一、问题分析
1, 环境
spark3.2 hadoop3.2.2
2, 问题现象
insert overwrite table到hive表时,出现路径不存在的报错,导致任务失败。
当表的路径在hdfs上时,没有问题。 表的路径在对象存储上时会有问题。
insert overwrite table带上分区路径也是没问题的。
具体报错:
org.apache.spark.sql.AnalysisException: Path does not exist: s3a://xxxx/hive/warehouse/tablename
at org.apache.spark.sql.errors.QueryCompilationErrors$.dataPathNotExistError(QueryCompilationErrors.scala:978)
at org.apache.spark.sql.execution.datasources.DataSource$.$anonfun$checkAndGlobPathIfNecessary$4(DataSource.scala:780)
at org.apache.spark.sql.execution.datasources.DataSource$.$anonfun$checkAndGlobPathIfNecessary$4$adapted(DataSource.scala:777)
3,问题原因分析
分析全量任务日志后发现,spark am失败了两次。
第一次失败是因为task中数据转换异常导致,属于业务异常。 但是,yarn的容错机制将spark am第二次启动起来的时候,报了 Path does not exist的异常。
在spark inseroverwrite的执行逻辑中,是先将表的路径删除,然后再写入。并且删除路径的动作,是在driver侧完成的。 表路径的再次创建是在task执行的时候做的。 所以该问题就是为什么task没有再次创建对象存储的表路径。首先梳理下task的写入逻辑(默认使用fileoutcommitter的1.0版本的算法),task写入数据前,会建临时目录,将数据写入到临时目录。
当一个task成功执行完毕的时候,通过commiter的commit task逻辑,将数据从临时目录转移到中间目录。 当所有的task都成功完成后,driver会调用commiter的commit job逻辑,将中间目录的数据转移到最终路径,也就是表路径下。需要注意的是,上述流程中涉及到的目录或者路径,如果不存在的话,会自动创建。
对于表路径在hdfs上的表,临时目录,中间目录,都在表路径之下。所以就算task有业务异常,临时目录在异常发生前已经创建了,表的路径同时也被创建了。 当am第二次执行的时候,是不会报 Path does not exist错误的。
对于表路径在对象存储的表,临时目录为本地目录,类似于/xx/xxx这种的。所以task有业务异常,没有创建表路径。 为什么临时目录为本地目录,因为该任务使用s3a协议去commit task和commit job。
所以问题就在于s3a协议上。
4,问题解决方案
不使用s3a协议去执行insert overwrite table。
set spark.sql.sources.commitProtocolClass=org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol;
set spark.sql.sources.outputCommitterClass=;
注意:不实用s3a协议的话,会严重影响commit性能,因为对象存储的mv或rename,都是先copy再delete。
