解决读取超大excel数据时OutOfMemoryError的问题
- 前言
- 关于Excel相关技术
- 场景复现与问题定位
- 问题代码
- 读取50MB40万行数据
- 读取84MB100万行数据
- 解决方案一:xlsx-streamer
- 引入依赖:
- 示例代码:
- 加载数据效果
- 耗费资源对比
- 解决方案二:EasyExcel
- 引入依赖
- 示例代码
前言
最近有个项目在生产环境做数据导入时,发现开始执行导入任务会出现cpu狂飙的情况。几番定位查找发现是在读取excel的时候导致此问题的发生,因此在通常使用的为POI的普通读取,在遇到大数据量excel,50mb大小或数十万行的级别的数据容易导致读取时内存溢出或者cpu飙升。需要注意,本文讨论的是针对xlsx格式的excel文件。
关于Excel相关技术
在Java技术生态圈中,可以进行Excel处理的主流技术包括:Apache POI,JXL,Alibaba EasyExcel等。由于JXL只支持Excel2003以下版本,所以不太常见。
Apache POI:基于DOM方式进行解析,将文件直接加载内存,所以速度较快,适合Excel文件数量不大的应用场景
Alibaba EasyExcel:采用逐行读取的解析模式,将每一行的解析结果以观察者模式通知处理(AnalyEventListener),所以比较适合数据体量较大的Excel文件解析。
场景复现与问题定位
问题代码
这种方式POI会把文件的所有内容都加载到内存中,读取大的excel文件时很容易占用大量内存导致oom的发生
/**
* POI方式读取excel
*
* @param file
*/
public static void readExcelByPoi(File file) {
long start = System.currentTimeMillis();
try (InputStream inp = new FileInputStream(file);
Workbook wb = WorkbookFactory.create(inp)) {
log.info("==读取excel完毕,耗时:{}毫秒,", System.currentTimeMillis() - start);
Sheet sheet = wb.getSheetAt(0);
//更新总数
System.out.println("读取结束行数:" + sheet.getLastRowNum());
} catch (Exception e) {
e.printStackTrace();
}
}
当前引入的poi依赖
<!-- excel工具 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
读取50MB40万行数据
首先在读取excel文件的断点执行之前的cpu和内存的占用分别为50%和42%,上传的excel大小为50MB
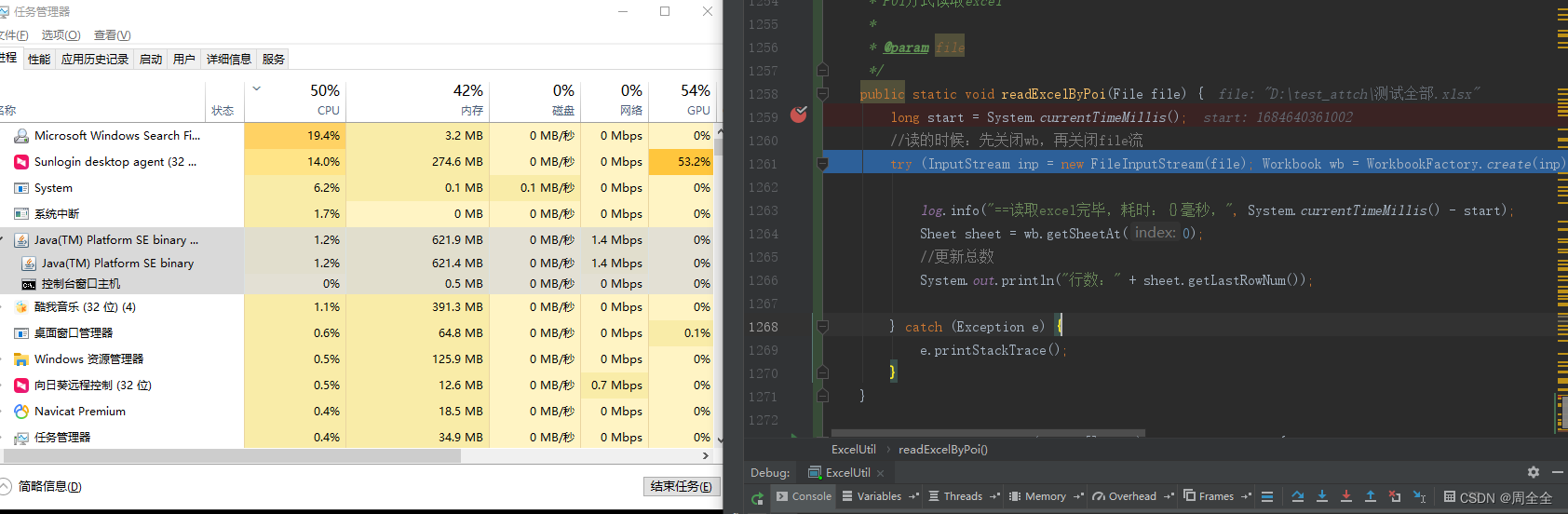
可以看到,读取时cpu飙升到100,而且读取40w行数据耗费了接近100秒
11:40:57.599 [main] INFO com.cxstar.common.utils.poi.ExcelUtil - ==读取excel完毕,耗时:96595毫秒,
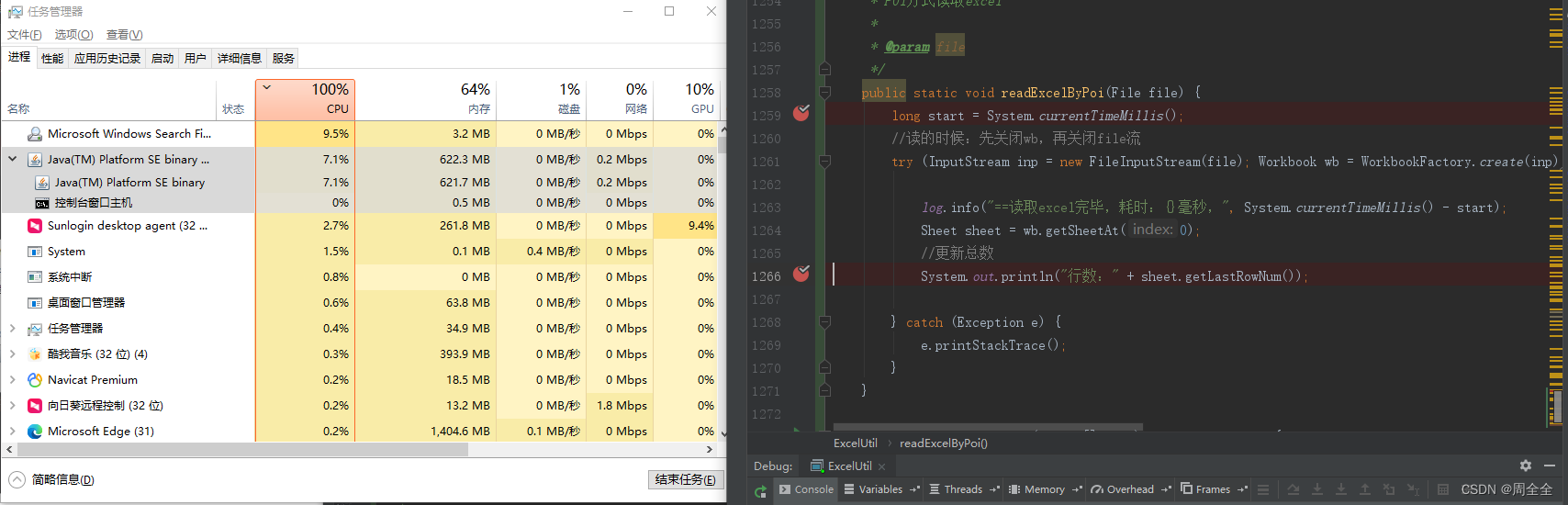
读取84MB100万行数据
直接飙到100%,内存占用65%
而且还直接报错:java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at org.apache.xmlbeans.impl.store.Cur.createElementXobj(Cur.java:260)
at org.apache.xmlbeans.impl.store.Cur$CurLoadContext.startElement(Cur.java:2997)
