文章目录
- 前言
- 一、背景
- 二、总体流程
- 三、构建知识库
- 四、粗排
- 五、精排
- 六、Prompt
- 总结
- 相关博客
前言
先看结果:
已经连续很多周获得了第二名(万年老二), 上周终于拿了一回第一, 希望继续保持. 😁
这是今天的榜单, 采纳的数量相对较少, 之前基本上维持在100+
重点说明一下, 第二名是一名20年+经验的程序员, 第四名是ChatGPT的使用者.
整体来说还是非常不错的, 超越了99%的人类, 争取做到100%😁
断断续续优化了一年才达到今天的效果, 从git日志来看是13个月前开始做的, 不容易啊
一、背景
1、降低用户重复提问率
2、提高问题的响应速度
3、减少无人回答的问题
总的来说, 都是为了提升用户体验, 做一个能够帮助解决实际问题的AI机器人
二、总体流程

在ChatGPT出来之前, 是没有prompt和之后的流程的, 也就是: 构建知识库 > 粗排 > 精排
三、构建知识库
知识库的数据来源:
- 已采纳的问题: 376140
- 编程语言的官方手册: 67015
- 高质量的博客: 4779402
- 技能树习题
- 学院的课程: 75302
4和5都是后面加的, 主要是为了推广技能树和课程, 主要的知识库来自1、2、3.
目前的数据是这些, 已经加了定时更新机制, 每月一号自动增量更新知识库
这里的477w博客, 是没有做结构化的量, 做完结构化后的量是12959544, 将近1300w的数据量了, 这么大的数据量, 如何存呢?
我知道你很急, 但你先别急, 听我娓娓道来!
结构化: 将博客按内容中的小标题拆分开
使用PostgresSQL存储知识库
表的整体结构
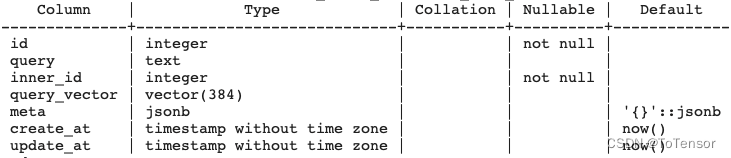
字段说明:
id: 博客id
query: 博客标题
inner_id: 小标题序号
query_vector: 目标query的向量, 这里是 query+head_title 的向量化后的结果
meta: 主要用于存储小标题及小标题之间的内容
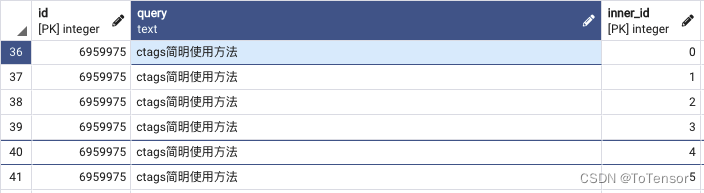
我随机取的一条拆分后的博客的数据, 这是其中一个meta字段
{
"url": "博客链接",
"tags": "debian,linux,ubuntu,vim,编辑器",
"content": "xxxxxxxxx",
"head_title": "安装ctags"
}
字段说明:
tags: 博客标签
content: 小标题与小标题之间的内容
head_title: 小标题
怕大家不理解, 我又截了个图
SQL大佬也许已经看出了端倪, 这里面存了好多重复数据, 理论上应该拆分出几个关联表来存的
确实, 说的很对, 当时有想过这个问题, 在众多因素之下, 就成了现在这样了, 大家可别像我一样
四、粗排
数据我们存起来了, 如何做粗排呢?
首先, 我们需要将我们的博客数据向量化, 上面的query_vector字段, 就是用来存储我们向量化后的数据的.
我们可以利用一些预训练的句向量模型, 来将我们的博客数据向量化, 我分为两部分来介绍:
- 构建训练数据
- 训练模型
在构建训练数据之前, 我想带大家看一下huggingface上的一些预训练句向量模型的效果.
