目录
一、CVPR
1.CrowdCLIP:基于视觉-语言模型的无监督人群计数
CrowdCLIP: Unsupervised Crowd Counting via Vision-Language Model
2.Beyond mAP:更好地评估实例分割
Beyond mAP: Re-evaluating and Improving Performance in Instance Segmentation with Semantic Sorting and Contrastive Flow
3.基于冲突的交叉视图一致性的半监督语义分割(无代码)
Conflict-Based Cross-View Consistency for Semi-Supervised Semantic Segmentation
4.提供任意模态语义分割(无代码)
Delivering Arbitrary-Modal Semantic Segmentation
5.弱监督语义分割的token对比(代码已公布)
Token Contrast for Weakly-Supervised Semantic Segmentation
6. CutLER(Cut-and-LEaRn):一种用于训练无监督目标检测和实例分割模型(无代码)
Cut and learn for unsupervised object detection and instance segmentation
7.基础模型驱动语义分割的弱增量学习(无代码)
Cut and learn for unsupervised object detection and instance segmentation
二、可能会感兴趣的
1.POMP:用于开放词汇视觉识别的20000类Prompt预训练
2.InterFormer:实时交互式图像分割
InterFormer: Real-time Interactive Image Segmentation
3.SALUDA :基于Surface的自动驾驶激光雷达无监督域自适应
SALUDA: Surface-based Automotive Lidar Unsupervised Domain Adaptation
4.SegGPT:分割上下文中的一切
Seggpt: Segmenting everything in context
5.谷歌提出:文本到图像扩散模型的零微调图像定制的Taming编码器
Taming Encoder for Zero Fine-tuning Image Customization with Text-to-Image Diffusion Models
三、医学图像分割相关
1.BerDiff:用于医学图像分割的条件伯努利扩散模型
2.(CVPR2023)基于扩散模型的Ambiguous医学图像分割
Ambiguous Medical Image Segmentation using Diffusion Models
3.SPIRiT-Diffusion:用于加速MRI的自一致性驱动扩散模型
Spirit-diffusion: Self-consistency driven diffusion model for accelerated mri
4.视频预训练促进胸部CT任务的3D深度学习
Video Pretraining Advances 3D Deep Learning on Chest CT Tasks
5.(CVPR2023)无标记肝肿瘤分割(代码以公布)
6.(CVPR2023)基于定向连接的医学图像分割(代码以公布)
Directional Connectivity-based Segmentation of Medical Images
7.(CVPR2023)用于半监督医学图像分割的双向复制粘贴(代码以公布)
8.(CVPR2023)通过客户贡献估计进行公平联合医学图像分割(代码以公布)
9.(CVPR2023)使用扩散模型的模糊医学图像分割(代码以公布)
