用例简介
Apache Paimon(以下简称 Paimon)作为支持实时更新的高性能湖存储,本用例展示了在千万数据规模下使用全量 + 增量一体化同步 MySQL 订单表到 Paimon明细表、下游计算聚合及持续消费更新的能力。整体流程如下图所示,其中 MySQL 需要提前准备 ,本机需要下载 Flink 包及 Paimon相关依赖,TPC-H 数据生成器。

数据源由 TPC-H toolkit 生成并导入 MySQL,在写入 Paimon时以 l_shipdate 字段作为业务时间定义分区 l_year 和 l_month,时间跨度从 1992.1-1998.12,动态写入 84 个分区,详细配置如下表所示。
| Configuration | Value | Description |
|---|---|---|
| 记录数 | 59,986,052 | 全量阶段同步数据量 |
| 动态写入分区数 | 84 | `l_year` 为一级分区,`l_month` 为二级分区 |
| Checkpoint Interval | 1m | 数据更新频率 |
| Parallelism | 2 | 单机 2 个并发 |
| FTS Bucket Number | 2 | 每个分区下生成 2 个 bucket |
经测试,在单机并发为 2,checkpoint interval 为 1 min 的配置下(每分钟更新可见)66 min 内写入 59.9 million 全量数据,每 10 min 的写入性能如下表所示,平均写入性能在 1 million/min。
| Duration(min) | Records In (million) |
|---|---|
| 10 | 10 |
| 20 | 20 |
| 30 | 31 |
| 40 | 42 |
| 50 | 50 |
| 60 | 57 |
从作业运行图中可以观测到每 10 min 作业写入的数据量,在 66 min 时全量同步完成,开始持续监听增量数据。
关于数据生成
TPC-H 作为一个经典的 Ad-hoc query 性能测试 benchmark,其包含的数据模型与真实的商业场景十分类似。本用例选取其中订单明细表 lineitem 和针对它的单表查询 Q1(下文会有详细说明)
lineitem schema 如下表所示,每行记录在 128 bytes 左右
| 字段 | 类型 | 描述 |
|---|---|---|
| l_orderkey | INT NOT NULL | 主订单 key,即主订单 id,联合主键第一位 |
| l_partkey | INT NOT NULL | 配件 key,即商品 id |
| l_suppkey | INT NOT NULL | 供应商 key,即卖家 id |
| l_linenumber | INT NOT NULL | 子订单 key,即子订单 id,联合主键第二位 |
| l_quantity | DECIMAL(15, 2) NOT NULL | 商品数量 |
| l_extendedprice | DECIMAL(15, 2) NOT NULL | 商品价格 |
| l_discount | DECIMAL(15, 2) NOT NULL | 商品折扣 |
| l_tax | DECIMAL(15, 2) NOT NULL | 商品税 |
| l_returnflag | CHAR(1) NOT NULL | 订单签收标志,A 代表 accepted 签收,R |
| l_linestatus | CHAR(1) NOT NULL | 子订单状态,发货日期晚于 1995-06-17 之前的订单标记为 O,否则标记为 F |
| l_shipdate | DATE NOT NULL | 订单发货日期 |
| l_commitdate | DATE NOT NULL | 订单提交日期 |
| l_receiptdate | DATE NOT NULL | 收货日期 |
| l_shipinstruct | CHAR(25) NOT NULL | 收货信息,比如 DELIVER IN PERSON 本人签收,TAKE BACK RETURN 退货,COLLECT COD 货到付款 |
| l_shipmode | CHAR(10) NOT NULL | 快递模式,有 SHIP 海运,AIR 空运,TRUCK 陆运,MAIL 邮递等类型 |
