目录
前言
使用chat-gpt过程中有哪些痛点
1.无法理解人类情感和主观性
2.上下文丢失
3.约定被打断
那如何去解决这个痛点
Transformer(RMT)怎么去实现的
1.Transformer 模型
2.RMT模型
3.计算推理速率
4.渐进学习能力
总结
写到最后
大家好,我是AI大侠,AI领域的专业博主
前言
ChatGPT已经成为了一款备受欢迎的工具,它可以帮助用户解答问题、写代码、翻译,甚至可以通过它学习更多行业的知识。然而,博主在使用ChatGPT时会发现它还不够智能,有时候不能够完全理解用户的意思,答非所问,下面是博主在使用中遇到的痛点
使用chat-gpt过程中有哪些痛点

1.无法理解人类情感和主观性
尽管ChatGPT可以根据上下文理解用户的输入,但它仍然无法真正了解用户的意图,ChatGPT只能根据输入数据和算法进行分析和回答,无法真正理解人类的情感和主观性。这种局限性可能导致一些误解和问题。
2.上下文丢失
与ChatGPT进行对话时,它能够记住上下文,并在后续回答中考虑之前的内容。但是,博主在使用过程中经常会出现ChatGPT忘记之前的对话,这可能是由于单次请求中Token数量的限制或是ChatGPT会话长度的限制所导致的。
3.约定被打断
如果在会话中如果有很多其他的问答,ChatGPT可能会在继续下一步时忘记之前的约定,需要再次约定才会保持下去
那如何去解决这个痛点
这几个痛点我想使用过gpt的小伙伴都深有体会,那如何去解决这些问题呢。其实openAI已经给出了答案。
在发布gpt4的时候,最大的变化除了新数据模型的发布,还有一个重要的技术点更新:上下文token默认为8K 最长32k(约50页文本) 这代表可以可以处理更长的对话 以及 更深层次的语义分析。这也是gpt4更智能好用的原因。
但如果把这个token提升到200万个,那又会发生什么,
AI 模型使用的是非结构化文本,常用 Token 表示,以 GPT 模型为例,1000 个 Token 约等于 750 个英文单词
一篇在AI界热论的论文给出了答案,《Scaling Transformer to 1M tokens and beyond with RMT》它可以把Transformer 的 Token 上限扩展至 100 万,甚至更多。
Transformer(RMT)怎么去实现的
1.Transformer 模型

Transformer 是一种神经网络模型,是迄今为止最新和最强大的模型之一,常用于处理上下文学习语义含义。
我们来看看gpt4的上下文处理模型为什么只能达到8-32k,因为transformer 的可输入长度取决于内存大小,这意味着实现太长的token不现实,Transformer 存在一个关键问题,即其注意力操作的二次复杂度,这导致将大模型应用于处理较长序列变得越来越困难。然而,通过利用特殊的记忆 token 实现记忆机制的 Recurrent Memory Transformer(RMT)模型,有效上下文长度能够增长到百万级,这带来了新的发展前景。
2.RMT模型
RMT 全称Recurrent Memory Transformer(递归记忆Transformer)
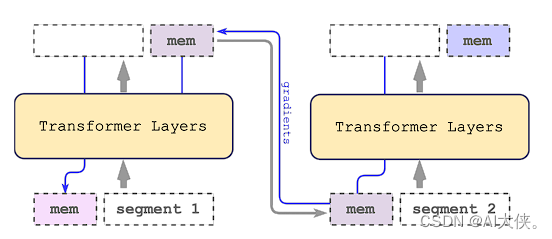
递归记忆Transformer(RMT)是一种基于记忆机制的序列建模架构,用于存储和处理序列数据中的局部和全局信息,并通过递归传递信息来处理长序列中的段之间的依赖关系。
相较于标准Transformer模型的实施,RMT仅通过对输入和输出序列进行修改而无需修改底层模型架构。模型通过训练过程中的记忆操作和序列表示处理来掌控记忆机制的行为。
具体而言,RMT采用记忆token的方式将记忆信息添加到输入序列中,从而为模型提供额外的容量,以处理与输入序列中任意元素无直接关联的信息。为了应对长序列的挑战,RMT将序列分割为不同的段,并通过记忆传递机制将上一段的记忆状态传递到当前段。在训练过程中,梯度通过记忆传递的路径从当前段向前一段流动,从而实现信息的回传和更新记忆状态的目的。
这意味着扩展了token的数量,如果达到理想的200万,我们可以将整部小说甚至更多内容输入到GPT中,而无需依赖上下文来理解用户的信息。这种改进使得GPT能够更准确地处理输入,并提供更精准的回复。现在,试想一下,如果我将整篇《红楼梦》输入到GPT中,是否可以让它帮我续写这个经典作品呢?
