一、目标跟踪
目标跟踪是计算机视觉领域研究的一个热点问题,其利用视频或图像序列的上下文信息,对目标的外观和运动信息进行建模,从而对目标运动状态进行预测并标定目标的位置。具体而言,视觉目标(单目标)跟踪任务就是在给定某视频序列初始帧的目标大小与位置的情况下,预测后续帧中该目标的大小与位置。
目标跟踪算法从构建模型的角度可以分为生成式(generative)模型和判别式(discrimination)模型两类;从跟踪目标数量可分为单目标跟踪和多目标跟踪。目标跟踪融合了图像处理、机器学习、最优化等多个领域的理论和算法,是完成更高层级的图像理解( 如目标行为识别) 任务的前提和基础。
二、孪生网络
孪生神经网络是一种包含两个或多个相同子结构的神经网络架构,各子网络共享权重。孪生神经网络的目标是通过多层卷积获取特征图后,比较两个对象的相似程度,在人脸认证、手写字体识别等任务中常被使用。其网络结构如下图所示,两个输入分别进入两个神经网络,将输入映射到新的空间,形成输入在新空间中的表示,通过损失的计算,评价两个输入的相似度。
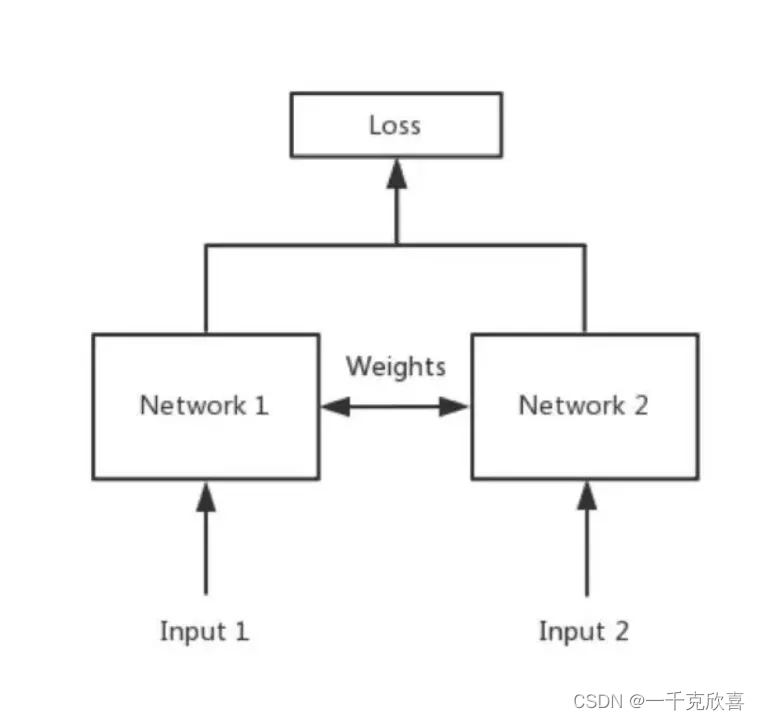
此外,该网络的特点是可以充分利用有限的数据进行训练,这一点对目标跟踪来说至关重要,因为在跟踪时能够提供的训练数据与目标检测相比较少。
若子网络之间不共享权重,则称为伪孪生神经网络。对于伪孪生神经网络,其子网络的结构可以相同,也可不同。与孪生神经网络不同,伪孪生神经网络适用于处理两个输入有一定差别的情况,如验证标题与正文内容是否一致、文字描述与图片内容是否相符等。要根据具体应用进行网络结构的选择。
四、基于孪生网络的目标跟踪、

SiamFC
