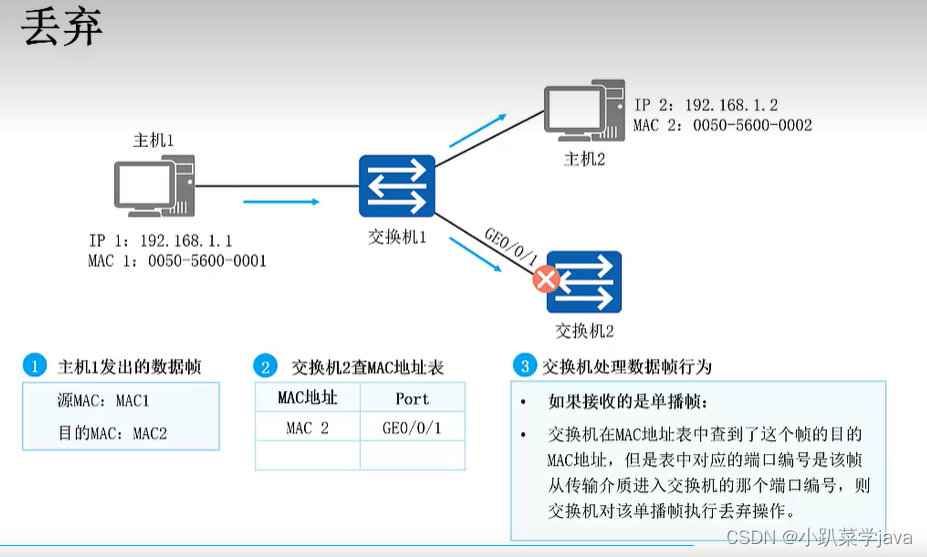
QueryNode 日志中频繁报错?对象存储数据离奇消失[1]?
令人震惊的数据丢失事件就这样发生了,一位来自 BOSS 直聘的 AI 研发工程师无意卷入到此次的风波中,他和 Milvus 社区的伙伴经过层层排查、抽丝剥茧,成功找出了问题所在——GC。
风波已然平息,不过,提起当日事件,这位工程师仍心有余悸,于是将自己的亲身经历记录下来,以求为其他伙伴提供借鉴。
对象存储数据离奇消失始末
那是一个风和日丽的下午,我像往常一样部署了一套 Milvus 集群,并写入了一批数据,愉快地进行着检索,相安无事。
好景不长,第二天我忽然发现 QueryNode 日志中频繁出现 No Such Key 的 ERROR,这个错误意味着节点无法从对象存储的对应路径下获取数据文件。已知并没有进行过任何删除操作与 TTL 设置,同时经过测试在 insert 后,对象存储中也确实能够正常产生相应的 Log 文件,数据消失发生在写入后的一定时间间隔之后。
最终经过社区协助,可以确定,这是由于路径配置重复,GC 操作造成的。
Milvus 的 GC 流程
我们知道,Milvus 的删除是软删除,即标记删除策略。在调用 drop 相关的方法时,会先在 meta 中将被删除项标记为 dropped,待到 GC 触发时,再进行具体的清理。
GC的目标主要包含两部分,一是 Etcd 中保存的元数据,二是对象存储的存储空间。
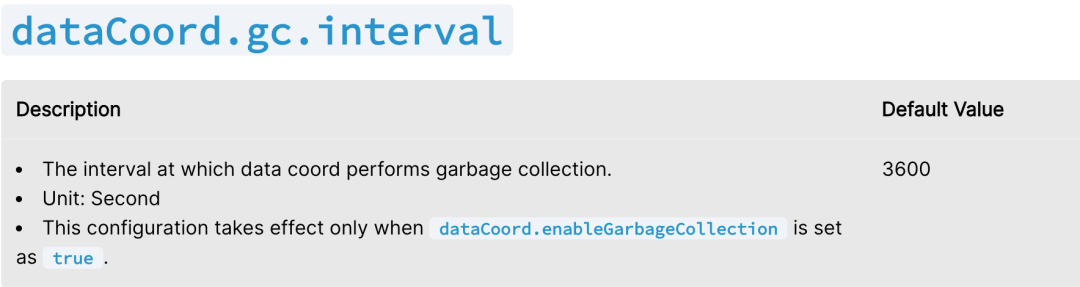
GC 行为由 DataCoord 发起。当 DataCoord 启动时,随之产生 Garbage Collector,执行周期性的 GC 任务,由 milvus.yaml 中的参数 dataCoord.gc.interval 指定 GC 周期。
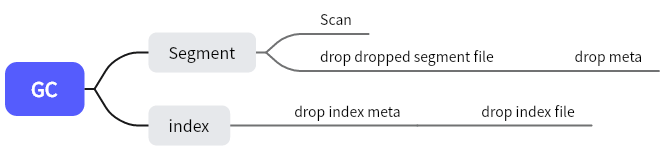
阅读 master 分支代码 internal/datacoord/garbage_collector.go 可知,每一次的 GC 分 5 步进行。
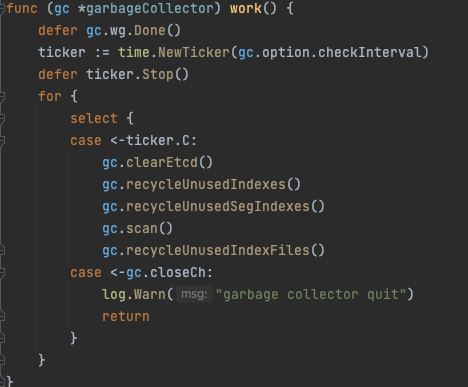
