11 framebuffer
我们已经将渲染传递设置为期望一个与交换链图像格式相同的单一帧缓冲,但我们还没有实际创建任何图像。
在渲染过程创建期间指定的附件通过将它们包装到一个VkFramebuffer对象中来绑定。帧缓冲区对象引用 VkImageView代表附件的所有对象。
std::vector<VkFramebuffer> swapChainFramebuffers;//帧缓冲区
void createFramebuffers() {
//调整容器的大小以容纳所有的帧缓冲区
swapChainFramebuffers.resize(swapChainImageViews.size());
//遍历图像视图并从中创建帧缓冲区
for (size_t i = 0; i < swapChainImageViews.size(); i++) {
VkImageView attachments[] = {
swapChainImageViews[i]
};
//首先需要指定renderPass帧缓冲区需要与哪个兼容
VkFramebufferCreateInfo framebufferInfo{};
framebufferInfo.sType = VK_STRUCTURE_TYPE_FRAMEBUFFER_CREATE_INFO;
framebufferInfo.renderPass = renderPass;
//应绑定到渲染通道数组中相应附件描述的attachmentCount对象
framebufferInfo.attachmentCount = 1;
framebufferInfo.pAttachments = attachments;
framebufferInfo.width = swapChainExtent.width;
framebufferInfo.height = swapChainExtent.height;
framebufferInfo.layers = 1;
if (vkCreateFramebuffer(device, &framebufferInfo, nullptr, &swapChainFramebuffers[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create framebuffer!");
}
}
}
//在它们所基于的图像视图和渲染通道之前删除帧缓冲区
void cleanup() {
for (auto framebuffer : swapChainFramebuffers) {
vkDestroyFramebuffer(device, framebuffer, nullptr);
}
...
}12 命令缓冲区
Vulkan 中的命令,如绘图操作和内存传输,不是直接使用函数调用执行的。您必须在命令缓冲区对象中记录要执行的所有操作。当我们准备好告诉 Vulkan 我们想要做什么时,所有的命令都会一起提交,Vulkan 可以更有效地处理这些命令,因为它们都是一起可用的。
在创建命令缓冲区之前,我们必须创建一个命令池。命令池管理用于存储缓冲区的内存,命令缓冲区是从它们中分配的。添加一个新的类成员来存储一个VkCommandPool:
VkCommandPool commandPool;void createCommandPool() {
//命令池创建只需要两个参数
QueueFamilyIndices queueFamilyIndices = findQueueFamilies(physicalDevice);
VkCommandPoolCreateInfo poolInfo{};
poolInfo.sType = VK_STRUCTURE_TYPE_COMMAND_POOL_CREATE_INFO;
//每帧记录一个命令缓冲区,因此我们希望能够重置并重新记录它
poolInfo.flags = VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT;
poolInfo.queueFamilyIndex = queueFamilyIndices.graphicsFamily.value();
if (vkCreateCommandPool(device, &poolInfo, nullptr, &commandPool) != VK_SUCCESS) {
throw std::runtime_error("failed to create command pool!");
}
}
//使用函数完成创建命令池vkCreateCommandPool。它没有任何特殊参数。
void cleanup() {
vkDestroyCommandPool(device, commandPool, nullptr);
...
