一、RDD持久化
1、不采用持久化操作
查看要操作的HDFS文件

以集群模式启动Spark Shell
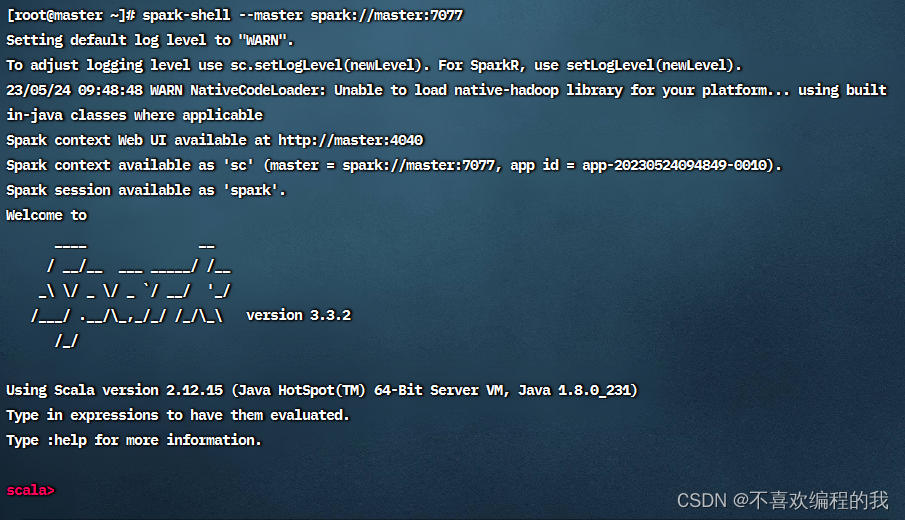
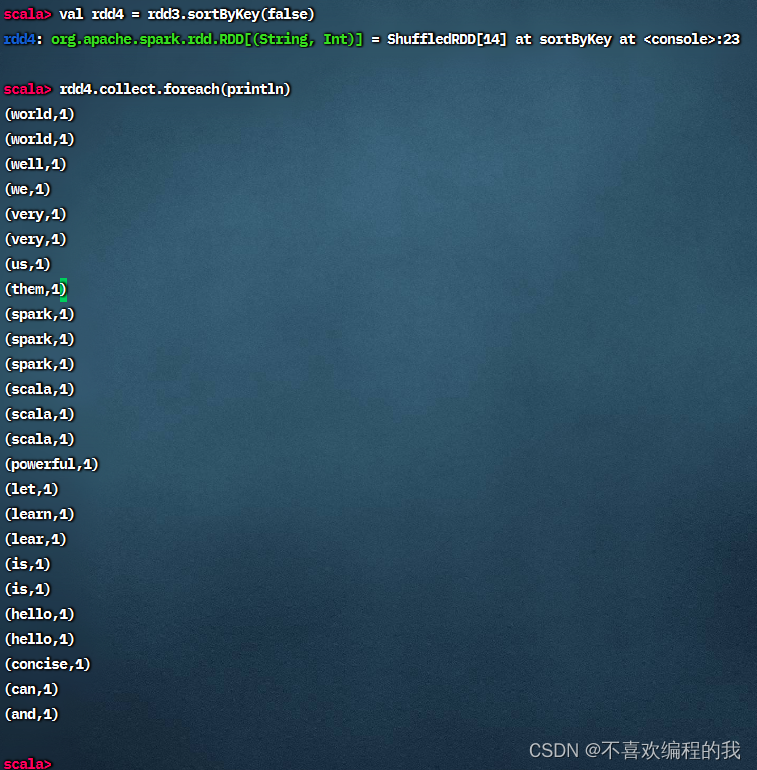
按照图示进行操作,得RDD4和RDD5
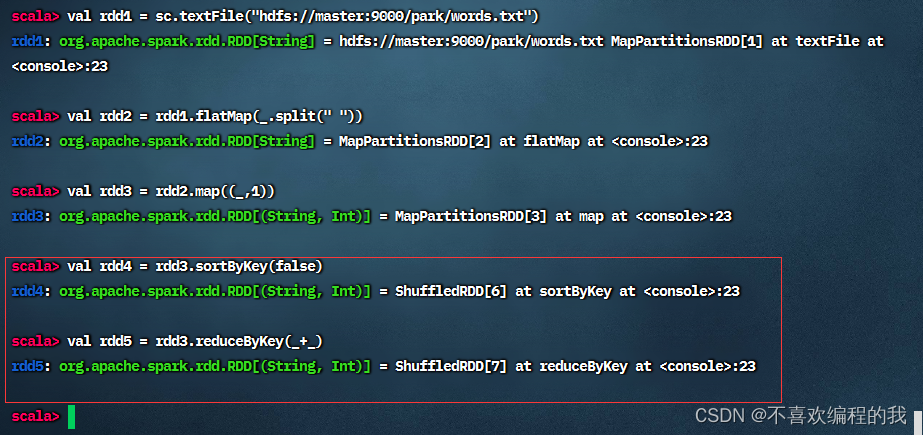
查看RDD4内容,会从RDD1到RDD2到RDD3到RDD4跑一趟
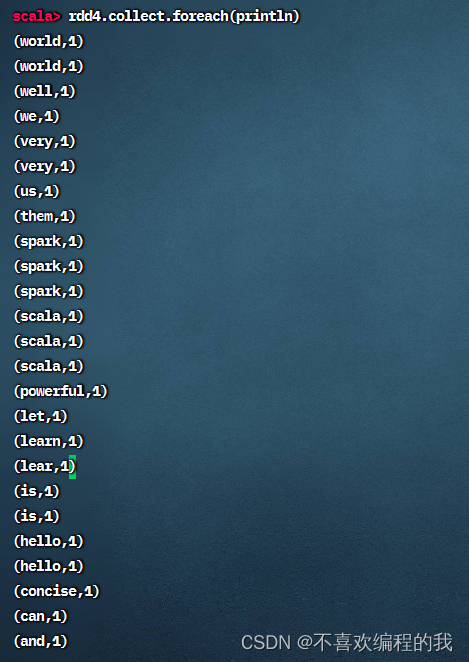
显示RDD5内容,也会从RDD1到RDD2到RDD3到RDD5跑一趟
2、采用持久化操作
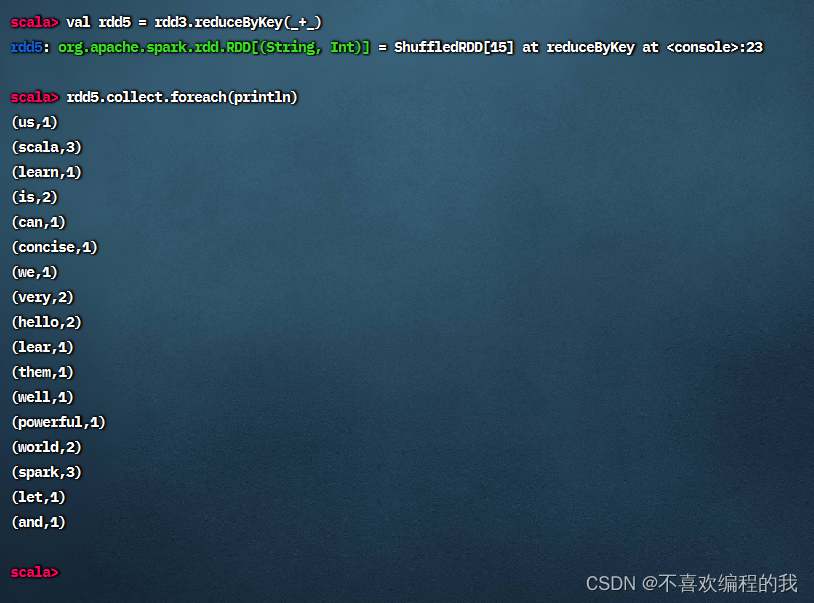
计算RDD4,就是基于RDD3缓存的数据开始计算,不用从头到尾跑一趟
计算RDD5,就是基于RDD3缓存的数据开始计算,不用从头到尾跑一趟
二、存储级别
案例演示设置存储级别
package net.cxf.rdd.day05
import org.apache.log4j.{Level, Logger}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
