import os
import time
import pandas as pd
def xlsx2csv ( ) :
t1 = time. time( )
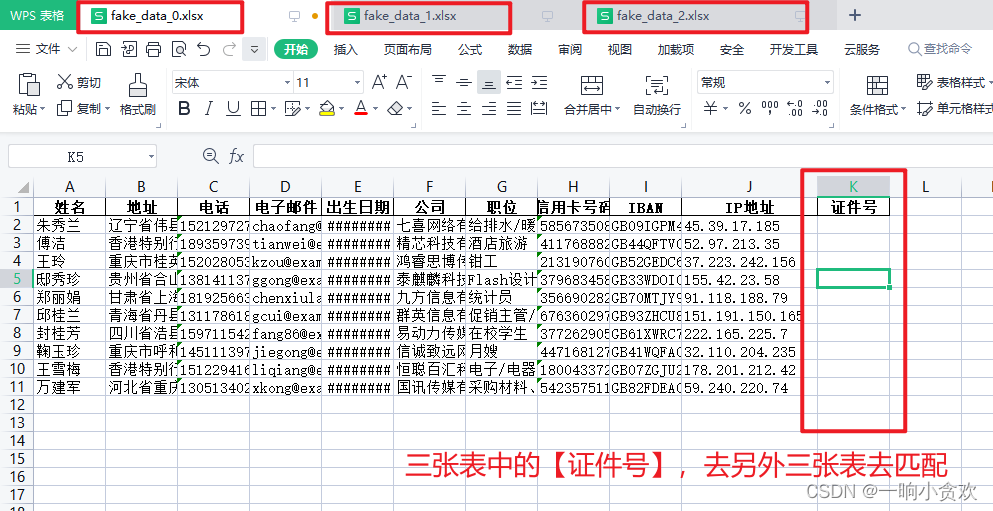
for f in os. listdir( "原始表/" ) :
data = pd. read_excel( "原始表/" + f, index_col= 0 )
data. to_csv( "csv版" + f + '.csv' , encoding= 'utf-8' )
print ( "写入完成......" )
t2 = time. time( )
print ( t2 - t1)
xlsx2csv( )
list_a.append((d[0], d[0])) 1
import csv
import os
from collections import defaultdict
def write_json ( ) :
for f in os. listdir( "./csv版/" ) :
