Hive安装部署(最小化部署)
安装部署Hive(最小化只用于本机测试环境中,不可用于生产环境),并运行。
步骤:
(1)把apache-hive-3.1.3-bin.tar.gz解压到/opt/module/目录下:
tar -zxvf /opt/software/apache-hive-3.1.3-bin.tar.gz -C /opt/module/
(2)修改apache-hive-3.1.3-bin.tar.gz的名称为hive:
mv /opt/module/apache-hive-3.1.3-bin/ /opt/module/hive
(3)修改/etc/profile.d/my_env.sh,添加环境变量:
sudo vim /etc/profile.d/my_env.sh
# 添加以下:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
(4)source一下,让环境变量生效:
source /etc/profile.d/my_env.sh
(5)先开启hadoop,再初始化元数据库:
myhadoop.sh start
bin/schematool -dbType derby -initSchema
最小化模式把元数据保存在默认的derby数据库中,最小化模式只适用于本地测试,不能用于生产环境。
Hive把元数据库metastore_db保存在hive的根目录下。
(6)启动hive:
bin/hive
(7)使用hive:
查看当前所有数据库信息,当没有声明使用什么数据库时则使用默认default数据库
hive> show databases;
hive> show tables;
创建表后hive把表到hdfs的路径进行映射,映射关系保存在元数据库中,在建表时可以指定hdfs路径,未指定则使用默认路径/user/hive/warehouse/中
hive> create table stu(id int, name string);
hive> insert into stu values(1,"ss");
hive优化了简单查询语句,即执行简单查询时hive不向yarn提交任务,减少了开销
hive> select * from stu;
Hive和Hadoop的关系:
Hive中的表在Hadoop中是目录;Hive中的数据在Hadoop中是文件。
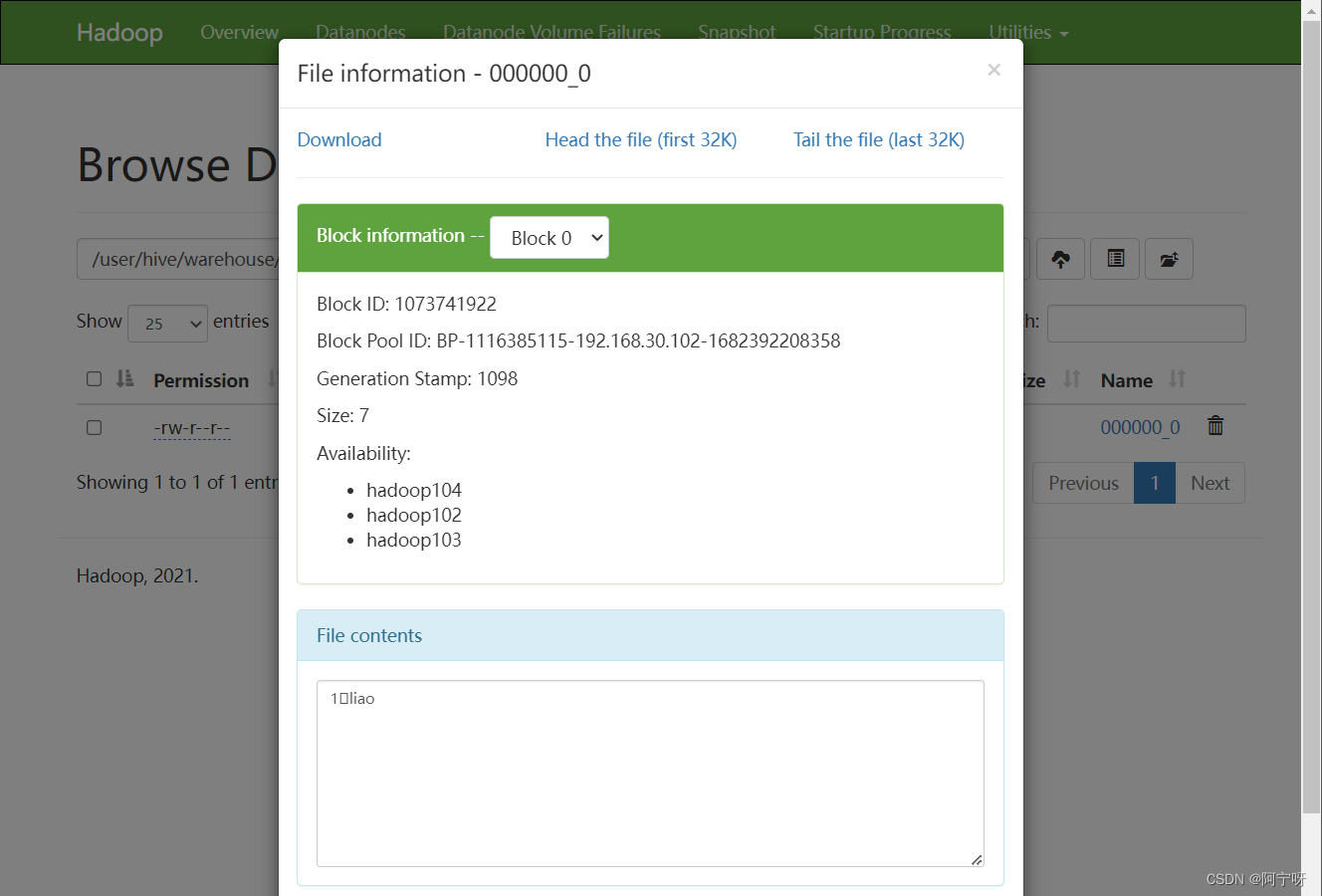
(8)在另外一个窗口开启hive,查看/tmp/用户名/下的hive.log日志文件:
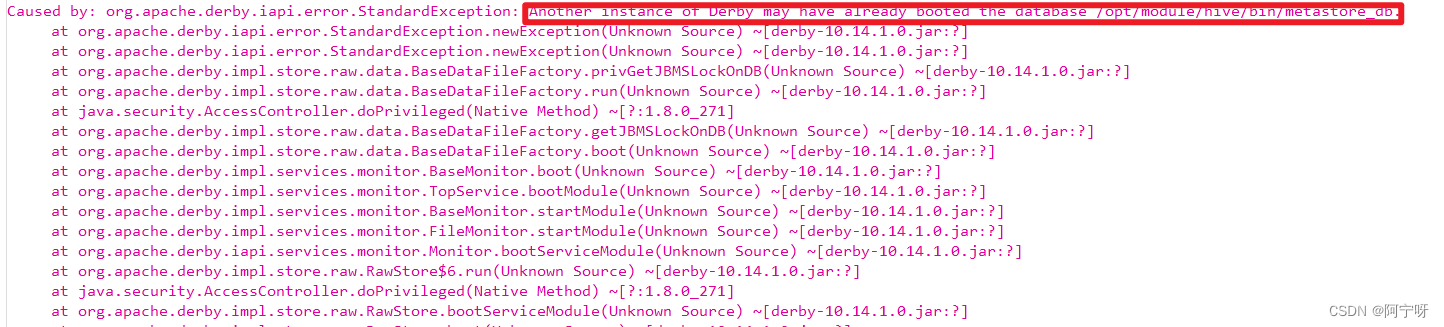
报错原因:
Hive默认使用的元数据库为derby,derby数据库在同一时间只能一个客户访问,如果多个hive客户端同时访问会报错。
解决:
企业开发中需要多客户访问hive,所以把hive元数据用MYSQL存储,MYSQL支持多客户端同时访问。
(9)先退出hive客户端,在hive根目录下删除derby.log和metastore_db,以及删除HDFS上的hive目录。
hive> quit;
rm -rf derby.log metastore_db
hadoop fs -rm -r /user