import java.awt.SystemTray
/**
* 功能:
* 作者:cxf
* 日期:2023年05月06日
*/
object SetStorageLevel {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf()
.setAppName("SetStorageLevel") //设置应用名称
.setMaster("local[*]") //设置主节点位置(本地调试>
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
//去除Spark运行信息
Logger.getLogger("org").setLevel(Level.OFF)
Logger.getLogger("com").setLevel(Level.OFF)
System.setProperty("spark.ui.showConsoleProgress", "false")
Logger.getRootLogger().setLevel(Level.OFF)
//创建RDD
val rdd = sc.textFile("hdfs://master:9000/park/words.txt")
//将rdd标记为持久化,采用默认存储级别- StorageLevel.MEMORY_ONLY
rdd.persist() //无参持久化方法
//对rdd做扁平映射,得到rdd1
val rdd1 = rdd.flatMap(_.split(" "))
//将rdd1持久化都磁盘
rdd1.persist(StorageLevel.DISK_ONLY)
//将rdd1映射成二元组,得到rdd2
val rdd2 = rdd1.map((_, 1))
//将rdd2持久化到内存,溢出的数据持久化到磁盘
rdd2.persist(StorageLevel.MEMORY_AND_DISK)
//第一次行动算子,对标记为持久化的RDD进行不同级别的持久化曹
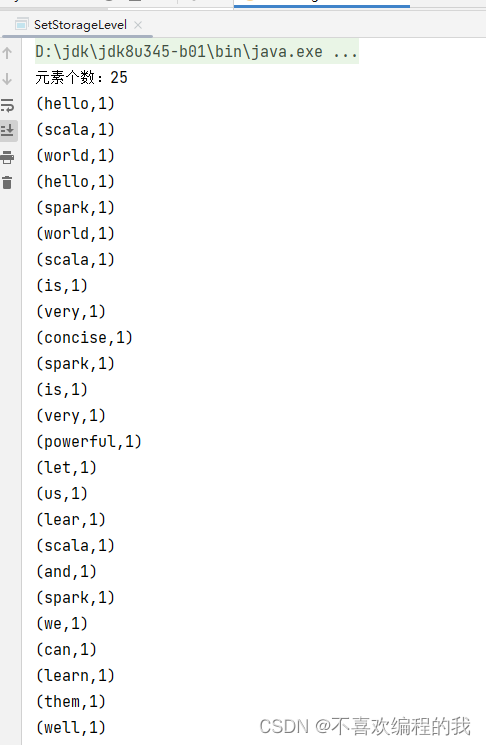
println("元素个数:" + rdd2.count)
//第二次行动算子,直接利用rdd2的持久化数据进行操作,无须从头进行计算
rdd2.collect.foreach(println)
}
}
运行程序,查看结果
三、利用Spark WebUI查看缓存
最好重启Spark Shell

