1、在线学习
实时获得一个新样本就进行一次模型更新。显然,在线学习时增量学习的特例,而增量学习可视为“批模式”的在线/离线学习。
online主要相对于offline或者说batch,强调的是每次只进入一个或者很少的几个样本,多见于推荐系统等实时运行、实时训练、实时反馈的系统,非常强调实时的反馈能力。
2、增量学习
每获得一批新样本就进行一次模型更新。学得模型后,再接收到训练样例时,仅需根据新样例对模型进行更新,不必重新训练整个模型,并且之前学得的有效信息不会被冲掉,得到一个在老数据和新数据上都能work的新模型。
“在线学习”和“增量学习”之间的区别?
- 在线学习一定是增量的。因为在线学习,实现方式就是数据一条一条流进来更新模型。技术上可以基于流计算实现。
- 增量学习不一定是在线的。因为给定一个模型和一批离线/在线数据,增量学习可以用这一批离线数据,去更新之前训练好的模型。而不需要从头开始训练一个模型。技术上可以基于批计算实现。
3、终身学习(LifeLong Learning)与 增量学习(Incremental Learning)?
Lifelong learning终生学习,又名增量学习increment learning。通常机器学习中,单个模型只解决单个或少数几个任务。对于新的任务,我们一般重新训练新的模型。而LifeLong learning,则先在task1(例如:语音识别)上使用一个模型,然后在task2(例如:图像分类)上仍然使用这个模型,一直到task n。Lifelong learning探讨的问题是,一个模型在很多个task上表现都很好。如此下去,模型能力就会越来越强。这和人类不停学习新的知识,从而掌握很多不同知识,是异曲同工的。
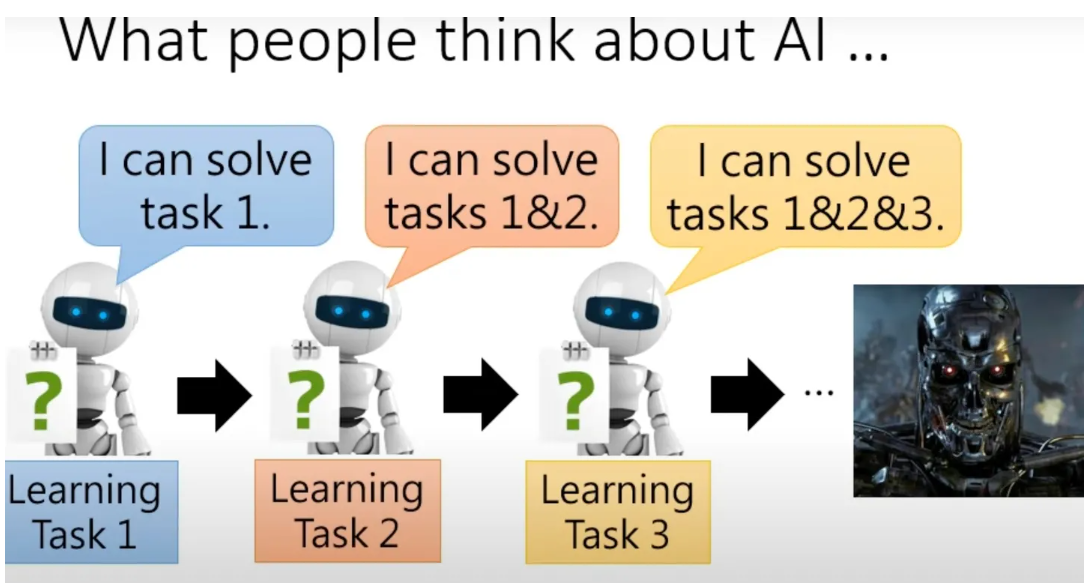
LifeLong learning需要解决三个问题
- Knowledge Retention 知识记忆。我们不希望学完task1的模型,在学习task2后,在task1上表现糟糕。也就是希望模型有一定的记忆能力,能够在学习新知识时,不要忘记老知识。但同时模型不能因为记忆老知识,而拒绝学习新知识。总之在新老task上都要表现比较好。
- Knowledge Transfer 知识迁移。我们希望学完task1的模型,能够触类旁通,即使不学习task2的情况下,也能够在task2上表现不错。也就是模型要有一定的迁移能力。这个和transfer learning有些类似。
- Model Expansion 模型扩张。一般来说,由于需要学习越来越多的任务,模型参数需要一定的扩张。但我们希望模型参数扩张是有效率的,而不是来一个任务就扩张很多参数。这会导致计算和存储问题。
4、life long learning 与 multi- task的区别?