10.(CVPR2023)正交注释有利于几乎受监督的医学图像分割(代码以公布)
Orthogonal Annotation Benefits Barely-supervised Medical Image Segmentation
11.(CVPR2023)MagicNet:通过 Magic-Cube 分区和恢复进行半监督多器官分割(代码以公布)
四、其他
1.Segment Anything
Segment anything
2.RFAConv,感受野注意力模块(代码还未公开)
RFAConv: Innovating Spatital Attention and Standard Convolutional Operation
一、CVPR
1.CrowdCLIP:基于视觉-语言模型的无监督人群计数
CrowdCLIP: Unsupervised Crowd Counting via Vision-Language Model
2.Beyond mAP:更好地评估实例分割
Beyond mAP: Re-evaluating and Improving Performance in Instance Segmentation with Semantic Sorting and Contrastive Flow

3.基于冲突的交叉视图一致性的半监督语义分割(无代码)
Conflict-Based Cross-View Consistency for Semi-Supervised Semantic Segmentation
半监督语义分割最近获得了越来越多的研究兴趣,因为它可以通过有效地利用大量未标记的数据来减少对大规模完全注释训练数据的需求。 目前的方法经常受到伪标记过程的确认偏差的影响,这可以通过协同训练框架来缓解。 目前基于协同训练的半监督语义分割方法依赖于手工扰动来防止不同子网相互折叠,但这些人为扰动不能导致最优解。 在这项工作中,我们提出了一种基于双分支协同训练框架的新的基于冲突的跨视图一致性(CCVC)方法,用于半监督语义分割。 我们的工作旨在强制这两个子网从不相关的视图中学习信息特征。 特别地,我们首先提出了一种新的跨视图一致性 (CVC) 策略,该策略通过引入特征差异损失来鼓励两个子网从同一输入中学习不同的特征,同时这些不同的特征有望产生一致的预测分数输入。 CVC策略有助于防止两个子网步入崩溃。 此外,我们进一步提出了一种基于冲突的伪标签(CPL)方法,以保证模型从冲突的预测中学习到更多有用的信息,从而实现稳定的训练过程。 我们在广泛使用的基准数据集 PASCAL VOC 2012 和 Cityscapes 上验证了我们新的半监督语义分割方法,我们的方法实现了新的最先进的性能。
4.提供任意模态语义分割(无代码)
Delivering Arbitrary-Modal Semantic Segmentation
多模态融合可以使语义分割更加健壮。然而,融合任意数量的模式仍有待探索。为了深入研究这个问题,我们创建了DELIVER任意模态分割基准,涵盖深度、LiDAR、多个视图、事件和RGB。除此之外,我们还提供了四种恶劣天气条件下的数据集以及五种传感器故障情况,以利用模式互补性并解决部分故障。
为了实现这一点,我们提出了跨任意模态分割模型CMNEXT。它包含一个自我查询中心(SQ Hub),旨在从任何模态中提取有效信息,以便随后与RGB表示进行融合,并且每个附加模态仅添加可忽略的参数量(~0.01M)。
首先,为了高效灵活地从辅助模态中获取辨别线索,我们引入了简单的并行池混合器(PPX)。
通过在总共六个基准上的广泛实验,我们的CMNEXT在DELIVER、KITTI-360、MFNet、NYU Depth V2、UrbanLF和MCubeS数据集上实现了最先进的性能,可从1种模式扩展到81种模式。在新收集的DELIVER上,四模态CMNEXT在mIoU中达到66.30%,与单模态基线相比,增益为+9.10%。
数据集
