文章目录
- 前言
- 背景
- 官网文档
- 概述
- 元数据
- 解析器
- 运行时的实现
- 自定义扩展点
- 工厂类
- Source
- 扩展Sink和编码与解码
- 自定义flink-http-connector
- SQL示例
- 具体代码
- pom依赖
- HttpTableFactory
- HttpTableSource
- HttpSourceFunction
- HttpClientUtil
- 最后
- 参考资料
前言
结合官网文档和自定义实现一个flink-http-connector,来学习总结Flink用户自定义连接器(Table API Connectors)。
背景
前段时间有个需求:需要Flink查询API接口,将返回的数据转为Flink Table,然后基于Table进行后面的计算。这个需求可以写Flink代码实现:使用HttpClient API请求接口返回数据,然后将返回的数据转为DataStream,最后再将DataStream转为Table。我想了一下是不是可以通过SQL的形式实现这种需求,于是在网上查了一下,还真有。Star比较多的项目:https://github.com/getindata/flink-http-connector.git,但是它要求Java 11,并且它的Http Source只支持Lookup Joins,限制太多,并不能满足我的需求。所以最终又尝试学习了自己写自定义的Table API Connectors,这样可以比较灵活的实现需求。
官网文档
官网文档地址:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/sourcessinks/,官网文档详细介绍了自定义连接器的概念、扩展点并给出了一个完整的代码实例,实例实现了自定义socket连接器。本文摘录一部分官方文档,便于自己理解。
动态表是 Flink Table & SQL API的核心概念,用于统一有界和无界数据的处理。
动态表只是一个逻辑概念,因此 Flink 并不拥有数据。相应的,动态表的内容存储在外部系统( 如数据库、键值存储、消息队列 )或文件中。
动态 sources 和动态 sinks 可用于从外部系统读取数据和向外部系统写入数据。在文档中,sources 和 sinks 常在术语连接器 下进行总结。
Flink 为 Kafka、Hive 和不同的文件系统提供了预定义的连接器。有关内置 table sources 和 sinks 的更多信息,请参阅连接器部分:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/overview/
概述
实心箭头展示了在转换过程中对象如何从一个阶段到下一个阶段转换为其他对象。
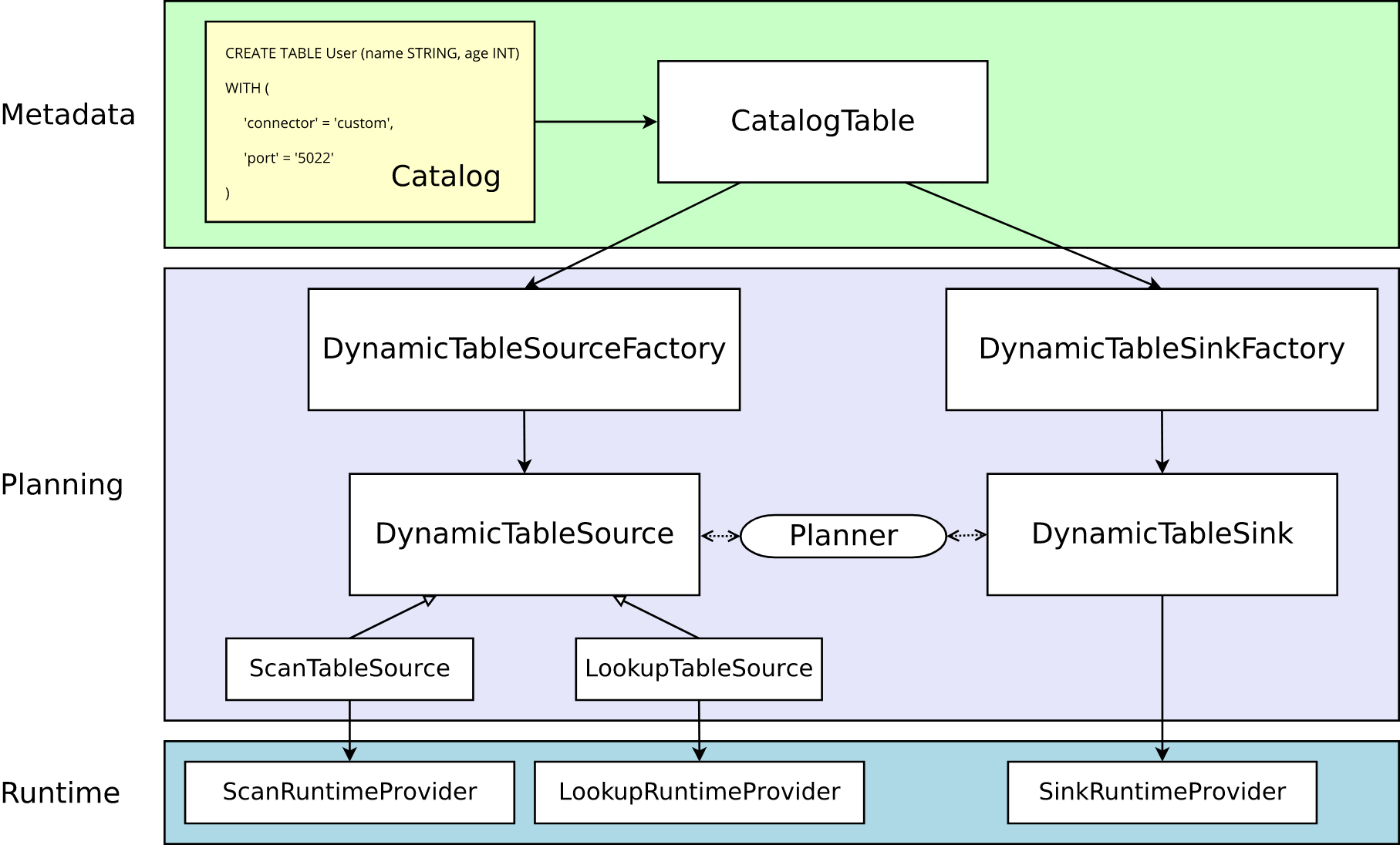
元数据
Table API 和 SQL 都是声明式 API。这包括表的声明。因此,执行 CREATE TABLE 语句会导致目标 catalog 中的元数据更新。
对于大多数 catalog 实现,外部系统中的物理数据不会针对此类操作进行修改。特定于连接器的依赖项不必存在于类路径中。在 WITH 子句中声明的选项既不被验证也不被解释。