我们拿月下载量最多的一个SBERT模型来试试, 链接: sentence-transformers/all-MiniLM-L6-v2

效果非常不错啊, 那还微调个啥, 直接拿来用呗
别急, 多测几个用例试试:
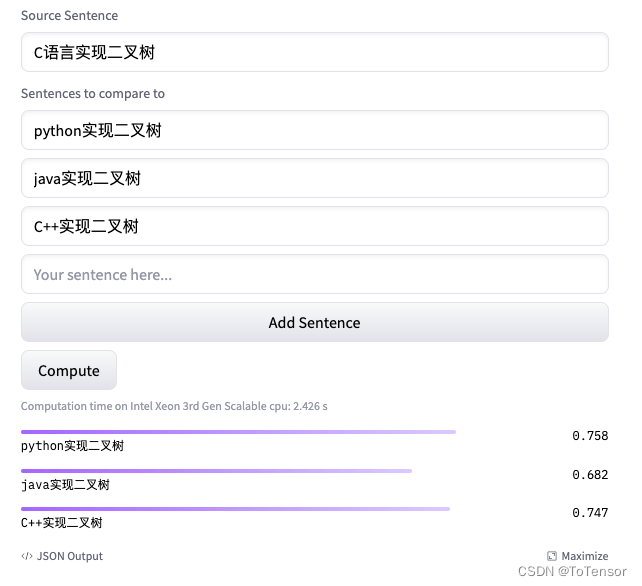
相似度有点大, 理想的情况, 这种案例的相似度应该在0.5以下, 如果用户要的是C语言答案, 我们的机器人返回的却是Java的结果, 对用户来说, 用处不大.
因此, 我们需要基于该预训练模型用我们自己标注好的数据微调.
那么问题来了, 如何标注数据?
- 人工标注, 构造: [query, query, label]元组
- 利用模型粗筛, 再人工标注
相信一个合格的NLPer都会选择2, 原因如下:
- 人工标注构造正例对非常困难, 例如, 我的数据是1w, 假如有一个query A, 需要你标注出与query A相似的句子B, 你需要遍历一遍数据后才知道哪些是相似的
- 人工标注周期长, 等你标完, 都猴年马月了
如何利用模型粗筛一遍数据
1、使用一些传统的相似度计算方法(如LCS), 将数据库中的博客标题, 两两计算相似度, 筛选出相似度比较高的数据, 组成 [query, query] 对
2、训练一个无监督的语义相似度模型(如SimCSE), 使用该模型来两两计算相似度, 筛选相似度比较高的数据
在CSDN问答机器人中, 两种方法我都试过, 最后选择了2, 因为方法一计算出来的阈值, 往往偏向文本相似, 很难挖掘出我们需要高度关注的数据, 也就是上面所举的例子:
python实现二叉树
C语言实现二叉树
这种类型的数据, 通过方法1比较难以控制阈值.
模型的训练过程我就不说了, 这里我直接给大家展示一下通过SimCSE计算相似度后的数据
TypeScript生成随机数 jmeter随机数生成 0.89
TypeScript生成随机数 kotlin 生成随机数 0.88
TypeScript生成随机数 Javascript生成随机数 0.88
TypeScript生成随机数 ThreadLocalRandom生成随机数 0.88
TypeScript生成随机数 Java生成随机数SecureRandom 0.86
TypeScript生成随机数 wincc随机数的生成 0.86
TypeScript生成随机数 pytorch生成随机数 0.86
TypeScript生成随机数 golang生成随机数 0.86
TypeScript生成随机数 MATLAB 生成随机数 0.86
TypeScript生成随机数 MATLAB生成随机数 0.86
TypeScript生成随机数 Python 随机数生成 0.86
TypeScript生成随机数 python 随机数生成 0.86
TypeScript生成随机数 c#Random类生成随机数 0.85
TypeScript生成随机数 android 生成随机数 0.85
TypeScript生成随机数 Android 生成随机数 0.85
TypeScript生成随机数 随机数生成器python 0.84
TypeScript生成随机数 Swift - 随机数生成 0.84
TypeScript生成随机数 Clickhouse 生成随机数据 0.83
TypeScript生成随机数 pytorch | 生成随机数 0.82
相似度阈值设定在0.9, 筛选出来的数据:
python中分割字符串 python字符串分割
python中分割字符串 oracle分割字符串
python中分割字符串 将String字符串分割
python中分割字符串 boost 分割字符串
python中分割字符串 Arduino分割字符串
python中分割字符串 Linux Shell 分割字符串
python中分割字符串 boost 拆分字符串
python中分割字符串 sscanf分割字符串
python中分割字符串 leetcode 分割字符串
python中分割字符串 golang:字符串分割
python中分割字符串 基于Oracle的字符串分割
python中分割字符串 SQL中按分隔符拆分字符串
python中分割字符串 C++ string字符串分割
python中分割字符串 C++ string 字符串的分割
python中分割字符串 python多空格字符串分割
可以看出, 这些筛选出来的数据, 就是我们所关心的部分文本相同, 但语义完全不同的数据.