with open ( "./csv版/" + f, newline= '' , encoding= 'utf-8' ) as csvfile:
reader = csv. reader( csvfile, delimiter= ',' , quotechar= '"' )
print ( f, "加载完毕" )
list_a = [ ]
for d in reader:
list_a. append( ( d[ 0 ] , d[ 0 ] ) )
d = defaultdict( list )
for key, value in list_a:
d[ key] . append( value)
with open ( f"./json文件/ { f. split( '.' ) [ 0 ] } .json" , "w" , encoding= "utf-8" ) as f2:
f2. write( json. dumps( d, ensure_ascii= False ) )
write_json( )
import json
import os
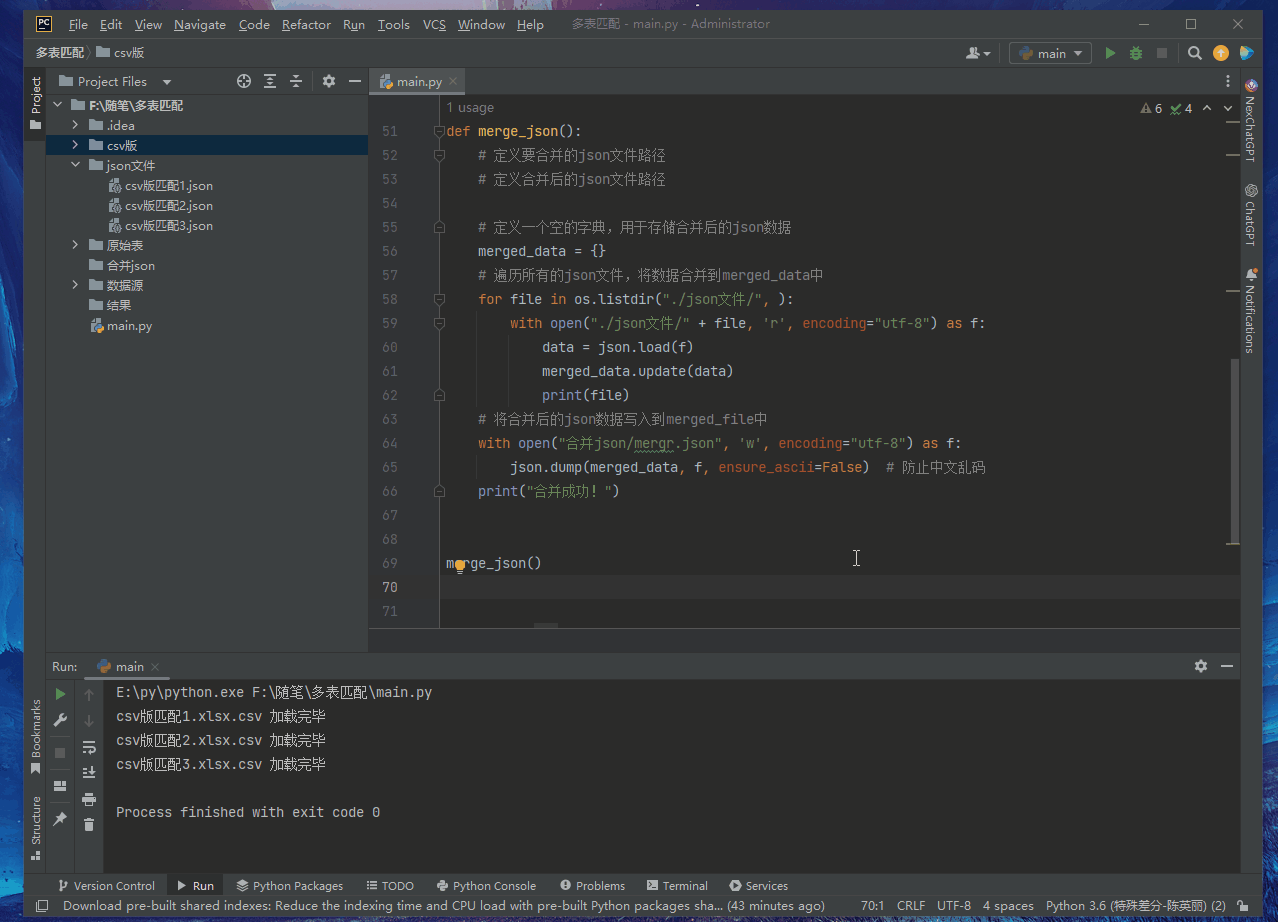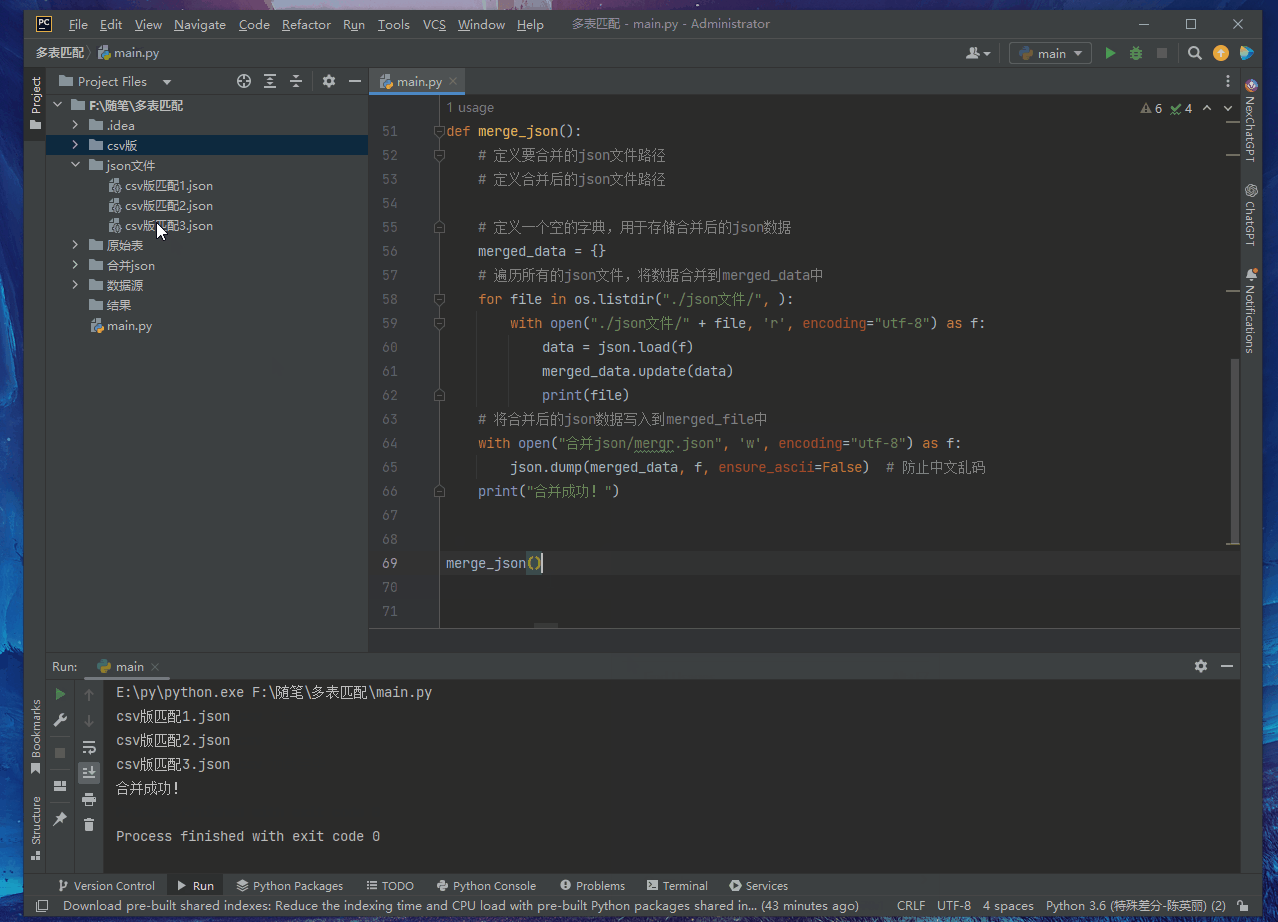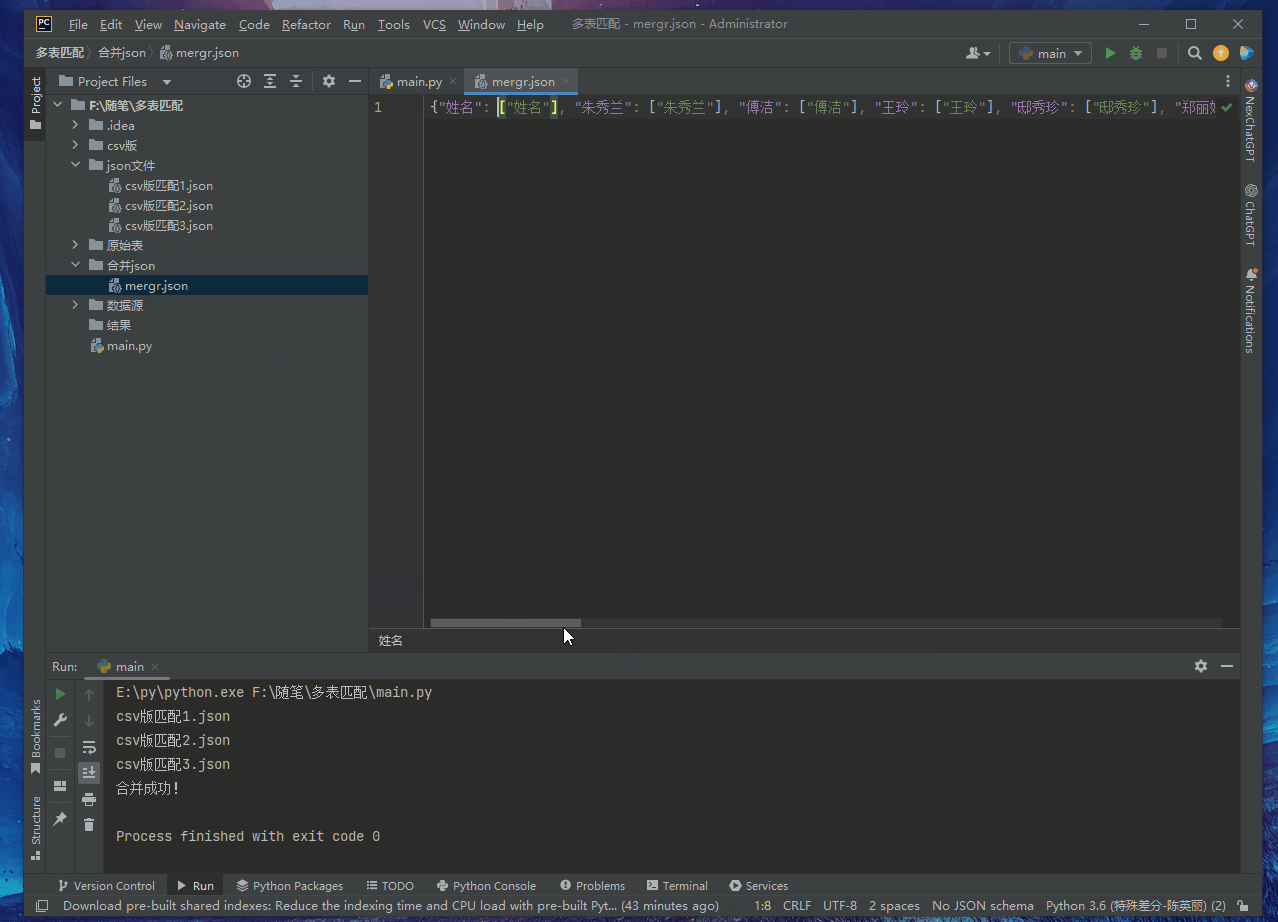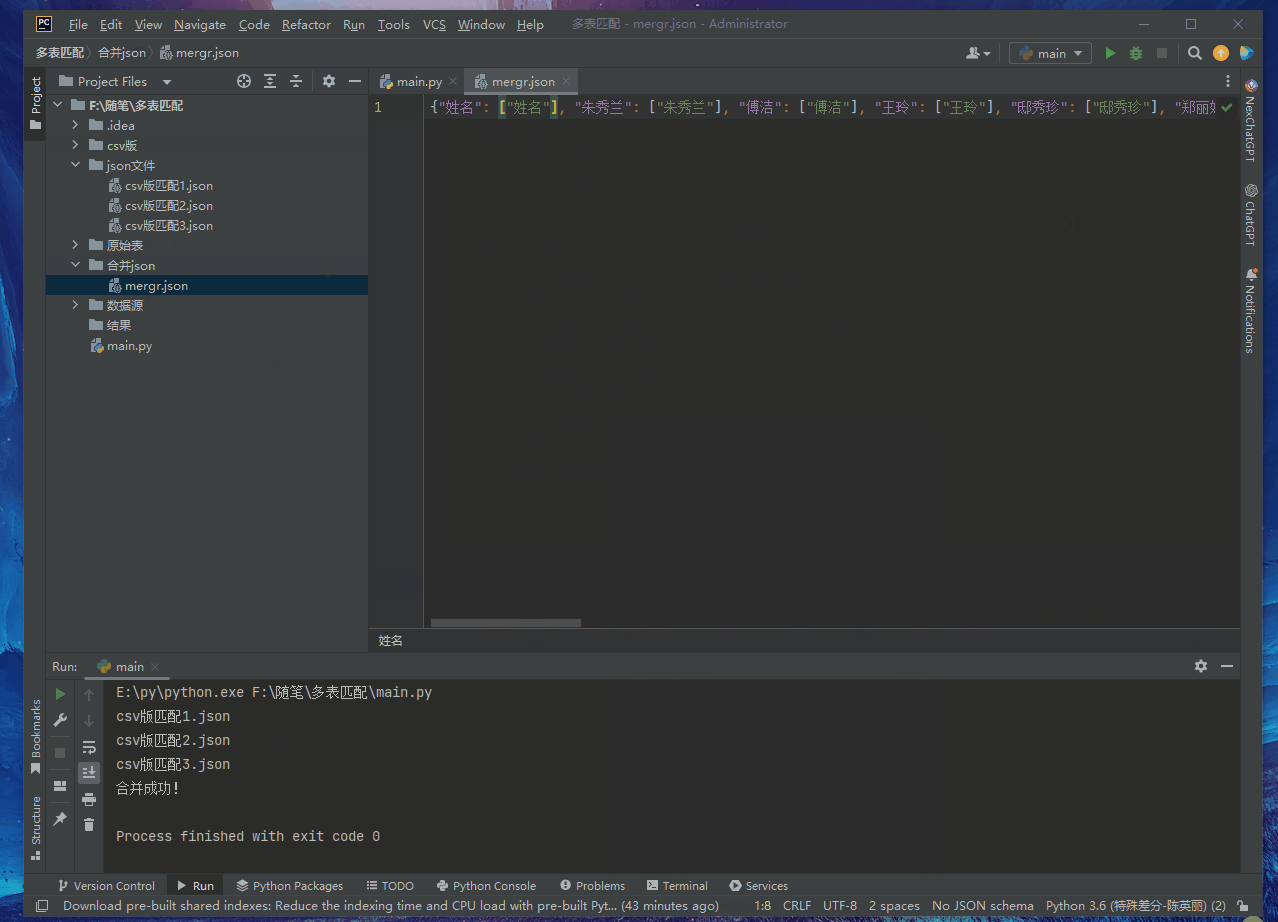
def merge_json ( ) :
merged_data = { }
for file in os. listdir( "./json文件/" , ) :
with open ( "./json文件/" + file , 'r' , encoding= "utf-8" ) as f:
data = json. load( f)
merged_data. update( data)
print ( file )
with open ( "合并json/mergr.json" , 'w' , encoding= "utf-8" ) as f:
json. dump( merged_data, f, ensure_ascii= False )
print ( "合并成功!" )
merge_json( )
'''
作者:一晌小贪欢
手机:xxxx
'''
import csv
import json
import os
import time
from collections import defaultdict
import pandas as pd
def xlsx2csv ( ) :
t1 = time. time( )
for f in os. listdir( "原始表/" ) :
data = pd. read_excel( "原始表/" + f, index_col= 0 )
data. to_csv( "csv版" + f + '.csv' , encoding= 'utf-8' )
print ( "写入完成......" )
t2 = time. time( )
print ( t2 - t1)
xlsx2csv( )
def write_json ( ) :
for f in os. listdir( "./csv版/" ) :
with open ( "./csv版/" + f, newline= '' , encoding= 'utf-8' ) as csvfile:
reader = csv. reader( csvfile, delimiter= ',' , quotechar= '"' )
print ( f, "加载完毕" )
list_a = [ ]
for d in reader:
list_a. append( ( d[ 0 ] , d[ 1 ] ) )
d = defaultdict( list )
for key, value in list_a:
d[ key] . append( value)
with open ( f"./json文件/ { f. split( '.' ) [ 0 ] } .json" , "w" , encoding= "utf-8" ) as f2:
f2. write( json. dumps( d, ensure_ascii= False ) )
write_json( )
def merge_json ( ) :
merged_data = { }
for file in os. listdir( "./json文件/" , ) :
with open ( "./json文件/" + file , 'r' , encoding= "utf-8" ) as f:
data = json. load( f)
merged_data. update( data)
print ( file )
with open ( "合并json/mergr.json" , 'w' , encoding= "utf-8" ) as f:
json. dump( merged_data, f, ensure_ascii= False )
print ( "合并成功!" )
merge_json( )
def main ( ) :
t1 = time. time( )