| l_comment | VARCHAR(44) NOT NULL | 订单注释 |
业务需求(TPC-H Q1)
对发货日期在一定范围内的订单,根据订单状态和收货状态统计订单数、商品数、总营业额、总利润、平均出厂价、平均折扣价、平均折扣含税价等指标。
快速开始
步骤简介
mysql环境准备:
DROP DATABASE IF EXISTS flink;
CREATE DATABASE IF NOT EXISTS flink;
USE flink;
CREATE USER 'flink' IDENTIFIED WITH mysql_native_password BY 'flink';
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flink';
FLUSH PRIVILEGES;
-- Create Base Table
CREATE TABLE lineitem (
l_orderkey INTEGER NOT NULL,
l_partkey INTEGER NOT NULL,
l_suppkey INTEGER NOT NULL,
l_linenumber INTEGER NOT NULL,
l_quantity DECIMAL(15,2) NOT NULL,
l_extendedprice DECIMAL(15,2) NOT NULL,
l_discount DECIMAL(15,2) NOT NULL,
l_tax DECIMAL(15,2) NOT NULL,
l_returnflag CHAR(1) NOT NULL,
l_linestatus CHAR(1) NOT NULL,
l_shipdate DATE NOT NULL,
l_commitdate DATE NOT NULL,
l_receiptdate DATE NOT NULL,
l_shipinstruct CHAR(25) NOT NULL,
l_shipmode CHAR(10) NOT NULL,
l_comment VARCHAR(44) NOT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- Add PK Constraint
ALTER TABLE lineitem ADD PRIMARY KEY (l_orderkey, l_linenumber);
-- Create Delta Table
CREATE TABLE update_lineitem LIKE lineitem;
CREATE TABLE delete_lineitem (
l_orderkey INTEGER NOT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE delete_lineitem ADD PRIMARY KEY (l_orderkey);准备TPC-H 生产文件 :添加tpch_dbgen_linux64-2.14.0.zip到服务器,解压执行命令,生产10G数据,其中lineitem大约7.3G
./dbgen -q -s 10 -T L ![]()
加载数据到mysql
添加mycreds.cnf文件,内容包含mysql的基本信息

mysql --defaults-extra-file=mycreds.cnf -D flink --local-infile=1 -e "
LOAD DATA LOCAL INFILE 'lineitem.tbl' INTO TABLE lineitem FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n';"本用例会在第一步中将全量订单数据(约 59.9 million)导入 MySQL container,预计耗时 15 min,在此期间您可以准备好 Flink 及 Paimon 等环境,等待数据导入完毕,然后启动 Flink 作业。然后使用脚本开始持续触发 TPC-H 产生 RF1(新增订单)和 RF2(删除已有订单)来模拟增量更新(每组新增和删除之间间隔 20s)。以 10 组更新为例,将会产生 6 million 新增订单和 1.5 million 删除订单(注:TPC-H 产生的删除订单为主订单 ID,由于 lineitem 存在联合主键,故实际删除数据量稍大于 1.5 million)。
第二步:下载 Flink、Paimon 及其他所需依赖