DeLiVER多模态数据集包括(a)五种条件中的四种不利条件(多云,有雾,夜间,雨天和晴天)。 除正常情况外,每种情况都有五个极端情况(MB:运动模糊;OE:过度曝光;UE:曝光不足;LJ:激光雷达抖动;和 EL:事件低分辨率)。 每个示例有六个视图。每个视图都有四种模态和两个标签(语义和实例)。
模型
提出了任意交叉模态CMNeXt分割模型。在增加更多模态时,CMNeXt结合了新的Hub2Fuse范式(图3c),而不会显著增加计算开销。与依赖于计算成本较高的单独分支(图3a)或使用通常丢弃有价值信息的单个联合分支(图3b)不同,CMNeXt是一种具有两个分支的不对称架构,一个用于RGB,另一个用于不同的补充模态。
关键的挑战在于设计两个分支来获取多模态线索。具体而言,在Hub2Fuse的中心步骤中,为了从辅助模态收集有用的补充信息,我们设计了一个自查询中心(SQ hub),该中心在与RGB分支融合之前从所有模态源中动态选择信息特征。SQ Hub的另一个巨大优势是,可以轻松地将其扩展到任意数量的模态,参数增加可以忽略不计(每个模态约0.01M)。在融合步骤,如果没有明确的融合(如TokenFusion),联合分支架构很难处理LiDAR或事件数据等稀疏模态的融合[72]。为了避免这一问题,并充分利用密集和稀疏模态,我们利用[49],并将其与我们提出的并行池混合器(PPX)相结合,该混合器可以高效灵活地从任何辅助模态中获取最具辨别力的线索。
Hub2Fuse 范式和非对称分支中的 CMNeXt 架构,在RGB分支中具有例如多头自关注(MHSA)[80]块,在伴随分支中具有我们的并行池混合器(PPX)块。在中心步骤,自我查询中心从补充模式中选择信息特征。在融合步骤,特征校正模块(FRM)和特征融合模块(FFM)[49]用于特征融合。在阶段之间,通过添加融合特征来恢复每个模态的特征。四级融合特征被转发到分割头用于最终预测。
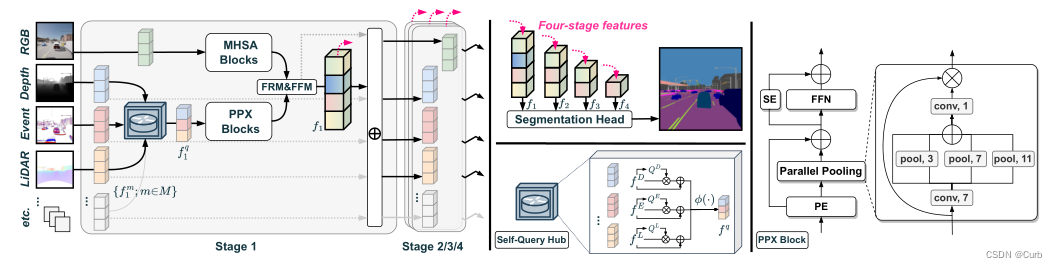
CMNeXt从双模态场景(如RGB-D解析)扩展到任意模态融合(如光场分割),几乎有81种模态。此外,我们还提供了一个DELIVER基准,以促进多模式学习。虽然有一些基于CARLA模拟器[19]的现有数据集[24,59,68],但我们的数据集不仅提供了多样的传感数据,还提供了传感器故障案例,以实现稳健的语义理解。
5.弱监督语义分割的token对比(代码已公布)
Token Contrast for Weakly-Supervised Semantic Segmentation
使用图像级标签的弱监督语义分割(WSSS)通常利用类激活图(CAM)来生成伪标签。受限于CNN的局部结构感知,CAM通常无法识别整体对象区域。虽然最近的Vision Transformer(ViT)可以弥补这一缺陷,但我们观察到它也带来了过度平滑的问题,即,最终的补丁令牌趋于均匀。在这项工作中,我们提出令牌对比度(ToCo)来解决这个问题,并进一步探索WSSS的ViT的优点。首先,由于观察到ViT中的中间层仍然可以保持语义多样性,我们设计了补丁令牌对比模块(PTC)。
PTC使用从中间层导出的伪令牌关系来监督最终的补丁令牌,允许它们对齐语义区域,从而生成更准确的CAM。
其次,为了进一步区分CAM中的低置信度区域,我们设计了一个类令牌对比模块(CTC),其灵感来自于ViT中的类令牌可以捕获高级语义这一事实。CTC通过对比不确定局部区域和全局对象的类标记,促进了它们之间的表示一致性。在PASCAL VOC和MS COCO数据集上的实验表明,所提出的ToCo可以显著超过其他单阶段竞争对手,并与最先进的多阶段方法实现类似的性能
6. CutLER(Cut-and-LEaRn):一种用于训练无监督目标检测和实例分割模型(无代码)
Cut and learn for unsupervised object detection and instance segmentation
参考解析:CVPR 2023 | 涨点显著!CutLER:用于无监督目标检测和实例分割的切割和学习 - 知乎 (zhihu.com)
