《A review of convolutional neural network architectures and their optimizations》论文指出一些高性能的卷积神经网络方法不可避免地带来巨大的计算成本,往往需要高性能GPU或高度优化的分布式CPU架构的支持。尽管CNNs应用向移动终端扩展,但大多数移动设备并不具备强大的计算能力和巨大的内存空间。因此,需要对轻量级网络架构进行研究,以妥善处理上述问题。轻量级卷积神经网络一般是指压缩和加速后得到的更小的卷积神经网络结构,其特点如下:
1 .与服务器通信要求小;
2 .网络参数少,模型数据量低;
3 .适合部署在内存受限的设备上。
为了使CNNs在满足需求的同时保持性能,提出了深度可分离卷积的架构。文中主要介绍了以下几个网络结构:MobileNet v1、MobileNet v2、MobileNet v3、Xception、ShuffleNet v1、ShuffleNet v2。
下面,本博文将介绍什么是深度可分离卷积,并对上述网络架构进行介绍。
目录
1.深度可分离卷积
1.1 逐通道卷积(Depthwise Convolution)
1.2 逐点卷积(Pointwise Convolution)
1.3 参数及计算量对比
2.MobileNet v1(2017)
2.1 网络结构
2.2 论文
2.3 参考博文
3.MobileNet v2(2018)
3.1 网络结构
3.2 Linear Bottlnecks(线性瓶颈结构)
3.3 Inverted Residuals(反向残差)
3.4 论文
4.MobileNet v3(2019)
4.1 网络架构
4.2 网络改进
4.3 论文
5.Xception(2017)
5.1 基于Inceptionv3模型改进
5.2 网络结构
5.3 论文
5.4 参考博文
6.ShuffleNetV1(2017)
6.1 group convolution
6.2 channel shuffle
6.3 ShuffleNet Units
6.4 网络结构
6.5 论文
6.6 参考博文
7.ShuffleNetV2(2018)
7.1 4个设计轻量级网络的要领
7.2 ShuffleNet Unit
7.3 网络结构
7.4 论文
7.5 参考博文
1.深度可分离卷积
深度可分离卷积 主要是两种卷积变体组合使用,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
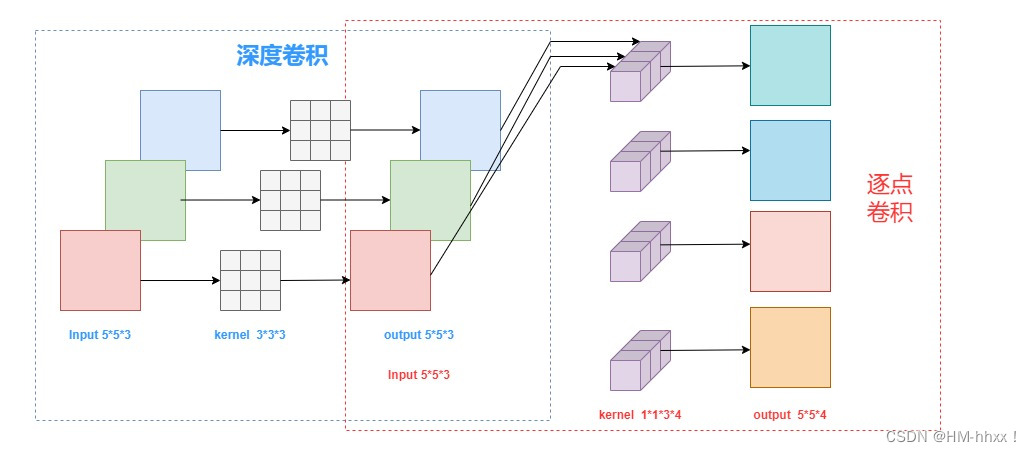
1.1 逐通道卷积(Depthwise Convolution)
Depthwise Convolution的一个卷积核只有一个通道,输入信息的一个通道只被一个卷积核卷积,这个过程产生的feature map通道数和输入的通道数完全一样。以一张5x5x3(长和宽为5,RGB3通道)的彩色图片为例。每层深度卷积卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。设padding=1,stride=1,一个三通道的图像经过运算后生成了3个特征图,如上图中蓝色虚线框部分所示。
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法在通道维度上扩展或压缩Feature map的数量。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的features的相关性。简而言之,虽然减少了计算量,但是失去了通道维度上的信息交互。因此需要Pointwise Convolution来将这些Feature maps进行组合生成新的Feature maps。
1.2 逐点卷积(Pointwise Convolution)
Pointwise Convolution的运算与常规卷积运算非常相似,其实就是1X1的卷积。它的卷积核的尺寸为 1×1×M,M为上一层输出信息的通道数。所以这里Pointwise Convolution的每个卷积核会将上一步的feature maps在通道方向上进行加权组合,生成新的feature map。有几个卷积核就有几个输出多少个新的feature maps,如图红色虚线部分所示。
1.3 参数及计算量对比
常规卷积参数个数:
卷积层共4个Filter,每个Filter包含一个通道数为3(与输入信息通道相同),且尺寸为3×3的kernel。因此卷积层的参数数量可以用如下公式来计算(即:卷积核W x 卷积核H x 输入通道数 x 输出通道数):
N_std = 4 × 3 × 3 × 3 = 108
深度可分离卷积参数个数:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
常规卷积计算量:
计算量可以用如下公式来计算(即:卷积核W x 卷积核H x (图片W-卷积核W+1) x (图片H-卷积核H+1) x 输入通道数 x 输出通道数):
C_std =3×3×(5-2)×(5-2)×3×4=972
深度可分离卷积计算量:
深度卷积计算量可用如下公式进行计算(卷积核W×卷积核H×(图片W-卷积核W+1)×(图片H-卷积核H+1)×输入通道数):
C_depthwise=3x3x(5-2)x(5-2)x3=243
逐点卷积计算量则为(1 x 1 特征层W x 特征层H x 输入通道数 x 输出通道数):
C_pointwise = 1 × 1 × 3 × 3 × 3 × 4 = 108
C_separable = C_depthwise + C_pointwise = 351
结论:
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数和据算量是常规卷积的约1/3。因此,在参数量相同的前提下,采用Depthwise Separable Convolution的神经网络层数可以做的更深。
2.MobileNet v1(2017)
MobileNetv1将传统的卷积过程分解为Depthwise卷积和Pointwise卷积两个步骤,在模型大小和计算负担方面都实现了大幅压缩。
2.1 网络结构
MobileNet的网络结构下表所示。首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。经过卷积提取特征后再采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。