Demo 运行使用 Flink 1.17.0 版本( flink-1.17.0 ),需要的其它依赖如下
- Flink MySQL CDC connector
- 基于 Flink 1.15 编译的 FTS(Paimon Jar File)
- Hadoop Bundle Jar
为方便操作,您可以直接在本项目的 flink-table-store-101/flink/lib 目录下载所有依赖,并放置于本地 flink-1.14.5/lib 目录下,也可以自行下载及编译
- flink-sql-connector-mysql-cdc-2.2.1.jar
- Hadoop Bundle Jar
上述步骤完成后,lib 目录结构如图所示
lib
-rw-r--r-- 1 hadoop hadoop 196487 3月 17 20:07 flink-cep-1.17.0.jar
-rw-r--r-- 1 hadoop hadoop 542616 3月 17 20:10 flink-connector-files-1.17.0.jar
-rw-r--r-- 1 hadoop hadoop 102468 3月 17 20:14 flink-csv-1.17.0.jar
-rw-r--r-- 1 hadoop hadoop 135969953 3月 17 20:22 flink-dist-1.17.0.jar
-rw-r--r-- 1 hadoop hadoop 180243 3月 17 20:13 flink-json-1.17.0.jar
-rw-r--r-- 1 hadoop hadoop 21043313 3月 17 20:20 flink-scala_2.12-1.17.0.jar
-rw-rw-r-- 1 hadoop hadoop 36327707 5月 19 15:12 flink-shaded-hadoop-2-uber-2.6.5-7.0.jar
-rw-rw-r-- 1 hadoop hadoop 22096298 5月 22 10:30 flink-sql-connector-mysql-cdc-2.2.1.jar
-rw-r--r-- 1 hadoop hadoop 15407474 3月 17 20:21 flink-table-api-java-uber-1.17.0.jar
-rw-r--r-- 1 hadoop hadoop 37975208 3月 17 20:15 flink-table-planner-loader-1.17.0.jar
-rw-r--r-- 1 hadoop hadoop 3146205 3月 17 20:07 flink-table-runtime-1.17.0.jar
-rw-r--r-- 1 hadoop hadoop 208006 3月 17 17:31 log4j-1.2-api-2.17.1.jar
-rw-r--r-- 1 hadoop hadoop 301872 3月 17 17:31 log4j-api-2.17.1.jar
-rw-r--r-- 1 hadoop hadoop 1790452 3月 17 17:31 log4j-core-2.17.1.jar
-rw-r--r-- 1 hadoop hadoop 24279 3月 17 17:31 log4j-slf4j-impl-2.17.1.jar
-rw-rw-r-- 1 hadoop hadoop 26745559 5月 19 15:14 paimon-flink-1.17-0.5-20230512.001824-7.jar
第三步:修改 flink-conf 配置文件并启动集群
vim flink-1.17.0/conf/flink-conf.yaml 文件,按如下配置修改
jobmanager.memory.process.size: 4096m taskmanager.memory.process.size: 4096m taskmanager.numberOfTaskSlots: 8 parallelism.default: 2 execution.checkpointing.interval: 1min state.backend: rocksdb state.backend.incremental: true execution.checkpointing.checkpoints-after-tasks-finish.enabled: true