论文:Fully-Convolutional Siamese Networks for Object Tracking(ECCV 2016)
链接:https://link.springer.com/chapter/10.1007/978-3-319-48881-3_56
方法:
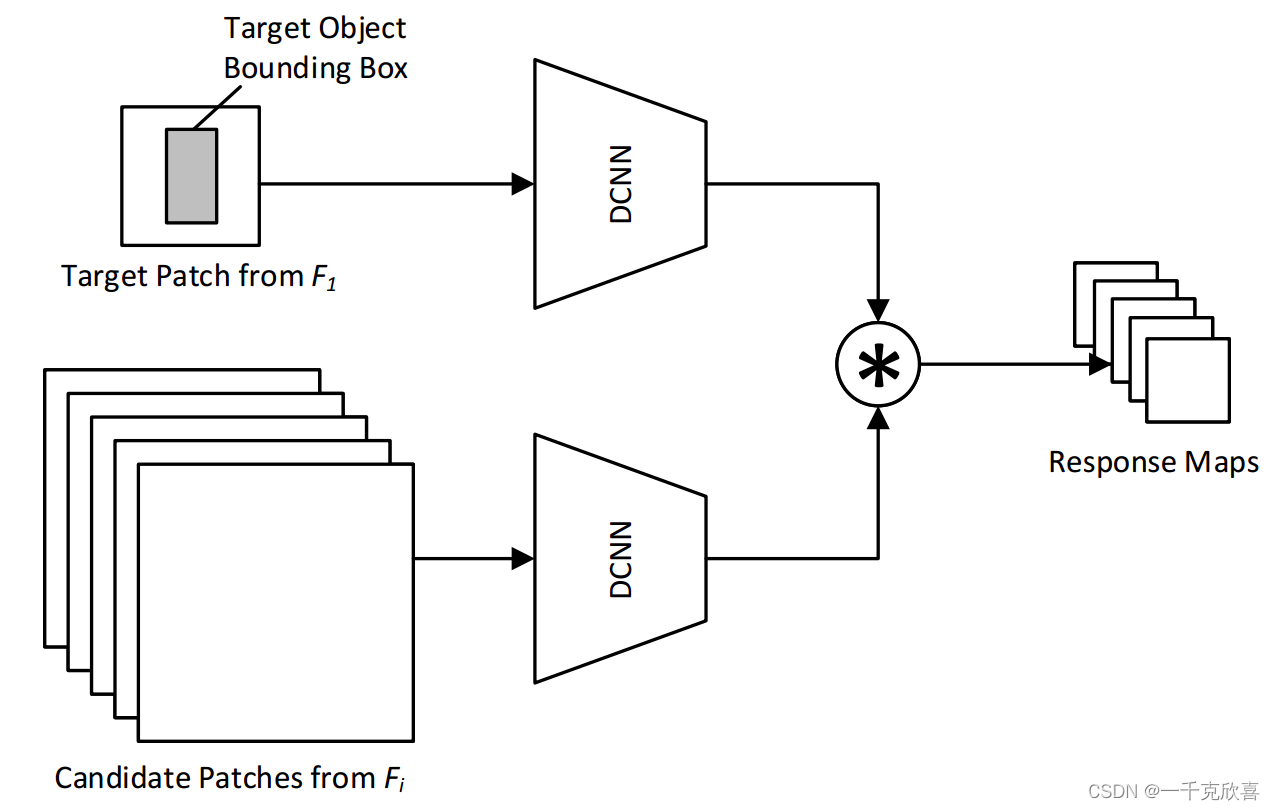
将目标的跟踪方式从在线执行随机梯度下降以适应网络的权重进行跟踪转变为前后帧目标对的形式进行匹配。通过同一网络AlexNet作为backbone,输出模板图像和待查询图像的特征图,并进行互卷积(相关滤波)操作,得到目标响应结果,反向映射到原图,计算当前帧目标位置。
SiamFC-tri
论文:Triplet Loss in Siamese Network for Object Tracking(ECCV 2018)
链接:https://openaccess.thecvf.com/content_ECCV_2018/html/Xingping_Dong_Triplet_Loss_with_ECCV_2018_paper.html
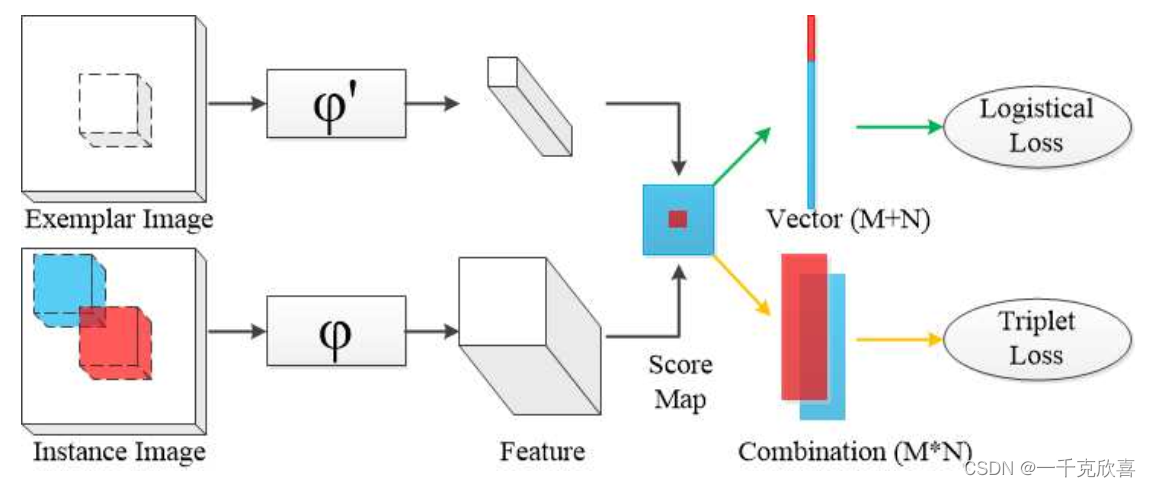
方法:提出了一种新的训练策略,通过训练时在Siamese Network中加入triplet loss提取出目标跟踪的深度表达特征。图中φ \varphiφ表示特征提取网络,当 φ = φ ′ φ=φ ' φ=φ′时,遵循SiamFC范式,当 φ ≠ φ ′ \varphi\neq\varphi^{'} φ=φ′ 时,遵循CFNet范式。
Siam-BM