3.parquet文件写入优化
set spark.sql.parquet.fs.optimized.committer.optimization-enabled=true;FileOutputCommitter的实际commitTask细节和参数 mapreduce.fileoutputcommitter.algorithm.version 有关(默认值是1)。
当mapreduce.fileoutputcommitter.algorithm.version=1时:
commit的操作是将 ${output.dir}/_temporary/${appAttemptId}/_temporary/${taskAttemptId} 重命名为 ${output.dir}/_temporary/${appAttemptId}/${taskId}
当mapreduce.fileoutputcommitter.algorithm.version=2时:
commit的操作是将 ${output.dir}/_temporary/${appAttemptId}/_temporary/${taskAttemptId} 下的文件移动到 ${output.dir} 目录下 (也就是最终的输出目录)
spark任务可以通过设置spark配置 spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=2来开启版本2的commit逻辑
在hadoop 2.7.0之前,FileOutputCommitter的实现没有区分版本,统一都是使用version=1的commit逻辑。因此如果spark的hadoop依赖包版本如果低于2.7.0,设置mapreduce.fileoutputcommitter.algorithm.version=2是没有用的
二、commit 原理详细介绍
Spark 输出数据到 HDFS 时,需要解决如下问题:
- 由于多个 Task 同时写数据到 HDFS,如何保证要么所有 Task 写的所有文件要么同时对外可见,要么同时对外不可见,即保证数据一致性
- 同一 Task 可能因为 Speculation 而存在两个完全相同的 Task 实例写相同的数据到 HDFS中,如何保证只有一个 commit 成功
- 对于大 Job(如具有几万甚至几十万 Task),如何高效管理所有文件
commit 原理
本文通过 Local mode 执行如下 Spark 程序详解 commit 原理
sparkContext.textFile("/json/input.zstd")
.map(_.split(","))
.saveAsTextFile("/jason/test/tmp")
|
在详述 commit 原理前,需要说明几个述语
- Task,即某个 Application 的某个 Job 内的某个 Stage 的一个 Task
- TaskAttempt,Task 每次执行都视为一个 TaskAttempt。对于同一个 Task,可能同时存在多个 TaskAttemp
- Application Attempt,即 Application 的一次执行
在本文中,会使用如下缩写
- ${output.dir.root} 即输出目录根路径
- ${appAttempt} 即 Application Attempt ID,为整型,从 0 开始
- ${taskAttemp} 即 Task Attetmp ID,为整型,从 0 开始
检查 Job 输出目录
在启动 Job 之前,Driver 首先通过 FileOutputFormat 的 checkOutputSpecs 方法检查输出目录是否已经存在。若已存在,则直接抛出 FileAlreadyExistsException