7.基础模型驱动语义分割的弱增量学习(无代码)
Cut and learn for unsupervised object detection and instance segmentation
语义分割方法的现代增量学习通常学习 基于密集批注的新类别。虽然取得了可喜的成果, 逐像素标记既昂贵又耗时。弱增量 学习语义分割(WILSS)是一项新颖而有吸引力的任务, 旨在学习从廉价和广泛可用的新课程中划分新课程 图像级标签。尽管结果相当,但图像级标签可以 不提供详细信息以查找每个段,这限制了 威尔斯。这激发了我们思考如何改进和有效利用 监督给定图像级标签的新类,同时避免遗忘 旧的。在这项工作中,我们提出了一个新颖且数据高效的框架 威尔斯,名叫FMWISS。具体来说,我们建议基于预训练 协同分割,以提炼互补基础模型的知识 生成密集的伪标签。我们进一步优化了噪声伪掩码 师生体系结构,其中插件教师使用 提出了密集对比损失。此外,我们引入了基于内存的复制粘贴 增强以改善旧班级的灾难性遗忘问题。 对Pascal VOC和COCO数据集的广泛实验证明了优越的 我们的框架的性能,例如,FMWISS在70-7中分别实现了73.3%和15.5% VOC设置,分别比最先进的方法高出3.4%和6.1%。
二、可能会感兴趣的
1.POMP:用于开放词汇视觉识别的20000类Prompt预训练
Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition
这项工作提出了POMP,一种视觉语言的快速预训练方法 模型。由于内存和计算效率高,POMP 支持学习提示 浓缩语义信息,以获得丰富的视觉概念集 两万节课。一旦预训练,提示与强 可转移能力可直接插入各种视觉 识别任务,包括图像分类、语义分割和 物体检测,以零镜头的方式提高识别性能。 实证评估表明,POMP 在 21 个下游数据集,例如,67 个分类的平均准确率为 0.10% 数据集(+3.1%与CoOp相比)和开放词汇Pascal VOC的84.4 hIoU 分段(+6.9与ZSSeg相比)。Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition

2.InterFormer:实时交互式图像分割
InterFormer: Real-time Interactive Image Segmentation

3.SALUDA :基于Surface的自动驾驶激光雷达无监督域自适应
SALUDA: Surface-based Automotive Lidar Unsupervised Domain Adaptation

4.SegGPT:分割上下文中的一切
Seggpt: Segmenting everything in context
5.谷歌提出:文本到图像扩散模型的零微调图像定制的Taming编码器
Taming Encoder for Zero Fine-tuning Image Customization with Text-to-Image Diffusion Models
三、医学图像分割相关
1.BerDiff:用于医学图像分割的条件伯努利扩散模型
BerDiff: Conditional Bernoulli Diffusion Model for Medical Image Segmentation

2.(CVPR2023)基于扩散模型的Ambiguous医学图像分割
Ambiguous Medical Image Segmentation using Diffusion Models

3.SPIRiT-Diffusion:用于加速MRI的自一致性驱动扩散模型
Spirit-diffusion: Self-consistency driven diffusion model for accelerated mri
4.视频预训练促进胸部CT任务的3D深度学习
Video Pretraining Advances 3D Deep Learning on Chest CT Tasks