若想观察 Paimon的异步合并、Snapshot 提交及流读等信息,可以在 flink-1.14.5/conf 目录下修改 log4j.properties 文件,按需增加如下配置
# Log FTS
logger.commit.name = org.apache.flink.table.store.file.operation.FileStoreCommitImpl
logger.commit.level = DEBUG
logger.compaction.name = org.apache.flink.table.store.file.mergetree.compact
logger.compaction.level = DEBUG
logger.enumerator.name = org.apache.flink.table.store.connector.source.ContinuousFileSplitEnumerator
logger.enumerator.level = DEBUG
这里我们只开启提交的 DEBUG,然后在 flink-1.17.0 目录下执行 ./bin/start-cluster.sh
第四步:初始化表 schema 并启动 Flink SQL CLI
./bin/sql-client.sh执行SQL
-- 设置使用流模式
SET 'execution.runtime-mode' = 'streaming';
-- 创建并使用 FTS Catalog
CREATE CATALOG `table_store` WITH (
'type' = 'table-store',
'warehouse' = 'hdfs://tmp/table-store-101'
);
USE CATALOG `table_store`;
-- ODS table schema
-- 注意在 FTS Catalog 下,创建使用其它连接器的表时,需要将表声明为临时表
CREATE TEMPORARY TABLE `ods_lineitem` (
`l_orderkey` INT NOT NULL,
`l_partkey` INT NOT NULL,
`l_suppkey` INT NOT NULL,
`l_linenumber` INT NOT NULL,
`l_quantity` DECIMAL(15, 2) NOT NULL,
`l_extendedprice` DECIMAL(15, 2) NOT NULL,
`l_discount` DECIMAL(15, 2) NOT NULL,
`l_tax` DECIMAL(15, 2) NOT NULL,
`l_returnflag` CHAR(1) NOT NULL,
`l_linestatus` CHAR(1) NOT NULL,
`l_shipdate` DATE NOT NULL,
`l_commitdate` DATE NOT NULL,
`l_receiptdate` DATE NOT NULL,
`l_shipinstruct` CHAR(25) NOT NULL,
`l_shipmode` CHAR(10) NOT NULL,
`l_comment` VARCHAR(44) NOT NULL,
PRIMARY KEY (`l_orderkey`, `l_linenumber`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1', -- 如果想使用 host,可以修改宿主机 /etc/hosts 加入 127.0.0.1 mysql.docker.internal
'port' = '3306',
'username' = 'flink',
'password' = 'flink',
'database-name' = 'flink',
'table-name' = 'lineitem'
);
-- DWD table schema
-- 以 `l_shipdate` 为业务日期,创建以 `l_year` + `l_month` 的二级分区表,注意所有 partition key 都需要声明在 primary key 中
CREATE TABLE IF NOT EXISTS `dwd_lineitem` (
`l_orderkey` INT NOT NULL,
`l_partkey` INT NOT NULL,