最后, 再人工标注一部分数据, 标注的数据如下:
利用python发送qq邮件 使用python发送qq邮件 1
利用python发送qq邮件 使用java发送qq邮件 0
利用python发送qq邮件 用Java发送QQ邮件 0
利用python发送qq邮件 使用python发送邮件 1
利用python发送qq邮件 C#利用QQ信箱发送EMAIL 0
利用python发送qq邮件 使用python发邮件 1
利用python发送qq邮件 用Python发送邮件 1
利用python发送qq邮件 Java使用QQ邮箱发送邮件 0
利用python发送qq邮件 python使用gmail发送邮件 0
利用python发送qq邮件 python发送QQ邮件 1
利用python发送qq邮件 PHP使用QQ邮箱发送邮件 0
利用python发送qq邮件 python 利用zmail库发送邮件 1
利用python发送qq邮件 利用Foxmail发送邮件 0
利用python发送qq邮件 python使用SMTP发送邮件 1
利用python发送qq邮件 用Python通过163邮箱发送邮件 0
利用python发送qq邮件 "Simple Java Mail的使用,发送qq邮件" 0
利用python发送qq邮件 Java实现利用QQ邮箱发送邮件 0
利用python发送qq邮件 使用Smtp来发送邮件 1
这里面存在一个包含关系, 当某个技术词里面包括了另一个词时, 我们认为是相似的, 如:
利用python发送qq邮件
python 利用zmail库发送邮件
使用zmail库可以发送163邮件、qq邮件、google邮件等
至此, 我们便有了高质量的有监督数据.
下一步, 就是微调SBERT模型了, 这里直接贴代码吧, 没什么难度, sentence_transformers库封装得太好了
import os
from sentence_transformers import SentenceTransformer, SentencesDataset
from sentence_transformers import InputExample, evaluation, losses
from torch.utils.data import DataLoader
class TrainSBert:
def __init__(self, config, options):
self.model_name="sentence-transformers/all-MiniLM-L6-v2"
self.data_path = "自己的标注数据路径"
self.model = None
self.model_base_dir = '模型保存base路径'
self.model_dir = os.path.join(self.model_base_dir, self.model_name.split("/")[-1])
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
self.evaluate_path = os.path.join(self.model_dir, "result.txt")
def load(self):
self.model = SentenceTransformer(self.model_name)
def load_train_data(self):
file_handle = open(self.data_path, 'r')
train_data_list = []
dev_sentences1, dev_sentences2, dev_labels = [], [], []
count = 0
for line in file_handle:
item_list = line.strip().split("\t")
sa = item_list[0]
sb = item_list[1]
label = float(item_list[2])
count += 1
if count <= 5000:
dn = InputExample(texts=[sa, sb], label=label)
train_data_list.append(dn)
else:
dev_sentences1.append(sa)
dev_sentences2.append(sb)
dev_labels.append(label)
train_dataset = SentencesDataset(train_data_list, self.model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=32)
return train_dataloader, dev_sentences1, dev_sentences2, dev_labels
def train(self):
self.load()
train_dataloader, dev_sentences1, dev_sentences2, dev_labels = self.load_train_data()
train_loss = losses.CosineSimilarityLoss(self.model)
evaluator = evaluation.EmbeddingSimilarityEvaluator(dev_sentences1, dev_sentences2, dev_labels)
self.model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=10, warmup_steps=100,
evaluator=evaluator, evaluation_steps=100, output_path= self.model_dir)
self.model.evaluate(evaluator, self.evaluate_path)
没几行代码, 训练完成后, 我们来看看效果:
s1: 二叉树的python实现 与 s2: Ribbon实现负载均衡 相似度为: 0.18773505091667175
s1: 二叉树的python实现 与 s2: 使用openFeign实现负载均衡 相似度为: -0.04088197648525238
s1: 二叉树的python实现 与 s2: Nginx负载均衡实现 相似度为: 0.018543850630521774
s1: 二叉树的python实现 与 s2: python 的二叉树实现 相似度为: 0.965272068977356
s1: 二叉树的python实现 与 s2: 请问下二叉树用python怎么实现, 求求各位大佬了, 小弟实在不会 相似度为: 0.8639361262321472
s1: 二叉树的python实现 与 s2: 二叉树的python实现 相似度为: 1.0
s1: 二叉树的python实现 与 s2: 二叉树的c++实现 相似度为: 0.21337147057056427
这效果, 绝了!