从整个网络架构来看,不算平均池化层与softmax层,共28层,且步长为2的卷积同时充当了下采样的功能,在每一个卷积层之后也会紧跟BN操作和ReLU激活后函数,结构如系图所示,左侧为标准卷积后接batchnorm和ReLU,右侧为深度可分离卷积中深度卷积和逐点卷积后接的batchnorm和ReLU。
2.2 论文
论文:《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
https://arxiv.org/pdf/1704.04861.pdf
贡献:用深度可分离卷积代替普通卷积;
缺陷:深度卷积存在无效卷积核;
2.3 参考博文
1.轻量级神经网络MobileNet全家桶详解_轻量级网络模型_雷恩Layne的博客-CSDN博客
2.
深度学习之图像分类(九):MobileNet系列(V1,V1,V3) - 魔法学院小学弟
3.MobileNet v2(2018)
Mark Sandler等人基于MobileNetv1,提出了线性瓶颈(linear bottleneck)的反向残差(inverted residual),并以此构建了MobileNetv2,其速度和精度均优于MobileNetv1。
3.1 网络结构
MobileNetv2网络结构如下图所示,t代表反转残差中第一个1*1卷积升为的倍数;c代表通道数;n代表堆叠的bottleneck的次数;s代表DWconv的幅度(1或2),不同的步幅对应了不同的模块(如图d所示)。效果上,在 ImageNet 图像分类的任务中,相比 V1 参数量减少了,效果也好了一些。


MobileNetV2网络模型中有共有17个Bottleneck层(每个Bottleneck包含两个逐点卷积层和一个深度卷积层),一个标准卷积层(conv),两个逐点卷积层(pw conv),共计有54层可训练参数层。MobileNetV2中使用线性瓶颈(Linear Bottleneck)和反向残差(Inverted Residuals)结构优化了网络,使得网络层次更深了,但是模型体积更小,速度更快了。
3.2 Linear Bottlnecks(线性瓶颈结构)
该模块将Inverted Residuals block中的bottleneck处的Relu去掉,通过下图可见,实质就是去掉了1*1卷积后的Relu激活函数,转为Linear激活函数,因为1X1卷积降维操作本来就会丢失一部分信息,ReLU 会对 channel 数较低的张量造成较大的信息损耗,出现输出为0的情况。线性瓶颈结构有两种,第一种是步长为1时使用残差结构,第二种是步长为2时不使用残差结构。