}命令池有两个可能的标志:
VK_COMMAND_POOL_CREATE_TRANSIENT_BIT:提示命令缓冲区经常用新命令重新记录(可能会改变内存分配行为)VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT: 允许单独重新记录命令缓冲区,如果没有这个标志,它们都必须一起重置
我们现在可以开始分配命令缓冲区。
创建一个VkCommandBuffer对象作为类成员。当它们的命令池被销毁时,命令缓冲区将自动释放,因此我们不需要显式清理。
VkCommandBuffer commandBuffer;void createCommandBuffer() {
VkCommandBufferAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
allocInfo.commandPool = commandPool;
//该level参数指定分配的命令缓冲区是主命令缓冲区还是辅助命令缓冲区。
allocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
//只分配一个命令缓冲区,所以commandBufferCount参数只有一个。
allocInfo.commandBufferCount = 1;
if (vkAllocateCommandBuffers(device, &allocInfo, &commandBuffer) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate command buffers!");
}
}命令缓冲区记录
我们现在开始研究将recordCommandBuffer要执行的命令写入命令缓冲区的函数。usedVkCommandBuffer将作为参数传入,以及我们要写入的当前交换链图像的索引。
void recordCommandBuffer(VkCommandBuffer commandBuffer, uint32_t imageIndex) {
VkCommandBufferBeginInfo beginInfo{};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
//指定我们将如何使用命令缓冲区
beginInfo.flags = 0; // Optional
beginInfo.pInheritanceInfo = nullptr; // Optional
//该pInheritanceInfo参数仅与辅助命令缓冲区相关。它指定从调用主命令缓冲区继承的状态。
if (vkBeginCommandBuffer(commandBuffer, &beginInfo) != VK_SUCCESS) {
throw std::runtime_error("failed to begin recording command buffer!");
}
VkRenderPassBeginInfo renderPassInfo{};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_BEGIN_INFO;
renderPassInfo.renderPass = renderPass;
//我们为每个交换链图像创建了一个帧缓冲区,它被指定为颜色附件。
renderPassInfo.framebuffer = swapChainFramebuffers[imageIndex];
//定义渲染区域的大小。渲染区域定义着色器加载和存储将发生的位置
renderPassInfo.renderArea.offset = {0, 0};
renderPassInfo.renderArea.extent = swapChainExtent;
//透明颜色定义为简单的黑色,不透明度为 100%。
VkClearValue clearColor = {{{0.0f, 0.0f, 0.0f, 1.0f}}};
renderPassInfo.clearValueCount = 1;
renderPassInfo.pClearValues = &clearColor;
//渲染过程现在可以开始了。所有记录命令的函数都可以通过它们的vkCmd前缀来识别。
vkCmdBeginRenderPass(commandBuffer, &renderPassInfo, VK_SUBPASS_CONTENTS_INLINE);
//我们现在可以绑定图形管道:
vkCmdBindPipeline(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, graphicsPipeline);
VkViewport viewport{};
viewport.x = 0.0f;
viewport.y = 0.0f;
viewport.width = static_cast<float>(swapChainExtent.width);
viewport.height = static_cast<float>(swapChainExtent.height);
viewport.minDepth = 0.0f;
viewport.maxDepth = 1.0f;
vkCmdSetViewport(commandBuffer, 0, 1, &viewport);
VkRect2D scissor{};
