推荐系统概念相关
维基百科定义:
推荐系统是一种信息过滤系统,用于预测用户对物品的“评分”或“偏好”。
推荐系统近年来非常流行,应用于各行各业。推荐的对象包括:电影、音乐、新闻、书籍、学术论文、搜索查询、分众分类、以及其他产品。也有一些推荐系统专门为寻找专家、合作者、笑话、餐厅、美食、金融服务、生命保险、网络交友,以及Twitter页面设计。
通俗定义
推荐系统可以把那些最终会在用户(User)和物品(Item)之间产生的连接提前找出来。
常见的有
1,社交产品,从已知的用户好友关系,帮助推荐感兴趣的人,可能认识的人。
2,资讯阅读产品,根据用户过去都点击阅读了哪些内容,以及停留时间等操作,来推荐感兴趣的内容
3,电商平台,用户刚买过什么,常买什么,你正在浏览什么,这些都是用户和物品之间已经存在的连接,用这些连接去预测还会买什么,还会看什么也是推荐系统。
推荐系统分类
根据推荐算法所用数据的不同分为基于内容的推荐、协同过滤的推荐以及混合的推荐
基于内容的推荐
基于内容推荐利用一些列有关物品的离散特征,推荐出具有类似性质的相似物品
通过算法将“标的物”与人关联起来,“标的物”包含很多自己的属性,用户通过与“标的物”的交互会产生行为日志,这些行为日志可以作为衡量用户对“标的物”偏好的标签,通过这些偏好标签为用户做推荐就是基于内容的推荐算法。比如:你在抖音中观看的感兴趣的视频,有各自的标签,通过系统推荐,下次打开时候,会主动给你推送你感兴趣的视频。
协同过滤的推荐
协同过滤方法根据用户历史行为(例如其购买的、选择的、评价过的物品等)结合其他用户的相似决策建立模型。这种模型可用于预测用户对哪些物品可能感兴趣(或用户对物品的感兴趣程度)
用户在产品上的交互行为为用户留下了标记,我们可以利用“物以类聚,人以群分”的朴素思想来为用户提供个性化推荐。一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐,通常需要用到UI矩阵的信息。
基于混合的推荐
对以上算法的融合,既有基于内容的推荐也有协同过滤的推荐。
内容推荐方法
基于内容的推荐向用户根据用户喜爱物品的直接推荐物品。
内容表示物品的描述。一般是自动从文档或无结构的文本描述中获得。因为在实际环境中对物品的专业描述需要专业人员的人工标注,这个费用是高昂的。
内容表示:物品的内容表示一般是维护每个物品特征的详细列表,例如属性集、特征集、物品记录。
基于内容的推荐的工作原理一般是评估用户还没看到的物品与当前用户过去喜欢的物品的相似程度。用到的典型的相似度方法是Dice系数,每物品Bi由一组关键词keyword(Bi)描述,Dice计算物品bi与bj之间的相似度:
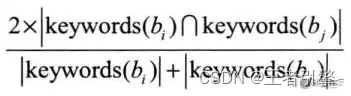
基于内容的推荐一般使用出现在文档中的相关关键词,用不同的方法转换文档内容到关键词列表中。
简单的布尔型方法:
文档所有词语为一个列表,1表示出现,0表示没有出现,这种方法词语在文档中的重要性相等。
TF-IDF转换形式
TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)
TF
就是词频,在要提取关键词的文本中出现的次数
计算公式
TF = 某个词在文章中出现的次数/文章的总次数
TF = 某个词在文章中出现的次数/该文出现的最多的词的次数
IDF
是提前统计好的,在已有的所有文本中,统计每一个词出现在了多少文本中,记为 n,也就是文档频率,一共有多少文本,记为 N。
计算公式
IDF = log(N/(n+1))
TF-IDF
计算出 TF 和 IDF 后,将两个值相乘,就得到每一个词的权重
TF-IDF = TF * IDF
筛选方式
根据该权重筛选关键词的方式有
1)TOP N的方式
2)大于平均值
3)对一些关键词过滤,例如只保留名词或者动词等操作
相关开源 sklearn TfidfVectorizer
TextRank
算法的基本思想是将文档看作一个词的网络,该网络中的链接表示词与词之间的语义关系
- 文本中,设定一个窗口宽度,比如 K
个词,统计窗口内的词和词的共现关系,将其看成无向图。图就是网络,由存在连接关系的节点构成,所谓无向图,就是节点之间的连接关系不考虑从谁出发,有关系就对了; - 所有词初始化的重要性都是 1;
- 每个节点把自己的权重平均分配给“和自己有连接“的其他节点;
- 每个节点将所有其他节点分给自己的权重求和,作为自己的新权重;
- 如此反复迭代第 3、4 两步,直到所有的节点权重收敛为止。
通过 TextRank 计算后的词语权重,呈现出这样的特点:
那些有共现关系的会互相支持对方成为关键词。
相关开源 https://gitee.com/mirrors_summanlp/textrank
中文分词组件jieba
jieba,做最好的Python中文分词组件
支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率
- 适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
相关开源 jieba
TextRank4ZH
To Be Continue
内容分类
聚类
词嵌入

![[附源码]计算机毕业设计作业查重系统Springboot程序](https://img-blog.csdnimg.cn/98bc29e21f054cd29bca364219a62894.png)
![[附源码]计算机毕业设计疫情管理系统Springboot程序](https://img-blog.csdnimg.cn/5234ddc39451428784c56643753dd004.png)










![[附源码]JAVA毕业设计红河旅游信息服务系统(系统+LW)](https://img-blog.csdnimg.cn/448c509d6ff64e43971797096602dd0b.png)
![[附源码]计算机毕业设计springboot项目管理系统的专家评审模块](https://img-blog.csdnimg.cn/2c7ea07d496e4508a1f1a3f6a24a8e04.png)