(一)创建RDD并标记为持久化
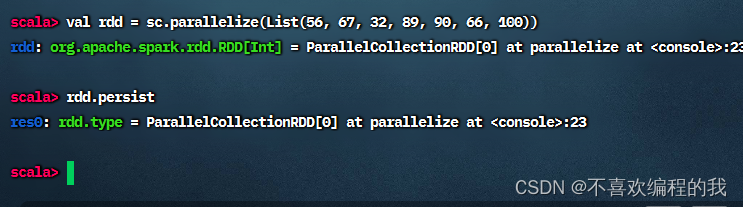
(二)Spark WebUI查看RDD存储信息
收集RDD数据

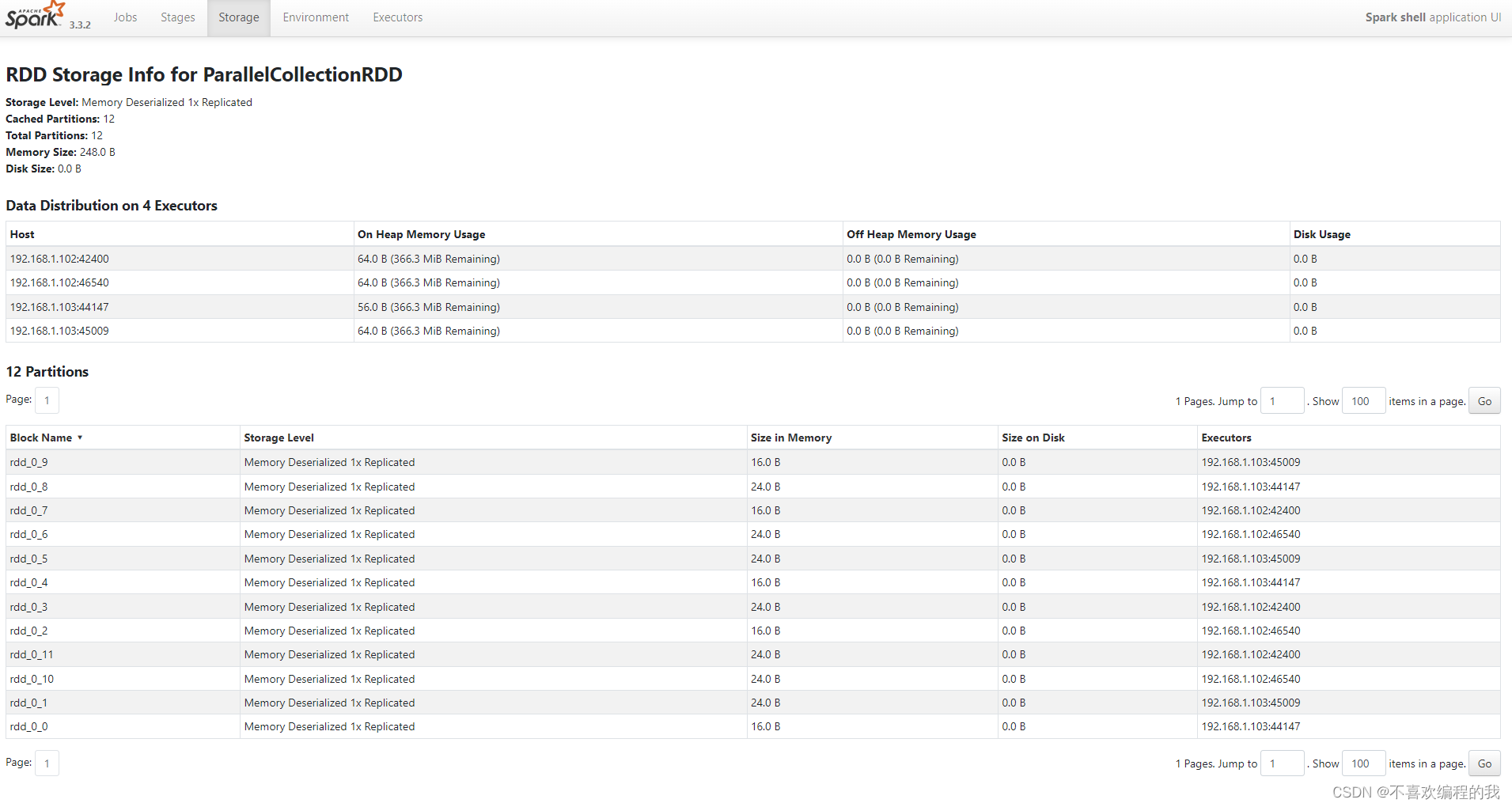
刷新WebUI,发现出现了一个ParallelCollectionRDD的存储信息,该RDD的存储级别为MEMORY,持久化的分区为8,完全存储于内存中。

单击ParallelCollectionRDD超链接,可以查看该RDD的详细存储信息
执行以下命令,创建rdd2,并将rdd2持久化到磁盘

刷新上述WebUI,发现多了一个MapPartitionsRDD的存储信息,该RDD的存储级别为DISK,持久化的分区为8,完全存储于磁盘中。

(三)将RDD从缓存中删除

刷新上述WebUI,发现只剩下了MapPartitionsRDD,ParallelCollectionRDD已被移除。