一、协同过滤概念
不论在淘宝还是京东,你浏览了/购买了某个商品A,后面几天你在该app内总是会在首页看到商品A和商品A相似的商品,背后支撑这种能力的就是推荐系统,而其推荐算法可能就是协同过滤。(注:app内的这种广告推荐能力是可以被关闭的,感谢人民政府)
核心思想
物以类聚,人以群分
两个思考角度:
1)与你喜好类似的 人 喜欢的东西 可能你也喜欢 ——user-based CF
2)跟你喜欢的 东西 相似的东西 可能你也喜欢 ——item-based CF
后续章节默认围绕user-based CF进行讲解,最后章节会简单介绍item-based CF计算过程
名词释义
协同:协, 众之同和也。同, 合会也——《说文》,协调两个或者两个以上的不同资源或者个体,协同一致地完成某一目标的过程或能力。
协同过滤:将许多用户和物品的相关信息汇集到一起,找出相同或相似的喜好物品,将他们从这个大集合中过滤出来。——个人解释
二、基于协同过滤算法的推荐流程

2.1 数据收集&整合
使用该算法的前提是经历过基础数据的收集沉淀,协同过滤算法主要使用的数据是用户对商品的交互信息,如购买、评分等可被量化的信息。
购买行为,如购买过商品A记为1,未购买过商品A记为0
评分行为,如每个用户对商品A的独立评分
按照评分行为,最高评分为5分,我们按照不同用户和不同商品构建透视图表——也叫矩阵:<举例商品粒度较粗>
| 口红 | 香水 | 粉底 | 眼霜 | 面霜 | 洗发水 | 洗面奶 | 护发素 | |
| 小明 | 4 | 5 | 4 | 5 | ||||
| 小熊 | 5 | 3 | 4 | 2 | 4 | |||
| 小璇 | 1 | 2 | 3 | 3 | 4 | |||
| 小代 | 4 | 2 | 3 | 4 | 2 | |||
| 小丽 | 1 | 1 | 2 | 1 | 1 |
透视图1
空格代表未做评分。
2.2 相似度计算
协同过滤的核心就在于相似度计算,协同过滤常用的相似度计算方法有有三种:余弦相似度、皮尔逊相关系数、杰卡德相似系数。在实际模型训练过程中只选择适用的一种即可。
2.2.1 余弦相似度
余弦相似度的计算公式如下:
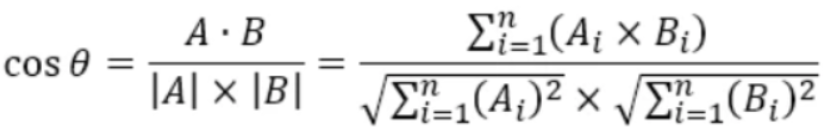
从数学上看,余弦相似度衡量的是投射到一个多维空间中的两个向量之间的夹角的余弦,
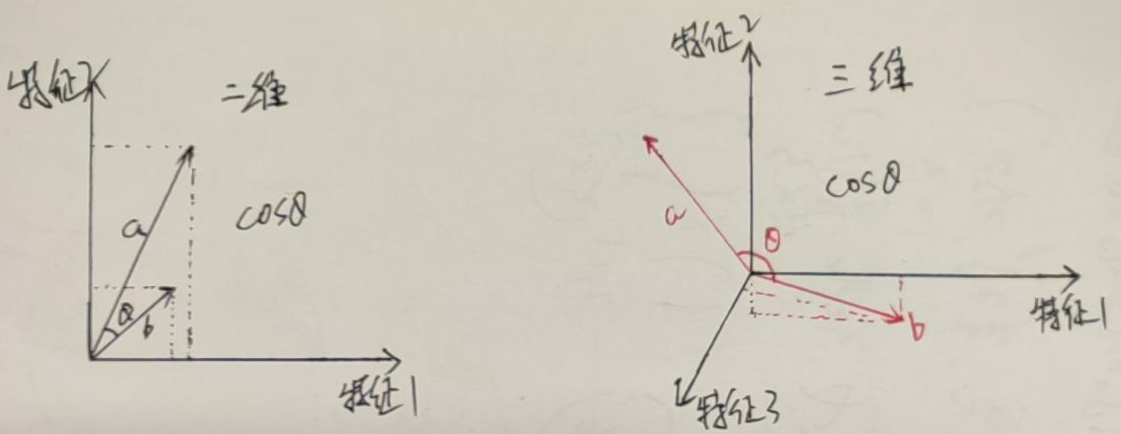
夹角越小,两个两个向量就越相似(相关),夹角越大两个向量就越不相似(不相关):cos0 正相关,cos180负相关。我们再一起重温下初中几何,

user-based CF 使用的的维度就是透视图中各个商品,值就是各个评分项。举例,对于小明和小璇我们有以下向量
\overrightarrow{小明}(None,None,4,None,None,5,4, 5)
\overrightarrow{小璇}(None,1, 2, 3, None,3,None,4)
在计算两个用户相似度时,选择两个向量都存在值的列值作为相似度计算向量,从而有向量
\overrightarrow{小明}(4,5,5)
\overrightarrow{小璇}(2,3,4)
按照余弦计算的公式计算小明和小璇的用户相似度为:
cos\theta=\frac{4*2+5*3+5*4}{\sqrt{4^2+5^2+5^2}*\sqrt{2^2+3^2+4^2}}=\frac{43}{\sqrt{66}*\sqrt{29}}\approx0.98287
故从余弦相似度计算原理来说,小明和小璇两个用户是几乎呈现正相关的。于是后面的推荐就可以使用小璇评分高的商品推荐给小明。
2.2.2 皮尔逊相关系数
公式如下,