3.3 Inverted Residuals(反向残差)
通过下图对比,如果采用residual block,在mobilenet中逐通道进行卷积,本来feature的维度就不多,如果还进行压缩,会使模型太小,所以使用inverted residual,先进行扩展(6倍)后进行压缩,这样就不会使模型压缩太厉害。MobileNetV2的残差结构实际是在线性瓶颈结构的基础上增加残差传播。
ResNet中的残差结构使用第一层逐点卷积降维,后使用深度卷积,再使用逐点卷积升维。
MobileNetV2版本中的残差结构使用第一层逐点卷积升维并使用Relu6激活函数代替Relu,之后使用深度卷积,同样使用Relu6激活函数,再使用逐点卷积降维,降维后使用Linear激活函数。

3.4 论文
论文:《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
https://openaccess.thecvf.com/content_cvpr_2018/papers/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.pdf
贡献:引入逆向残差(inverted residual)和线性瓶颈(linear bottleneck)结构;
缺陷:可优化的特征提取效率;
4.MobileNet v3(2019)
Andrew G. Howard 等于 2019 年又提出了 MobileNet V3。文中提出了两个网络模型, MobileNetV3-Small 与 MobileNetV3-Large 分别对应对计算和存储要求低和高的版本。
-
Large版本共有15个bottleneck层,一个标准卷积层,三个逐点卷积层。
-
Small版本共有12个bottleneck层,一个标准卷积层,两个逐点卷积层。
4.1 网络架构
MobileNet V3-Large结构图:
MobileNetV3中引入了5×5大小的深度卷积代替部分3×3的深度卷积。引入Squeeze-and-excitation(SE)模块和 h-swish(HS)激活函数以提高模型精度。结尾两层逐点卷积不使用批规范化(Batch Norm),在MobileNetV3结构图中使用NBN标识。

MobileNet V3-Small结构图:

4.2 网络改进
1.基于 MobileNetV2的改进:
作者发现v2网络最后一部分结构可以优化,如上图所示,去除3x3 Dconv,1x1Conv等卷积层,原始结构使用1×1卷积进行feature维度的调整,从而提高模型预测的精度,但这一部分工作会造成一定的时间消耗,因此,作者将average pooling提前,这样可以提前把feature的size减下来(pooling之后的feature size由7×7降至1×1),并且精度几乎没有降低。
2.h-swish:
文中指出利用swish激活函数比ReLU激活函数精度高,但swish激活函数在移动端设备上耗费资源,因此作者提出h-swish激活函数代替swish,效果和swish差不多,但计算量大大减少,下图为h-swish激活函数表达式:
Sigmoid和Swish非线性函数的"hard"对比:

3.squeeze-and-excite(SE):
SE模块由自动驾驶公司Momenta在2017年公布的一种图像识别结构,旨在通过对特征通道之间的相关性进行建模,把重要的特征进行强化来提升准确率。运用SE模块使得有效的权重大,无效或效果较小的权重小,可以训练出更好的模型。改进的SE模块在传统SE模块的基础上保证了准确率,提升了性能,减少了参数量和计算量。
与MobileNetV2相比,MobileNetV3中增加了SE结构,并将含有SE结构部分的expand layer 的channel数减少,发现这样做增加了精度,在适度增加参数的数量,并且没有明显的延迟成本。

参考链接:
SE:解读Squeeze-and-Excitation Networks(SENet) - 简书
4.3 论文
论文:《Searching for MobileNetV3》
https://openaccess.thecvf.com/content_ICCV_2019/papers/Howard_Searching_for_MobileNetV3_ICCV_2019_paper.pdf
贡献:引入Squeeze-and-excitation(SE)模块和 h-swish(HS)激活函数,引入神经架构搜索(NAS)技术生成的网络结构;
缺陷:网络解释性差,模型结构混乱,不利于模型部署,昂贵的计算成本;
5.Xception(2017)
Xception借鉴了AlexNet中引入的深度可分离卷积的思想,可以认为是一种极端的Inception架构。下图描述了Xception模块,该模块拓宽了原有的Inception,使用一层紧跟1 × 1的3 × 3卷积核替换不同空间维度的( 1 × 1、3 × 3、3 × 3),从而调节计算复杂度。首先,输入特征图通过1 × 1卷积核进行处理。然后,使用3 × 3的卷积核对输出特征图的每个通道进行卷积操作。最后将所有输出拼接在一起,得到新的特征图。尽管Xception网络的训练参数比Inceptionv3少,但Xception网络的识别精度和训练速度与Inceptionv3相同,在更大的数据集上也有更好的表现。