论文:Towards a Better Match in Siamese Network Based Visual Object Tracker(ECCV 2018 workshop)
链接:https://openaccess.thecvf.com/content_eccv_2018_workshops/w1/html/He_Towards_a_Better_Match_in_Siamese_Network_Based_Visual_Object_ECCVW_2018_paper.html
方法:
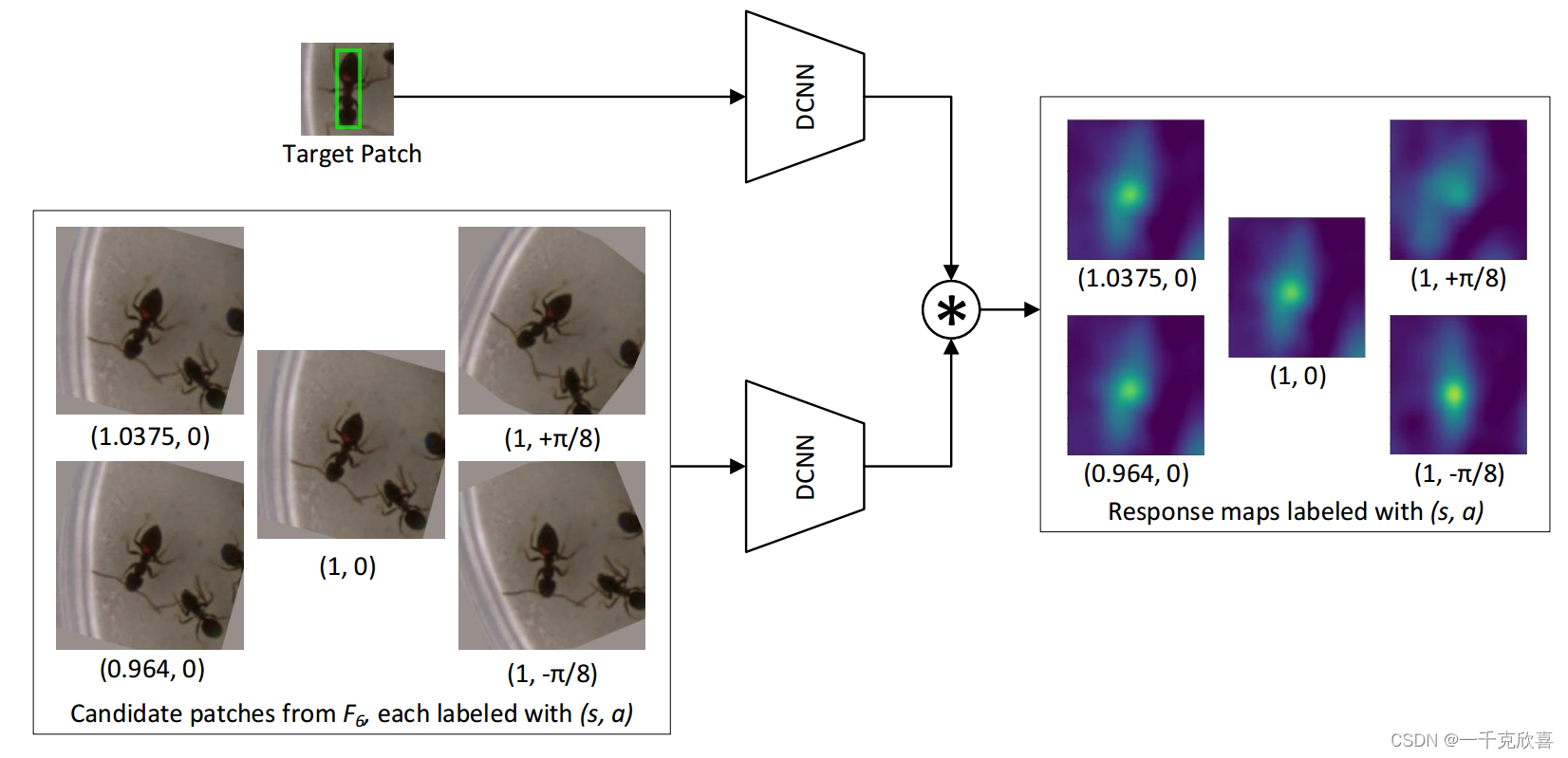
跟踪阶段由于目标会不断变化,网络直接在跟踪阶段自设置不同变换的待跟踪图像。SiamFC在跟踪阶段使用图像金字塔,但仅仅是crop不同大小的图像区域。Siam-BM则在跟踪阶段,不仅是图像金字塔,同时对每层图片加入了旋转操作。让网络在跟踪时更鲁棒。
CFNet
论文:End-to-end representation learning for Correlation Filter based tracking(CVPR 2017)
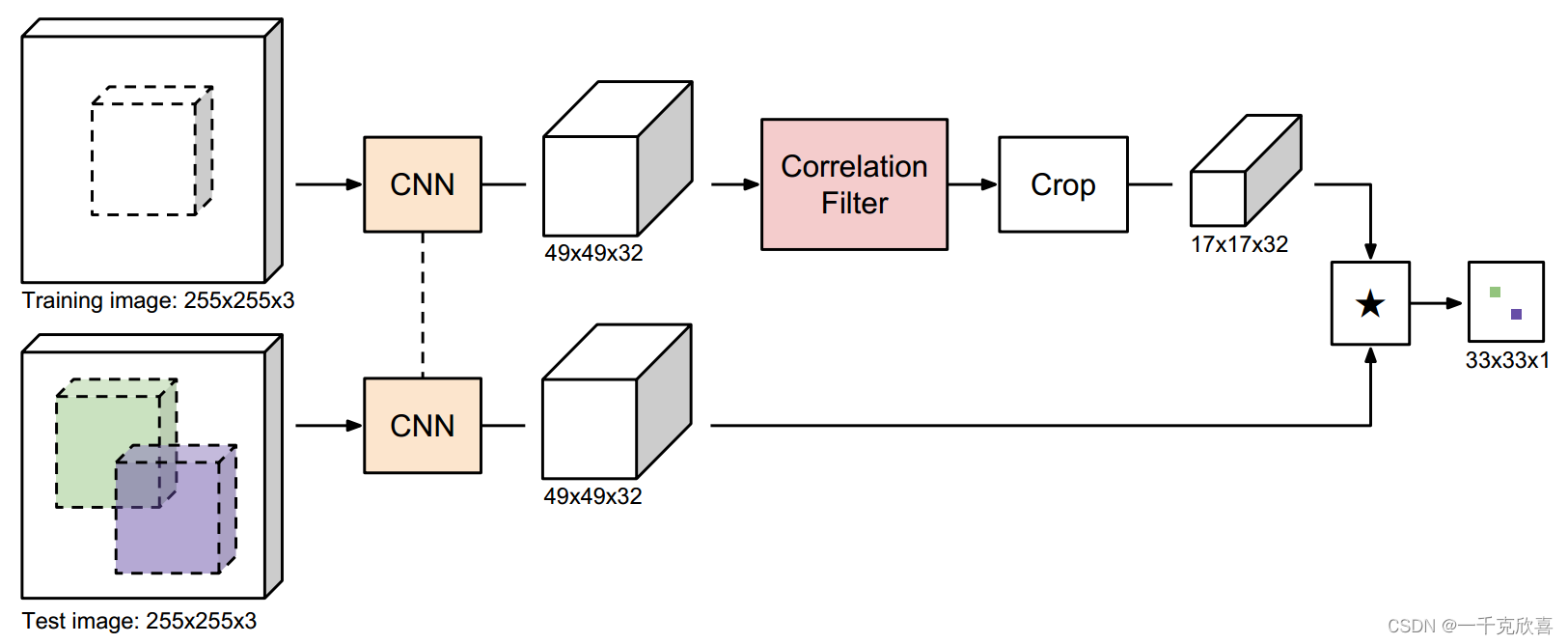
方法:最初的SiamFC只是将每一帧与对象的初始外观进行比较。相比之下,这篇文章在每一帧中计算一个新的模板,然后与之前帧的模板进行融合。
每一帧计算时,SiamFC公式如下:
f ( z , x ) = γ φ ( z ) ∗ φ ( x ) + b 1 {f(z,x)=\gamma\varphi(z)*{\varphi(x)}+b\mathbb{1}} f(z,x)=γφ(z)∗φ(x)+b1