with open ( "合并json/mergr.json" , "r" , encoding= "utf-8" ) as f:
res = json. load( f)
t2 = time. time( )
print ( t2 - t1)
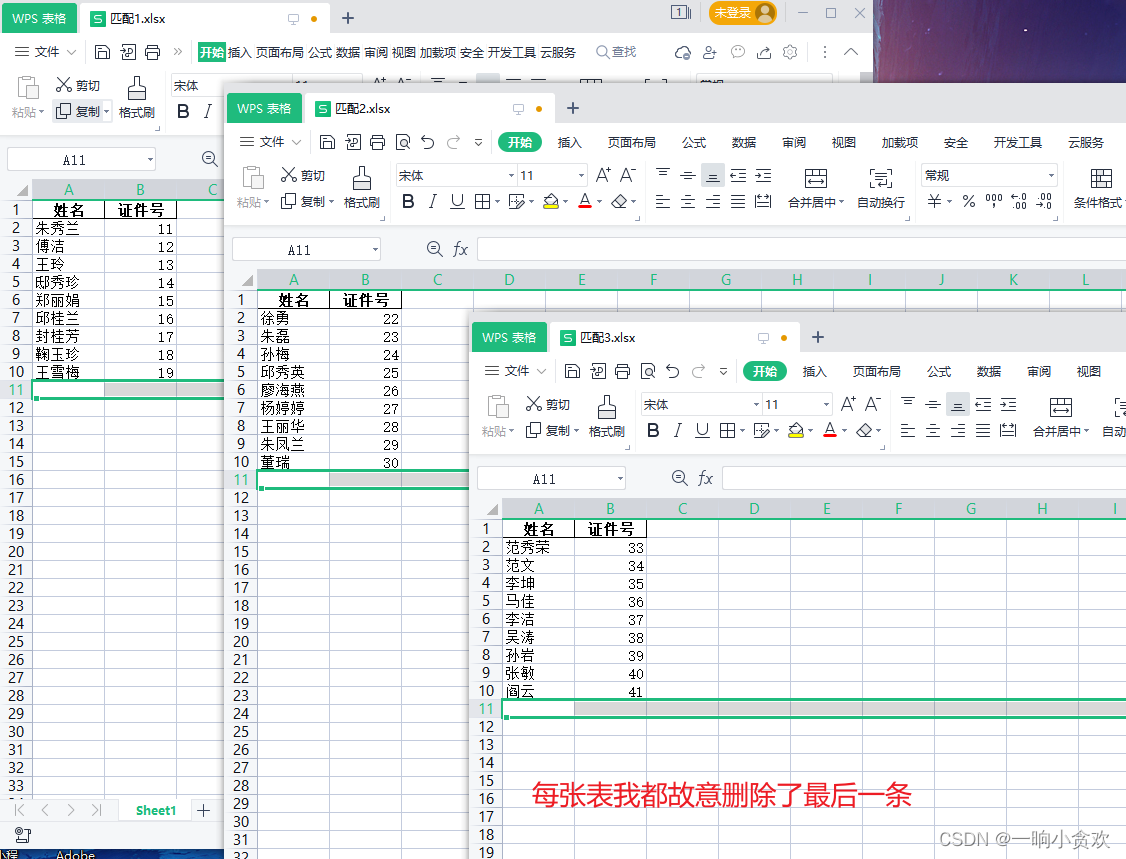
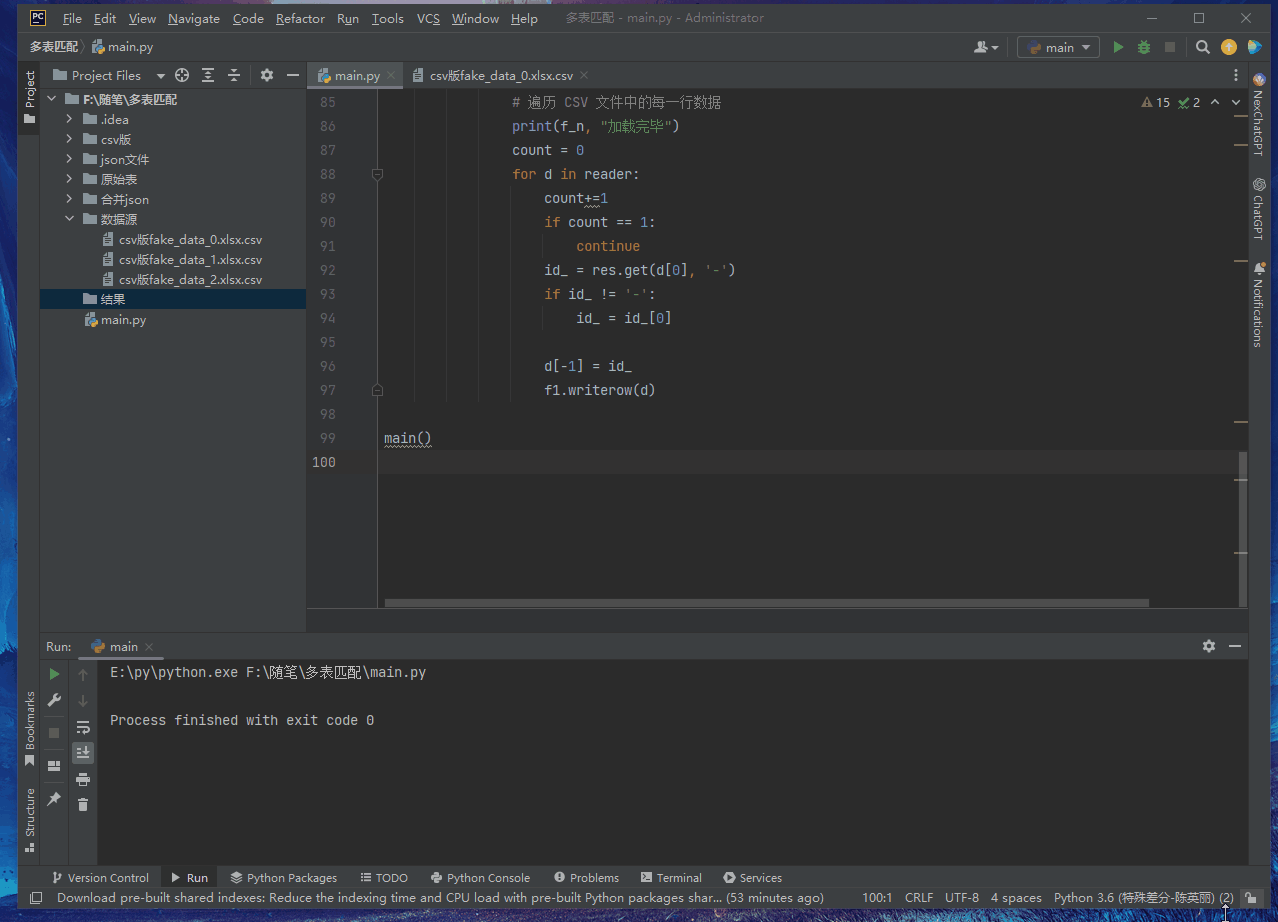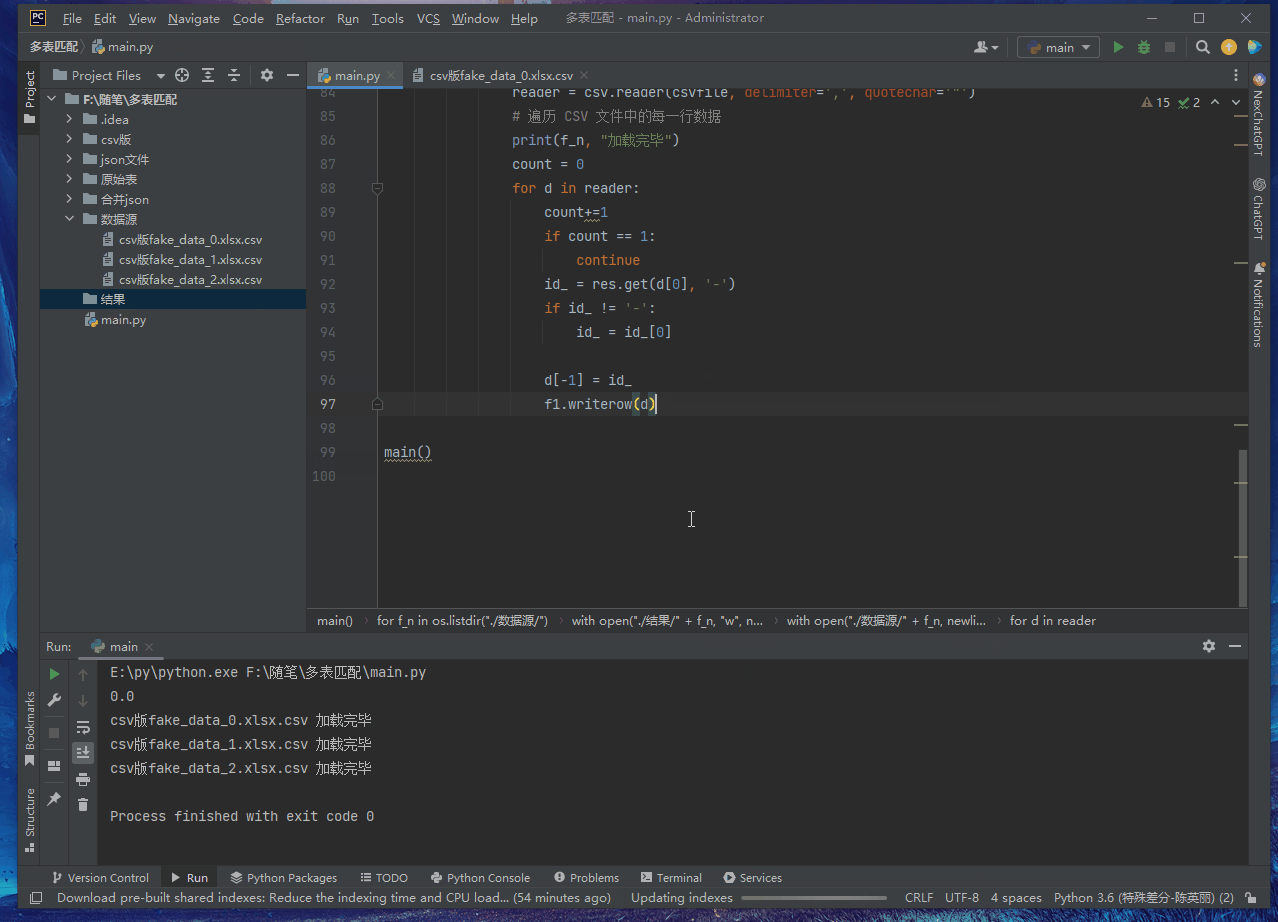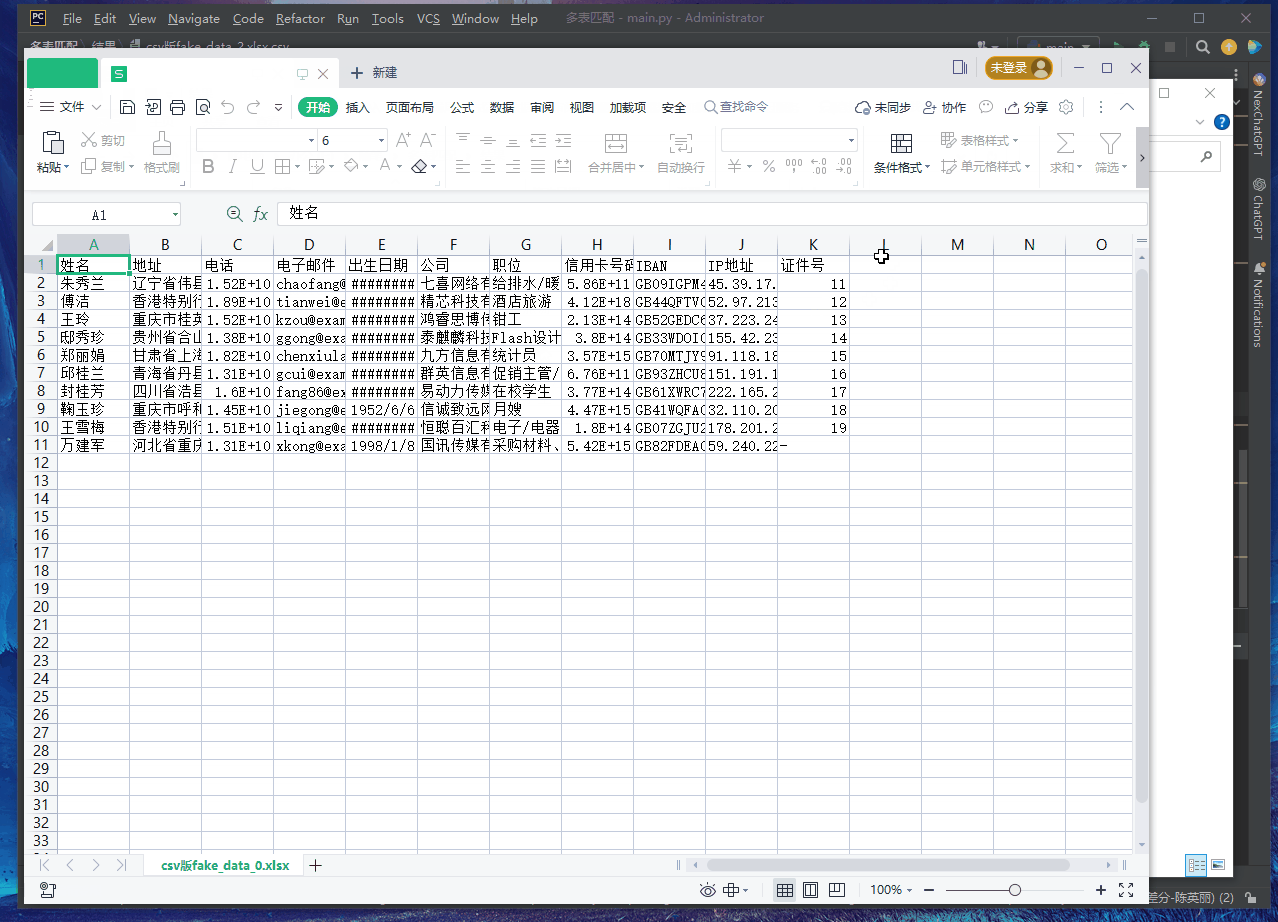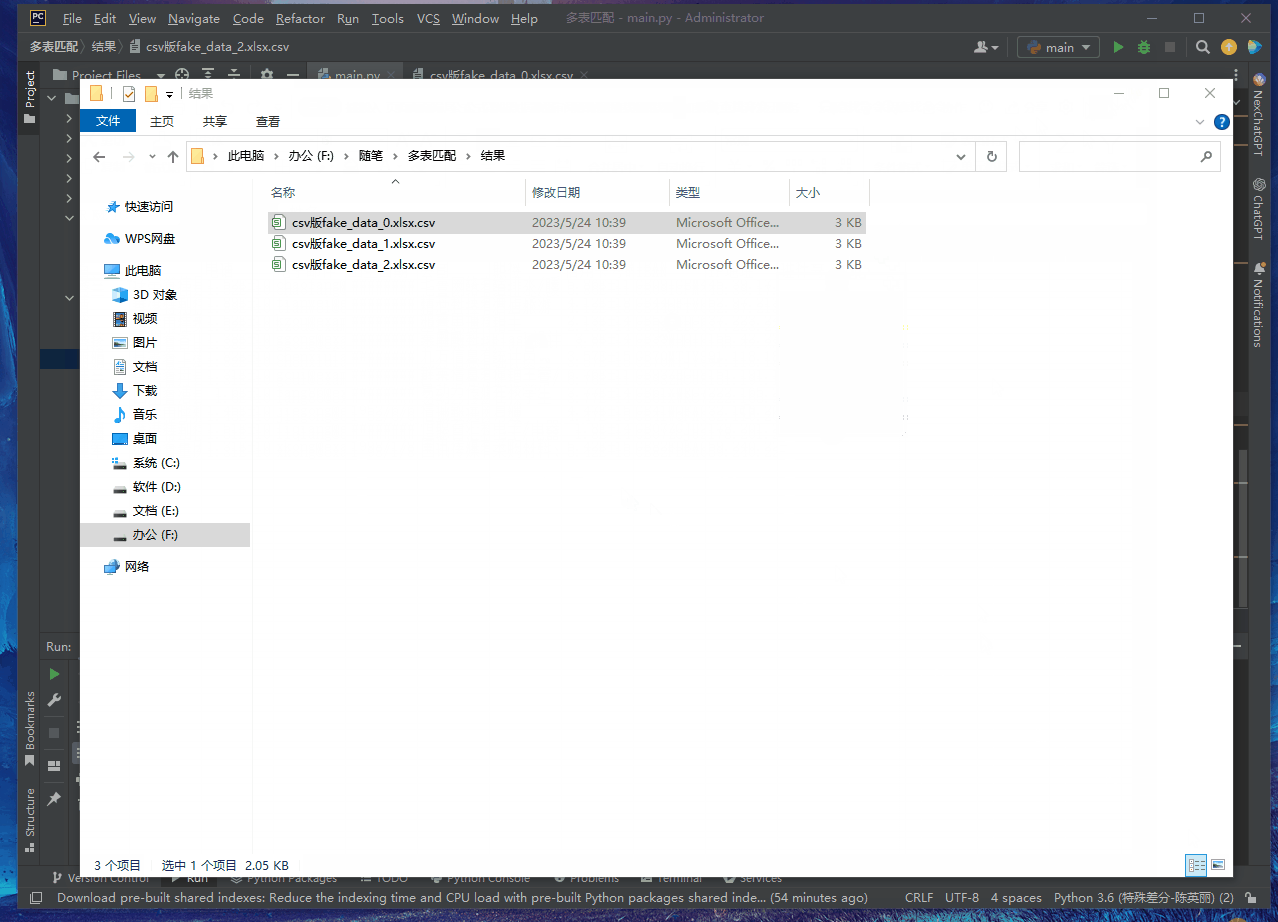
for f_n in os. listdir( "./数据源/" ) :
with open ( "./结果/" + f_n, "w" , newline= '' , encoding= "utf-8" ) as f1:
f1 = csv. writer( f1)