`l_suppkey` INT NOT NULL,
`l_linenumber` INT NOT NULL,
`l_quantity` DECIMAL(15, 2) NOT NULL,
`l_extendedprice` DECIMAL(15, 2) NOT NULL,
`l_discount` DECIMAL(15, 2) NOT NULL,
`l_tax` DECIMAL(15, 2) NOT NULL,
`l_returnflag` CHAR(1) NOT NULL,
`l_linestatus` CHAR(1) NOT NULL,
`l_shipdate` DATE NOT NULL,
`l_commitdate` DATE NOT NULL,
`l_receiptdate` DATE NOT NULL,
`l_shipinstruct` CHAR(25) NOT NULL,
`l_shipmode` CHAR(10) NOT NULL,
`l_comment` VARCHAR(44) NOT NULL,
`l_year` BIGINT NOT NULL,
`l_month` BIGINT NOT NULL,
PRIMARY KEY (`l_orderkey`, `l_linenumber`, `l_year`, `l_month`) NOT ENFORCED
) PARTITIONED BY (`l_year`, `l_month`) WITH (
-- 每个 partition 下设置 2 个 bucket
'bucket' = '2',
-- 设置 changelog-producer 为 'input',这会使得上游 CDC Source 不丢弃 update_before,并且下游消费 dwd_lineitem 时没有 changelog-normalize 节点
'changelog-producer' = 'input'
);
-- ADS table schema
-- 基于 TPC-H Q1,对已发货的订单,根据订单状态和收货状态统计订单数、商品数、总营业额、总利润、平均出厂价、平均折扣价、平均折扣含税价等指标
CREATE TABLE IF NOT EXISTS `ads_pricing_summary` (
`l_returnflag` CHAR(1) NOT NULL,
`l_linestatus` CHAR(1) NOT NULL,
`sum_quantity` DOUBLE NOT NULL,
`sum_base_price` DOUBLE NOT NULL,
`sum_discount_price` DOUBLE NOT NULL,
`sum_charge_vat_inclusive` DOUBLE NOT NULL,
`avg_quantity` DOUBLE NOT NULL,
`avg_base_price` DOUBLE NOT NULL,
`avg_discount` DOUBLE NOT NULL,
`count_order` BIGINT NOT NULL,
PRIMARY KEY (`l_returnflag`, `l_linestatus`) NOT ENFORCED
) WITH (
'bucket' = '2',
'merge-engine'='partial-update',
'changelog-producer'='full-compaction'
);第五步:提交同步任务
在全量数据导入到 MySQL lineitem 表后,我们启动全量同步作业,这里以结果表作为作业名,方便标识
任务1:通过 Flink MySQL CDC 同步 ods_lineitem 到 dwd_lineitem
-- 设置作业名
SET 'pipeline.name' = 'dwd_lineitem';
INSERT INTO dwd_lineitem
SELECT
`l_orderkey`,
`l_partkey`,
`l_suppkey`,
`l_linenumber`,
`l_quantity`,
`l_extendedprice`,
`l_discount`,
`l_tax`,
`l_returnflag`,
`l_linestatus`,
`l_shipdate`,
`l_commitdate`,
`l_receiptdate`,
`l_shipinstruct`,
`l_shipmode`,
`l_comment`,