动态表的元数据( 通过 DDL 创建或由 catalog 提供 )表示为 CatalogTable 的实例。必要时,表名将在内部解析为 CatalogTable。
解析器
在解析和优化以 table 编写的程序时,需要将 CatalogTable 解析为 DynamicTableSource( 用于在 SELECT 查询中读取 )和 DynamicTableSink( 用于在 INSERT INTO 语句中写入 )。
DynamicTableSourceFactory 和 DynamicTableSinkFactory 提供连接器特定的逻辑,用于将 CatalogTable 的元数据转换为 DynamicTableSource 和 DynamicTableSink 的实例。在大多数情况下,以工厂模式设计的目的是验证选项(例如示例中的 ‘port’ = ‘5022’ ),配置编码解码格式( 如果需要 ),并创建表连接器的参数化实例。
默认情况下,DynamicTableSourceFactory 和 DynamicTableSinkFactory 的实例是使用 Java的 [Service Provider Interfaces (SPI)] (https://docs.oracle.com/javase/tutorial/sound/SPI-intro.html) 发现的。 connector 选项(例如示例中的 ‘connector’ = ‘custom’)必须对应于有效的工厂标识符。
尽管在类命名中可能不明显,但 DynamicTableSource 和 DynamicTableSink 也可以被视为有状态的工厂,它们最终会产生具体的运行时实现来读写实际数据。
规划器使用 source 和 sink 实例来执行连接器特定的双向通信,直到找到最佳逻辑规划。取决于声明可选的接口( 例如 SupportsProjectionPushDown 或 SupportsOverwrite),规划器可能会将更改应用于实例并且改变产生的运行时实现。
运行时的实现
一旦逻辑规划完成,规划器将从表连接器获取 runtime implementation。运行时逻辑在 Flink 的核心连接器接口中实现,例如 InputFormat 或 SourceFunction。
这些接口按另一个抽象级别被分组为 ScanRuntimeProvider、LookupRuntimeProvider 和 SinkRuntimeProvider 的子类。
例如,OutputFormatProvider( 提供 org.apache.flink.api.common.io.OutputFormat )和 SinkFunctionProvider( 提供org.apache.flink.streaming.api.functions.sink.SinkFunction)都是规划器可以处理的 SinkRuntimeProvider 具体实例。
自定义扩展点
工厂类
需要实现 org.apache.flink.table.factories.DynamicTableSourceFactory 接口完成一个工厂类,来生产 DynamicTableSource 类。比如:
public class HttpTableFactory implements DynamicTableSourceFactory {
...