scissor.offset = {0, 0};
scissor.extent = swapChainExtent;
vkCmdSetScissor(commandBuffer, 0, 1, &scissor);
//现在我们准备发出三角形的绘制命令:
vkCmdDraw(commandBuffer, 3, 1, 0, 0);
//vkCmdEndRenderPass(commandBuffer);
//我们已经完成了命令缓冲区的记录:
if (vkEndCommandBuffer(commandBuffer) != VK_SUCCESS) {
throw std::runtime_error("failed to record command buffer!");
}
}每个命令的第一个参数始终是用于记录命令的命令缓冲区。第二个参数指定我们刚刚提供的渲染过程的细节。最后一个参数控制如何提供渲染过程中的绘图命令。它可以具有以下两个值之一:
VK_SUBPASS_CONTENTS_INLINE:渲染过程命令将嵌入主命令缓冲区本身,不会执行辅助命令缓冲区。VK_SUBPASS_CONTENTS_SECONDARY_COMMAND_BUFFERS:渲染过程命令将从辅助命令缓冲区执行。
13 Rendering and presentation
在这一章,一切都将汇集在一起。我们将编写drawFrame将从主循环调用的函数,以将三角形显示在屏幕上。让我们从创建函数开始并从以下位置调用它 mainLoop:
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
}在 Vulkan 中渲染帧由一组通用步骤组成:
- 等待上一帧完成
- 从交换链获取图像
- 记录将场景绘制到该图像上的命令缓冲区
- 提交记录的命令缓冲区
- 呈现交换链图像
Vulkan的一个核心设计理念是,在GPU上执行的同步是明确的。操作的顺序是由我们使用各种同步原语来定义的,这些原语告诉驱动程序我们希望事情的运行顺序。这意味着许多在GPU上开始执行工作的Vulkan API调用是异步的,这些函数将在操作完成之前返回。
- 从交换链获取图像
- 执行在获取的图像上绘制的命令
- 将该图像呈现到屏幕上进行展示,然后将其返回到交换链
这些事件中的每一个都是使用单个函数调用启动的,但都是异步执行的。函数调用将在操作实际完成之前返回,并且执行顺序也是未定义的。这很不幸,因为每个操作都依赖于前一个操作的完成。
信号量
信号量用于在队列操作之间添加顺序。队列操作是指我们提交给队列的工作,可以是在命令缓冲区中,也可以是从我们稍后将看到的函数中。队列的示例是图形队列和演示队列。信号量用于在同一队列内和不同队列之间对工作进行排序。
Vulkan 中正好有两种信号量,binary 和 timeline
//我们使用信号量来安排队列操作的方式是在一个队列操作中提供相同的信号量作为“信号”信号量
//在另一个队列操作中提供“等待”信号量。
VkCommandBuffer A, B = ... // record command buffers
VkSemaphore S = ... // create a semaphore
//假设我们有信号量 S 和我们想要按顺序执行的队列操作 A 和 B。
操作 A 将在完成执行时“发出信号”信号量 S,而操作 B 将在信号量 S 开始执行之前“等待”它。
// enqueue A, signal S when done - starts executing immediately
vkQueueSubmit(work: A, signal: S, wait: None)
// enqueue B, wait on S to start
vkQueueSubmit(work: B, signal: None, wait: S)
//当操作 A 完成时,信号量 S 将发出信号,而操作 B 直到 S 发出信号后才会开始。
//操作 B 开始执行后,信号量 S 自动重置为未发出信号,允许再次使用。栅栏
栅栏具有类似的用途,因为它用于同步执行,但它用于在 CPU(也称为主机)上排序执行。简单地说,如果主机需要知道 GPU 何时完成某事,我们使用栅栏。
与信号量类似,栅栏处于有信号或无信号状态。每当我们提交要执行的工作时,我们都可以为该工作附加一个栅栏。工作完成后,围栏将发出信号。然后我们可以让主机等待栅栏发出信号,保证在主机继续之前工作已经完成。
//假设我们已经在 GPU 上完成了必要的工作。现在需要将图像从 GPU 传输到主机,然后将内存保存到文件中
VkCommandBuffer A = ... // record command buffer with the transfer
VkFence F = ... // create the fence
//我们有执行传输的命令缓冲区 A 和 fence F
// enqueue A, start work immediately, signal F when done
vkQueueSubmit(work: A, fence: F)
//用 fence F 提交命令缓冲区 A,然后立即告诉主机等待 F 发出信号
vkWaitForFence(F) // blocks execution until A has finished executing
//这会导致主机阻塞,直到命令缓冲区 A 完成执行。因此我们可以安全地让主机将文件保存到磁盘
