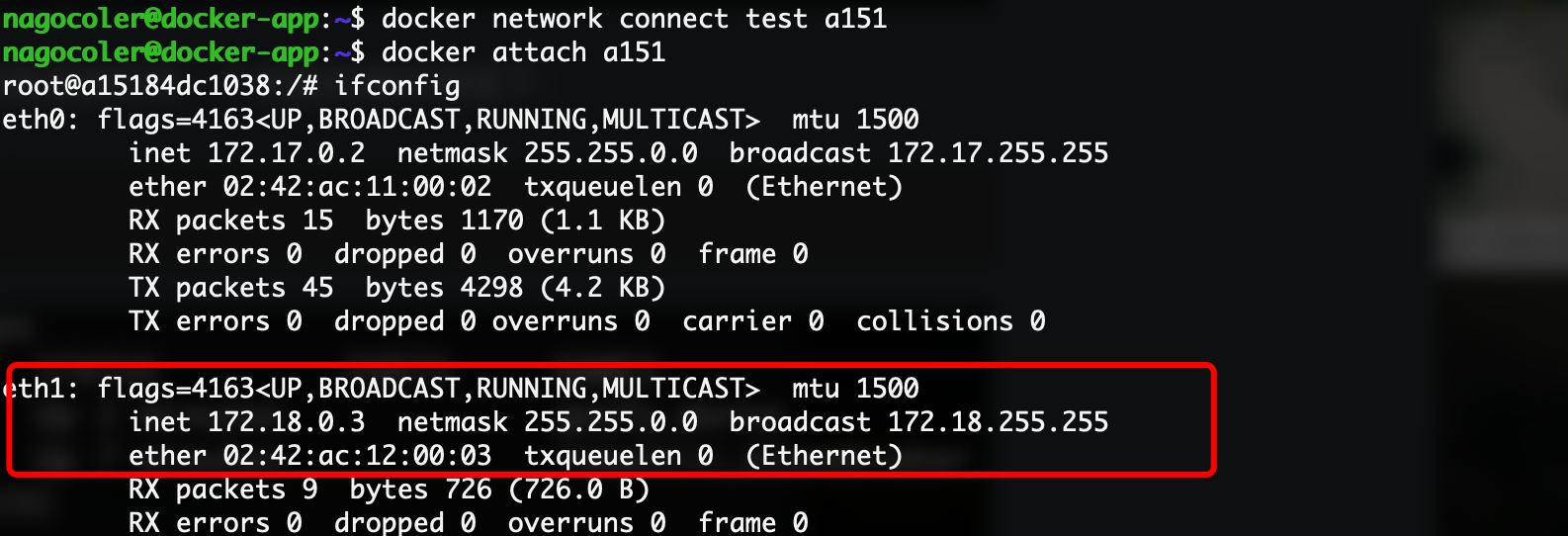
可以看到容器中新增了一个网络设备连接到我们自己定义的网络中,现在这两个容器在同一个网络下,就可以相互ping了:

这里就不介绍另外两种类型的网络了,他们是用于多主机通信的,目前我们只学习单机使用。
容器间网络
我们首先来看看容器和容器之间的网络通信,实际上我们之前已经演示过ping的情况了,现在我们创建两个ubuntu容器:
docker run -it ubuntu-net
先获取其中一个容器的网络信息:

我们可以直接在另一个容器中ping这个容器:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZHCuiBpn-1685016038376)(/Users/nagocoler/Library/Application Support/typora-user-images/image-20220702175444713.png)]
可以看到能够直接ping通,因为这两个容器都是使用的bridge网络,在同一个子网中,所以可以互相访问。
我们可以直接通过容器的IP地址在容器间进行通信,只要保证两个容器处于同一个网络下即可,虽然这样比较方便,但是大部分情况下,容器部署之后的IP地址是自动分配的(当然也可以使用--ip来手动指定,但是还是不方便),我们无法提前得知IP地址,那么有没有一直方法能够更灵活一些呢?
我们可以借助Docker提供的DNS服务器,它就像是一个真的DNS服务器一样,能够对域名进行解析,使用很简单,我们只需要在容器启动时给个名字就行了,我们可以直接访问这个名称,最后会被解析为对应容器的IP地址,但是注意只会在我们用户自定义的网络下生效,默认的网络是不行的:
docker run -it --name=test01 --network=test ubuntu-net
docker run -it --name=test02 --network=test ubuntu-net
接着直接ping对方的名字就可以了:

可以看到名称会自动解析为对应的IP地址,这样的话就不用担心IP不确定的问题了。
当然我们也可以让两个容器同时共享同一个网络,注意这里的共享是直接共享同一个网络设备,两个容器共同使用一个IP地址,只需要在创建时指定:
docker run -it --name=test01 --network=container:test02 ubuntu-net
这里将网络指定为一个容器的网络,这样两个容器使用的就是同一个网络了:
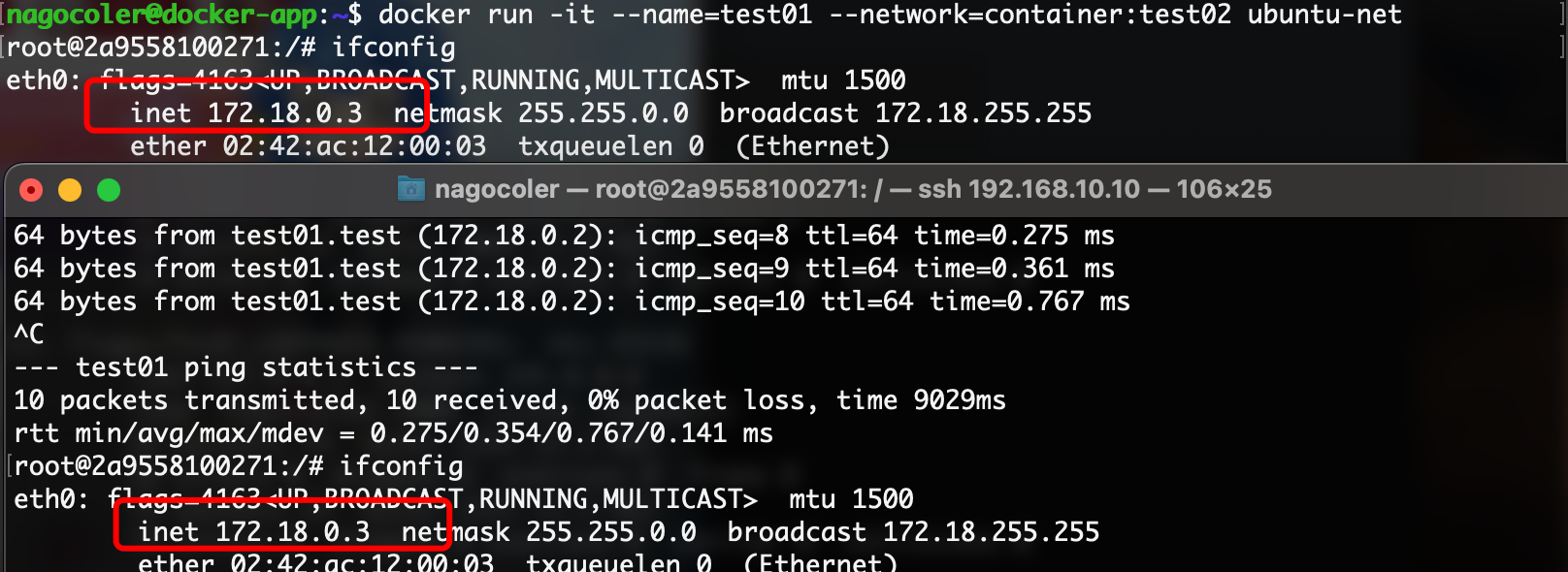
可以看到两个容器的IP地址和网卡的Mac地址是完全一样的,它们的网络现在是共享状态,此时在容器中访问,localhost,既是自己也是别人。
我们可以在容器1中,安装Nginx,然后再容器2中访问:
apt install -y systemctl nginx
systemctl start nginx
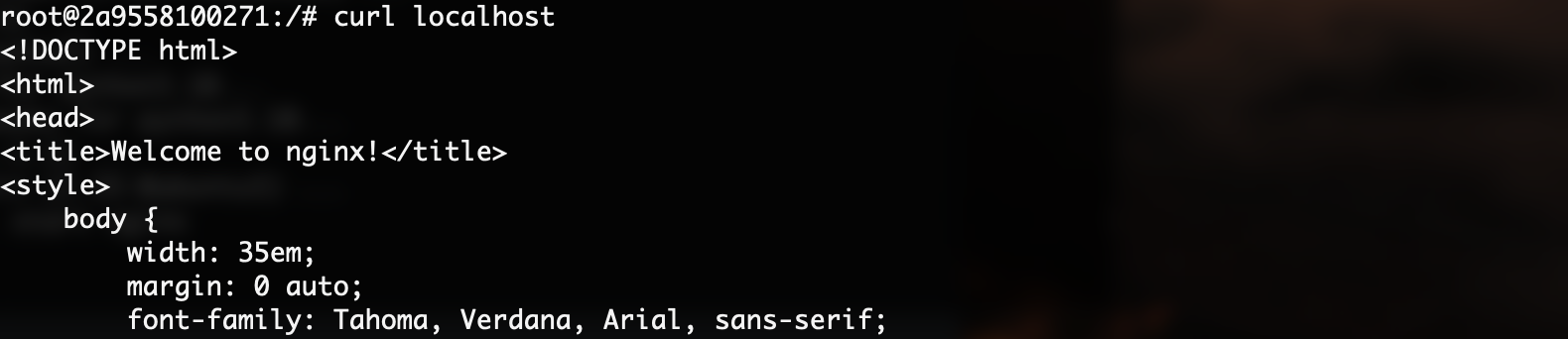
成功访问到另一个容器中的Nginx服务器。
容器外部网络
前面我们介绍了容器之间的网络通信,我们接着来看容器与外部网络的通信。
首先我们来看容器是如何访问到互联网的,在默认的三种的网络下,只有共享模式和桥接模式可以连接到外网,共享模式实际上就是直接使用宿主主机的网络设备连接到互联网,这里我们主要来看一下桥接模式。
通过前面的学习,我们了解到桥接模式实际上就是创建一个单独的虚拟网络,让容器在这个虚拟网络中,然后通过桥接器来与外界相连,那么数据包是如何从容器内部的网络到达宿主主机再发送到互联网的呢?实际上整个过程中最关键的就是依靠NAT(Network Address Translation)将地址进行转换,再利用宿主主机的IP地址发送数据包出去。
这里我们就来补充一下《计算机网络》课程中学习的NAT:
实际上NAT在我们生活中也是经常见到的,比如我们要访问互联网上的某个资源,要和服务器进行通信,那么就需要将数据包发送出去,同时服务器也要将数据包发送回来,我们可以知道服务器的IP地址,也可以直接去连接,因为服务器的IP地址是暴露在互联网上的,但是我们的局域网就不一样了,它仅仅局限在我们的家里,比如我们连接了家里的路由器,可以得到一个IP地址,但是你会发现,这个IP公网是无法直接访问到我们的,因为这个IP地址仅仅是一个局域网的IP地址,俗称内网IP,既然公网无法访问到我们,那服务器是如何将数据包发送给我们的呢?
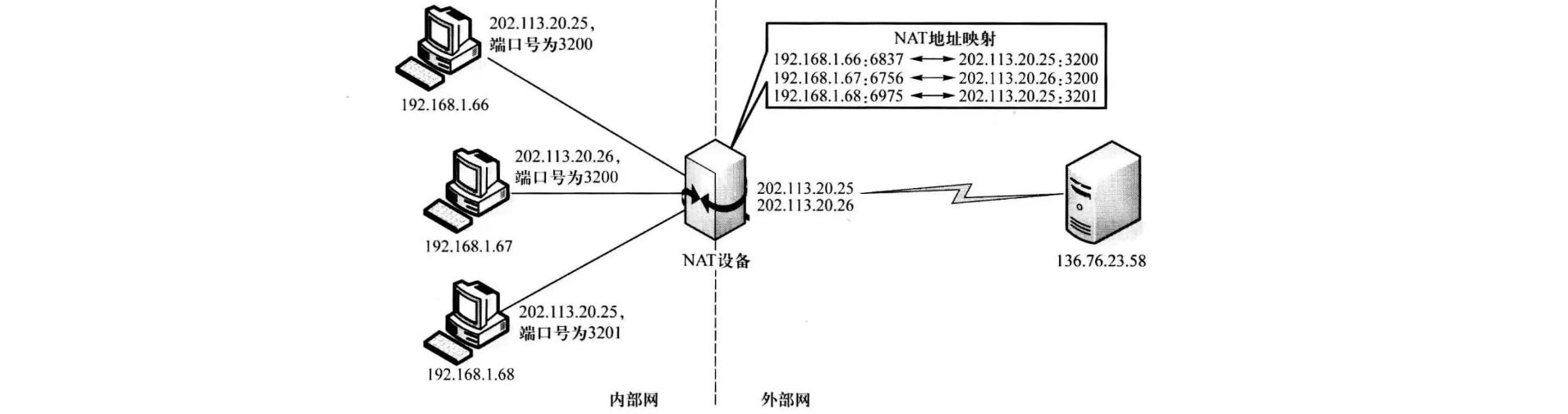
实际上这里就借助了NAT在帮助我们与互联网上的服务器进行通信,通过NAT,可以实现将局域网的IP地址,映射为对应的公网IP地址,而NAT设备一端连接外网,另一端连接内网的所有设备,当我们想要与外网进行通信时,就可以将数据包发送给NAT设备,由它来将数据包的源地址映射为它在外网上的地址,这样服务器就能够发现它了,能够直接与它建立通信。当服务器发送数据回来时,也是直接交给NAT设备,然后再根据地址映射,转发给对应的内网设备(当然由于公网IP地址有限,所以一般采用IP+端口结合使用的形式ANPT)
所以你打开百度直接搜IP,会发现这个IP地址并不是你本地的,而是NAT设备的公网地址:
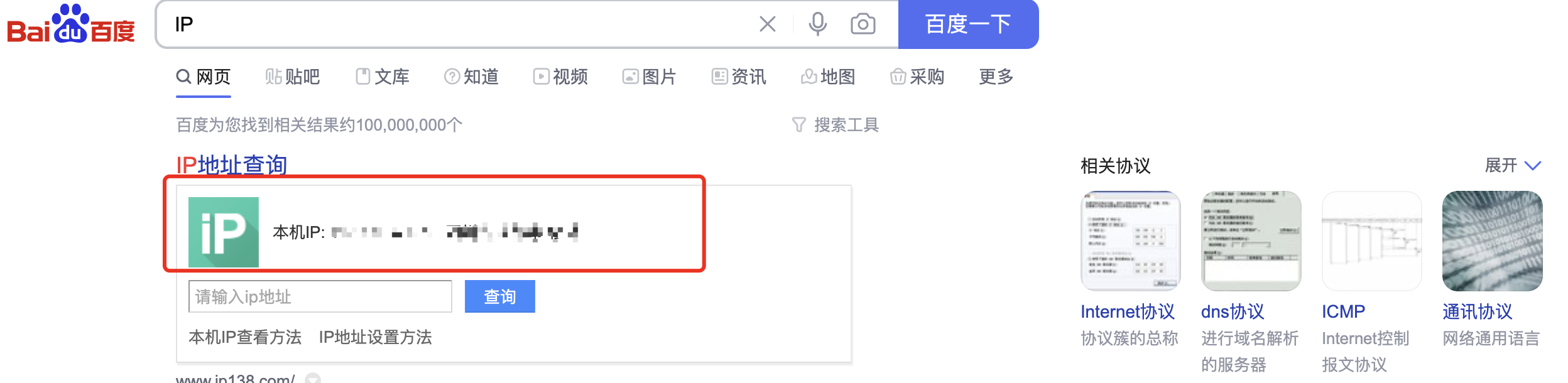
实际上我们家里的路由器一般都带有NAT功能,默认开启NAT模式,包括我们的小区也是有一个NAT设备在进行转换的,这样你的电脑才能在互联网的世界中遨游。当然NAT也可以保护内网的设备不会直接暴露在公网,这样也会更加的安全,只有当我们主动发起连接时,别人才能知道我们。
当然,我们的Docker也是这样的,实际上内网的数据包想要发送到互联网上去,那么就需要经过这样的一套流程:

这样,Docker容器使用的内网就可以和外网进行通信了。
但是这样有一个问题,单纯依靠NAT的话,只有我们主动与外界联系时,外界才能知道我们,但是现在我们的容器中可能会部署一些服务,需要外界来主动连接我们,此时该怎么办呢?
我们可以直接在容器时配置端口映射,还记得我们在第一节课部署Nginx服务器吗?
docker run -d -p 80:80 nginx
这里的-p参数实际上是进行端口映射配置,端口映射可以将容器需要对外提供服务的端口映射到宿主主机的端口上,这样,当外部访问到宿主主机的对应端口时,就会直接转发给容器内映射的端口了。规则为宿主端口:容器端口,这里配置的是将容器的80端口映射到宿主主机的80端口上。

一旦监听到宿主主机的80端口收到了数据包,那么会直接转发给对应的容器。所以配置了端口映射之后,我们才可以从外部正常访问到容器内的服务:
我们也可以直接输入docker ps查看端口映射情况:

至此,有关容器的网络部分,就到此为止,当然这仅仅是单机下的容器网络操作,在以后的课程中,我们还会进一步学习多主机下的网络配置。
容器存储管理
前面我们介绍了容器的网络管理,我们现在已经了解了如何配置容器的网络,以及相关的一些原理。还有一个比较重要的部分就是容器的存储,在这一小节我们将深入了解容器的存储管理。
容器持久化存储
我们知道,容器在创建之后,实际上我们在容器中创建和修改的文件,实际上是被容器的分层机制保存在最顶层的容器层进行操作的,为了保护下面每一层的镜像不被修改,所以才有了这样的CopyOnWrite特性。但是这样也会导致容器在销毁时数据的丢失,当我们销毁容器重新创建一个新的容器时,所有的数据全部丢失,直接回到梦开始的地方。
在某些情况下,我们可能希望对容器内的某些文件进行持久化存储,而不是一次性的,这里就要用到数据卷(Data Volume)了。
在开始之前我们先准备一下实验要用到的镜像:
docker run -it ubuntu
apt update && apt install -y vim
然后打包为我们一会要使用的镜像:
docker commit
我们可以让容器将文件保存到宿主主机上,这样就算容器销毁,文件也会在宿主主机上保留,下次创建容器时,依然可以从宿主主机上读取到对应的文件。如何做到呢?只需要在容器启动时指定即可:
mkdir test
我们现在用户目录下创建一个新的test目录,然后在里面随便创建一个文件,再写点内容:
vim test/hello.txt
接着我们就可以将宿主主机上的目录或文件挂载到容器的某个目录上:
docker run -it -v ~/test:/root/test ubuntu-volume
这里用到了一个新的参数-v,用于指定文件挂载,这里是将我们刚刚创建好的test目录挂在到容器的/root/test路径上。