单位:斯坦福大学、麻省总医院、哈佛医学院
5.(CVPR2023)无标记肝肿瘤分割(代码以公布)
Label-free liver tumor segmentation
我们证明了人工智能模型可以准确地分割肝肿瘤,而无需 需要在 CT 扫描中使用合成肿瘤进行手动注释。我们的合成 肿瘤有两个有趣的优点:
(一)形状和质地逼真, 即使是医学专业人员也会将其与真正的肿瘤混淆;
(二)有效 用于训练AI模型,其可以执行类似于肝肿瘤分割的 在真实肿瘤上训练的模型 - 这个结果是令人兴奋的,因为没有现有的 迄今为止,仅使用合成肿瘤的工作已经达到了类似甚至接近的程度。 对真实肿瘤的表现。这一结果也意味着手动努力 通过体素(花费数年时间创建)注释肿瘤体素可以是 未来显着减少。而且,我们的合成肿瘤可以 自动生成许多小(甚至微小)合成肿瘤的例子 并有可能提高小肝检测的成功率 肿瘤,这对于检测癌症的早期阶段至关重要。另外 为了丰富训练数据,我们的合成策略还使我们能够 严格评估 AI 鲁棒性。
方法
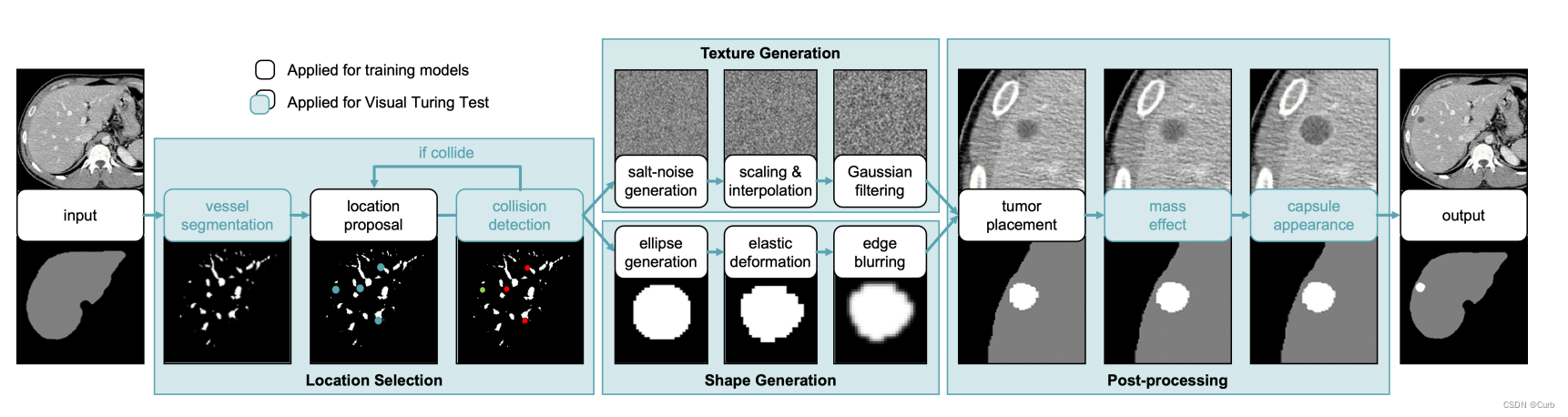
肿瘤生成
为了定位肝脏,我们首先将预先训练的nnUNet应用于CT扫描。在获得肝脏的粗略位置后,我们开发了一系列形态学图像处理操作,以合成肝脏内真实的肿瘤(见图3)。肿瘤的生成包括四个步骤:
(1)位置选择、
(2)纹理生成、
(3)形状生成
(4)后处理。
实验
数据集
LiTS[5]中提供了肝脏肿瘤的详细体素注释。肝脏肿瘤的体积范围为38mm3至349cm3,肿瘤的半径范围为[2,44]mm。我们进行了5倍的交叉验证,遵循与Tang等人[55]相同的分割。在101次带有注释的肝脏和肝脏肿瘤的CT扫描上训练AI模型(例如U-Net)。为了进行比较,健康肝脏的116次CT扫描数据集由CHAOS[28](20次CT扫描)、BTCV[31](47次CT扫描)胰腺CT[50](38次CT扫描)和LiTS中的健康受试者(11次CT扫描)。然后,我们在这些扫描中实时生成肿瘤,从而产生巨大的合成肿瘤图像标签对,用于训练人工智能模型。我们生成五个级别的肿瘤大小用于模型训练;参数和示例见附录表6和图11。
- 01 [Multi-Atlas Labeling Beyond the Cranial Vault - Workshop and Challenge (BTCV)](https://www.synapse.org/#!Synapse:syn3193805/wiki/89480)
- 02 [Pancreas-CT TCIA](https://wiki.cancerimagingarchive.net/display/Public/Pancreas-CT)
- 03 [Combined Healthy Abdominal Organ Segmentation (CHAOS)](https://chaos.grand-challenge.org/)
- 04 [Liver Tumor Segmentation Challenge (LiTS)](https://competitions.codalab.org/competitions/17094)我们的代码是基于U-Net和Swin UNETR的MONAI2框架实现的。输入图像以[-21, 189]的窗口范围进行剪裁,然后归一化为零平均值和单位标准差。在训练过程中,从3D图像体积中裁剪出96×96×96的随机补丁。所有模型都经过了4000个epochs的训练,基本学习率为0.0002。每个GPU的批处理大小为两个。我们采用了线性预热策略(linear warmup strategy)和余弦退火学习速率(the cosine annealing learning rate)调度。为了进行推断,我们使用滑动窗口策略,将重叠面积比设置为0.75。
总结
未来,我们将考虑生成对抗性网络(GAN)[17,19]、扩散模型[22],并可能使用NeRF[43]等3D几何模型进行改进,以生成更好的肿瘤纹理。