与深度可分离卷积对比,唯一的区别是 1X1 卷积的执行顺序是在 Depthwise Conv之前还是之后而已。他们从不同的角度揭示了深度可分离卷积的强大作用,MobileNet的思路是通过将普通卷积拆分的形式来减少参数数量,而Xception是通过对Inception的充分解耦来完成的。
5.1 基于Inceptionv3模型改进
针对Inceptionv3改进步骤:
(1)Inceptionv3原始模块如下图所示

(2)简化Inception模块:

(3)inception改进
对于一个输入的Feature Map,首先通过三组 1X1 卷积得到三组Feature Map,它和先使用一组 1X1 卷积得到Feature Map,再将这组Feature Map分成三组是完全等价的。

(4)Xception模块
Inception模块的一个"极端"版本,在1x1卷积的每一个输出通道有一个空间卷积。此时,这个的参数数量是普通卷积的 1/k,k为3×3卷积的个数。

5.2 网络结构
数据首先经过Entry flow,然后经过Middle flow重复八次,最后经过Exit flow。注意,所有的卷积层和可分离卷积层后面都进行了batch normalization(不包括在图中)。所有的Separable Convolution层使用1 (无深度扩展)的深度乘子。

5.3 论文
论文:《Xception: Deep Learning with Depthwise Separable Convolutions》
https://arxiv.org/pdf/1610.02357v3.pdf
贡献:结合卷积分离和深度可分离卷积;
缺陷:计算开销大,模型结构复杂;
5.4 参考博文
1.深度学习之图像分类(五):GoogLeNet - 魔法学院小学弟
6.ShuffleNetV1(2017)
ShuffleNet v1是由旷视科技在2017年底提出的轻量级可用于移动设备的卷积神经网络。
该网络创新之处在于,使用 group convolution还有channel shuffle,保证网络准确率的同时,大幅度降低了所需的计算资源。作者在文中提出了pointwise group convolution来降低逐点卷积的计算量,但在组卷积运算中,group与group之间没有联系,在一定程度上影响了网络的准确度,因此作者提出shuffle操作,在channel见进行shuffle操作可以加强group之间的联系,在一定的计算复杂度下,网络允许更多的通道数来保留更多的信息。
6.1 group convolution
group convolution:
与普通卷积相比,虽然在参数量与运算向上两者相同,但通过组卷积可生成g倍的feature map数量,所以group conv可以用少量的参数两和运算量就能生成大量的feature map,获取更多的特征信息。如下图所示,g作为分组数量的控制参数,最小值为1,最大值为输入feature map的通道数。当g=1时,为普通卷积,当g=输入feature map通道数时,为深度分离卷积(depthwise sepereable convolution)。

6.2 channel shuffle
在Group Convolution中,仅仅是将这一个Group内的特征图进行了融合,但是不同的group之间缺乏计算,不同组中的特征图对于其他组的特征了解就越来越少。因此,作者提出把每个组的特征图经过组卷积计算之后,结果进行一定程度的乱序结合再送入下一层组卷积,以这样的方式增加特征图的连接融合次数,过程如下图所示:

上图中(a)为正常的组卷积;(b)和(c)是channel shuffle的方式。
6.3 ShuffleNet Units
如下图所示,(a)深度卷积( DWConv )]的瓶颈单元;(B )点群卷积( GConv )和通道洗牌的ShuffleNet单元;(c)步幅= 2的ShuffleNet单元。
(b)是3X3卷积步幅等于1的情况,可以看出与DWconv非常像,只是为了进一步减少参数量将 1X1 kernel尺寸的卷积优化成1X1组卷积,而且添加channel shuffle来确保不同组之间的信息交互。注意:Channel Shuffle操作在1×1的卷积操作之后,也就是先对通道进行了收缩,随后进行通道调整,最后卷积在调整回原来的通道数;
(c)是步幅等于2的情况,即输出特征图尺寸减半,channel维度增加为原先的2倍,为了保证最后的concat连接,需要保证两个分支的输出特征图尺寸相同,因此,在捷径分支上添加步幅为2的3X3全局池化。