这样我们就可以直接在容器中访问宿主主机上的文件了,当然如果我们对挂载目录中的文件进行编辑,那么相当于编辑的是宿主主机的数据:
vim /root/test/test.txt

在宿主主机的对应目录下,可以直接访问到我们刚刚创建好的文件。
接着我们来将容器销毁,看看当容器不复存在时,挂载的数据时候还能保留:

可以看到,即使我们销毁了容器,在宿主主机上的文件依然存在,并不会受到影响,这样的话,当我们下次创建新的镜像时,依然可以使用这些保存在外面的文件。
比如我们现在想要部署一个Nginx服务器来代理我们的前端,就可以直接将前端页面保存到宿主主机上,然后通过挂载的形式让容器中的Nginx访问,这样就算之后Nginx镜像有升级,需要重新创建,也不会影响到我们的前端页面。这里我们来测试一下,我们先将前端模板上传到服务器:
scp Downloads/moban5676.zip 192.168.10.10:~/
然后在服务器上解压一下:
unzip moban5676.zip
接着我们就可以启动容器了:
docker run -it -v ~/moban5676:/usr/share/nginx/html/ -p 80:80 -d nginx
这里我们将解压出来的目录,挂载到容器中Nginx的默认站点目录/usr/share/nginx/html/(由于挂在后位于顶层,会替代镜像层原有的文件),这样Nginx就直接代理了我们存放在宿主主机上的前端页面,当然别忘了把端口映射到宿主主机上,这里我们使用的镜像是官方的nginx镜像。
现在我们进入容器将Nginx服务启动:
systemctl start nginx
然后通过浏览器访问看看是否代理成功:
可以看到我们的前端页面直接被代理了,当然如果我们要编写自定义的配置,也是使用同样的方法操作即可。
注意如果我们在使用-v参数时不指定宿主主机上的目录进行挂载的话,那么就由Docker来自动创建一个目录,并且会将容器中对应路径下的内容拷贝到这个自动创建的目录中,最后挂在到容器中,这种就是由Docker管理的数据卷了(docker managed volume)我们来试试看:
docker run -it -v /root/abc ubuntu-volume
注意这里我们仅仅指定了挂载路径,没有指定宿主主机的对应目录,继续创建:

创建后可以看到root目录下有一个新的abc目录,那么它具体是在宿主主机的哪个位置呢?这里我们依然可以使用inspect命令:
docker inspect bold_banzai
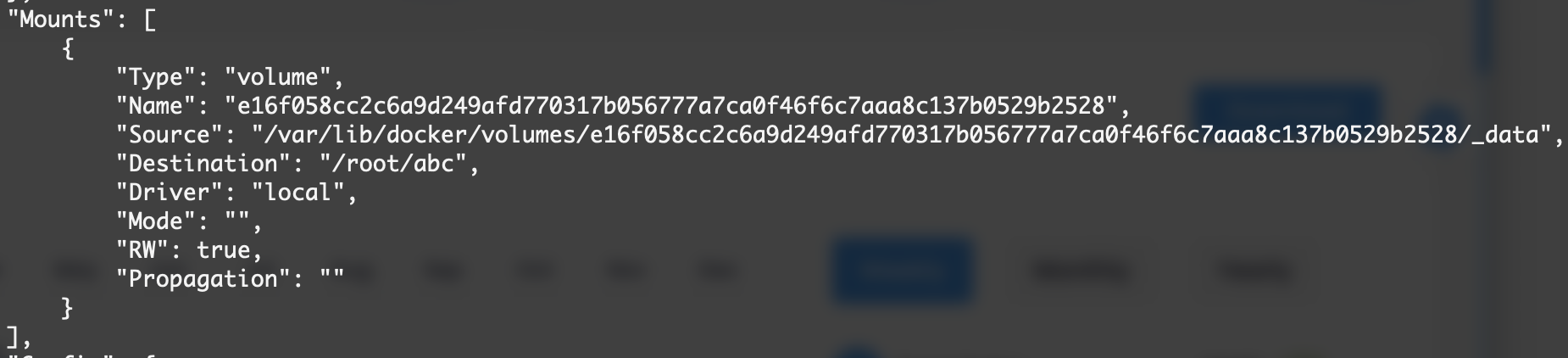
可以看到Sorce指向的是/var/lib中的某个目录,我们可以进入这个目录来创建一个新的文件,进入之前记得提升一下权限,权限低了还进不去:

我们来创一个新的文本文档:

实际上和我们之前是一样的,也是可以在容器中看到的,当然删除容器之后,数据依然是保留的。当我们不需要使用数据卷时,可以进行删除:

当然有时候为了方便,可能并不需要直接挂载一个目录上去,仅仅是从宿主主机传递一些文件到容器中,这里我们可以使用cp命令来完成:

这个命令支持从宿主主机复制文件到容器,或是从容器复制文件到宿主主机,使用方式类似于Linux自带的cp命令。
容器数据共享
前面我们通过挂载的形式,将宿主主机上的文件直接挂载到容器中,这样容器就可以直接访问到宿主主机上的文件了,并且在容器删除时也不会清理宿主主机上的文件。
我们接着来看看如何实现容器与容器之间的数据共享,实际上按照我们之前的思路,我们可以在宿主主机创建一个公共的目录,让这些需要实现共享的容器,都挂载这个公共目录:
docker run -it -v ~/test:/root/test ubuntu-volume

由于挂载的是宿主主机上的同一块区域,所以内容可以直接在两个容器中都能访问。当然我们也可以将另一个容器挂载的目录,直接在启动容器时指定使用此容器挂载的目录:
docker run -it -v ~/test:/root/test --name=data_test ubuntu-volume
docker run -it --volumes-from data_test ubuntu-volume
这里使用--volumes-from指定另一个容器(这种用于给其他容器提供数据卷的容器,我们一般称为数据卷容器)

可以看到,数据卷容器中挂载的内容,在当前容器中也是存在的,当然就算此时数据卷容器被删除,那么也不会影响到这边,因为这边相当于是继承了数据卷容器提供的数据卷,所以本质上还是让两个容器挂载了同样的目录实现数据共享。
虽然通过上面的方式,可以在容器之间实现数据传递,但是这样并不方便,可能某些时候我们仅仅是希望容器之间共享,而不希望有宿主主机这个角色直接参与到共享之中,此时我们就需要寻找一种更好的办法了。其实我们可以将数据完全放入到容器中,通过构建一个容器,来直接将容器中打包好的数据分享给其他容器,当然本质上依然是一个Docker管理的数据卷,虽然还是没有完全脱离主机,但是移植性就高得多了。
我们来编写一个Dockerfile:
FROM ubuntu
ADD moban5676.tar.gz /usr/share/nginx/html/
VOLUME /usr/share/nginx/html/
这里我们使用了一个新的指令ADD,它跟COPY命令类似,也可以复制文件到容器中,但是它可以自动对压缩文件进行解压,这里只需要将压缩好的文件填入即可,后面的VOLUME指令就像我们使用-v参数一样,会创建一个挂载点在容器中:
cd test
tar -zcvf moban5676.tar.gz *
mv moban5676.tar.gz ..
cd ..
接着我们直接构建:
docker build -t data .

现在我们运行一个容器看看:

可以看到所有的文件都自动解压出来了(除了中文文件名称乱码了之外,不过无关紧要)我们退出容器,可以看到数据卷列表中新增了我们这个容器需要使用的:


这个位置实际上就是数据存放在当前主机上的位置了,不过是由Docker进行管理而不是我们自定义的。现在我们就可以创建一个新的容器直接继承了:
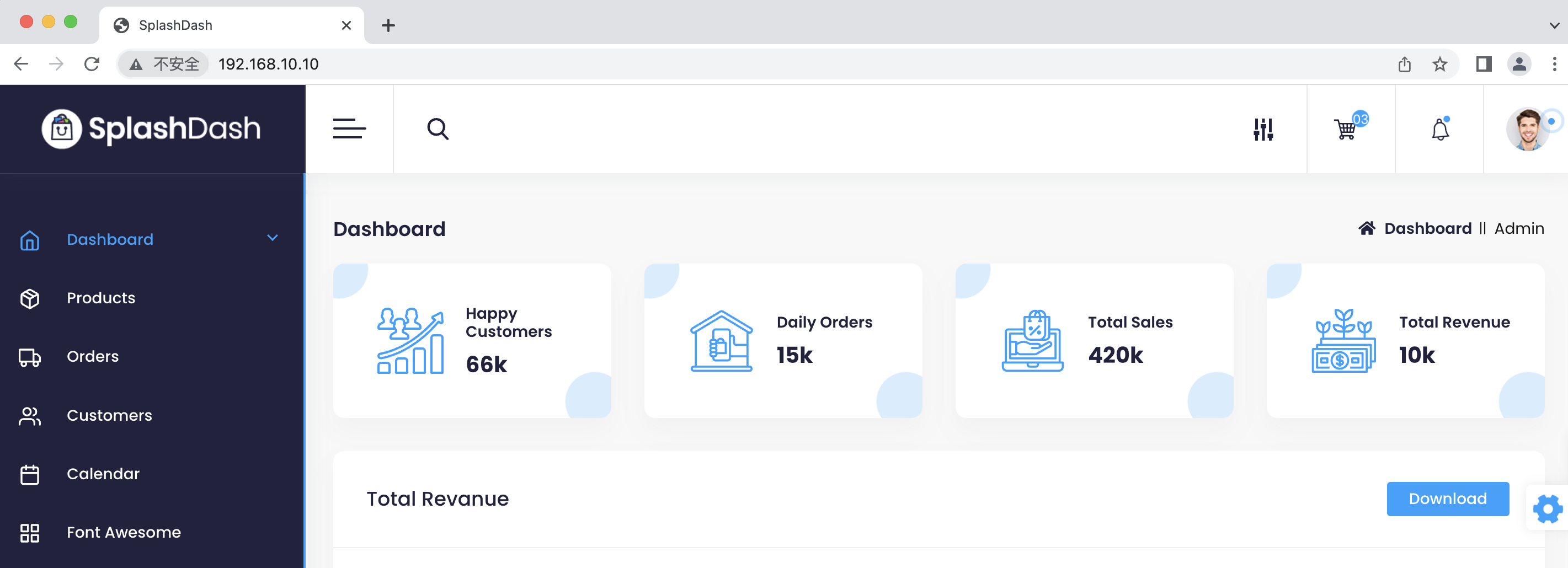
docker run -p 80:80 --volumes-from=data_test -d nginx
访问一下Nginx服务器,可以看到成功代理:
这样我们就实现了将数据放在容器中进行共享,我们不需要刻意去指定宿主主机的挂载点,而是Docker自行管理,这样就算迁移主机依然可以快速部署。
容器资源管理
前面我们已经完成Docker的几个主要模块的学习,最后我们来看看如何对容器的资源进行管理。
容器控制操作
在开始之前,我们还是要先补充一些我们前面没有提到的其他容器命令。
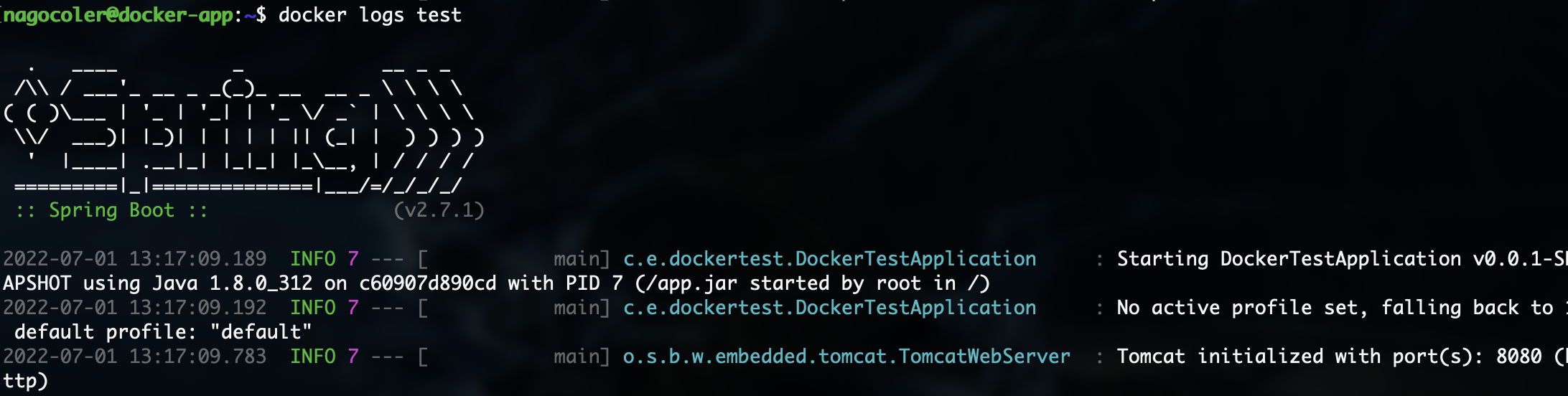
首先我们的SpringBoot项目在运行是,怎么查看输出的日志信息呢?
docker logs test
这里使用log命令来打印容器中的日志信息:
当然也可以添加-f参数来持续打印日志信息。

现在我们的容器已经启动了,但是我们想要进入到容器监控容器的情况怎么办呢?我们可以是attach命令来附加到容器启动命令的终端上:
docker attach 容器ID/名称

注意现在就切换为了容器内的终端,如果想要退出的话,需要先按Ctrl+P然后再按Ctrl+Q来退出终端,不能直接使用Ctrl+C来终止,这样会直接终止掉Docker中运行的Java程序的。

退出后,容器依然是处于运行状态的。
我们也可以使用exec命令在容器中启动一个新的终端或是在容器中执行命令:
docker exec -it test bash
-it和run命令的操作是一样的,这里执行后,会创建一个新的终端(当然原本的程序还是在正常运行)我们会在一个新的终端中进行交互:

当然也可以仅仅在容器中执行一条命令:

执行后会在容器中打开一个新的终端执行命令,并输出结果。
前面我们还学习了容器的停止操作,通过输入stop命令来停止容器,但是此操作并不会立即停止,而是会等待容器处理善后,那么怎么样才能强制终止容器呢?我们可以直接使用kill命令,相当于给进程发送SIGKILL信号,强制结束。
docker kill test
相比stop命令,kill就没那么温柔了。
有时候可能只是希望容器暂时停止运行,而不是直接终止运行,我们希望在未来的某个时间点,恢复容器的运行,此时就可以使用pause命令来暂停容器:
docker pause test
暂停容器后,程序暂时停止运行,无法响应浏览器发送的请求:


此时处于爱的魔力转圈圈状态,我们可以将其恢复运行,使用unpause命令:
docker unpause test
恢复运行后,瞬间就响应成功了。
物理资源管理
对于一个容器,在某些情况下我们可能并不希望它占据所有的系统资源来运行,我们只希望分配一部分资源给容器,比如只分配给容器2G内存,最大只允许使用2G,不允许再占用更多的内存,此时我们就需要对容器的资源进行限制。
docker run -m 内存限制 --memory-swap=内存和交换分区总共的内存限制 镜像名称
其中-m参数是对容器的物理内存的使用限制,而--memory-swap是对内存和交换分区总和的限制,它们默认都是-1,也就是说没有任何的限制(如果在一开始仅指定-m参数,那么交换内存的限制与其保持一致,内存+交换等于-m的两倍大小)默认情况下跟宿主主机一样,都是2G内存,现在我们可以将容器的内存限制到100M试试看,其中物理内存50M,交换内存50M,尝试启动一下SpringBoot程序:
docker run -it -m 50M --memory-swap=100M nagocoler/springboot-test:1.0
可以看到,上来就因为内存不足无法启动了:
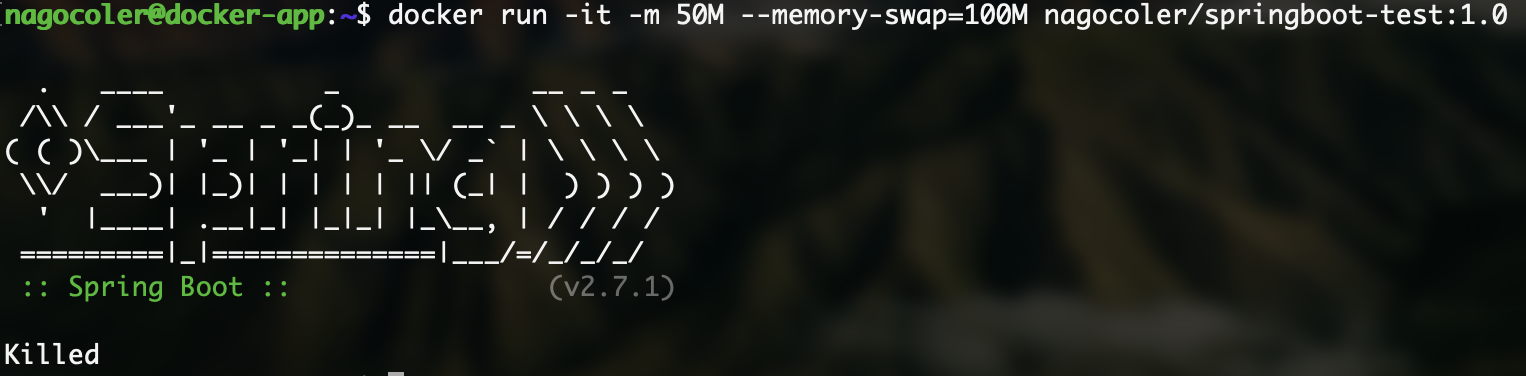
当然除了对内存的限制之外,我们也可以对CPU资源进行限额,默认情况下所有的容器都可以平等地使用CPU资源,我们可以调整不同的容器的CPU权重(默认为1024),来按需分配资源,这里需要使用到-c选项,也可以输入全名--cpu-share:
docker run -c 1024 ubuntu
docker run -c 512 ubuntu
这里容器的CPU权重比例为16比8,也就是2比1(注意多个容器时才会生效),那么当CPU资源紧张时,会按照此权重来分配资源,当然如果CPU资源并不紧张的情况下,依然是有机会使用到全部的CPU资源的。
这里我们使用一个压力测试工具来进行验证:
docker run -c 1024 --name=cpu1024 -it ubuntu
docker run -c 512 --name=cpu512 -it ubuntu
接着我们分别进入容器安装stress压力测试工具:
apt update && apt install -y stress
接着我们分别在两个容器中都启动压力测试工具,产生4个进程不断计算随机数的平方根:
stress -c 4
接着我们进入top来看看CPU状态(看完之后记得赶紧去kill掉容器,不然CPU拉满很卡的):
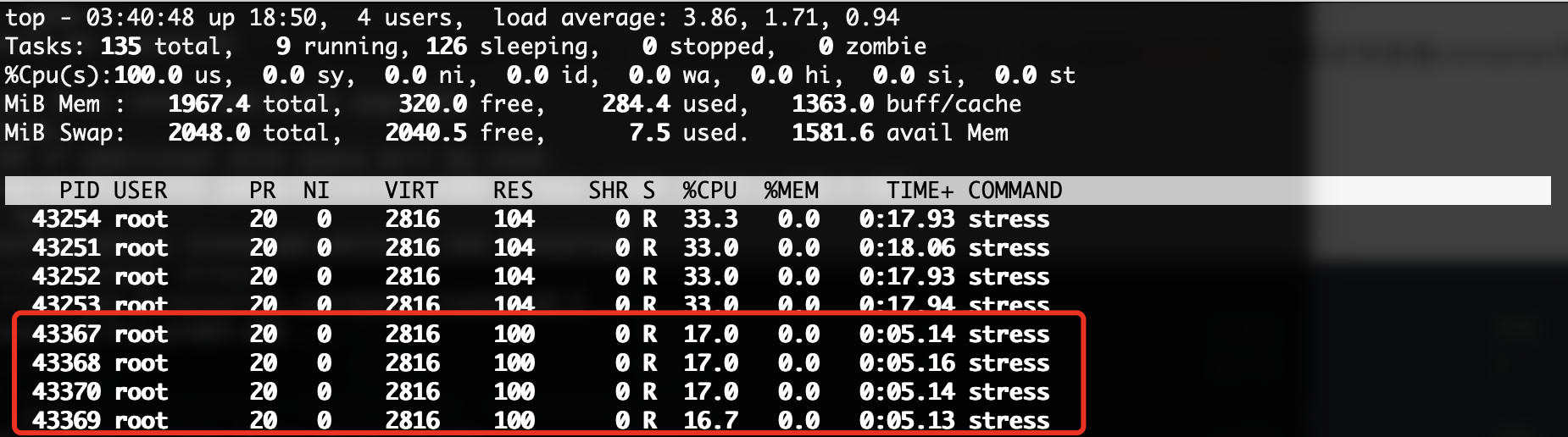
可以看到权重高的容器中,分配到了更多的CPU资源,而权重低的容器中,只分配到一半的CPU资源。
当然我们也可以直接限制容器使用的CPU数量:
docker run -it --cpuset-cpus=1 ubuntu
--cpuset-cpus选项可以直接限制在指定的CPU上运行,比如现在我们的宿主机是2核的CPU,那么就可以分0和1这两个CPU给Docker使用,限制后,只会使用CPU 1的资源了:

可以看到,4个进程只各自使用了25%的CPU,加在一起就是100%,也就是只能占满一个CPU的使用率。如果要分配多个CPU,则使用逗号隔开:
docker run -it --cpuset-cpus=0,1 ubuntu
这样就会使用这两个CPU了:

当然也可以直接使用--cpus来限制使用的CPU资源数:
docker run -it --cpus=1 ubuntu

限制为1后,只能使用一个CPU提供的资源,所以这里加载一起只有一个CPU的资源了。当然还有更精细的--cpu-period 和--cpu-quota,这里就不做介绍了。
最后我们来看一下对磁盘IO读写性能的限制,我们首先使用dd命令来测试磁盘读写速度:
dd if=/dev/zero of=/tmp/1G bs=4k count=256000 oflag=direct
可以不用等待跑完,中途Ctrl+C结束就行:

可以看到当前的读写速度为86.4 MB/s,我们可以通过--device-read/write-bps和--device-read/write-iops参数对其进行限制。
这里要先说一下区别:
- bps:每秒读写的数据量。
- iops:每秒IO的次数。
为了直观,这里我们直接使用BPS作为限制条件:
docker run -it --device-write-bps=/dev/sda:10MB ubuntu
因为容器的文件系统是在/dev/sda上的,所以这我们就/dev/sda:10MB来限制对/dev/sda的写入速度只有10MB/s,我们来测试一下看看:

可以看到现在的速度就只有10MB左右了。
容器监控
最后我们来看看如何对容器的运行状态进行实时监控,我们现在希望能够对容器的资源占用情况进行监控,该怎么办呢?
我们可以使用stats命令来进行监控:
docker stats

可以实时对容器的各项状态进行监控,包括内存使用、CPU占用、网络I/O、磁盘I/O等信息,当然如果我们限制内存的使用的话:
docker run -d -m 200M nagocoler/springboot-test:1.0
可以很清楚地看到限制情况:

除了使用stats命令来实时监控情况之外,还可以使用top命令来查看容器中的进程:
docker top 容器ID/名称

当然也可以携带一些参数,具体的参数与Linux中ps命令参数一致,这里就不多做介绍了。
但是这样的监控是不是太原始了一点?有没有那种网页面板可以进行实时监控和管理的呢?有的。
我们需要单独部署一个Docker网页管理面板应用,一般比较常见的有:Portainer,我们这里可以直接通过Docker镜像的方式去部署这个应用程序,搜索一下,发现最新版维护的地址为:https://hub.docker.com/r/portainer/portainer-ce
CE为免费的社区版本,当然也有BE商业版本,这里我们就直接安装社区版就行了,官方Linux安装教程:https://docs.portainer.io/start/install/server/docker/linux,包含一些安装前需要的准备。
首先我们需要创建一个数据卷供Portainer使用:
docker volume create portainer_data
接着通过官方命令安装启动:
docker run -d -p 8000:8000 -p 9443:9443 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer-ce:latest
注意这里需要开放两个端口,一个是8000端口,还有一个是9443端口。
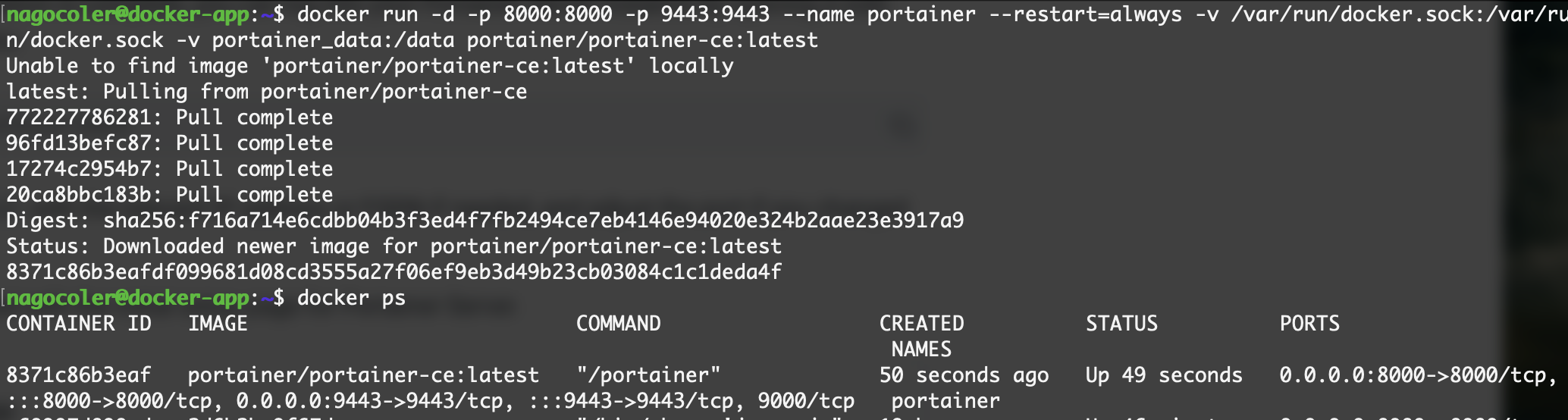
OK,开启成功,我们可以直接登录后台面板:https://IP:9443/,这里需要HTTPS访问,浏览器可能会提示不安全,无视就行:
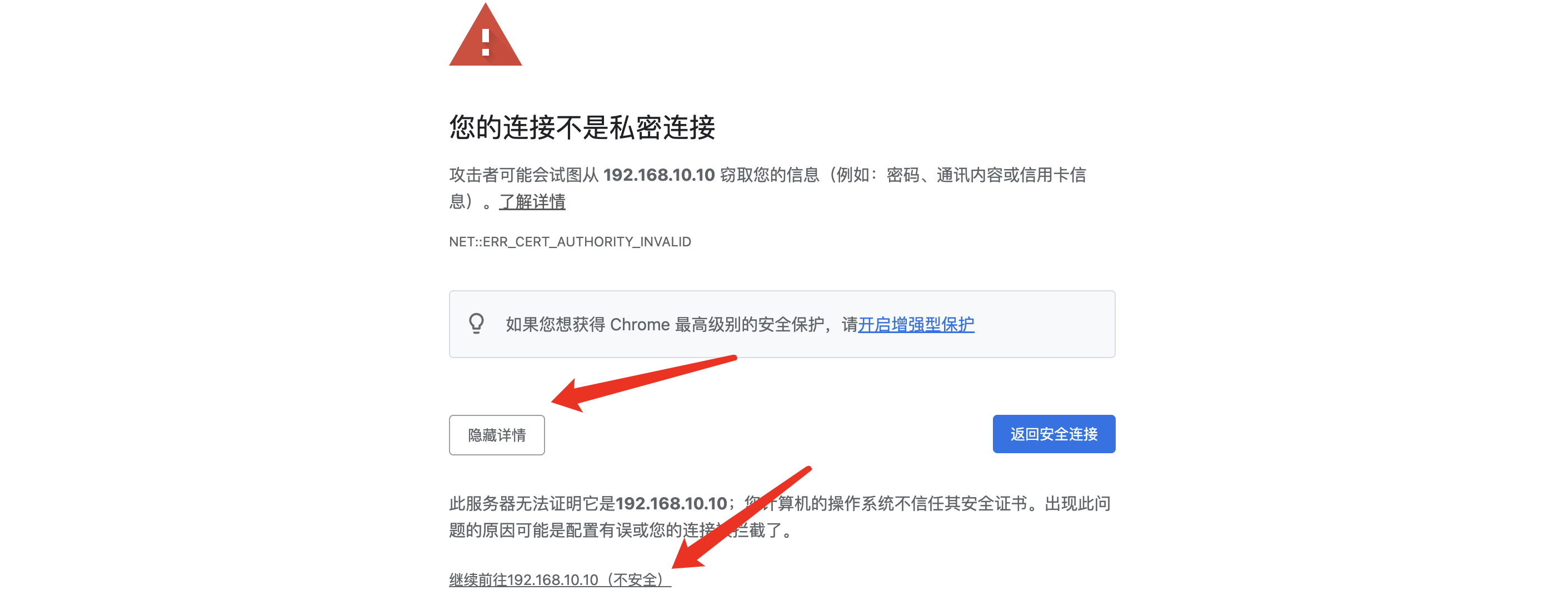
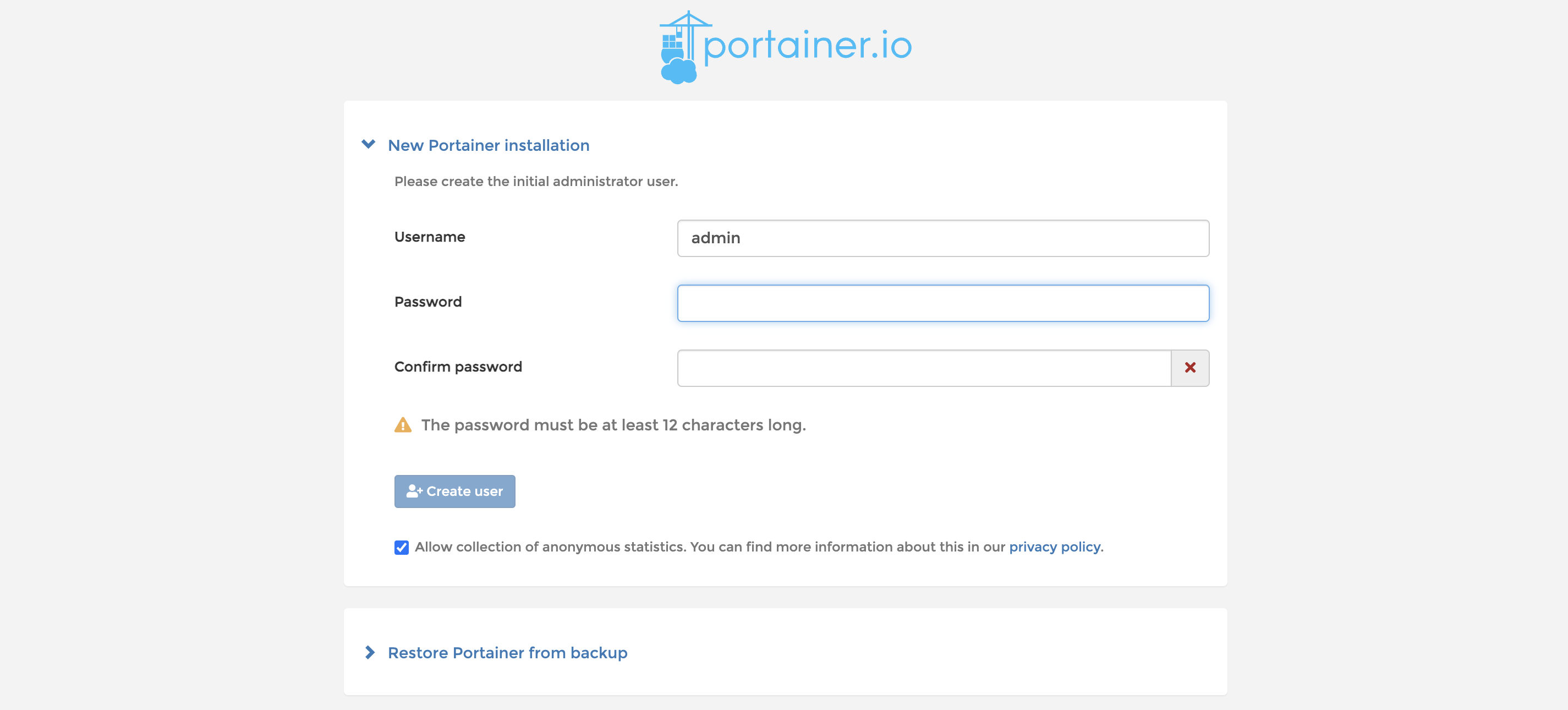
进入后就需要我们进行注册了,这里我们只需输入两次密码即可,默认用户名就是admin,填写完成后,我们就可以开始使用了:
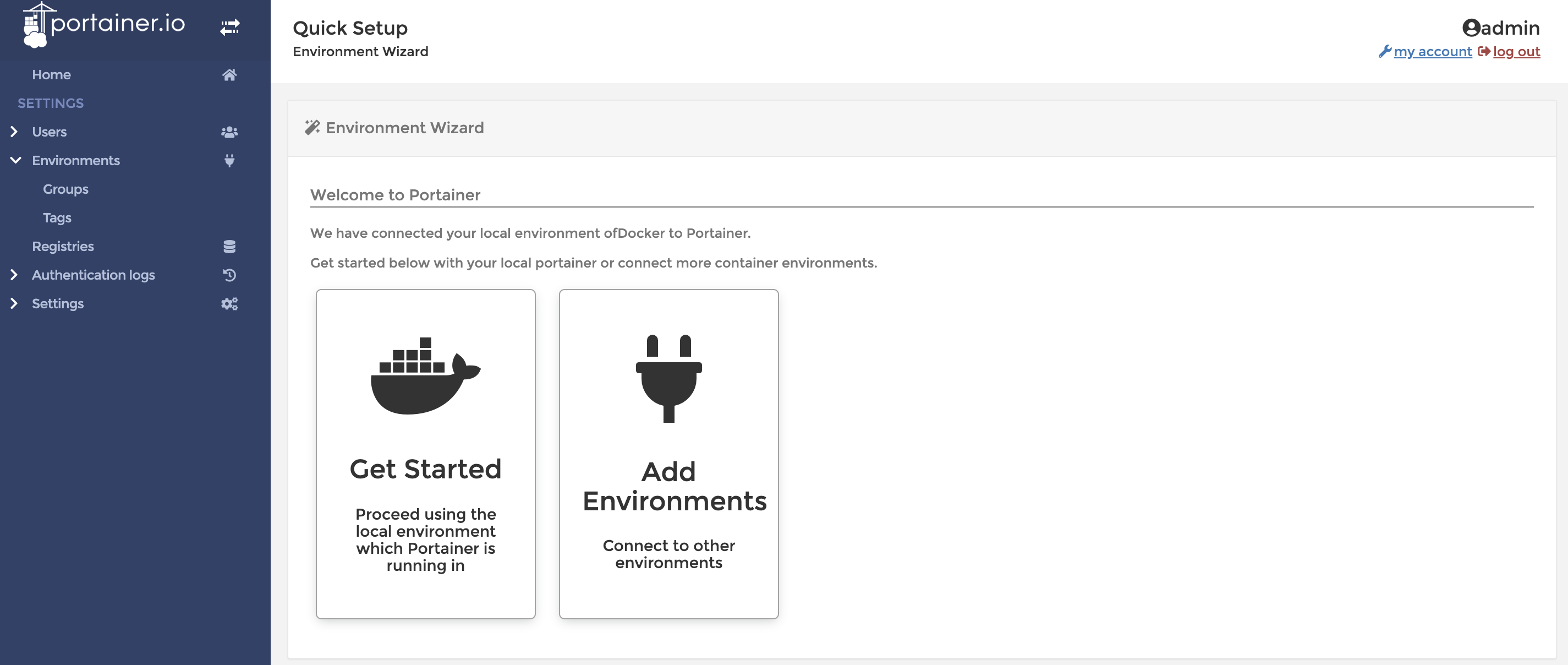
点击Get Started即可进入到管理页面,我们可以看到目前有一个本地的Docker服务器正在运行:
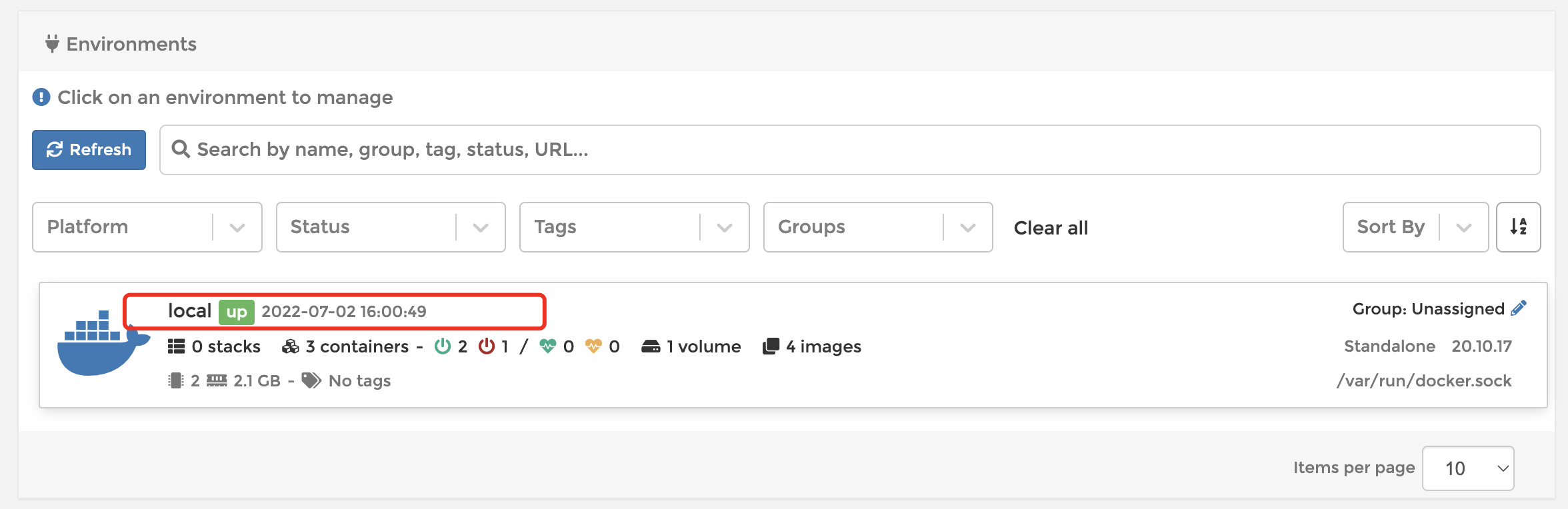
我们可以点击进入,进行详细地管理,不过唯一缺点就是没中文,挺难受的,也可以使用非官方的汉化版本:https://hub.docker.com/r/6053537/portainer-ce。
单机容器编排
最后我们来讲解一下Docker-Compose,它能够对我们的容器进行编排。比如现在我们要在一台主机上部署很多种类型的服务,包括数据库、消息队列、SpringBoot应用程序若干,或是想要搭建一个MySQL集群,这时我们就需要创建多个容器来完成来,但是我们希望能够实现一键部署,这时该怎么办呢?我们就要用到容器编排了,让多个容器按照我们自己的编排进行部署。
**官方文档:**https://docs.docker.com/get-started/08_using_compose/,视频教程肯定不可能把所有的配置全部介绍完,所以如果各位小伙伴想要了解更多的配置,有更多需求的话,可以直接查阅官方文档。
快速开始
在Linux环境下我们需要先安装一下插件:
sudo apt install docker-compose-plugin
接着输入docker compose version来验证一下是否安装成功。