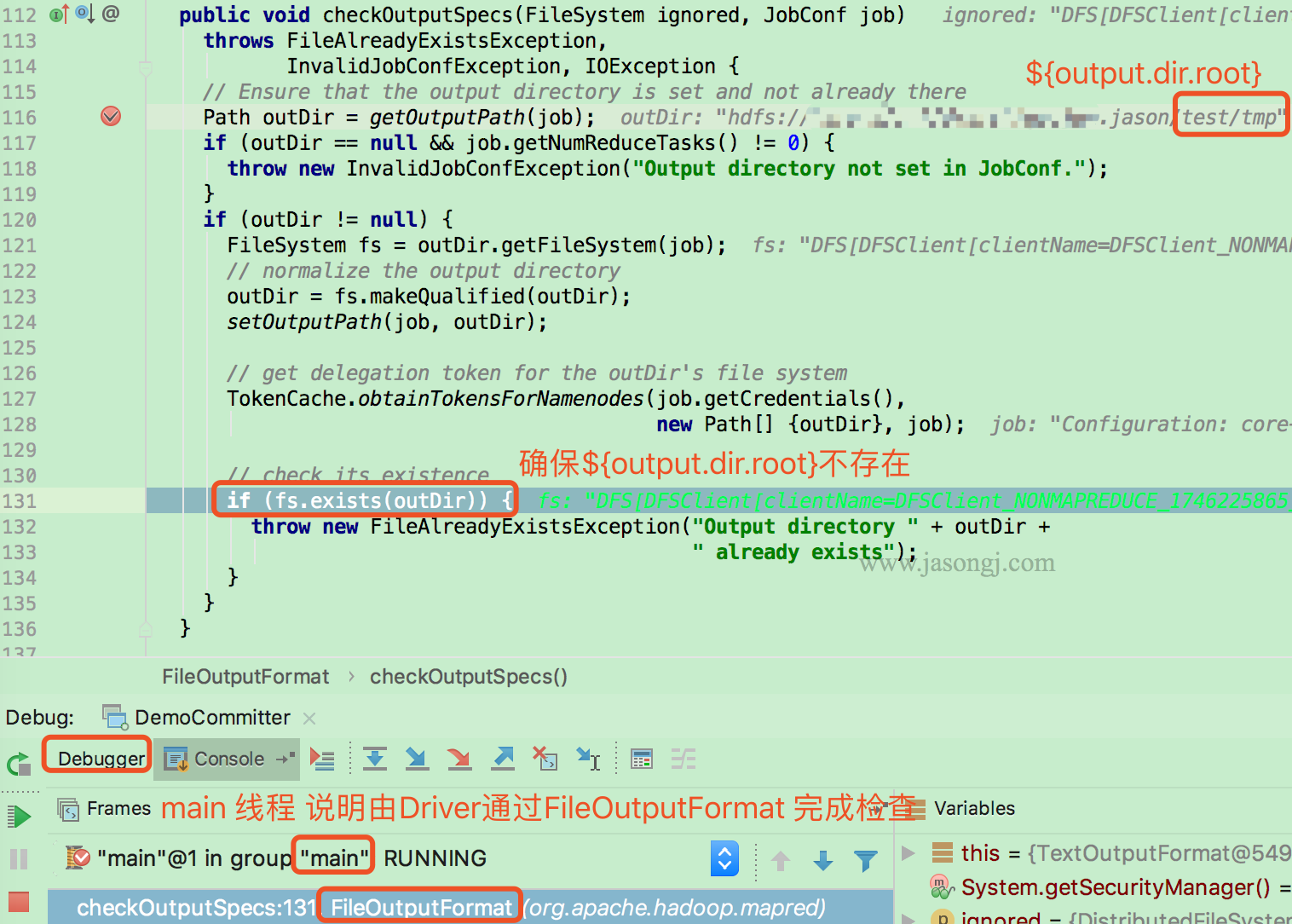
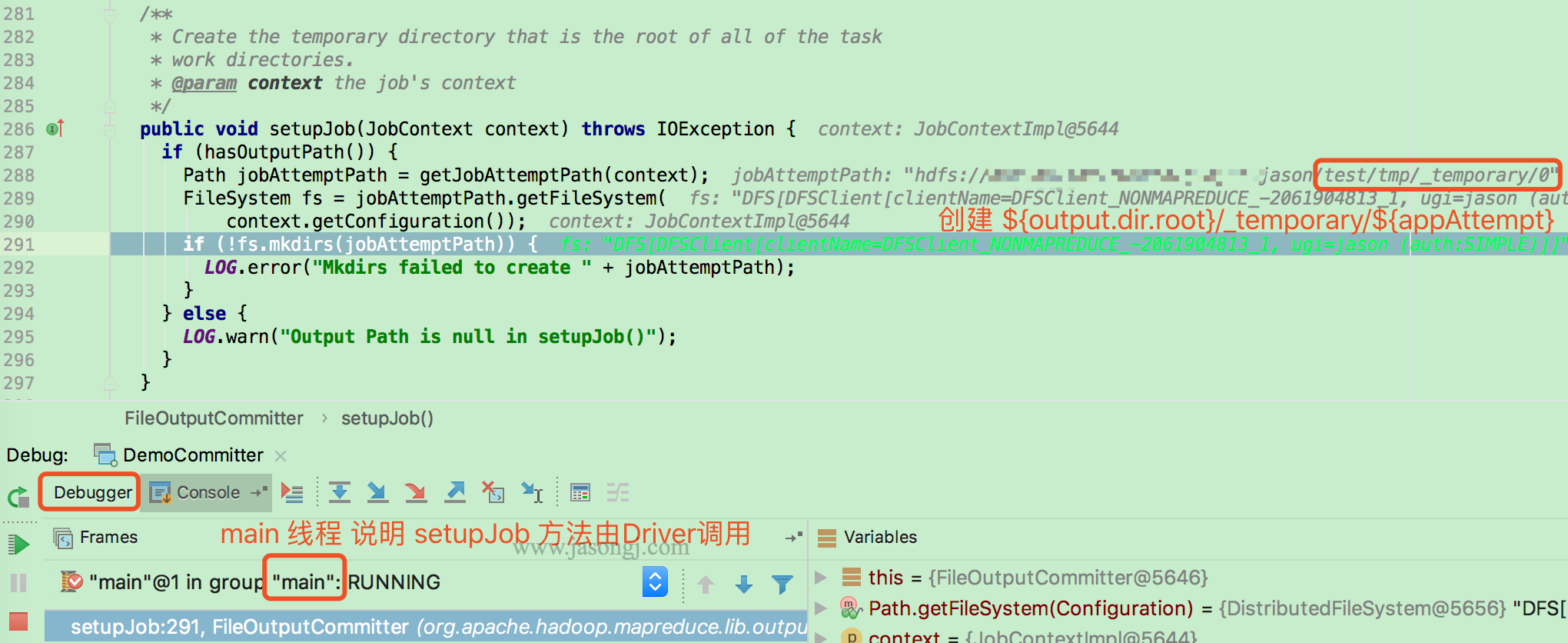
Driver执行setupJob
Job 开始前,由 Driver(本例使用 local mode,因此由 main 线程执行)调用 FileOuputCommitter.setupJob 创建 Application Attempt 目录,即 output.dir.root/temporary/xxxx/{appAttempt}
Task执行setupTask
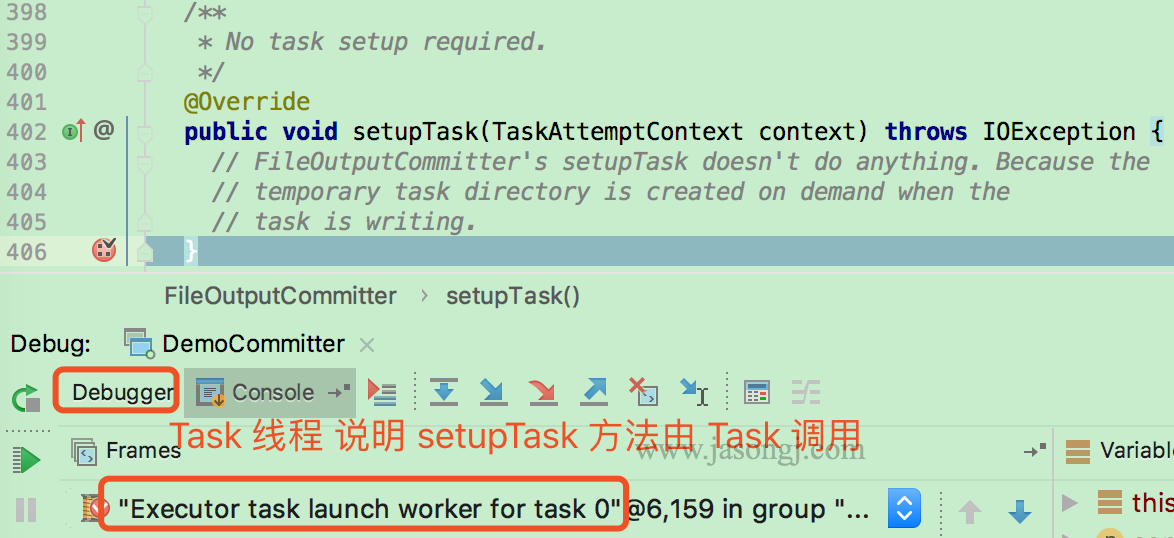
由各 Task 执行 FileOutputCommitter.setupTask 方法(本例使用 local mode,因此由 task 线程执行)。该方法不做任何事情,因为 Task 临时目录由 Task 按需创建。
按需创建 Task 目录
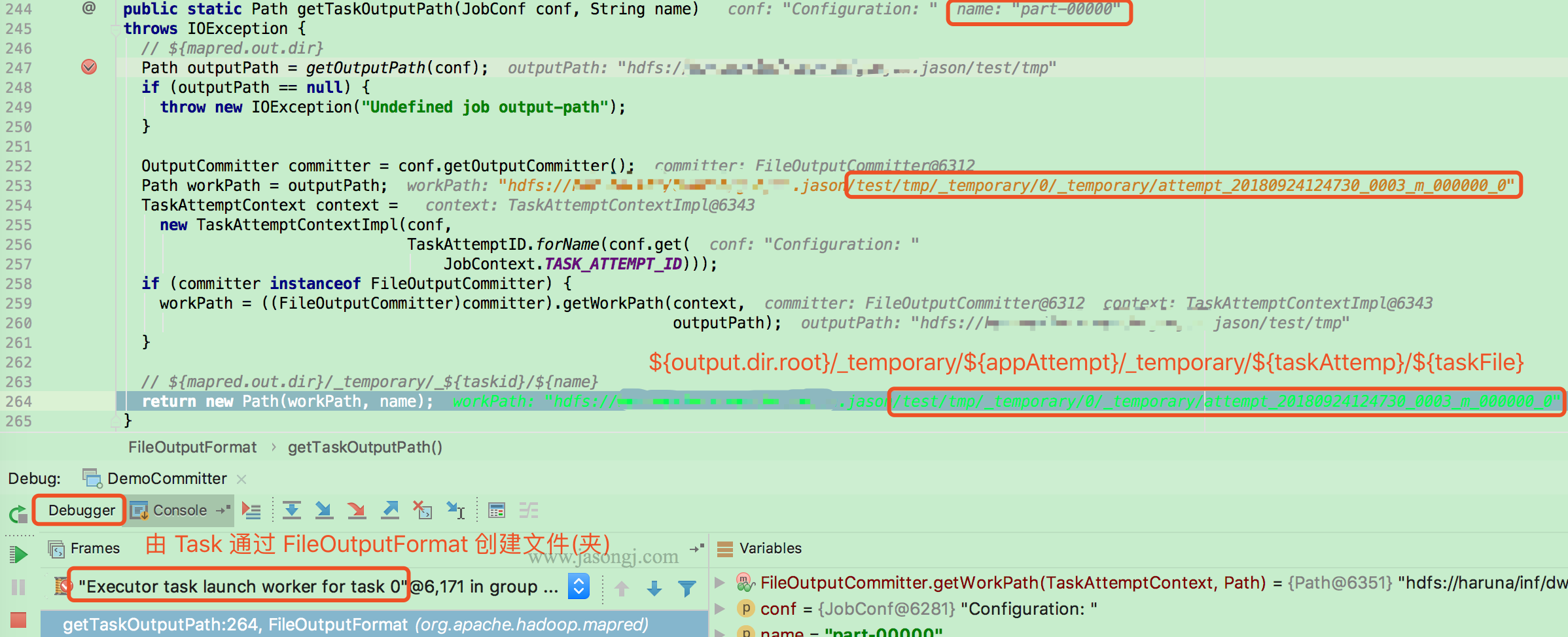
本例中,Task 写数据需要通过 TextOutputFormat 的 getRecordWriter 方法创建 LineRecordWriter。而创建前需要通过 FileOutputFormat.getTaskOutputPath设置 Task 输出路径,即 ${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt}/${fileName}。该 Task Attempt 所有数据均写在该目录下的文件内
检查是否需要 commit
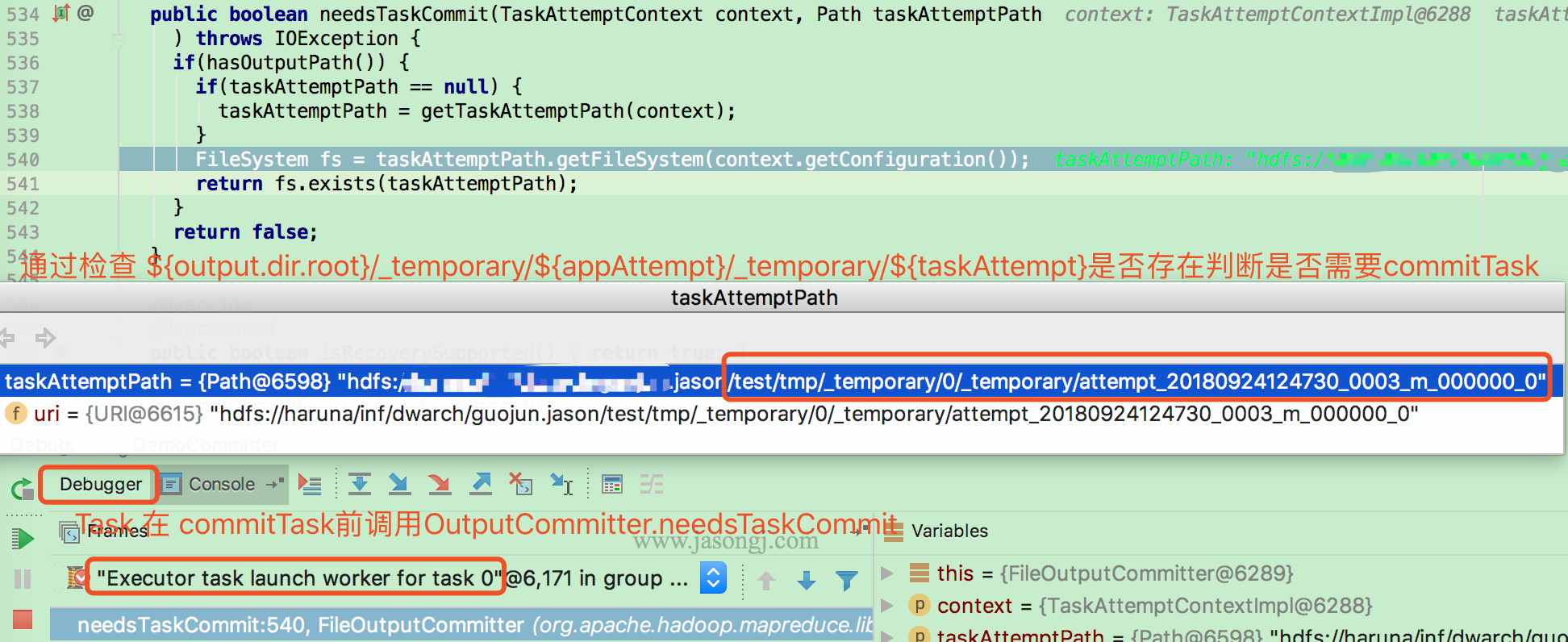