CFNet公式如下:
f ( z , x ) = γ w ( φ ( z ) ) ∗ φ ( x ) + b 1 {f(z,x)=\gamma{w(\varphi(z))*{\varphi(x)}+b\mathbb{1}}} f(z,x)=γw(φ(z))∗φ(x)+b1
CFNet的模板图像输入也是255 *255 *3,这样的话, φ ( z ) \varphi(z) φ(z)和 φ ( x ) \varphi(x) φ(x)的输出特征图都是一样大小,为49*49 *32 。之后利用相关滤波模块(Correlation Filter)CF Block w = w ( x ) w = w ( x ) w=w(x) 提取在每一帧中的模板。输出 ∗ 17 ∗ 32 *17*32 ∗17∗32的模板特征。与待查询图像互卷积。
CFNet和SiamFC一样,有必要引入标量参数 γ \gamma γ和 b b b,使分数范围适合逻辑回归。
RASNet
论文:Learning Attentions: Residual Attentional Siamese Network for High Performance Online Visual Tracking(CVPR 2018)
链接:https://openaccess.thecvf.com/content_cvpr_2018/html/Wang_Learning_Attentions_Residual_CVPR_2018_paper.html
方法:
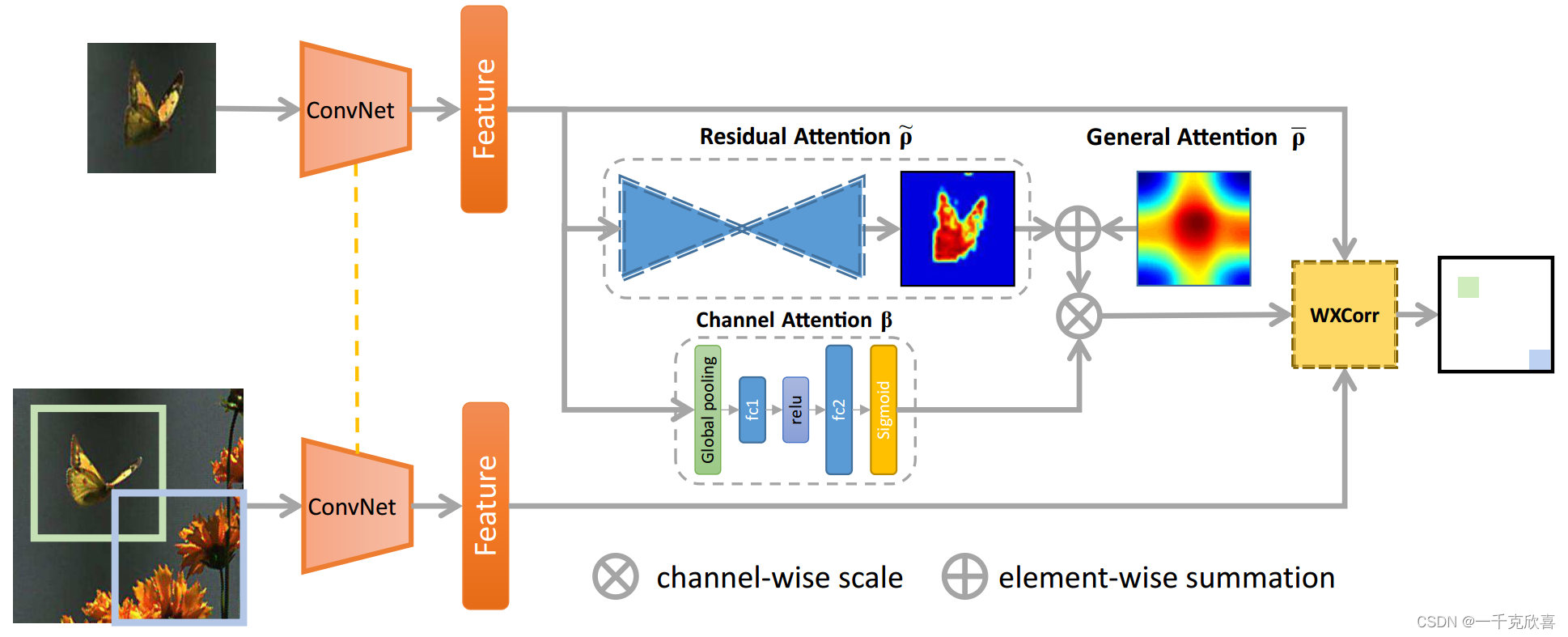