背景
MICCAI FLARE 2022腹部CT多器官分割比赛介绍
MICCAI FLARE 2022腹部CT多器官分割比赛介绍 - 知乎 (zhihu.com)
评测指标方面,我们同时考虑了常用的分割精度指标和实际部署中关注的性能指标
-
DSC:区域重合度
-
NSD:给定误差范围内的边界重合度
-
GPU显存-Time曲线下面积,显存在2G以内按照0算,即用来排名的GPU显存 = max(0, GPU Memory consumption-2048)
-
CPU利用率-Time曲线下面积
-
Time
6.(CVPR2023)基于定向连接的医学图像分割(代码以公布)
Directional Connectivity-based Segmentation of Medical Images
摘要
生物标志物分割中的解剖学一致性对于许多医学至关重要 图像分析任务。在解剖学上实现的有前途的范式 通过深度网络的一致分割正在整合像素连接, 数字拓扑学中的基本概念,用于对像素间关系进行建模。 然而,以前的连通性建模工作忽略了丰富的 潜在空间中的通道方向信息。在这项工作中,我们 证明方向子空间与 共享潜在空间可以显著增强 基于连接的网络。为此,我们提出了定向连接 用于解耦、跟踪和利用 跨网络的方向信息。各种公众实验 医学图像分割基准测试表明我们的模型的有效性为 与最先进的方法相比。
7.(CVPR2023)用于半监督医学图像分割的双向复制粘贴(代码以公布)
Bidirectional Copy-Paste for Semi-Supervised Medical Image Segmentation
摘要
在半监督医学图像分割中,存在经验不匹配 标记和未标记数据分布之间的问题。所学知识 从标记的数据可以在很大程度上被丢弃,如果处理标记和 单独或以不一致的方式未标记的数据。我们提出一个 缓解问题的简单方法 - 复制粘贴标记和 双向未标记数据,在简单的平均教师架构中。这 方法鼓励未标记的数据从中学习全面的通用语义 向内和向外方向的标记数据。更重要的是, 标记和未标记数据的一致学习过程可以在很大程度上减少 经验分布差距。详细地说,我们从 标记图像(前景)到未标记的图像(背景)和 未标记的图像(前景)分别到标记的图像(背景)上。 两个混合图像被输入学生网络并由混合图像监督 伪标签和地面真相的监督信号。我们揭示了 在标记和未标记之间双向复制粘贴的简单机制 数据足够好,实验显示出稳定的收益(例如,超过 21% 的骰子 具有5%标记数据的ACDC数据集的改进)与其他数据集相比 各种半监督医学图像分割的最新技术 数据。
8.(CVPR2023)通过客户贡献估计进行公平联合医学图像分割(代码以公布)
Fair Federated Medical Image Segmentation via Client Contribution Estimation
摘要
如何确保公平性是联邦学习(FL)中的一个重要主题。 最近的研究调查了如何根据客户奖励客户 贡献(协作公平性),以及如何实现 跨客户端的性能(性能公平性)。尽管取得了进展 无论哪一个,我们认为,将它们放在一起考虑是至关重要的,以便 吸引和激励更多多元化的客户加入FL,以获得高质量的 全局模型。在这项工作中,我们提出了一种优化两种类型的新方法 同时公平。具体来说,我们建议估计客户 梯度和数据空间的贡献。在梯度空间中,我们监控 每个客户端相对于其他客户端的梯度方向差异。而在 数据空间,我们使用辅助测量客户端数据的预测误差 型。基于这种贡献估计,我们提出了一种 FL 方法,联合 通过贡献估计(FedCE)进行培训,即使用估计作为全局 模型聚合权重。我们已经从理论上分析了我们的方法和 在两个真实世界的医学数据集上对其进行了实证评估。
9.(CVPR2023)使用扩散模型的模糊医学图像分割(代码以公布)
Ambiguous Medical Image Segmentation using Diffusion Models
摘要