Task 执行数据写完后,通过 FileOutputCommitter.needsTaskCommit 方法检查是否需要 commit 它写在 ${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt} 下的数据。
检查依据是 ${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt} 目录是否存在
如果需要 commit,并且开启了 Output commit coordination,还需要通过 RPC 由 Driver 侧的 OutputCommitCoordinator 判断该 Task Attempt 是否可以 commit
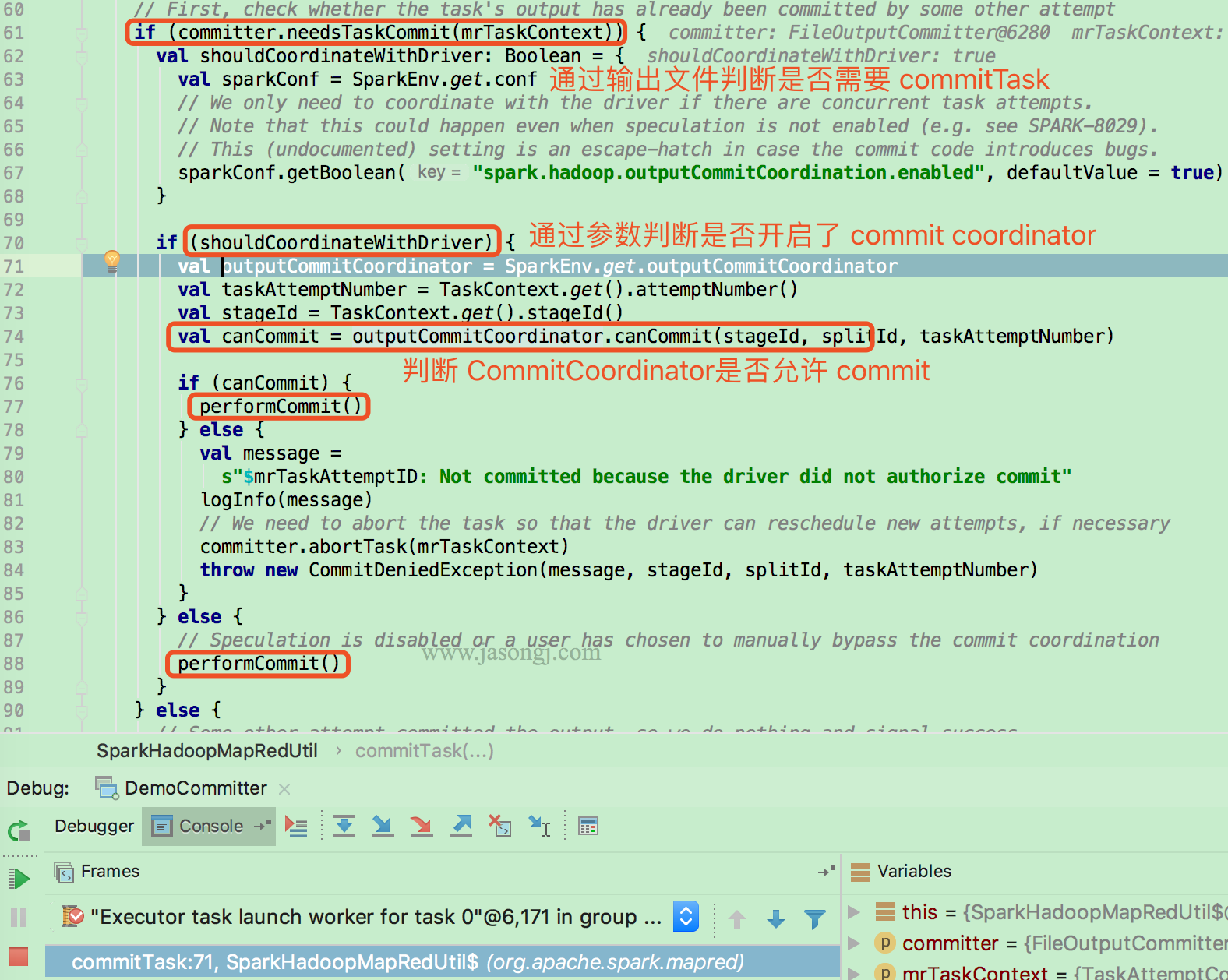
之所以需要由 Driver 侧的 CommitCoordinator 判断是否可以 commit,是因为可能由于 speculation 或者其它原因(如之前的 TaskAttemp 未被 Kill 成功)存在同一 Task 的多个 Attemp 同时写数据且都申请 commit 的情况。
CommitCoordinator
当申请 commitTask 的 TaskAttempt 为失败的 Attempt,则直接拒绝
若该 TaskAttempt 成功,并且 CommitCoordinator 未允许过该 Task 的其它 Attempt 的 commit 请求,则允许该 TaskAttempt 的 commit 请求
若 CommitCoordinator 之前已允许过该 TaskAttempt 的 commit 请求,则继续同意该 TaskAttempt 的 commit 请求,即 CommitCoordinator 对该申请的处理是幂等的。