at org.apache.xmlbeans.impl.store.Locale$SaxHandler.startElement(Locale.java:3164)
at org.apache.xerces.parsers.AbstractSAXParser.startElement(AbstractSAXParser.java:498)
at org.apache.xerces.impl.XMLNSDocumentScannerImpl.scanStartElement(XMLNSDocumentScannerImpl.java:283)
at org.apache.xerces.impl.XMLDocumentFragmentScannerImpl$FragmentContentDispatcher.dispatch(XMLDocumentFragmentScannerImpl.java:1653)
at org.apache.xerces.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:324)
at org.apache.xerces.parsers.XML11Configuration.parse(XML11Configuration.java:890)
at org.apache.xerces.parsers.XML11Configuration.parse(XML11Configuration.java:813)
at org.apache.xerces.parsers.XMLParser.parse(XMLParser.java:108)
at org.apache.xerces.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1198)
at org.apache.xerces.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:564)
at org.apache.xmlbeans.impl.store.Locale$SaxLoader.load(Locale.java:3422)
at org.apache.xmlbeans.impl.store.Locale.parseToXmlObject(Locale.java:1272)
at org.apache.xmlbeans.impl.store.Locale.parseToXmlObject(Locale.java:1259)
at org.apache.xmlbeans.impl.schema.SchemaTypeLoaderBase.parse(SchemaTypeLoaderBase.java:345)
at org.openxmlformats.schemas.spreadsheetml.x2006.main.WorksheetDocument$Factory.parse(Unknown Source)
at org.apache.poi.xssf.usermodel.XSSFSheet.read(XSSFSheet.java:226)
at org.apache.poi.xssf.usermodel.XSSFSheet.onDocumentRead(XSSFSheet.java:218)
at org.apache.poi.xssf.usermodel.XSSFWorkbook.parseSheet(XSSFWorkbook.java:454)
at org.apache.poi.xssf.usermodel.XSSFWorkbook.onDocumentRead(XSSFWorkbook.java:419)
at org.apache.poi.ooxml.POIXMLDocument.load(POIXMLDocument.java:184)