f1. writerow( [ '姓名' , '地址' , '电话' , '电子邮件' , '出生日期' , '公司' , '职位' , '信用卡号码' , 'IBAN' , 'IP地址' , '证件号' ] )
with open ( "./数据源/" + f_n, newline= '' , encoding= 'utf-8' ) as csvfile:
reader = csv. reader( csvfile, delimiter= ',' , quotechar= '"' )
print ( f_n, "加载完毕" )
count = 0
for d in reader:
count+= 1
if count == 1 :
continue
id_ = res. get( d[ 0 ] , '-' )
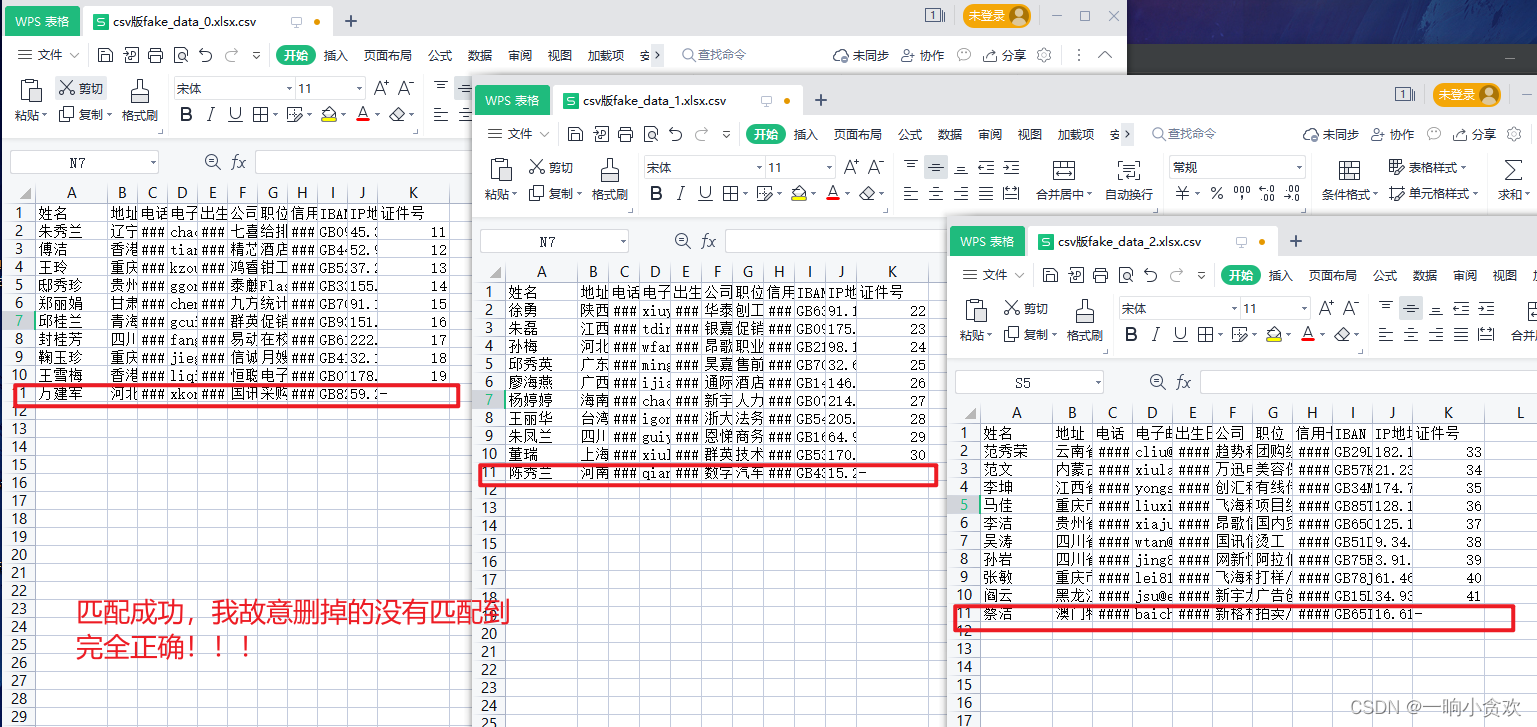
if id_ != '-' :
id_ = id_[ 0 ]
d[ - 1 ] = id_
f1. writerow( d)
main( )