若该 TaskAttempt 成功,且 CommitCoordinator 之前已允许该 Task 的其它 Attempt 的 commit 请求,则直接拒绝当前 TaskAttempt 的 commit 请求

OutputCommitCoordinator 为了实现上述功能,为每个 ActiveStage 维护一个如下 StageState
private case class StageState(numPartitions: Int) {
val authorizedCommitters = Array.fill[TaskAttemptNumber](numPartitions)(NO_AUTHORIZED_COMMITTER)
val failures = mutable.Map[PartitionId, mutable.Set[TaskAttemptNumber]]()
}
|
该数据结构中,保存了每个 Task 被允许 commit 的 TaskAttempt。默认值均为 NO_AUTHORIZED_COMMITTER
同时,保存了每个 Task 的所有失败的 Attempt
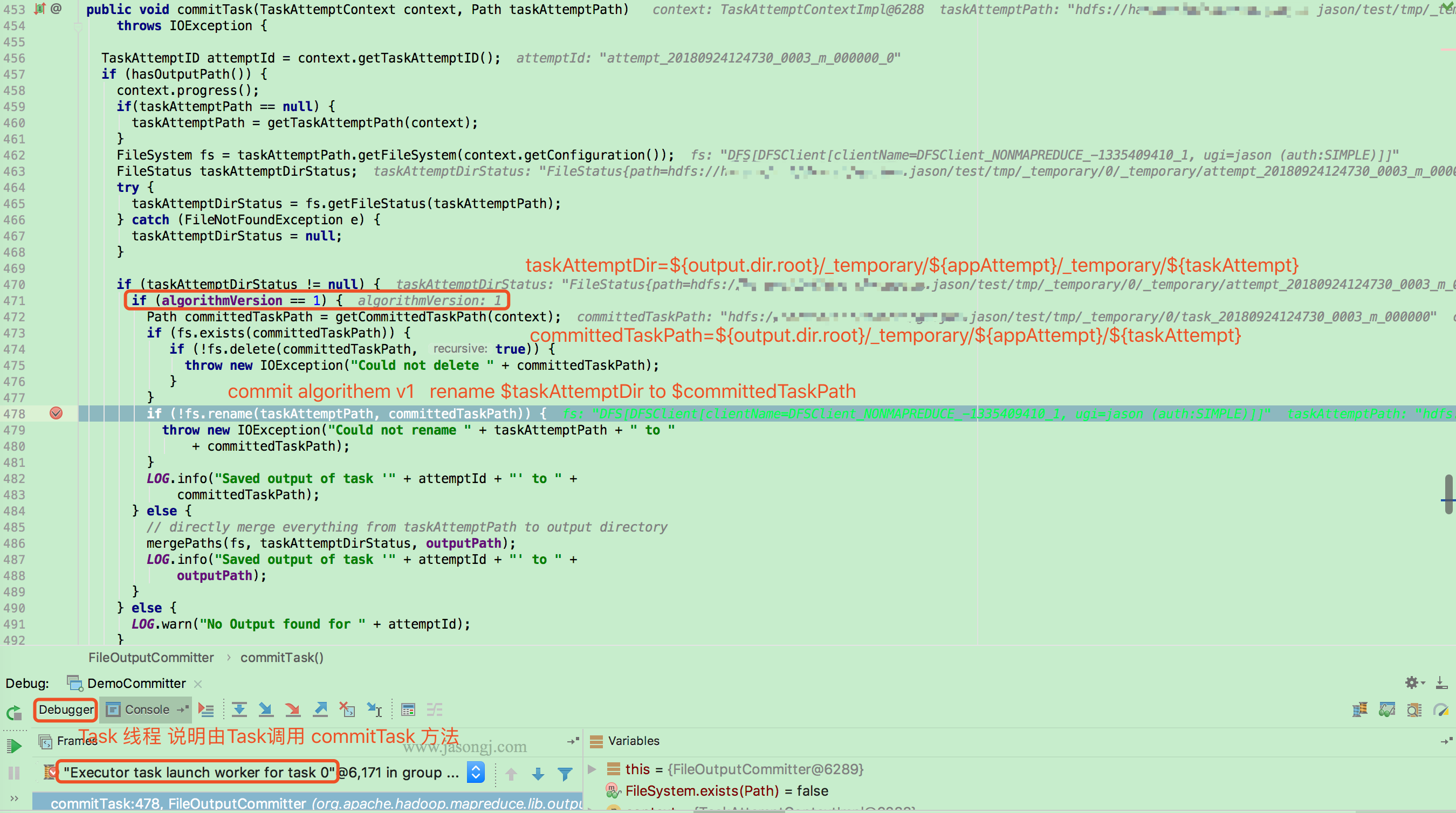
commitTask
当 TaskAttempt 被允许 commit 后,Task (本例由于使用 local model,因此由 task 线程执行)会通过如下方式 commitTask。
当 mapreduce.fileoutputcommitter.algorithm.version 的值为 1 (默认值)时,Task 将 taskAttemptPath 即 ${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt} 重命令为 committedTaskPath 即 ${output.dir.root}/_temporary/${appAttempt}/${taskAttempt}