at org.apache.poi.xssf.usermodel.XSSFWorkbook.<init>(XSSFWorkbook.java:288)
at org.apache.poi.xssf.usermodel.XSSFWorkbookFactory.createWorkbook(XSSFWorkbookFactory.java:97)
at org.apache.poi.xssf.usermodel.XSSFWorkbookFactory.createWorkbook(XSSFWorkbookFactory.java:147)
at org.apache.poi.xssf.usermodel.XSSFWorkbookFactory$$Lambda$2/1073533248.apply(Unknown Source)
at org.apache.poi.ss.usermodel.WorkbookFactory.create(WorkbookFactory.java:256)
at org.apache.poi.ss.usermodel.WorkbookFactory.create(WorkbookFactory.java:221)
at com.cxstar.common.utils.poi.ExcelUtil.readExcelByPoi(ExcelUtil.java:1209)
at com.cxstar.common.utils.poi.ExcelUtil.main(ExcelUtil.java:1224)
解决方案一:xlsx-streamer
采用分段缓存的方式加载数据到内存中,此种方式在创建Workbook对象时借助xlsx-streamer(StreamingReader) 来创建一个缓冲区域批量地读取文件 ,因此不会将整个文件实例化到对象当中
引入依赖:
<!-- excel工具 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
<!-- 读取大量excel数据时使用 -->
<dependency>
<groupId>com.monitorjbl</groupId>
<artifactId>xlsx-streamer</artifactId>
<version>2.1.0</version>
</dependency>
示例代码:
/**
* 大批量数据读取 十万级以上
* 思路:采用分段缓存加载数据,防止出现OOM的情况
*
* @param file
* @throws Exception
*/
public static void readLagerExcel(File file) throws Exception {
InputStream inputStream = new FileInputStream(file);
long start = System.currentTimeMillis();
try (Workbook workbook = StreamingReader.builder()
.rowCacheSize(10 * 10) //缓存到内存中的行数,默认是10
.bufferSize(1024 * 4) //读取资源时,缓存到内存的字节大小,默认是1024
.open(inputStream)) { //打开资源,可以是InputStream或者是File,注意:只能打开.xlsx格式的文件
Sheet sheet = workbook.getSheetAt(0);
log.info("==读取excel完毕,耗时:{}毫秒,", System.currentTimeMillis() - start);
//遍历所有的行
for (Row row : sheet) {
System.out.println("开始遍历第" + row.getRowNum() + "行数据:");
//遍历所有的列
for (Cell cell : row) {