我们需要在META-INF/services/org.apache.flink.table.factories.Factory中添加自定义实现的工厂类,如下图:

注意:图中的META-INF.services实际为META-INF/services
默认情况下,Java 的 SPI 机制会自动识别这些工厂类,同时将 connector 配置项作为工厂类的”标识符“。
一个工厂类可以同时实现Source和Sink,比如HoodieTableFactory
public class HoodieTableFactory implements DynamicTableSourceFactory, DynamicTableSinkFactory {
...
Source
按照定义,动态表是随时间变化的。
在读取动态表时,表中数据可以是以下情况之一:
- changelog 流(支持有界或无界),在 changelog 流结束前,所有的改变都会被源源不断地消费,由 ScanTableSource 接口表示。
- 处于一直变换或数据量很大的外部表,其中的数据一般不会被全量读取,除非是在查询某个值时,由 LookupTableSource 接口表示。
一个类可以同时实现这两个接口,Planner 会根据查询的 Query 选择相应接口中的方法。
示例:
public class HttpTableSource implements ScanTableSource {
...
可以实现更多的功能接口来优化数据源,比如实现 SupportsProjectionPushDown 接口,这样在运行时在 source 端就处理数据。在 org.apache.flink.table.connector.source.abilities 包下可以找到各种功能接口,更多内容可查看https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/sourcessinks/#source-abilities。比如HoodieTableSource
public class HoodieTableSource implements
ScanTableSource,
SupportsPartitionPushDown,
SupportsProjectionPushDown,
SupportsLimitPushDown,
SupportsFilterPushDown {
...
实现ScanTableSource接口的类必须能够生产Flink内部数据结构,因此每条记录都会按照org.apache.flink.table.data.RowData 的方式进行处理。所以我们可能还要一个类来生产RowData类型的数据,比如实现RichSourceFunction<RowData>
public class HttpSourceFunction extends RichSourceFunction<RowData> {
...
扩展Sink和编码与解码
可以参考官网:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/sourcessinks/#%E5%8A%A8%E6%80%81%E8%A1%A8%E7%9A%84-sink-%E7%AB%AF
自定义flink-http-connector
自定义flink-http-connector,实现SQL读http接口数据,代码实现参考博文:https://www.cnblogs.com/Springmoon-venn/p/15392511.html,其实大部分和官网实例代码是一样的,不一样的地方是需要HttpSourceFunction中实现通过HttpClient读取接口并返回数据。我在参考博文的基础上添加了两个配置项http.mode和read.streaming.enabled分别代表接口的方式、是否流读。接口方式支持post、get两种。
完整代码地址:https://github.com/dongkelun/flink-learning/tree/master/flink-http-connector
Flink版本 1.15
SQL示例
需要将项目打包,并放到$FLINK_HOME/lib下
Jar包地址:https://fast.uc.cn/s/a553136362ac4
create table cust_http_get_source(
id int,
name string
)WITH(
'connector' = 'http',
'http.url' = 'http://mock.apifox.cn/m1/2518376-0-default/test/flink/get/order',
'format' = 'json'
);
create table cust_http_post_source(
id int,
name string
)WITH(
'connector' = 'http',
'http.url' = 'http://mock.apifox.cn/m1/2518376-0-default/test/flink/post/order',
'http.mode' = 'post',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '10',
'format' = 'json'
);
示例中的接口是我使用apifox在线mock出来的可以直接调用
参数解释:
- http.mode 调用接口模式、支持post、get两种,默认get
- read.streaming.enabled 是否流读,默认false
- read.streaming.check-interval 流读间隔,单位秒,默认60s
其实read.streaming.enabled和read.streaming.check-interval是拷贝的Hudi的源码配置
结果:
select * from cust_http_post_source;

具体代码
pom依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.14</version>
</dependency>
</dependencies>
HttpTableFactory
package com.dkl.flink.connector.http;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DeserializationFormatFactory;
import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.types.DataType;
import java.util.HashSet;
import java.util.Set;
public class HttpTableFactory implements DynamicTableSourceFactory {
// 定义所有配置项
// define all options statically
public static final ConfigOption<String> URL = ConfigOptions.key("http.url")
.stringType()
.noDefaultValue();
public static final ConfigOption<String> MODE = ConfigOptions.key("http.mode")
.stringType()
.defaultValue("get");
public static final ConfigOption<Boolean> READ_AS_STREAMING = ConfigOptions
.key("read.streaming.enabled")
.booleanType()
.defaultValue(false)// default read as batch
.withDescription("Whether to read as streaming source, default false");