以SiamFC为基础,在backbone提取模板图像和待跟踪图像的特征后,模板特征后加入了残差注意力(Residual Attention)、通道注意力(Channel Attention)和通用注意力(General Attention),同时将互卷积更改为加权互相关层(WXCorr)。
当一张模板和一张待搜索图像流入网络时,通过backbone生成特征图。基于模板特征,使用三种注意力机制提取了模板信息。模板、待搜索特征、作为权重的attention输出,被输入到WXCorr,并最终转换为响应图。
SASiam
论文:A Twofold Siamese Network for Real-Time Object Tracking (CVPR 2018)
链接:https://openaccess.thecvf.com/content_cvpr_2018/html/He_A_Twofold_Siamese_CVPR_2018_paper.html
方法:
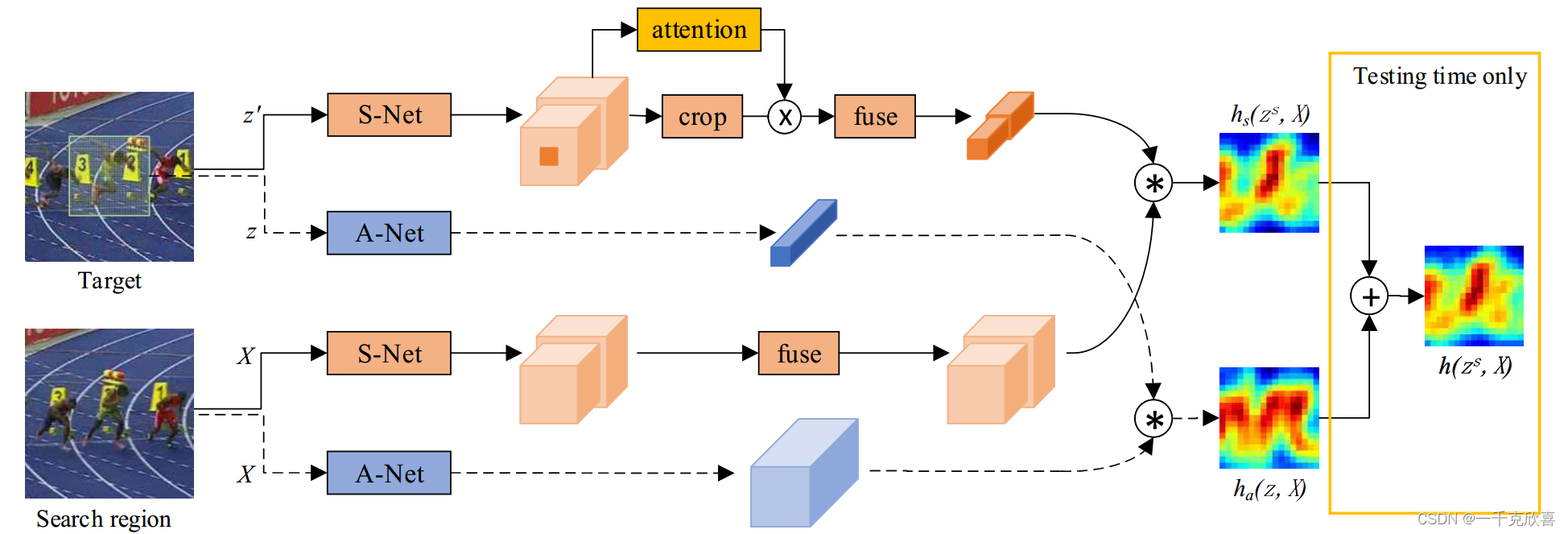
观察到在图像分类任务中学习到的语义特征和在相似性匹配任务中学习到的外观特征相辅相成,构建了一个双分支网络。SASiam由Semantic branch语义分支和Appearance branch外观分支两部分构成,语义分支中还加入了通道注意力机制SEBlock。分别训练这两个网络,将特征图加权输出。
外观特征网络:加入了SEBlock的SiamFC
语义特征网络:Alexnet在ImageNet上训练的权重,并不再跟踪数据集上fine-tune,直接拿过来用。
外观特征更像对于同一个目标外观的相似程度,而语义特征更像是对于同一类目标的相似程度,两者相辅相成。