来自一组专家的集体见解总是被证明表现优异 个人对临床任务的最佳诊断。用于医疗任务 图像分割,现有关于基于AI的替代方案的研究更侧重于 开发可以模仿最佳个人而不是利用的模型 专家组的力量。在本文中,我们介绍了单一扩散 基于模型的方法,通过学习 分布在组见解上。我们提出的模型生成了一个分布 的分割掩码,利用固有的随机采样过程 仅使用最少的额外学习进行扩散。我们演示三个 不同的医学图像模式 - 我们的模型是 CT、超声波和 MRI 能够在捕获频率的同时产生多种可能的变体 它们的发生。综合结果表明,我们提出的方法 在现有最先进的模糊分割网络方面优于现有 的准确性,同时保留自然发生的变化。我们还提出了一个 评估多样性和细分准确性的新指标 符合集体临床实践利益的预测 见解。
10.(CVPR2023)正交注释有利于几乎受监督的医学图像分割(代码以公布)
Orthogonal Annotation Benefits Barely-supervised Medical Image Segmentation
摘要
半监督学习的最新趋势显着推动了 3D半监督医学图像分割的性能。与 2D 相比 图像,3D医疗体积涉及来自不同方向的信息,例如, 横平面、矢状面和冠状面,以便自然提供 补充观点。这些互补的观点和内在的相似性 在相邻的3D切片中,激发我们开发一种新颖的注释方式及其 用于有效分割的相应半监督模型。具体说来 我们首先提出正交注释,只标记两个正交 标记体积中的切片,这大大减轻了 注解。然后,我们执行注册以获得初始伪标签 对于稀疏标记的卷。随后,通过引入未标记的卷, 我们提出了一种名为密集稀疏协同训练(DeSCO)的双网络范式, 早期利用密集伪标签,后期利用稀疏标签 同时强制两个网络的一致输出。实验结果 三个基准数据集验证了我们在性能和 注释效率。例如,只有 10 个带注释的切片,我们的 方法在 KiTS86 数据集上达到高达 93.19% 的骰子。
11.(CVPR2023)MagicNet:通过 Magic-Cube 分区和恢复进行半监督多器官分割(代码以公布)
MagicNet: Semi-Supervised Multi-Organ Segmentation via Magic-Cube Partition and Recovery
摘要
我们提出了一种新的半监督多器官师生模型 分割。在师生模型中,数据增强通常采用 未标记的数据,以规范教师和教师之间的一致培训 学生。我们从一个关键的角度出发,固定相对位置和 不同大小的器官可以提供分布信息,其中 进行多器官 CT 扫描。因此,我们将先前的解剖结构视为一个强大的工具 指导数据增强并减少标记和之间的不匹配 用于半监督学习的未标记图像。更具体地说,我们提出一个 基于分区和恢复N的数据增强策略3立方体交叉- 以及标记内和未标记的图像。我们的策略鼓励不标记 图像,用于从标记图像中学习相对位置的器官语义 (跨分支)增强小器官的学习能力 (分支内)。对于分支内,我们进一步建议细化质量 通过将从小立方体学习到的表示混合到 合并本地属性。我们的方法被称为MagicNet,因为它处理 CT体积作为魔方和N3-多维数据集分区和恢复过程 与玩魔方的规则相匹配。对两个进行了广泛的实验 公共CT多器官数据集证明了MagicNet的有效性,并且 明显优于最先进的半监督医学图像 分割方法,MACT 数据集的 DSC 改进 +7%,10% 带标签的图像。
四、其他
1.Segment Anything
Segment anything
Segment Anything 做为Facebook 推出的object分割模型(segment anything model ,SAM)和数据集(SA-1B),万物可分割。


![深度学习基础入门篇-序列模型[11]:循环神经网络 RNN、长短时记忆网络LSTM、门控循环单元GRU原理和应用详解](https://img-blog.csdnimg.cn/img_convert/b54420b25d75b627fd62bbe341255c0e.png)