public static final ConfigOption<Long> READ_STREAMING_CHECK_INTERVAL = ConfigOptions.key("read.streaming.check-interval")
.longType()
.defaultValue(60L)// default 1 minute
.withDescription("Check interval for streaming read of SECOND, default 1 minute");
@Override
public String factoryIdentifier() {
// 用于匹配: `connector = '...'`
return "http"; // used for matching to `connector = '...'`
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(URL);
// 解码的格式器使用预先定义的配置项
options.add(FactoryUtil.FORMAT); // use pre-defined option for format
return options;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(MODE);
options.add(READ_AS_STREAMING);
options.add(READ_STREAMING_CHECK_INTERVAL);
return options;
}
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
// 使用提供的工具类或实现你自己的逻辑进行校验
// either implement your custom validation logic here ...
// or use the provided helper utility
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// 找到合适的解码器
// discover a suitable decoding format
final DecodingFormat<DeserializationSchema<RowData>> decodingFormat = helper.discoverDecodingFormat(
DeserializationFormatFactory.class,
FactoryUtil.FORMAT);
// 校验所有的配置项
// validate all options
helper.validate();
// 获取校验完的配置项
// get the validated options
final ReadableConfig options = helper.getOptions();
final String url = options.get(URL);
final String mode = options.get(MODE);
final boolean isStreaming = options.get(READ_AS_STREAMING);
final long interval = options.get(READ_STREAMING_CHECK_INTERVAL);
// 从 catalog 中抽取要生产的数据类型 (除了需要计算的列)
// derive the produced data type (excluding computed columns) from the catalog table
final DataType producedDataType =
context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();
// 创建并返回动态表 source
// create and return dynamic table source
return new HttpTableSource(url, mode, isStreaming, interval, decodingFormat, producedDataType);
}
}
HttpTableSource
package com.dkl.flink.connector.http;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.connector.source.ScanTableSource;
import org.apache.flink.table.connector.source.SourceFunctionProvider;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
public class HttpTableSource implements ScanTableSource {
private final String url;
private final String mode;
private final boolean isStreaming;
private final long interval;
private final DecodingFormat<DeserializationSchema<RowData>> decodingFormat;
private final DataType producedDataType;
public HttpTableSource(
String hostname,
String mode,
boolean isStreaming,
long interval,
DecodingFormat<DeserializationSchema<RowData>> decodingFormat,
DataType producedDataType) {
this.url = hostname;
this.mode = mode;
this.isStreaming = isStreaming;
this.interval = interval;
this.decodingFormat = decodingFormat;
this.producedDataType = producedDataType;
}
@Override
public ChangelogMode getChangelogMode() {
// 在我们的例子中,由解码器来决定 changelog 支持的模式
// 但是在 source 端指定也可以
// in our example the format decides about the changelog mode
// but it could also be the source itself
return decodingFormat.getChangelogMode();
}
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
// 创建运行时类用于提交给集群
// create runtime classes that are shipped to the cluster
final DeserializationSchema<RowData> deserializer = decodingFormat.createRuntimeDecoder(
runtimeProviderContext,
producedDataType);
final SourceFunction<RowData> sourceFunction = new HttpSourceFunction(url, mode, isStreaming, interval, deserializer);
return SourceFunctionProvider.of(sourceFunction, !isStreaming);
}
@Override
public DynamicTableSource copy() {
return new HttpTableSource(url, mode, isStreaming, interval, decodingFormat, producedDataType);