save_screenshot_to_disk() // can't run until the transfer has finished与信号量示例不同,此示例确实会阻止主机执行。这意味着主机除了等待执行完成外不会做任何事情。对于这种情况,我们必须先确保传输完成,然后才能将屏幕截图保存到磁盘。
通常,除非必要,否则最好不要阻止主机。我们希望为 GPU 和主机提供有用的工作。在栅栏上等待信号不是有用的工作。因此,我们更喜欢使用信号量或其他尚未涵盖的同步原语来同步我们的工作。
信号量用于指定 GPU 上操作的执行顺序,而栅栏用于保持 CPU 和 GPU 彼此同步。
创建同步对象
我们需要一个信号量来表示图像已从交换链获取并准备渲染,另一个信号量表示渲染已完成并且可以进行展示,以及一个栅栏以确保一次只渲染一帧.(需要主机等待。这样我们就不会一次绘制超过一帧)
创建三个类成员来存储这些信号量对象和栅栏对象:
VkSemaphore imageAvailableSemaphore;
VkSemaphore renderFinishedSemaphore;
VkFence inFlightFence;void createSyncObjects() {
//创建信号量
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
//创建围栏需要填写VkFenceCreateInfo:
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphore) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphore) != VK_SUCCESS ||
vkCreateFence(device, &fenceInfo, nullptr, &inFlightFence) != VK_SUCCESS) {
throw std::runtime_error("failed to create semaphores!");
}
}
//号量和栅栏应该在程序结束时清理,当所有命令都已完成并且不再需要同步时:
void cleanup() {
vkDestroySemaphore(device, imageAvailableSemaphore, nullptr);
vkDestroySemaphore(device, renderFinishedSemaphore, nullptr);
vkDestroyFence(device, inFlightFence, nullptr);等待上一帧
在帧的开始,我们希望等到前一帧完成,以便可以使用命令缓冲区和信号量。为此,我们调用vkWaitForFences:函数采用一系列栅栏并在主机上等待任何或所有栅栏在返回之前发出信号。超时参数,我们将其设置为 64 位无符号整数的最大值, UINT64_MAX这可以有效地禁用超时。
void drawFrame() {
vkWaitForFences(device, 1, &inFlightFence, VK_TRUE, UINT64_MAX);
//等待所有的栅栏,但在单个栅栏的情况下,这无关紧要
}一个小问题:在第一帧我们调用
drawFrame(),它立即等待inFlightFence信号。inFlightFence仅在一帧完成渲染后发出信号,但由于这是第一帧,因此没有之前的帧可以发出栅栏信号!因此vkWaitForFences()无限期地阻塞,等待永远不会发生的事情。
在解决这个难题的众多解决方案中,API 中内置了一个巧妙的解决方法。在信号状态下创建围栏,以便第一次调用 vkWaitForFences()立即返回,因为围栏已经发出信号。
为此,我们将VK_FENCE_CREATE_SIGNALED_BIT标志添加到VkFenceCreateInfo:
fenceInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT;
从交换链获取图像
我们需要在函数中做的下一件事drawFrame是从交换链获取图像。回想一下,交换链是一个扩展功能,因此我们必须使用具有命名约定的函数vk*KHR:
void drawFrame() {
uint32_t imageIndex;
//希望从中获取图像的逻辑设备和交换链
//指定图像可用的超时时间(以纳秒为单位)
//使用 64 位无符号整数的最大值意味着我们可以有效地禁用超时。
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphore, VK_NULL_HANDLE, &imageIndex);
//开始绘制的时间点
//最后一个参数指定一个变量来输出已变为可用的交换链图像的索引
}提交命令缓冲区
VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
//指定在执行开始之前要等待的信号量以及要等待的管道阶段
VkSemaphore waitSemaphores[] = {imageAvailableSemaphore};
VkPipelineStageFlags waitStages[] = {VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT};
//指定了写入颜色附件的图形管道阶段
submitInfo.waitSemaphoreCount = 1;
submitInfo.pWaitSemaphores = waitSemaphores;