YEAR(`l_shipdate`) AS `l_year`,
MONTH(`l_shipdate`) AS `l_month`
FROM `ods_lineitem`;可以在 Flink Web UI 观察全量同步阶段的 rps、checkpoint 等信息,也可以切换到hdfs的 /tmp/table-store-101/default.db/dwd_lineitem 目录下,查看生成的 snpashot、manifest 和 sst 文件。
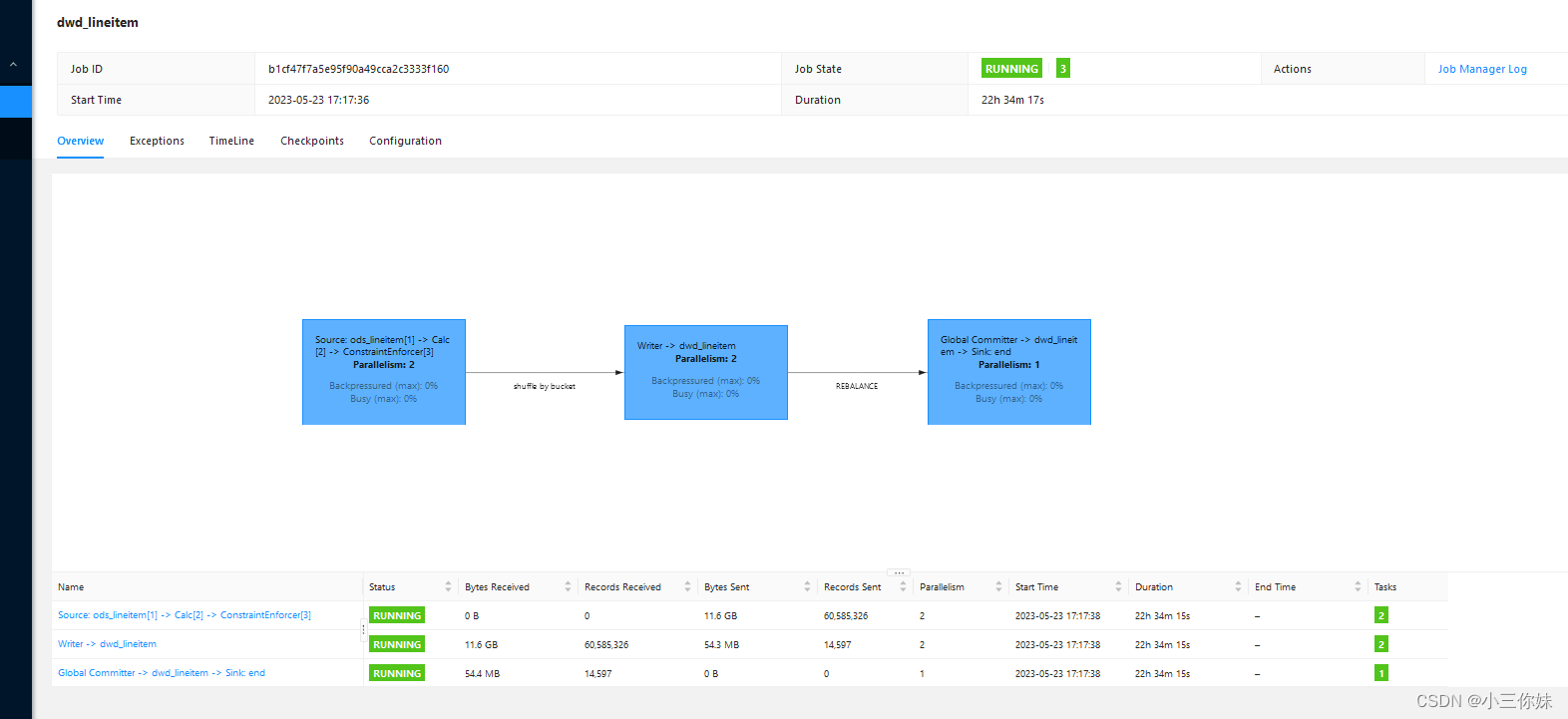
第六步:计算聚合指标并查询结果
在全量同步完成后,我们启动聚合作业,实时写入 ads 表 (注:如有需要在历史全量数据不全的情况下也展示聚合结果,可以不用等待全量同步完成)
任务2:写入结果表 ads_pricing_summary
-- 设置作业名
SET 'pipeline.name' = 'ads_pricing_summary';
INSERT INTO `ads_pricing_summary`
SELECT
`l_returnflag`,
`l_linestatus`,
SUM(`l_quantity`) AS `sum_quantity`,
SUM(`l_extendedprice`) AS `sum_base_price`,
SUM(`l_extendedprice` * (1-`l_discount`)) AS `sum_discount_price`, -- aka revenue
SUM(`l_extendedprice` * (1-`l_discount`) * (1+`l_tax`)) AS `sum_charge_vat_inclusive`,
AVG(`l_quantity`) AS `avg_quantity`,
AVG(`l_extendedprice`) AS `avg_base_price`,
AVG(`l_discount`) AS `avg_discount`,
COUNT(*) AS `count_order`
FROM `dwd_lineitem`
WHERE (`l_year` < 1998 OR (`l_year` = 1998 AND `l_month`<= 9))
AND `l_shipdate` <= DATE '1998-12-01' - INTERVAL '90' DAY
GROUP BY
`l_returnflag`,
`l_linestatus`;
我们切换到 batch 模式并且将结果展示切换为 tableau 模式
SET 'execution.runtime-mode' = 'batch';
SET 'sql-client.execution.result-mode' = 'tableau';然后查询刚才聚合的结果,可以多运行几次来观测指标的变化 (查询间隔应大于所查上游表的 checkpoint 间隔)
SET 'pipeline.name' = 'Pricing Summary';
SELECT * FROM ads_pricing_summary;除了查询聚合指标外,FTS 同时支持查询明细数据。假设我们发现 1998 年 12 月发生退货的子订单指标有问题,想通过订单明细进一步排查,可在 batch 模式下进行如下查询
SELECT `l_orderkey`, `l_returnflag`, `l_linestatus`, `l_shipdate` FROM `dwd_lineitem` WHERE `l_year` = 1998 AND `l_month` = 12 AND `l_linenumber` = 2 AND `l_shipinstruct` = 'TAKE BACK RETURN';使用spark查询数据
下载spark-3.1.2-bin-hadoop2.7
在jars里面放入paimon-spark-3.1-0.5-SNAPSHOT.jar
spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog --conf spark.sql.catalog.paimon.warehouse=hdfs://tmp/table-store-101USE paimon.default;
select count(*) from dwd_lineitem;
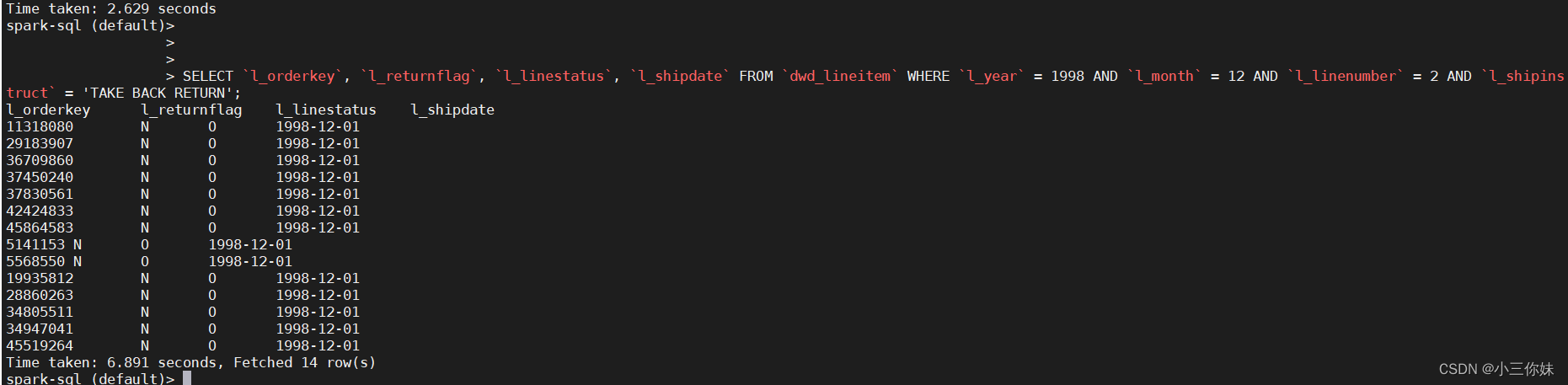