6.4 网络结构
下图为ShuffleNet-v1网络结构,stride表示步幅,不同的步幅对应不同的ShuffleNet Units;repeat代表重复次数,例如stage3阶段对stride为2的ShuffleNet Units惊醒重复一次,对stride为1的ShuffleNet Units单元重复七次;

在上图的网络架构基础之上,作者也按照MobileNetV1的思路,对于网络设置了一些超参数s,表示通道数的多少,例如s=1,即标准的网络结构;s=0.5表明每个stage的输出和输入通道数都为上图中通道数的一半,其他的类似。通过通道缩放s倍,整个计算复杂度和参数均下降s2 倍。

6.5 论文
论文:《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》
https://arxiv.org/pdf/1707.01083.pdf
贡献:引入pointwise group convolution和channel shuffle;
缺陷:产生边界效应;
6.6 参考博文
1.ShuffleNet:通道的打乱与混洗_通道混洗_心之所向521的博客-CSDN博客
2.深度学习之图像分类(十):ShuffleNet系列(V1,V2) - 魔法学院小学弟
7.ShuffleNetV2(2018)
2018年,Ma等人提出了一种称为ShuffleNetv2的新架构。并在论文中指出,作为衡量计算复杂度的指标,FLOPs实际并不等同于速度。FLOPs相似的网络中,在速度上有着巨大的差别,因此还需考虑内存消耗及GPU并行计算。
7.1 4个设计轻量级网络的要领
在论文中,作者指出了4个设计轻量级网络的要领:
G1) Equal channel width minimizes memory access cost (MAC).
当卷积的输入和输出是相同维度的通道时,将最小化内存访问成本,如下表所示,当input/output=1:1时,每秒处理的涂料数量最多。
 G2) Excessive group convolution increases MAC.
G2) Excessive group convolution increases MAC.
过多的分组卷积会加大内存访问成本,如下表所示,随分组数的增多,速度会急剧下降,尤其在GPU上。同时也说明了并不是参数量越小,计算复杂度越小,运算速度就越快。因此,作者建议根据目标平台和任务谨慎选择组数。简单地使用大量的组数是不明智的,因为这可能使使用更多的通道,因为精度提高的好处很容易被迅速增加的计算成本所抵消。

G3) Network fragmentation reduces degree of parallelism.
碎片化操作(将一个大卷积分解为多个小卷积)将会减小网络的平行度,作者在实验中发现,固定FLOPs的情况下,分别对比串和并行分支结构,结果发现增加并行度的平行结构居然降低了速度的,结果如下表所示:
G4) Element-wise operations are non-negligible.
不要忽略元素级操作,即ReLU,AddTensor,AddBias等对矩阵元素的操作,它们具有较小的FLOPs但相对较重的MAC。为了验证该想法,作者对bottleneck这个层级进行了相应的修改,测试了是否含有ReLU和short-cut操作的两种情况,对比如下表所示,可以看到,在去除ReLU和short-cut后,GPU和ARM都获得了20 %左右的加速比。

Conclusion and Discussions:
1 )使用"平衡"卷积(等通道宽度);
2 )意识到使用分组卷积的代价;
3 )降低碎片化程度;
4 )减少元素操作。
7.2 ShuffleNet Unit
如下图所示,(a)(b)对应shufflenetV1是uints; (c),(d)对应改进后的V2版units。为了解决在全卷积或者分组卷积中维护大多数的卷积的输入通道数与输出通道数相等,作者提出了Channel Split操作。
split channel把整个特征图分为两个组了(模拟分组卷积的分组操作,接下来的1X1卷积又变回了正常卷积),这样的分组避免了像分组卷积一样过多的增加了卷积时的组数,符合G2。split channel之后,一个小组的数据是通过short-cut通道,而另一个小组的数据经过bottleneck层;这时,由于split channel已经降低了维度,因此bottleneck的1X1就不需要再降维了,输入输出的通道数就可以保持一致,符合G1。同时,由于最后使用的concat操作,没有用TensorAdd操作,符合G4。

7.3 网络结构

7.4 论文
论文:《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》
https://arxiv.org/pdf/1807.11164.pdf
贡献:提出了轻量快速模型的四个准则;优化了shufflenet网络结构;
缺陷:特征损失显著;
7.5 参考博文
1.轻量级神经网络——shuffleNet2_秃头小苏的博客-CSDN博客