submitInfo.pWaitDstStageMask = waitStages;
//指定实际提交执行的命令缓冲区
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &commandBuffer;
//指定在命令缓冲区执行完毕后发送信号的信号量signalSemaphoreCount
VkSemaphore signalSemaphores[] = {renderFinishedSemaphore};
submitInfo.signalSemaphoreCount = 1;
submitInfo.pSignalSemaphores = signalSemaphores;
//使用 将命令缓冲区提交到图形队列 vkQueueSubmit
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFence) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}子通道依赖
渲染通道中的子通道会自动处理图像布局转换。这些转换由subpass dependencies控制,它指定子通道之间的内存和执行依赖性。我们现在只有一个子通道,但是这个子通道之前和之后的操作也算作隐式“子通道”。
子通道依赖项在结构中指定VkSubpassDependency。转到 createRenderPass函数并添加一个:
VkSubpassDependency dependency{};
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.dstSubpass = 0;
//两个字段指定依赖项和依赖子通道的索引
//指定要等待的操作以及这些操作发生的阶段
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.srcAccessMask = 0;
//需要等待交换链完成从图像中的读取,然后才能访问它
//等待的操作在颜色附件阶段,涉及颜色附件的写入
dependency.dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;
renderPassInfo.dependencyCount = 1;
renderPassInfo.pDependencies = &dependency;Presentation
绘制框架的最后一步是将结果提交回交换链,使其最终显示在屏幕上。表示是通过函数VkPresentInfoKHR末尾的结构配置的drawFrame。
VkPresentInfoKHR presentInfo{};
presentInfo.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR;
//发生之前要等待的信号量
presentInfo.waitSemaphoreCount = 1;
presentInfo.pWaitSemaphores = signalSemaphores;
//获取将发出信号的信号量并等待它们
//呈现图像的交换链以及每个交换链的图像索引
VkSwapchainKHR swapChains[] = {swapChain};
presentInfo.swapchainCount = 1;
presentInfo.pSwapchains = swapChains;
presentInfo.pImageIndices = &imageIndex;
//VkResult如果演示成功,它允许您指定一个值数组来检查每个单独的交换链
presentInfo.pResults = nullptr; // Optional
//向交换链提交呈现图像的请求
vkQueuePresentKHR(presentQueue, &presentInfo);
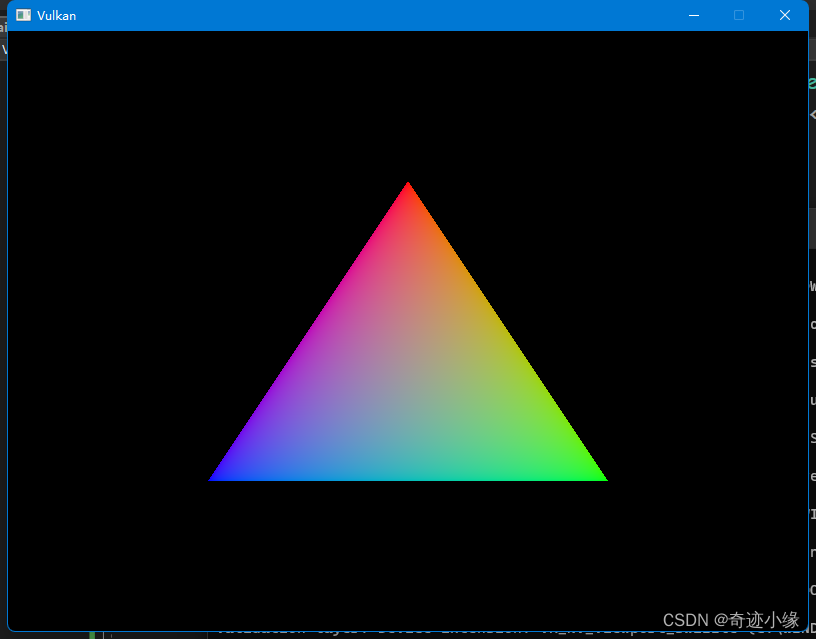
如果到目前为止您所做的一切都是正确的,那么当您运行您的程序时,您现在应该会看到类似于以下内容的内容:
14 Frames in flight
现在我们的渲染循环有一个明显的缺陷。我们需要等待前一帧完成,然后才能开始渲染下一帧,这会导致主机不必要的空闲。
解决这个问题的方法是允许多个帧同时进行中,也就是说,允许一帧的渲染不干扰下一帧的记录。我们如何做到这一点?在渲染期间访问和修改的任何资源都必须复制。因此,我们需要多个命令缓冲区、信号量和栅栏。在后面的章节中,我们还将添加其他资源的多个实例,因此我们将看到这个概念再次出现。
首先在程序顶部添加一个常量,该常量定义应同时处理的帧数:
const int MAX_FRAMES_IN_FLIGHT = 2;std::vector<VkCommandBuffer> commandBuffers;
...
std::vector<VkSemaphore> imageAvailableSemaphores;
std::vector<VkSemaphore> renderFinishedSemaphores;
std::vector<VkFence> inFlightFences;
//每个帧都应该有自己的命令缓冲区、信号量集和栅栏。
void createCommandBuffers() {
commandBuffers.resize(MAX_FRAMES_IN_FLIGHT);
...