3.计算推理速率
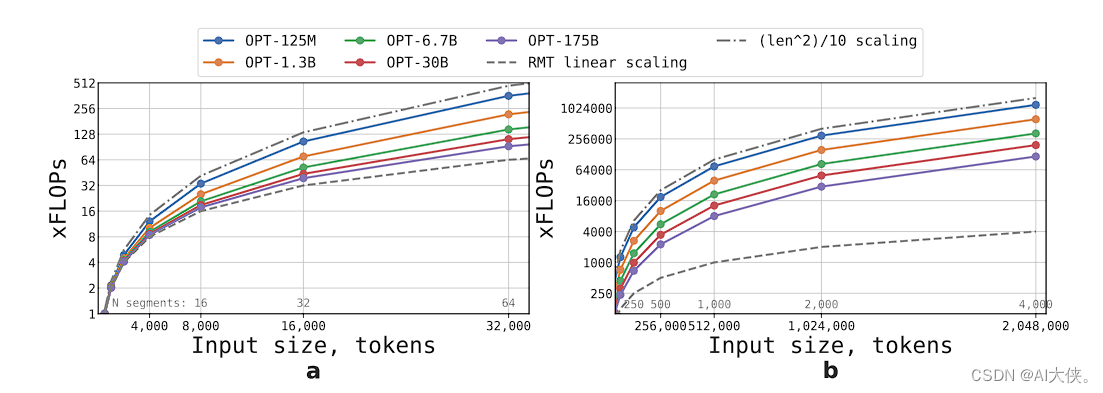
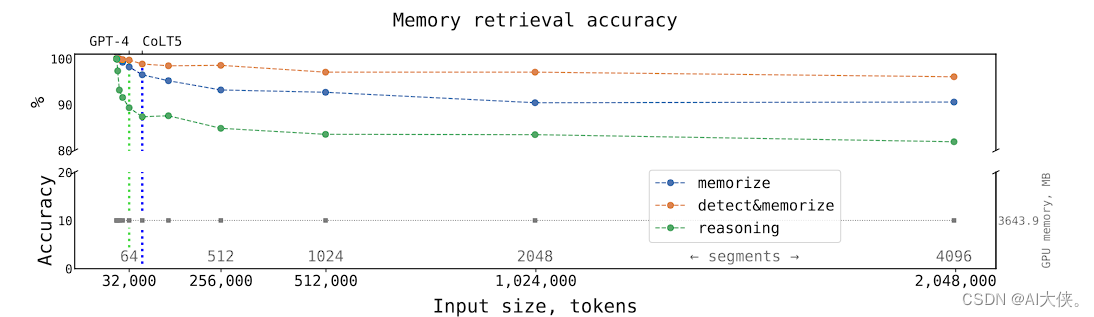
从论文的计算结果中可以很直观地观察到,推理时间与输入序列长度呈线性关系。
在处理包含多个片段的大型序列时,递归记忆Transformer(RMT)模型可能比非循环模型更有效率。
这意味着在GPT模型中输入更多内容,可以让模型更深入地理解用户的意图,从而提供更准确的答复。
如果将自己的聊天信息和朋友圈动态等数据导入GPT模型,并让它进行理解和吸收,是否能够快速生成一个完整的虚拟人格呢?如果token达到这个量级 完全是可实现的,这就有些恐怖了
4.渐进学习能力
论文中还指出,随着输入数量的增加,机器学习模型学习到的结果也变得更加准确。
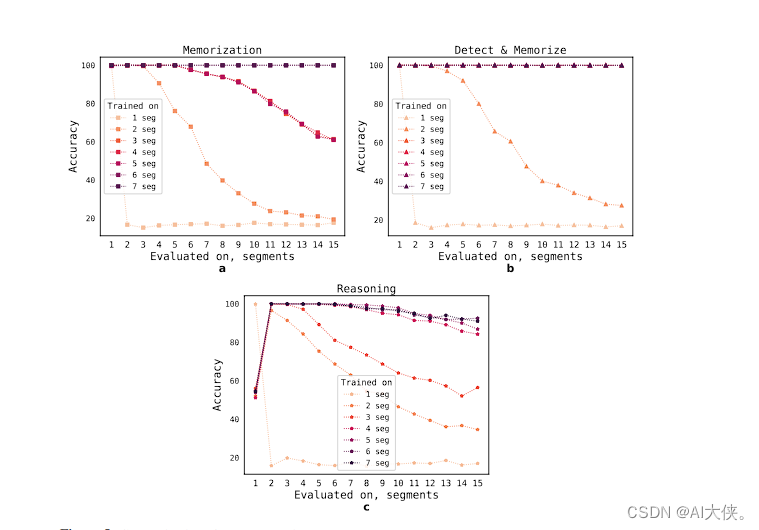
这意味着输入更多的数据可以显著提升模型的性能和预测准确度。
总结
这项技术将使得ChatGPT的能力上限被突破。这也让ChatGPT的痛点得以解决,使得它更完美。
我们甚至可以将整个项目的代码交给GPT,并明确告诉它我们的需求,它将能够直接开始处理后续需求、修改代码并进行优化以及后面的需求迭代。
写到最后
每天在AI领域都有令人震撼的进展,各种新技术层出不穷。有幸生活在这个充满创新的时代,你准备好了吗
AI是一个充满机遇和挑战的领域,
AI时代已经到来,AI真的会取代我们吗?
你还不主动了解AI?
你还在为跟同事聊AI插不上话吗?
那请关注大侠,带你了解AI行业第一动态。