接着, 我们用微调好的SBERT, 将知识库向量化后, 存到PG数据库中, 也就是query_vector字段的部分.
pgvector的官方仓库: https://github.com/pgvector/pgvector
milvus、hnswlib、faiss等都可以实现向量的存储, 这一块的工具还是挺多的, 主要是索引的构建方式不同, 感兴趣的可以去了解一下
这里要说明一下, 在meta里面的tags字段, 存的是博客标签, 这样做的好处:
1、加速召回
2、在一定程度上提高召回准确率
原因: 通过传入博客标签, 我们将query库从全量数据缩小到单个标签的数据, 数据量减少, 速度当然变快, 准确率也有一定提升.
取召回后的top5结果:
query: android jar包转dex文件
召回数据0: android jar包转dex文件
召回数据1: android jar包免费下载
召回数据2: android jar包下载地址
召回数据3: Android Jar包冲突及解决方法
召回数据4: android 反编译jar包
至此, 粗排的部分我们就完成了
五、精排
精排这部分, 其实就是人工构造特征, 作为LTR模型的输入, 在这里, 我构造了以下特征:
1、SBERT语义相似度
2、最长公共子序列
3、编辑距离
4、jaccard相似度
5、余弦相似度
6、皮尔逊相关性系数
7、欧式距离
8、KL散度
大家可以适当删减, 因为有些相似度的计算方法是类似的
def jaccard_sim(self, str_a, str_b):
seta = set(self.segment.segment(str_a))
setb = set(self.segment.segment(str_b))
sa_sb = 1.0 * len(seta & setb) / len(seta | setb)
return sa_sb
def cos_sim(self, a, b):
a = np.array(a)
b = np.array(b)
return np.sum(a * b) / (np.sqrt(np.sum(a**2)) * np.sqrt(np.sum(b**2)))
def eucl_sim(self, a, b):
a = np.array(a)
b = np.array(b)
return 1 / (1 + np.sqrt((np.sum(a - b) ** 2)))
def pearson_sim(self, a, b):
a = np.array(a)
b = np.array(b)
a = a - np.average(a)
b = b - np.average(b)
return np.sum(a * b) / (np.sqrt(np.sum(a**2)) * np.sqrt(np.sum(b**2)))
def kl_divergence(self, p, q):
return scipy.stats.entropy(q, p)
训练数据还是我们用来微调SBERT的那部分有监督数据
LTR模型使用的是lightgbm的LGBMRanker, 文档请看: LGBMRanker
不得不说, 参数是真的多, 我使用的参数:
params = {
"boosting_type": "gbdt",
"max_depth": 5,
"objective": "binary",
"num_leaves": 64,
"learning_rate": 0.05,
"max_bin": 512,
"subsample_for_bin": 200,
"subsample": 0.5,
"subsample_freq": 5,
"colsample_bytree": 0.8,
"reg_alpha": 5,
"reg_lambda": 10,
"min_split_gain": 0.5,
"min_child_weight": 1,
"min_child_samples": 5,
"scale_pos_weight": 1,
"group": "name:groupId",
"metric": "auc",
}
具体参数的含义及作用, 还是查看官方文档吧.
六、Prompt
我使用的prompt:
假如你是一名资深的IT专家, 请你结合以下参考资料和你现有的知识回答以下问题, 尽量给出具体的解决方案, 请将每一步都以清晰易懂的语言告诉我, 请尽可能地展示代码, 如果你没有把握解决该问题, 只需要回答: 我无法解决该问题, 请不要试图编造假的答案来忽悠我, 答案用markdown格式返回, 以下是问题和参考资料:
问题:
{query}
参考资料:
{blog_content}
改prompt确实是门玄学, 多用Chatgpt, 调起来就没那么难, 据说以后会不需要自己调prompt, 由模型自己来完成, 当然这也是趋势
整体来说, 跟ChatPDF的原理类似, 都是匹配相关性文档, 然后再让Chatgpt总结答案
总结
1、重点部分是SBERT训练数据集的构建
2、可能的优化方向:
- 结构化博客的方法更加合理
- 增加
SBERT微调数据集 - 精排模型的优化
- 用
ChatGPT的Embedding接口来替代自己的句向量模型
3、项目的代码不方便开源, 涉及到的东西太多了, 大家有任何问题, 可以在评论区留言
相关博客
- 基于Sentence-Bert的检索式问答系统
- FAQ式问答系统
有帮助的话, 一键三连吧, 跪谢