SELECT `l_orderkey`, `l_returnflag`, `l_linestatus`, `l_shipdate` FROM `dwd_lineitem` WHERE `l_year` = 1998 AND `l_month` = 12 AND `l_linenumber` = 2 AND `l_shipinstruct` = 'TAKE BACK RETURN';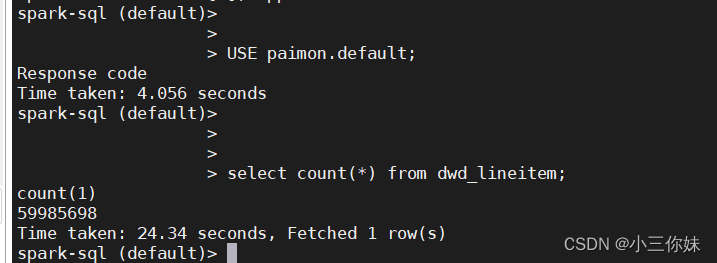
第七步:观测更新数据
生成更新数据
编写脚本
start_pair=1
total_pair=10
MYSQL_DATABASE=gmall
for i in `seq ${start_pair} ${total_pair}`; do
if [[ `expr ${i} % 10` -eq 0 ]]; then
echo "$(date +"%Y-%m-%d %H:%M:%S") Start to apply Old Sales Refresh Function (RF2) for pair ${i}"
fi
# This refresh function removes old sales information from the database.
mysql --defaults-extra-file=mycreds.cnf -D ${MYSQL_DATABASE} -e "TRUNCATE delete_lineitem"
mysql --defaults-extra-file=mycreds.cnf -D ${MYSQL_DATABASE} --local-infile=1 -e "SET UNIQUE_CHECKS = 0;" -e "
LOAD DATA LOCAL INFILE 'delete.${i}' INTO TABLE delete_lineitem FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n';"
mysql --defaults-extra-file=mycreds.cnf -D ${MYSQL_DATABASE} -e "
BEGIN;
DELETE FROM lineitem WHERE l_orderkey IN (SELECT l_orderkey FROM delete_lineitem);
COMMIT;"
sleep 20s
if [[ `expr ${i} % 10` -eq 0 ]]; then
echo "$(date +"%Y-%m-%d %H:%M:%S") Start to apply New Sales Refresh Function (RF1) for pair ${i}"
fi
# This refresh function adds new sales information to the database.
mysql --defaults-extra-file=mycreds.cnf -D ${MYSQL_DATABASE} -e "TRUNCATE update_lineitem"
mysql --defaults-extra-file=mycreds.cnf -D ${MYSQL_DATABASE} --local-infile=1 -e "SET UNIQUE_CHECKS = 0;" -e "
LOAD DATA LOCAL INFILE 'lineitem.tbl.u${i}' INTO TABLE update_lineitem FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n';"
mysql --defaults-extra-file=mycreds.cnf -D ${MYSQL_DATABASE} -e "
BEGIN;
INSERT INTO lineitem
SELECT * FROM update_lineitem;
COMMIT;"
done
start_pair=`expr ${total_pair} + 1`
total_pair=`expr ${total_pair} \* 2`
sleep 2m参考
基于 Apache Flink Table Store 的全增量一体实时入湖 - 简书
Apache Flink Table Store 全增量一体 CDC 实时入湖