实际上是将图像解耦为语义和外观。
MBST
论文:Multi-Branch Siamese Networks with Online Selection for Object Tracking(ISVC 2018)
链接:https://link.springer.com/chapter/10.1007/978-3-030-03801-4_28
方法:
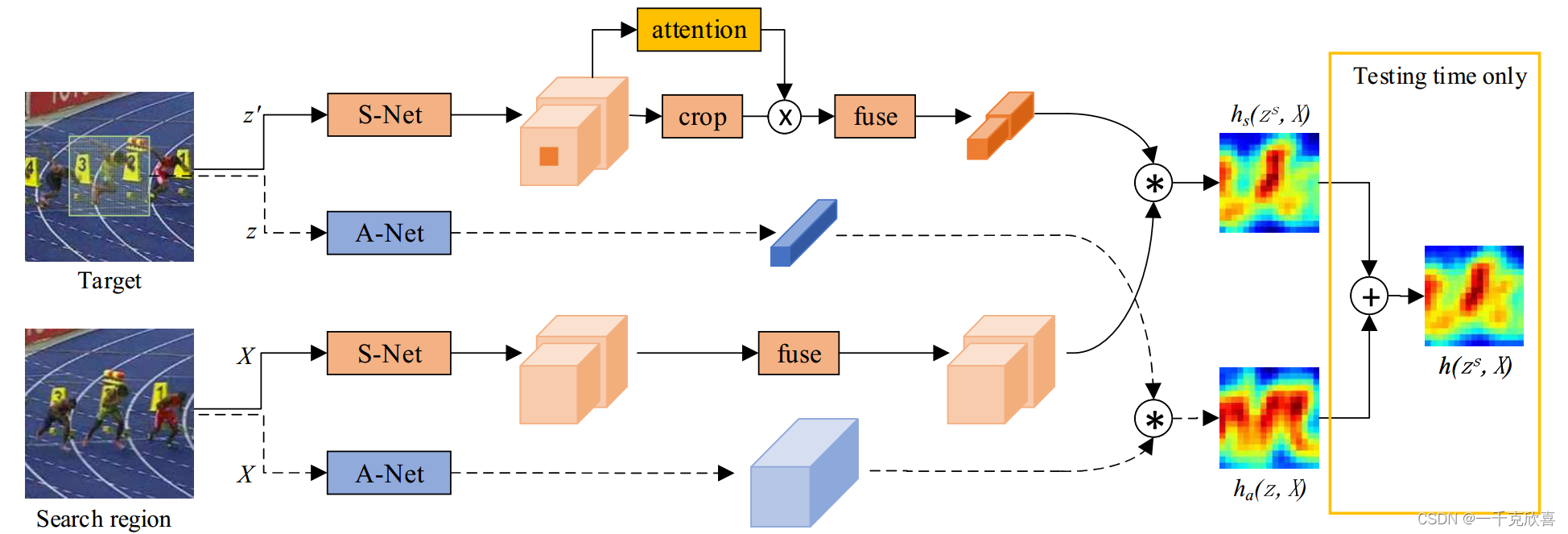
MBST中有两个分支,其中一条是AlexNet分支,另外一条有很多结构一模一样的Context Dependent分支,通过一个分支选择结构,选择输出结果更好的一个Context Dependent。
DSiam
论文:Learning Dynamic Siamese Network for Visual Object Tracking (ICCV 2017)
链接:https://openaccess.thecvf.com/content_iccv_2017/html/Guo_Learning_Dynamic_Siamese_ICCV_2017_paper.html
方法:
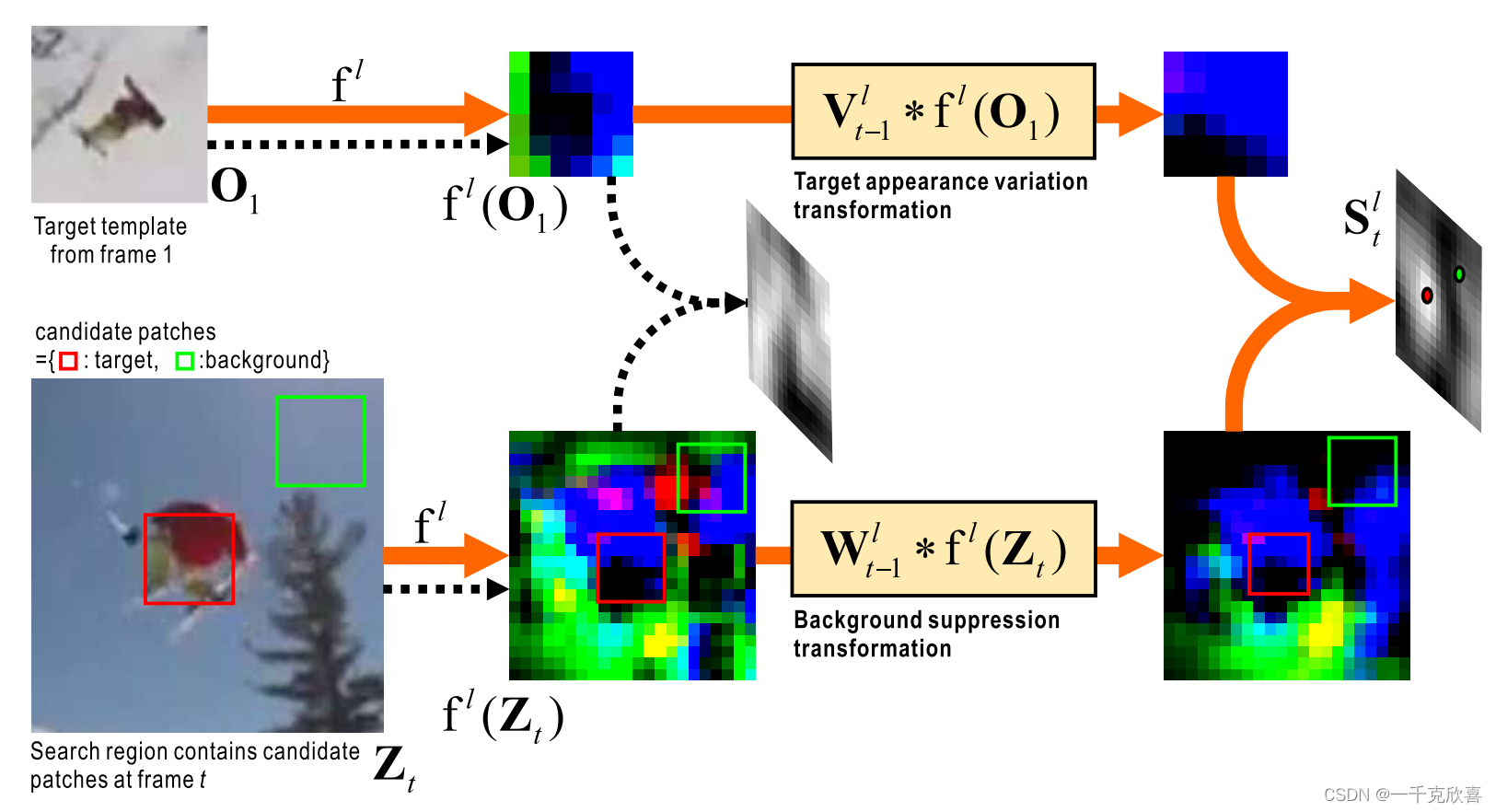
如何1)有效地学习目标外观的时间变化,2)在保持实时响应的同时排除杂波背景的干扰,是视觉目标跟踪的一个基本问题。文章围绕这个问题提出了目标外观变换层和背景抑制层,名字为动态孪生神经网络(Dynamic Siamese Network, DSiam),即对template image使用目标外观变换层,让其更趋进于当前帧的目标外观,对current image使用背景抑制层,抑制背景带来的跟踪干扰。