System.out.print(cell.getStringCellValue() + " ");
}
System.out.println(" ");
}
//总数
System.out.println("读取结束行数:" + sheet.getLastRowNum());
}
}
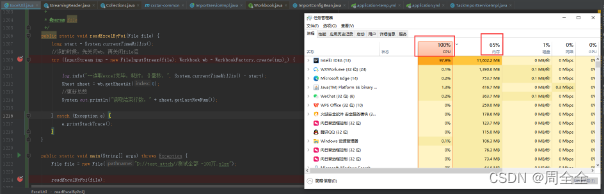
加载数据效果
40万级别数据近花费5.4秒
13:58:09.160 [main] INFO com.cxstar.common.utils.poi.ExcelUtil - ==读取excel完毕,耗时:5477毫秒,
行数:412845
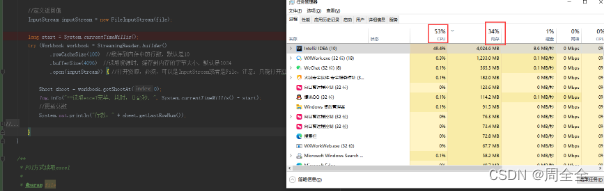
百万级别花费6.75秒
14:37:24.235 [main] INFO com.cxstar.common.utils.poi.ExcelUtil - ==读取excel完毕,耗时:6751毫秒,
读取结束行数:1000000
耗费资源对比
| 数据量 | 常规poi | 分段缓存 |
|---|---|---|
| 40万 | 96s,cpu100%,内存64% | 5.4s,cpu57%,内存34% |
| 100万 | OOM | 6.75s,cpu58%,内存43% |
解决方案二:EasyExcel
使用EasyExcel解决大文件Excel内存溢出的问题,基于POI进行封装优化,可以在不考虑性能、内存的等因素的情况下,快速完成Excel的读、写等功能。
官网: https://easyexcel.opensource.alibaba.com/
github:https://github.com/alibaba/easyexcel
引入依赖
<!-- EasyExcel 大数据量excel读写 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.1.0</version>
</dependency>
示例代码
仅做简单读取示例,详细文档api可参考:读Excel|EasyExcel
/**
* EasyExcel方式读取excel
* <p>
* 读取并封装为对象
*
* @param file
*/
public static void readExcelByEasyExcel(File file) {
long start = System.currentTimeMillis();
List<ExcelData> excelDataList = EasyExcel.read(file).head(ExcelData.class).sheet(0).doReadSync();
excelDataList.stream().forEach(x -> System.out.println(x.toString()));
log.info("==读取excel完毕,耗时:{}毫秒,", System.currentTimeMillis() - start);
}
/**
* EasyExcel方式读取excel
* <p>
* 不指定head类
*
* @param file
*/
public static void readExcelByEasyExcel1(File file) {
long start = System.currentTimeMillis();
List<Map<Integer, String>> listMap = EasyExcel.read(file).sheet(0).doReadSync();
listMap.stream().forEach(x -> System.out.println(JSON.toJSONString(x)));
log.info("==读取excel完毕,耗时:{}毫秒,", System.currentTimeMillis() - start);
}