allocInfo.commandBufferCount = (uint32_t) commandBuffers.size();
if (vkAllocateCommandBuffers(device, &allocInfo, commandBuffers.data()) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate command buffers!");
}
}
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphores[i]) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphores[i]) != VK_SUCCESS ||
vkCreateFence(device, &fenceInfo, nullptr, &inFlightFences[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create synchronization objects for a frame!");
}
}每次都前进到下一帧:
void drawFrame() {
...
currentFrame = (currentFrame + 1) % MAX_FRAMES_IN_FLIGHT;
}通过使用模 (%) 运算符,我们确保帧索引在每个 MAX_FRAMES_IN_FLIGHT 入队帧之后循环。
15 Swap chain recreation
我们现在的应用程序成功地绘制了一个三角形,但是在某些情况下它还没有正确处理。窗口表面可能会发生变化,从而使交换链不再与它兼容。可能导致这种情况发生的原因之一是窗口大小的变化。我们必须捕捉这些事件并重新创建交换链。
重新创建交换链
创建一个新的 recreateSwapChain 函数,该函数调用 createSwapChain 以及依赖于交换链或窗口大小的对象的所有创建函数。
void recreateSwapChain() {
vkDeviceWaitIdle(device);
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
}- 我们要做的第一件事就是重新创建交换链本身。
- 图像视图需要重新创建,因为它们直接基于交换链图像。
- 渲染通道需要重新创建,因为它取决于交换链图像的格式。
- 在窗口调整大小等操作期间,交换链图像格式很少发生变化,但仍应进行处理。视口和剪刀矩形大小是在创建图形管线时指定的,因此管线也需要重建。
- 可以通过对视口和剪刀矩形使用动态状态来避免这种情况。最后,帧缓冲区直接依赖于交换链图像。
为了确保这些对象的旧版本在重新创建它们之前被清理,我们应该将一些清理代码移动到一个单独的函数中,我们可以从 recreateSwapChain 函数调用该函数。让我们称之为cleanupSwapChain:
void cleanupSwapChain() {
for (size_t i = 0; i < swapChainFramebuffers.size(); i++) {
vkDestroyFramebuffer(device, swapChainFramebuffers[i], nullptr);
}
for (size_t i = 0; i < swapChainImageViews.size(); i++) {
vkDestroyImageView(device, swapChainImageViews[i], nullptr);
}
vkDestroySwapchainKHR(device, swapChain, nullptr);
}
void recreateSwapChain() {
vkDeviceWaitIdle(device);
cleanupSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
}请注意,在
chooseSwapExtent中,我们已经查询了新窗口分辨率以确保交换链图像具有(新的)正确大小,因此无需修改chooseSwapExtent(请记住,我们已经使用glfwGetFramebufferSize获取创建交换链时表面的分辨率(以像素为单位)。
这种方法的缺点是我们需要在创建新的交换链之前停止所有渲染。可以在来自旧交换链的图像上的绘图命令仍在进行中时创建新的交换链。您需要将先前的交换链传递给 VkSwapchainCreateInfoKHR 结构中的 oldSwapChain 字段,并在使用完旧的交换链后立即销毁它。
不匹配或者过时的交换链
现在我们只需要确定何时需要重新创建交换链并调用我们的新 recreateSwapChain 函数。幸运的是,Vulkan 通常只会告诉我们交换链在演示过程中已经不够用了。 vkAcquireNextImageKHR 和 vkQueuePresentKHR 函数可以返回以下特殊值来表明这一点。
VK_ERROR_OUT_OF_DATE_KHR:交换链与表面不兼容,不能再用于渲染。通常发生在窗口调整大小之后。VK_SUBOPTIMAL_KHR:交换链仍可用于成功呈现到表面,但表面属性不再完全匹配。
result = vkQueuePresentKHR(presentQueue, &presentInfo);
if (result == VK_ERROR_OUT_OF_DATE_KHR || result == VK_SUBOPTIMAL_KHR) {
recreateSwapChain();
} else if (result != VK_SUCCESS) {
throw std::runtime_error("failed to present swap chain image!");