UpdateNet
论文:Learning the Model Update for Siamese Trackers(ICCV 2019)
链接:https://openaccess.thecvf.com/content_ICCV_2019/html/Zhang_Learning_the_Model_Update_for_Siamese_Trackers_ICCV_2019_paper.html
方法:
Siamese方法通过从当前帧中提取一个外观模板来解决视觉跟踪问题,该模板用于在下一帧中定位目标。通常,此模板与前一帧中累积的模板线性组合(最初的SiamFC有且仅使用第一帧目标外观作为模板),导致信息随时间呈指数衰减。虽然这种更新方法已经带来了更好的结果,但它的简单性限制了通过学习更新可能获得的潜在收益。因此,文章用一种学习更新的方法来取代线性加权。我们使用卷积神经网络,称为UpdateNet,它给出初始模板、累积预测模板和当前帧的模板,目的是估计下一帧的最佳模板。
SiamFC++
论文:SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines (AAAI 2020)
链接:https://ojs.aaai.org/index.php/AAAI/article/view/6944
方法:
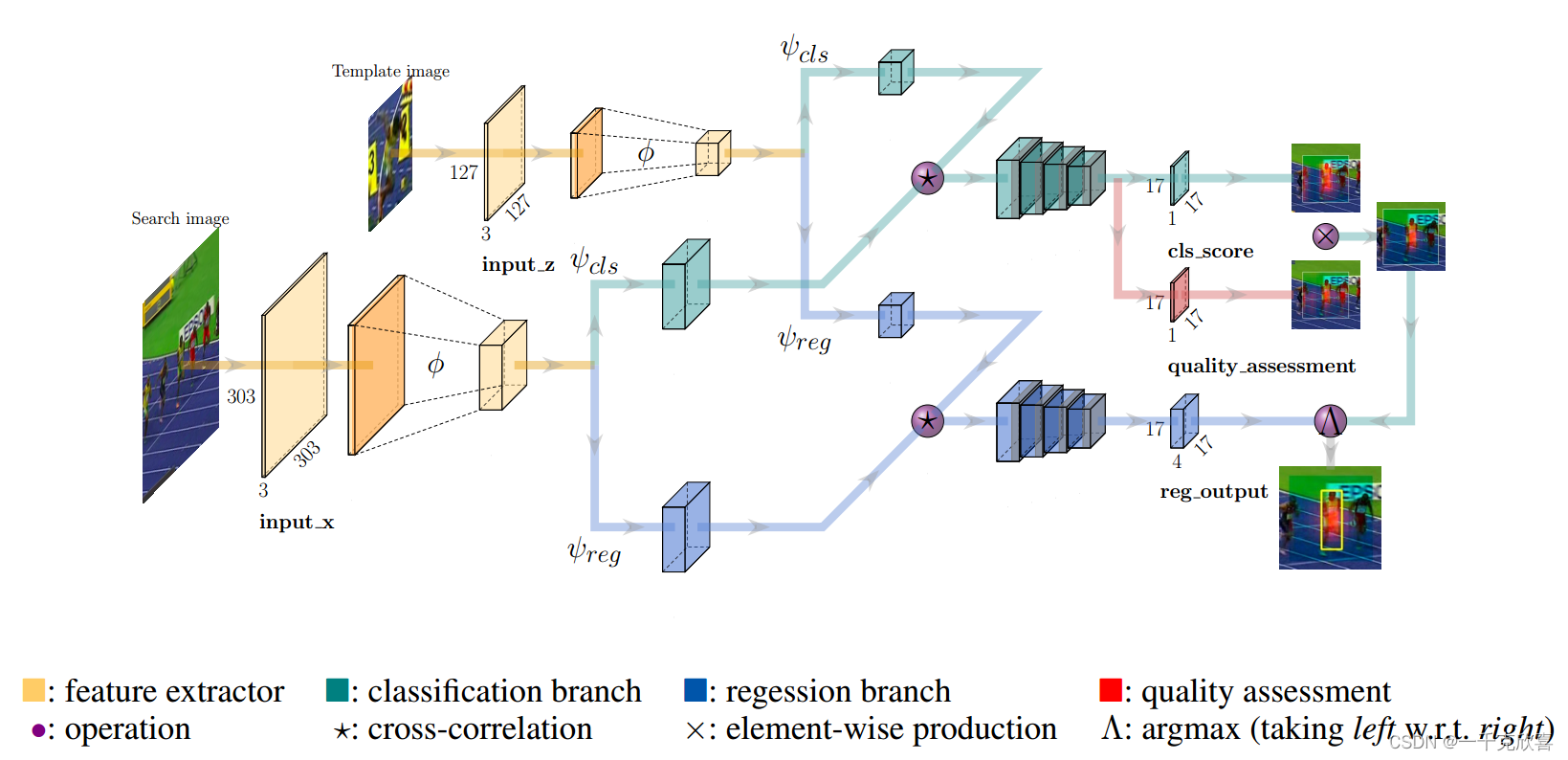
整体结构和SiamRPN类似,都是先提取特征,再互卷积,再添加卷积层输出回归和类别结果,但增加了quality assessment分支,强化回归效果(目标检测中的anchor free算法的FCOS中也有类似结构)