}
@Override
public String asSummaryString() {
return "Http Table Source";
}
}
HttpSourceFunction
package com.dkl.flink.connector.http;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.metrics.Counter;
import org.apache.flink.metrics.SimpleCounter;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.data.RowData;
import java.util.concurrent.TimeUnit;
/**
* http table source
*/
public class HttpSourceFunction extends RichSourceFunction<RowData> {
private volatile boolean isRunning = true;
private String url;
private String mode;
private boolean isStreaming;
private long interval;
private DeserializationSchema<RowData> deserializer;
// count out event
private transient Counter counter;
public HttpSourceFunction(String url, String mode, boolean isStreaming,
long interval, DeserializationSchema<RowData> deserializer) {
this.url = url;
this.mode = mode;
this.isStreaming = isStreaming;
this.interval = interval;
this.deserializer = deserializer;
}
@Override
public void open(Configuration parameters) {
counter = new SimpleCounter();
this.counter = getRuntimeContext()
.getMetricGroup()
.counter("http-counter");
}
@Override
public void run(SourceContext<RowData> ctx) {
if (isStreaming) {
while (isRunning) {
try {
// 接收http消息
// receive http message
String message = mode.equalsIgnoreCase("get") ? HttpClientUtil.get(url) : HttpClientUtil.post(url, "");
// 解码并处理记录
// deserializer message
ctx.collect(deserializer.deserialize(message.getBytes()));
this.counter.inc();
TimeUnit.SECONDS.sleep(interval);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
} else {
try {
// receive http message
String message = mode.equalsIgnoreCase("get") ? HttpClientUtil.get(url) : HttpClientUtil.post(url, "");
// deserializer message
ctx.collect(deserializer.deserialize(message.getBytes()));
this.counter.inc();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
@Override
public void cancel() {
isRunning = false;
}
}
HttpClientUtil
package com.dkl.flink.connector.http;
import com.dkl.flink.utils.StringUtils;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
public class HttpClientUtil {
public static String post(String uri, String json) throws Exception {
HttpPost httpPost = new HttpPost(uri);
CloseableHttpClient client = HttpClients.createDefault();
StringEntity entity = StringUtils.isNullOrEmpty(json) ? new StringEntity("utf-8") : new StringEntity(json, "utf-8");//解决中文乱码问题
entity.setContentEncoding("UTF-8");
entity.setContentType("application/json");
httpPost.setEntity(entity);
HttpResponse resp = client.execute(httpPost);
String respContent = EntityUtils.toString(resp.getEntity(), "UTF-8");
if (resp.getStatusLine().getStatusCode() == 200) {
return respContent;
} else {
throw new RuntimeException(String.format("调用接口%s失败:%s", uri, respContent));
}
}
public static String get(String uri) throws Exception {
HttpGet httpGet = new HttpGet(uri);
CloseableHttpClient client = HttpClients.createDefault();
HttpResponse resp = client.execute(httpGet);
String respContent = EntityUtils.toString(resp.getEntity(), "UTF-8");
if (resp.getStatusLine().getStatusCode() == 200) {
return respContent;
} else {
throw new RuntimeException(String.format("调用接口%s失败:%s", uri, respContent));
}
}
}
最后
其实我最终还是写代码来实现读取Http接口再转为Flink Table,因为我们的需求比较复杂,一个接口返回的数据需要转化为很多张表,且表的个数、Schema都不固定。但是学会了自定义连接器有利于我们加深对Flink的理解和技术掌握,对于后面有需求的也可以轻松扩展,而且对于理解Flink Hudi Connector源码很有帮助。
参考资料
- https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/sourcessinks/
- https://www.cnblogs.com/Springmoon-venn/p/15392511.html
- https://www.cnblogs.com/Ning-Blog/p/16714511.html