第一步是 clearEtcd,在这一步中,主要关注已标记为 Dropped 的 segment。
a. 通过遍历 meta 中的 segment 信息,统计出所有应该删除的 segment 信息,再逐一执行删除操作。
b. 对于每个待删除的 segment,首先进行删除校验。
-
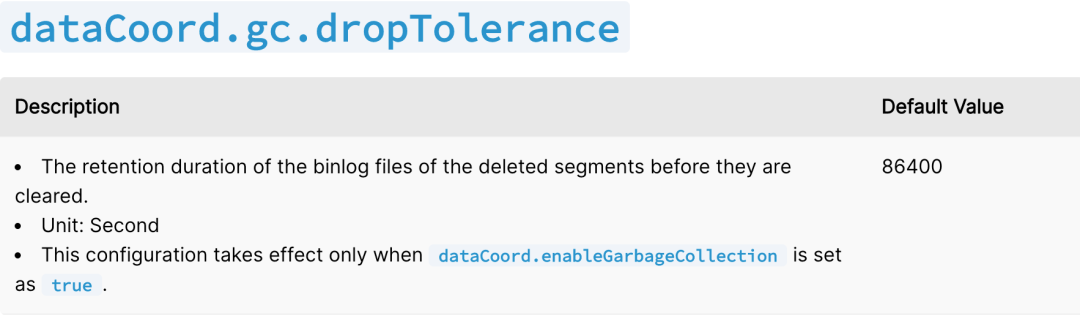
判断 segment 是否满足过期时间,该时间由 dataCoord.gc.dropTolerance [2]参数指定;
-
判断 channel checkpoint 是否为最新,在 dml 位置之后;
-
判断 compact 后的旧 segment 是否可以删除。(在 compact 过后,旧的 segment 会被标记为 Dropped,但若新的 segment 并未完成索引构建,则不能进行清理。)
c. 校验通过后,则执行对象存储回收动作,先清理 log 数据,再清理 meta 数据。
-
删除对象存储的 log 数据;
-
删除 meta 中的段信息;
-
删除空 channel 及对应 checkpoint。
第二步是 recycleUnusedIndexes,清理已标记删除的 index 的 meta 信息。
第三步是 recycleUnusedSegIndexes,同样是清理 index 的 meta 信息,这一步主要关注没有对应 segment 信息的 index。
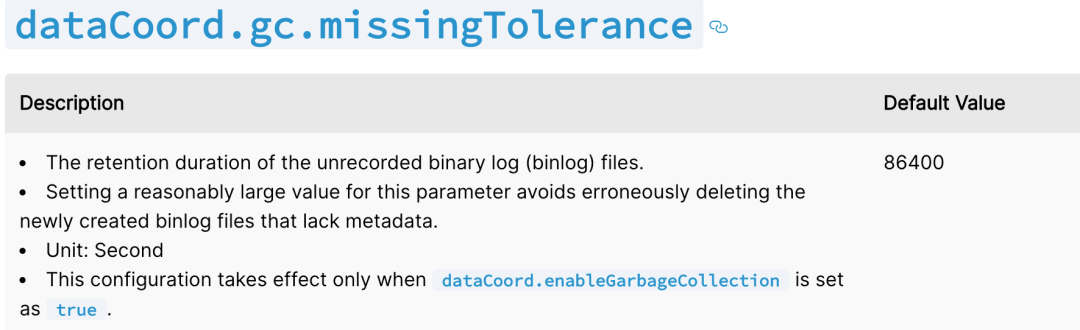
第四步是 scan,顾名思义,这一步中扫描所有的 segment 的 meta 数据与对象存储路径下文件(insetLog/statsLog/deltaLog),如果存储中的数据与元数据不匹配,在容忍一段时间后,执行清理,容忍时间由参数 dataCoord.gc.missingTolerance 指定。
最后是 recycleUnusedIndexFiles,执行 index file 的清理。
流程与 scan 步骤类似,扫描对象存储的 index_file 路径,清理所有在 meta 中已删除的 index 的索引文件。其中,为加快清理速度,若该路径对应的 segment 已删除时,则直接删除所有以该 segment ID 为前缀的所有 index file。