这里我们就以部署SpringBoot项目为例,我们继续使用之前打包好的SpringBoot项目,现在我们希望部署这个SpringBoot项目的同时,部署一个MySQL服务器,一个Redis服务器,这时我们SpringBoot项目要运行的整个完整环境,先获取到对应的镜像:
docker pull mysql/mysql-server
docker pull redis
接着,我们需要在自己的本地安装一下DockerCompose,下载地址:https://github.com/docker/compose/releases,下载自己电脑对应的版本,然后在IDEA中配置:

下载完成后,将Docker Compose可执行文件路径修改为你存放刚刚下载的可执行文件的路径,Windows直接设置路径就行,MacOS下载之后需要进行下面的操作:
mv 下载的文件名称 docker-compose
sudo chmod 777 docker-compose
sudo mv docker-compose /usr/local/bin
配置完成后就可以正常使用了,否则会无法运行,接着我们就可以开始在IDEA中编写docker-compose.yml文件了。

这里点击右上角的“与服务工具窗口同步”按钮,这样一会就可以在下面查看情况了。
我们现在就从头开始配置这个文件,现在我们要创建三个服务,一个是MySQL服务器,一个是Redis服务器,还有一个是SpringBoot服务器,需要三个容器来分别运行,首先我们先写上这三个服务:
version: "3.9" #首先是版本号,别乱写,这个是和Docker版本有对应的
services: #services里面就是我们所有需要进行编排的服务了
spring: #服务名称,随便起
container_name: app_springboot #一会要创建的容器名称
mysql:
container_name: app_mysql
redis:
container_name: app_redis
这样我们就配置好了一会要创建的三个服务和对应的容器名称,接着我们需要指定一下这些容器对应的镜像了,首先是我们的SpringBoot应用程序,可能我们后续还会对应用程序进行更新和修改,所以这里我们部署需要先由Dockerfile构建出镜像后,再进行部署:
spring:
container_name: app_springboot
build: . #build表示使用构建的镜像,.表示使用当前目录下的Dockerfile进行构建
我们这里修改一下Dockerfile,将基础镜像修改为已经打包好JDK环境的镜像:
FROM adoptopenjdk/openjdk8
COPY target/DockerTest-0.0.1-SNAPSHOT.jar app.jar
CMD java -jar app.jar
接着是另外两个服务,另外两个服务需要使用对应的镜像来启动容器:
mysql:
container_name: app_mysql
image: mysql/mysql-server:latest #image表示使用对应的镜像,这里会自动从仓库下载,然后启动容器
redis:
container_name: app_redis
image: redis:latest
还没有结束,我们还需要将SpringBoot项目的端口进行映射,最后一个简单的docker-compose配置文件就编写完成了:
version: "3.9" #首先是版本号,别乱写,这个是和Docker版本有对应的
services: #services里面就是我们所有需要进行编排的服务了
spring: #服务名称,随便起
container_name: app_springboot #一会要创建的容器名称
build: .
ports:
- "8080:8080"
mysql:
container_name: app_mysql
image: mysql/mysql-server:latest
redis:
container_name: app_redis
image: redis:latest
现在我们就可以直接一键部署了,我们点击下方部署按钮:


看到 Running 4/4 就表示已经部署成功了,我们现在到服务器这边来看看情况:

可以看到,这里确实是按照我们的配置,创建了3个容器,并且都是处于运行中,可以正常访问:

如果想要结束的话,我们只需要点击停止就行了:

当然如果我们不再需要这套环境的话,可以直接点击下方的按钮,将整套编排给down掉,这样的话相对应的容器也会被清理的:


注意在使用docker-compose部署时,会自动创建一个新的自定义网络,并且所有的容器都是连接到这个自定义的网络里面:

这个网络默认也是使用bridge作为驱动:

这样,我们就完成了一个简单的配置,去部署我们的整套环境。
部署完整项目
前面我们学习了使用docker-compose进行简单部署,但是仅仅只是简单启动了服务,我们现在来将这些服务给连起来。首先是SpringBoot项目,我们先引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
接着配置一下数据源,等等,我们怎么知道数据库的默认密码是多少呢?所以我们先配置一下MySQL服务:
mysql:
container_name: app_mysql
image: mysql/mysql-server:latest
environment: #这里我们通过环境变量配置MySQL的root账号和密码
MYSQL_ROOT_HOST: '%' #登陆的主机,这里直接配置为'%'
MYSQL_ROOT_PASSWORD: '123456.root' #MySQL root账号的密码,别设定得太简单了
MYSQL_DATABASE: 'study' #在启动时自动创建的数据库
TZ: 'Asia/Shanghai' #时区
ports:
- "3306:3306" #把端口暴露出来,当然也可以不暴露,因为默认所有容器使用的是同一个网络
有关MySQL的详细配置请查阅:https://registry.hub.docker.com/_/mysql
接着我们将数据源配置完成:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://app_mysql:3306/study #地址直接输入容器名称,会自动进行解析,前面已经讲过了
username: root
password: 123456.root
然后我们来写点测试的代码吧,这里我们使用JPA进行交互:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity
@Table(name = "db_account")
public class Account {
@Column(name = "id")
@Id
long id;
@Column(name = "name")
String name;
@Column(name = "password")
String password;
}
@Repository
public interface AccountRepository extends JpaRepository<Account, Long> {
}
@RestController
public class MainController {
@Resource
AccountRepository repository;
@RequestMapping("/")
public String hello(){
return "Hello World!";
}
@GetMapping("/get")
public Account get(@RequestParam("id") long id){
return repository.findById(id).orElse(null);
}
@PostMapping("/post")
public Account get(@RequestParam("id") long id,
@RequestParam("name") String name,
@RequestParam("password") String password){
return repository.save(new Account(id, name, password));
}
}
接着我们来修改一下配置文件:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://app_mysql:3306/study
username: root
password: 123456.root
jpa:
database: mysql
show-sql: true
hibernate:
ddl-auto: update #这里自动执行DDL创建表,全程自动化,尽可能做到开箱即用
现在代码编写完成后,我们可以将项目打包了,注意执行我们下面的打包命令,不要进行测试,因为连不上数据库:
mvn package -DskipTests
重新生成jar包后,我们修改一下docker-compose配置,因为MySQL的启动速度比较慢,我们要一点时间等待其启动完成,如果连接不上数据库导致SpringBoot项目启动失败,我们就重启:
spring: #服务名称,随便起
container_name: app_springboot #一会要创建的容器名称
build: .
ports:
- "8080:8080"
depends_on: #这里设置一下依赖,需要等待mysql启动后才运行,但是没啥用,这个并不是等到启动完成后,而是进程建立就停止等待
- mysql
restart: always #这里配置容器停止后自动重启
然后我们将之前自动构建的镜像删除,等待重新构建:
现在我们重新部署docker-compos吧:

当三个服务全部为蓝色时,就表示已经正常运行了,现在我们来测试一下吧:

接着我们来试试看向数据库传入数据:
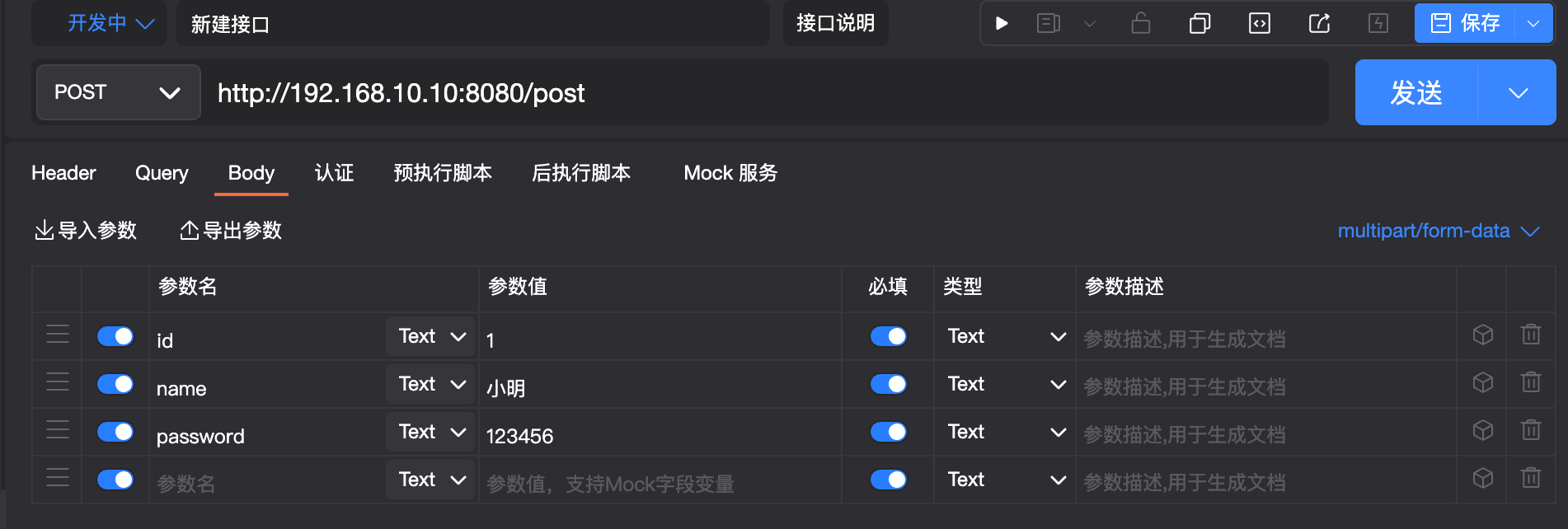

可以看到响应成功,接着我们来请求一下:

这样,我们的项目和MySQL基本就是自动部署了。
接着我们来配置一下Redis:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
接着配置连接信息:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://app_mysql:3306/study
username: root
password: 123456.root
jpa:
database: mysql
show-sql: true
hibernate:
ddl-auto: update
redis:
host: app_redis
//再加两个Redis操作进来
@Resource
StringRedisTemplate template;
@GetMapping("/take")
public String take(@RequestParam("key") String key){
return template.opsForValue().get(key);
}
@PostMapping("/put")
public String put(@RequestParam("key") String key,
@RequestParam("value") String value){
template.opsForValue().set(key, value);
return "操作成功!";
}
最后我们来配置一下docker-compose的配置文件:
redis:
container_name: app_redis
image: redis:latest
ports:
- "6379:6379"
OK,按照之前的方式,我们重新再部署一下,然后测试:
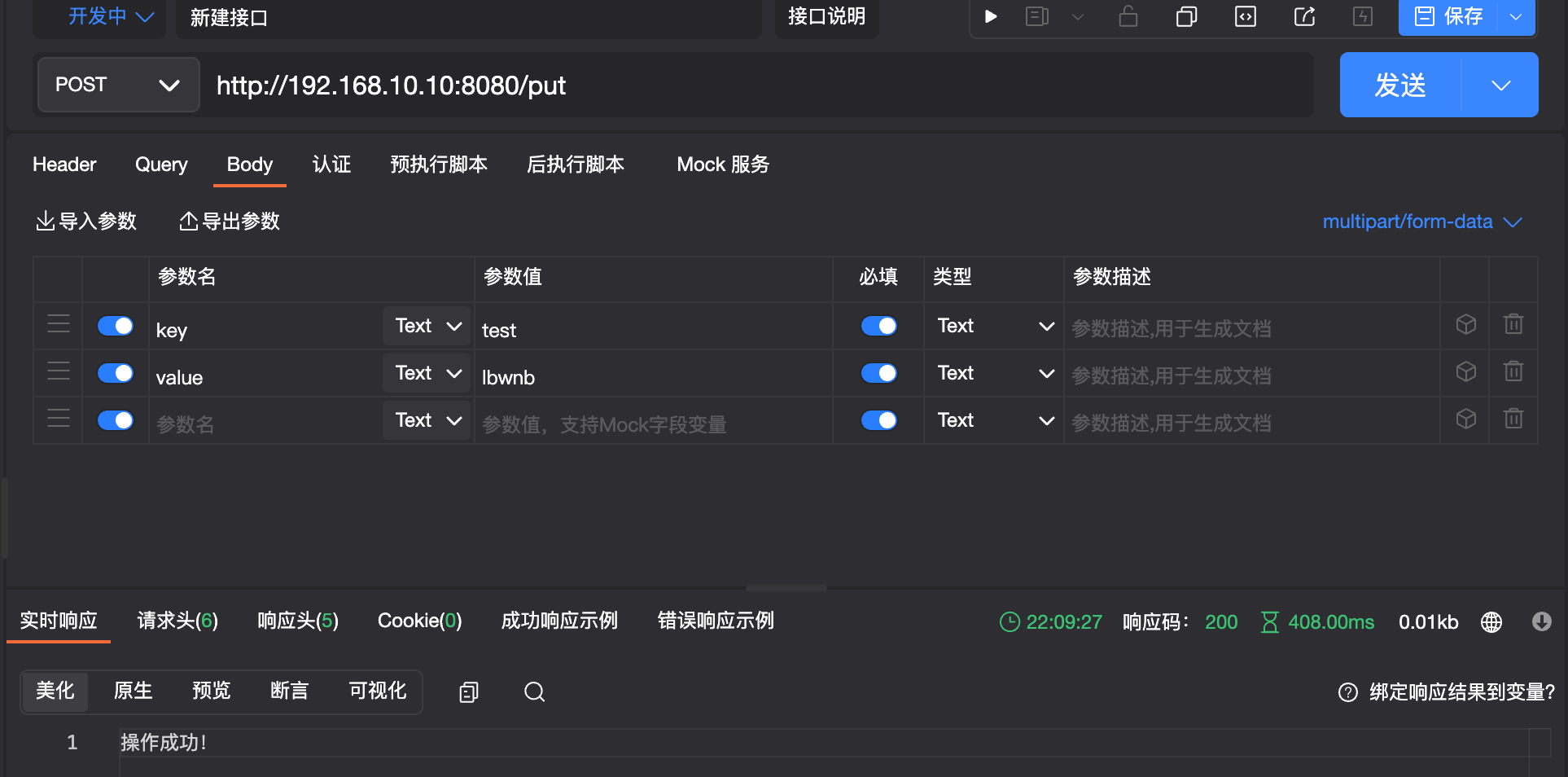

这样我们就完成整套环境+应用程序的配置了,我们在部署整个项目时,只需要使用docker-compose配置文件进行启动即可,这样就大大方便了我们的操作,实现开箱即用。甚至我们还可以专门使用一个平台来同时对多个主机进行一次性配置,大规模快速部署,而这些就留到以后的课程中再说吧。
总结
好好学习,天天向上。
| 往期专栏 |
|---|
| Java全栈开发 |
| 数据结构与算法 |
| 计算机组成原理 |
| 操作系统 |
| 数据库系统 |
| 物联网控制原理与技术 |



![[黑盾CTF 2023] secret_message 复现](https://img-blog.csdnimg.cn/ce77087f9c8b4ed2b832ecb9436daf02.png)