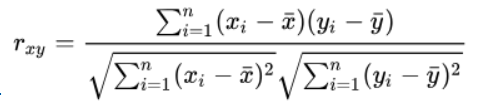
皮尔逊相关系数也是一种余弦相似度计算方式,考虑了向量的长度对评分的影响,从而能够反映出用户的喜好。
我们来看小熊和小丽,按照余弦相似度取计算向量的方式有向量,
\overrightarrow{小熊}(5,3,4,2)
\overrightarrow{小丽}(1,1,2,1)
按照余弦相似度计算,可得出余弦相似度cos\theta\approx0.92582,两个用户是很相似的。然后我们从用户评分视角来分析下,评分区间1~5分,小丽的评分普遍较低,说明小丽对口红、香水、粉底、面霜都不喜欢,而小熊对口红、香水、粉底的评分较高,说明还是很喜欢的,从这种直观性来看,两个用户应该是不相关的。显然余弦相似度在这种情况下得出的结果是与我们预期不相符的。
从业务角度看,皮尔逊相关系数极大消除了个人评分差异化的因素。每个人对同一商品的评分存在差异,每个用户自己心中的都有一个评价基准值,高于该值的代表用户很喜欢该商品,低于该值的代表用户不大喜欢该商品,现象就是有些用户评分普遍高,有些用户评分普遍低。皮尔逊相关系数公式的做法是做中心化,对每个用户的评分取平均分,即定位每个用户的评价基准值,然后每个商品的评分减去该平均值,负数表示不喜欢,正数表示喜欢,值的大小表示用户喜恶程度。
我们一起计算下皮尔逊相关系数,
cos\theta=\frac{(5-3.5)*(1-1.25)+(3-3.5)*(1-1.25)+(4-3.5)*(2-1.25)+(2-3.5)*(1-1.25)}{\sqrt{(5-3.5)^2+(3-3.5)^2+(4-3.5)^2+(2-3.5)^2} * \sqrt{(1-1.25)^2+(1-1.25)^2+(2-1.25)^2+(1-1.25)^2}}=\frac{0.5}{\sqrt{5}*\sqrt{0.75}}\approx0.25819
可以看到,皮尔逊相关系数的计算结果与我们的前期分析基本一致。
2.2.3 杰卡德相关系数
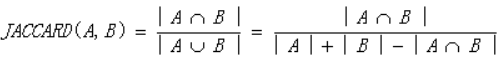
分子两个向量的点乘积,分母是两个向量或运算后求和
只适用于0,1矩阵的相似度计算,面向只有是否概念的场景。
2.3 推荐商品过滤
与小明相似的用户找出来了,实际情况是广告位有限,很难将这么多相似物品一股脑曝光给用户,那这么多商品全部哪个应该排在前面哪个排在后面推荐给小明呢?我们还需要预估小明对这些未评价过的商品的评分,对这些评分我们再做一次排序,这样商品推荐的顺序就有了。我们先将透视图1中数据用户的皮尔逊相关性全部计算出来,有如下透视图:
| 用户 | 小丽 | 小代 | 小明 | 小熊 | 小璇 |
| 小丽 | 1 | 0.866025 | NaN | 0.258199 | 0 |
| 小代 | 0.866025 | 1 | 0.5 | 0 | -0.5 |
| 小明 | NaN | 0.5 | 1 | NaN | 0.866025 |
| 小熊 | 0.258199 | 0 | NaN | 1 | 1 |
| 小璇 | 0 | -0.5 | 0.866025 | 1 | 1 |
透视图2
小明和小璇相似程度较高,小璇还评价过香水和眼霜,如何推算出小明对这两个物品的评分呢?这里使用到加权平均法,公式如下,

R_{u,p}表示推断的用户u对商品p的评价分,W_{u,s}表示两个用户的相似度,R_{s,p}表示用户s对p商品的评价分,
另外如果用户s无对商品p的评分,则其不参与到此公式的计算。
在实际计算中我们还需要确定集合S的范围,即我们需要用到多少个和小明相似的用户信息作为推荐给小明商品的基础数据集。为方便计算,此处我们暂定为使用1个相似用户作为基础数据集,透视图2中可知小璇和小明最相似。可对小明推荐商品香水和眼霜的估分情况如下:
R_{小明,香水}=\frac{0.866025*1}{0.866025}=1
R_{小明,眼霜}=\frac{0.866025*3}{0.866025}=3
从结果看,好像感觉有问题,推算的结果与小璇的评分是一致的,部分原因是因为我们只使用 了1一个相似用户数据集原因,还有一点结合前面讲到的是未考虑到个性化评分差异。我们使用去中心化的思想,有如下公式,
R_{u,p}=\overline{R_u}+\frac{\Sigma_{\in S}(w_{u,s}*(R_{s,p}-\overline{R_s}))}{\Sigma_{\in S}w_{u,s}}
再次计算小明推荐商品香水和眼霜的估分情况如下:
\overrightarrow{小明}(4,5,5) \overline{R_{小明}}=\frac{4+5+5}{3}\approx4.667
\overrightarrow{小璇}(2,3,4) \overline{R_{小璇}}=\frac{2+3+4}{3}=3
R_{小明,香水}=4.667+\frac{0.866025*(1-3)}{0.866025}=4.667-2\approx2.667
R_{小明,眼霜}=4.667+\frac{0.866025*(3-3)}{0.866025}\approx4.667
两种计算方式都可给出正确排序,优先推荐给小明眼霜。两种算法在实践中大家根据实际情况使用即可。
实际情况中,小明自身评价高的商品也需要根据业务情况考虑是否需要纳入推荐列表中。
到这里协同过滤算法的整体过程就结束了。
三、推荐系统效果评价
召回率,也叫查全率
一个投放周期T中,Recall Rate=\frac{预测正确的个数}{用户实际操作的个数}
准确率,也叫查准率
一个投放周期T中,Precision=\frac{预测正确的个数}{预测用户会操作的个数}
覆盖率
一个投放周期中,Coverage=\frac{所有用户推荐集并集去重的物品数量}{物品总数量}
覆盖率只说明了有多少物品被推荐了,并不能展示出被推荐的次数。
流行度
后续补充。略。
名词解释
操作:可以是点击、购买、评价等;
预测正确:整个测试周期中,预测出来用户会购买某商品,验证时用户确实购买了该商品;
用户实际操作:如在整个测试周期中用户购买了商品
四、总结
问题1:数据稀疏,泛化能力弱
实际情况中,商品数量或用户数量是很庞大的,从而生成的矩阵数据容易为稀疏矩阵,这样热门商品容易产生头部效应而与很多其他商品产生相似性,而尾部商品因矩阵稀疏而很少会被推荐,同样活跃用户也会产生相同影响。对应的业界对协同过滤相似度计算有对热门商品惩罚、对活跃用户惩罚。
问题2:冷启动问题
协同过滤适用于留存用户推荐,新用户需要经过冷启动周期完成数据收集。
优点1:简单高效
简单高效,使用极少的特征即可完成推荐功能,只使用到用户与物品的交互信息。
互联网营销一直在向精准化前进,用户行为信息、物品信息其实是很丰富的,协同过滤算法未充分利用这些有效信息,在精准化营销场景下很多推荐系统采用了逻辑回归模型。
基于用户和基于物品的CF对比

五、item-based CF计算简要说明
基于用户的CF计算使用的是透视图1中的行向量,基于物品的CF计算使用的则是透视图中的列向量,
对于口红、香水、粉底分别由如下向量:
\overrightarrow{口红}=(None,5,None,None,1)
\overrightarrow{香水}=(None,3,1,None,1)
\overrightarrow{粉底}=(4,4,2,4,2)
相似度计算公式不变,预估评分计算公式也不变。