}
currentFrame = (currentFrame + 1) % MAX_FRAMES_IN_FLIGHT;vkQueuePresentKHR 函数返回具有相同含义的相同值。在这种情况下,如果交换链不是最理想的,我们也会重新创建它,因为我们想要最好的结果。
修复死锁
如果我们现在尝试运行代码,可能会遇到死锁。调试代码,我们发现应用程序到达 vkWaitForFences 但从未继续通过它。这是因为当 vkAcquireNextImageKHR 返回 VK_ERROR_OUT_OF_DATE_KHR 时,我们重新创建了交换链,然后从 drawFrame 返回。但在此之前,当前帧的栅栏被等待并重置。由于我们立即返回,因此没有提交任何工作执行,并且永远不会发出围栏信号,导致 vkWaitForFences 永远停止。
延迟重置围栏,直到我们确定我们将提交使用它的工作。因此,如果我们提前返回,围栏仍然会发出信号,并且 vkWaitForFences 下次不会死锁我们使用相同的栅栏对象。
drawFrame 的开头现在应该如下所示:
vkWaitForFences(device, 1, &inFlightFences[currentFrame], VK_TRUE, UINT64_MAX);
uint32_t imageIndex;
VkResult result = vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
if (result == VK_ERROR_OUT_OF_DATE_KHR) {
recreateSwapChain();
return;
} else if (result != VK_SUCCESS && result != VK_SUBOPTIMAL_KHR) {
throw std::runtime_error("failed to acquire swap chain image!");
}
// Only reset the fence if we are submitting work
vkResetFences(device, 1, &inFlightFences[currentFrame]);显式处理调整大小
尽管许多驱动程序和平台在调整窗口大小后会自动触发VK_ERROR_OUT_OF_DATE_KHR,但并不保证一定会发生。这就是为什么我们将添加一些额外的代码来显式地处理调整大小。首先添加一个新的成员变量来标记发生了调整大小:
std::vector<VkFence> inFlightFences;
bool framebufferResized = false;然后应该修改 drawFrame 函数以检查此标志:
if (result == VK_ERROR_OUT_OF_DATE_KHR || result == VK_SUBOPTIMAL_KHR || framebufferResized) {
framebufferResized = false;
recreateSwapChain();
} else if (result != VK_SUCCESS) {
...
}在 vkQueuePresentKHR 之后执行此操作很重要,以确保信号量处于一致状态,否则可能永远无法正确等待已发出信号量。现在要实际检测调整大小,我们可以使用 GLFW 框架中的 glfwSetFramebufferSizeCallback 函数来设置回调:
void initWindow() {
glfwInit();
glfwWindowHint(GLFW_CLIENT_API, GLFW_NO_API);
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
glfwSetFramebufferSizeCallback(window, framebufferResizeCallback);
}
//我们创建 static 函数作为回调的原因是因为 GLFW 不知道如何使用正确的 this 指针正确调用成员函数
//该指针指向我们的 HelloTriangleApplication 实例。
static void framebufferResizeCallback(GLFWwindow* window, int width, int height) {
window = glfwCreateWindow(WIDTH, HEIGHT, "Vulkan", nullptr, nullptr);
glfwSetWindowUserPointer(window, this);
//glfwGetWindowUserPointer 从回调中检索此值,以正确设置标志:
glfwSetFramebufferSizeCallback(window, framebufferResizeCallback);
}处理最小化
还有另一种情况,交换链可能会过时,这是一种特殊的窗口大小调整:窗口最小化。这种情况很特殊,因为它会导致帧缓冲区大小为“0”。我们将通过扩展 recreateSwapChain 函数暂停直到窗口再次位于前台来处理这个问题:
void recreateSwapChain() {
int width = 0, height = 0;
glfwGetFramebufferSize(window, &width, &height);
while (width == 0 || height == 0) {
glfwGetFramebufferSize(window, &width, &height);
glfwWaitEvents();
}
vkDeviceWaitIdle(device);
...
}对 glfwGetFramebufferSize 的初始调用会处理大小已经正确且 glfwWaitEvents 没有任何等待的情况。