Ranking-Based Siamese Visual Tracking
论文:Ranking-Based Siamese Visual Tracking(CVPR 2022)
链接:https://openaccess.thecvf.com/content/CVPR2022/html/Tang_Ranking-Based_Siamese_Visual_Tracking_CVPR_2022_paper.html
方法:
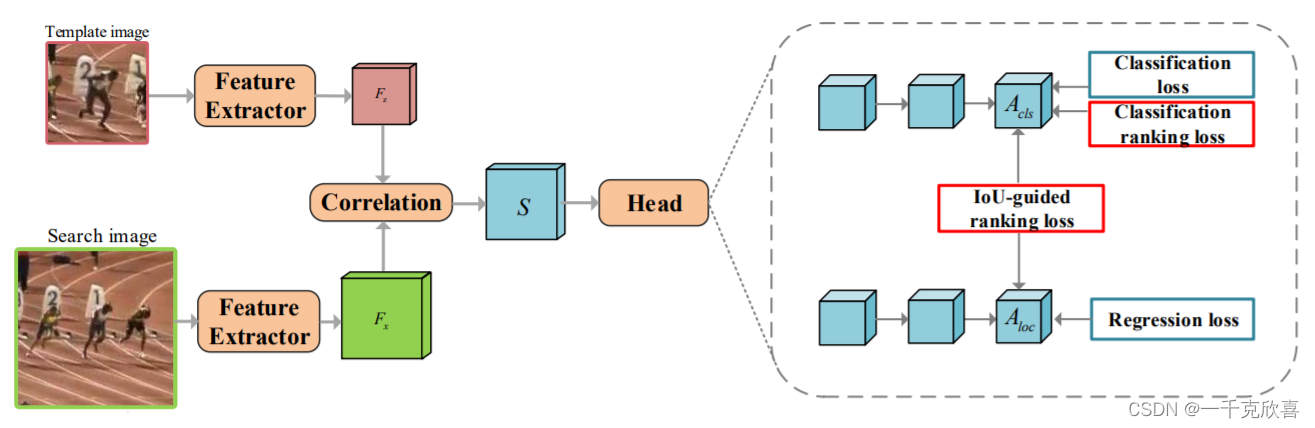
目前基于孪生网络的跟踪器主要将视觉跟踪分为两个子任务,包括分类和定位。他们通过分别处理每个样本来学习分类子网络,忽略了正样本和负样本之间的关系。此外,这种跟踪范式只对最终预测的建议进行分类置信度,这可能会导致分类和定位之间的错位。为了解决这些问题,文章提出了一种基于排序的优化算法来探索不同方案之间的关系。为此,引入了两种排名损失,包括分类损失和IoU引导损失,作为优化约束。分类排名损失可以确保正样本的排名高于硬负样本,即干扰物,这样跟踪器就可以成功地选择前景样本,而不会被干扰物欺骗。IoUguided排名损失旨在将分类置信度得分与正样本的相应定位预测的并集交集(IoU)对齐,从而使定位良好的预测能够用高分类置信度来表示。具体而言,所提出的两种排名损失与大多数暹罗跟踪器兼容,并且不需要额外的推理计算。
参考:https://blog.csdn.net/weixin_43913124/article/details/123545157