多个任务(或者可以一个任务的不同domain)不是同时学,而是依次有顺序的学习,但是依次学习面临的问题是学到新知识,忘记了新知识,也就是catastrophic forgetting。另外,任务学习的顺序也很重要!!!
其实,multi- task也可以解决life long learning问题(multi- task是LLL的上界,相当于复习以前的内容),但是存在一些问题:
(1)存储空间:当有大量任务需要同时学习的时候,说明此刻机器需要将所有任务的资料或数据同时存储并且学习,那么当任务数大且占用内存大时,便会导致存储空间不足。
(2)计算问题:因为任务量大,模型需要同时调整多个任务的参数,计算量会无限增大,计算速度变慢。
这时,有人就会想到,那既然同时学习不行,会产生内存和计算的问题,那是不是可以单独学习每个任务呢?
回答当然是可以的,but, 每个任务单独学习首先仍然存在内存开销大的问题,其次,针对每个任务单独学习一个模型,每个任务之间的知识是不互通,无法发生知识迁移,这也就违背了life long learning的初衷
5、Life long learning 和transfer learning的区别?
transfer learning更关注后续任务的学习,如果我们把transfer learning比作一个奥运长跑冠军,那么life long learning则相当于奥运会中的全能选手,他需要关注到每个任务的性能,保证模型十八般武艺都精通。
6、在线学习(Online Learning)和离线学习(Offline Learning)的区别?
第一种理解
在线学习,通常是一次输入一条数据(而不是一个batch),训练完了直接更新权重。一个一个地按照顺序处理数据,但是每一个数据训练完后都会直接更新权重,但不知道是对是错,如果某一次权重更新错误,在这之后的权重更新可能一直都是错的,最后得到的模型可能就会逐渐走向错误方向,残差出现。在线学习先按顺序处理数据,他们产生一个模型,并把这个模型放在实际操作中,不需要一开始就提供完整的训练数据集。随着更多实时数据进入模型,模型会在操作中不断被更新
离线学习,类似于批量学习,假设整个样本有m个数据,离线训练会训练m的整数倍次数,然后带入下一条,直至跑完整个样本,这个时候误差率可能不让你满意,把整个样本又做个上述操作,直至误差很小。离线学习是一个batch训练完才更新权重,因此要求所有数据必须在每一个训练训练操作中(batch)中都是可用的,这样不会因为个别数据的更新错误把网络带向极端。
第二种理解
在线学习中,恰恰相反,在线算法按照顺序处理数据。它们产生一个模型,并在把这个模型放入实际操作中,而不需要在一开始就提供完整的的训练数据集。随着更多的实时数据到达,模型会在操作中不断地更新。具体而言,在线学习(Online Learning)指的是在数据不断到来的过程中,动态地更新模型。在线学习具有实时性,可以快速适应新数据的特征变化,而且可以避免离线学习需要重新生成模型的问题。但是,由于在线学习需要实时计算,因此会对系统的性能产生一定的影响。此外,由于在线学习需要实时计算,因此需要进行一定的模型设计和优化,以提高算法的效率和准确性。
在离线学习中,所有的训练数据在模型训练期间必须是可用的。只有训练完成了之后,模型才能被拿来用。简而言之,先训练,再用模型,不训练完就不用模型。
具体而言,离线学习(Offline Learning)指的是在离线状态下,使用历史数据进行学习,从而生成模型。这种方式的优点是可以在对数据进行了预处理后,通过离线计算的方式,快速地生成模型。缺点是模型生成后,无法对其进行动态更新,对于新数据的学习需要重新生成模型,因此不太适用于需要频繁更新模型的场景。
机器学习:在线学习和离线学习的区别 - 知乎