复盘小结
回到我们的问题上。经过排查,我发现该集群与另一集群配置了相同的 bucket 与 rootPath。通过对 GC 流程的了解,可知问题出现在第四步 scan。当集群 A 写入完成后,数据正常持久化到对象存储中,此时集群 B 的 garbage Collector 扫描存储路径,发现这一批数据在 meta 中不存在,但是由于仍在容忍时间内,所以暂不回收。而等到容忍时间一过,数据便被逐渐回收掉了。
如果不小心触发了此问题,配置到重复 bucket 存储路径的集群将互相干扰,互相 GC,互相损坏数据。当我们将其中的干扰集群下线后,问题便自然停止了。但伤痕难以抚平,若重新 load 那些遭到清理的 collection 时,我们会发现依然无法成功加载。这也很容易理解,在加载时,querynode 会按照 meta 中的 segment 存储路径寻找数据文件,一旦发生 No Such Key 的错误,便会加载失败。很可惜,这种数据的破坏是不可逆的(除非所依赖的对象存储有数据恢复的能力),不过如果是已经加载到内存的 collection,不会受到对象存储数据文件的消失的影响,仍可进行正常的检索操作。
为了避免此类乌龙事件的发生,我们需要保证一个独立的 Milvus 集群拥有独立的存储资源,若是依赖于外部的 Etcd 与对象存储服务,需要格外注意配置中 etcd.rootPath 与 minio.rootPath 的全局唯一。为什么会出现不同集群使用相同的存储路径的问题呢?这不能以粗心大意一言蔽之。主观上,这是手动部署的必然缺陷,若是将集群部署纳入到自动化流程中,进行统一的配置管理,可以防患于未然;客观角度,在集群启动时没有对存储路径的校验环节,一个简单的解决方法是对 rootPath 加锁,从而避免冲突配置的集群能够启动。 (本文作者马秉政系 BOSS 直聘 AI 研发工程师)
🌟【相关链接】🌟
[1] 问题链接
[2] dataCoord.gc.dropTolerance)
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 -
欢迎关注微信公众号“Zilliz”,了解最新资讯。 
本文由 mdnice 多平台发布