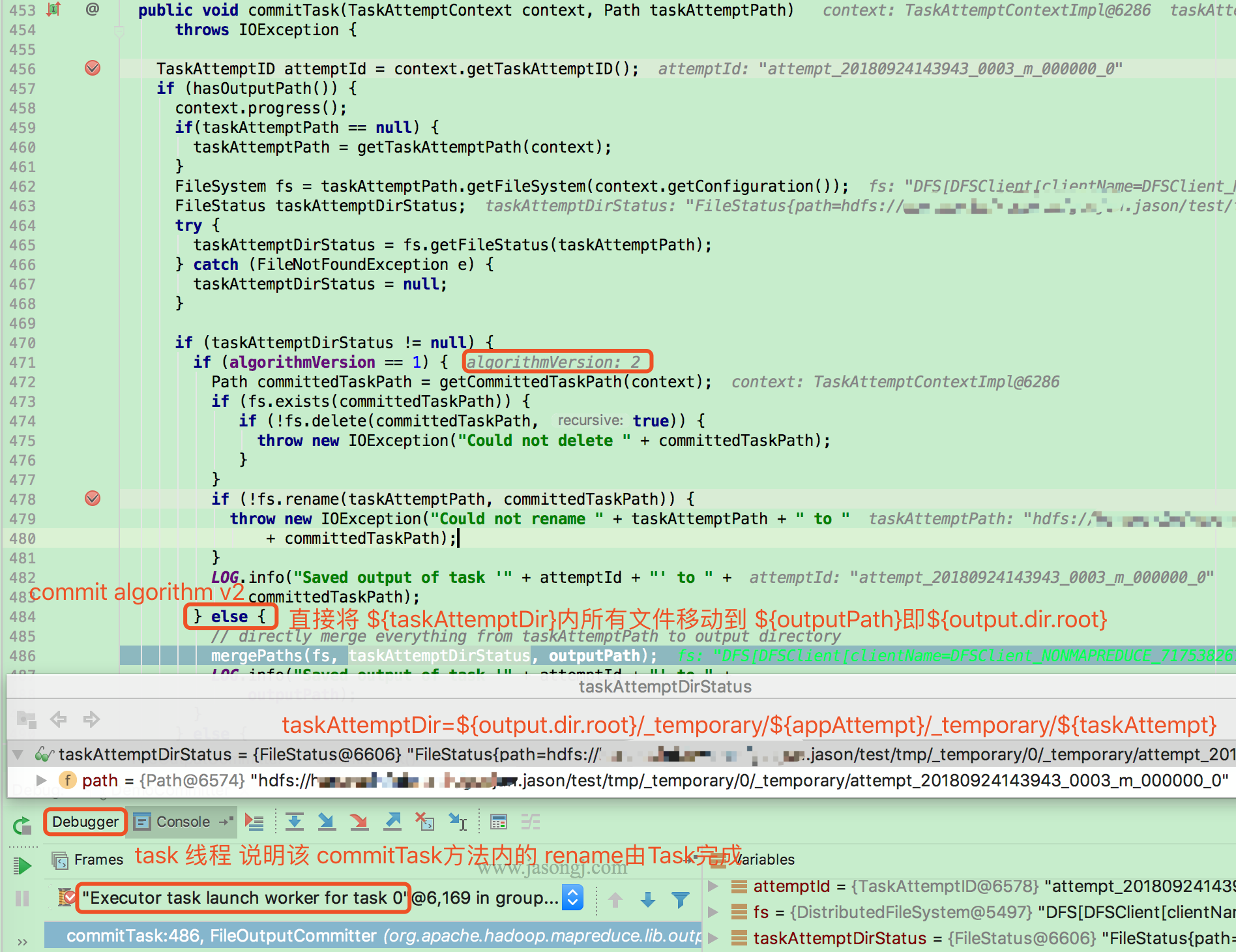
若 mapreduce.fileoutputcommitter.algorithm.version 的值为 2,直接将taskAttemptPath 即 ${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt} 内的所有文件移动到 outputPath 即 ${output.dir.root}/
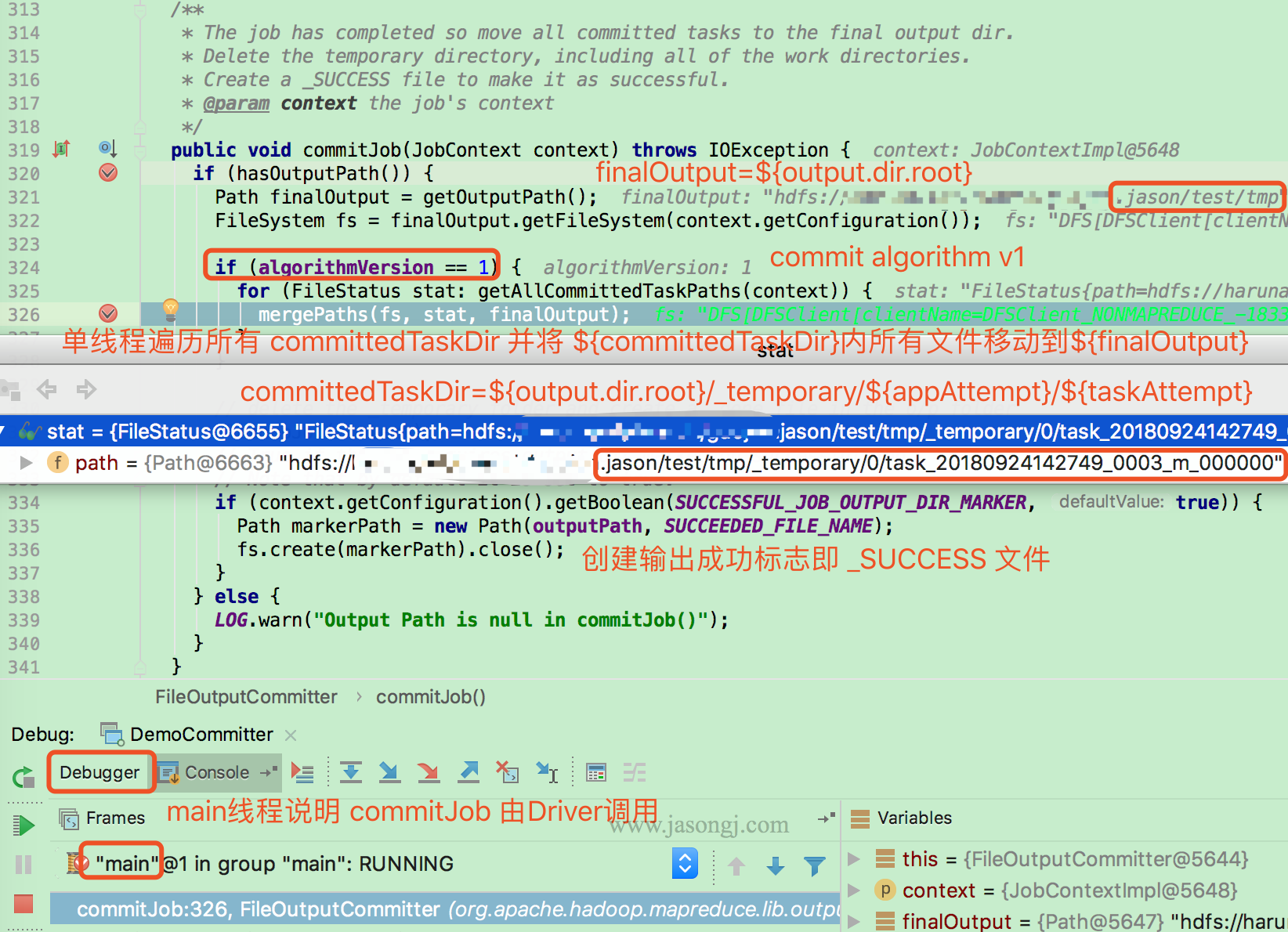
commitJob
当所有 Task 都执行成功后,由 Driver (本例由于使用 local model,故由 main 线程执行)执行 FileOutputCommitter.commitJob
若 mapreduce.fileoutputcommitter.algorithm.version 的值为 1,则由 Driver 单线程遍历所有 committedTaskPath 即 ${output.dir.root}/_temporary/${appAttempt}/${taskAttempt},并将其下所有文件移动到 finalOutput 即 ${output.dir.root} 下
若 mapreduce.fileoutputcommitter.algorithm.version 的值为 2,则无须移动任何文件。因为所有 Task 的输出文件已在 commitTask 内被移动到 finalOutput 即 ${output.dir.root} 内
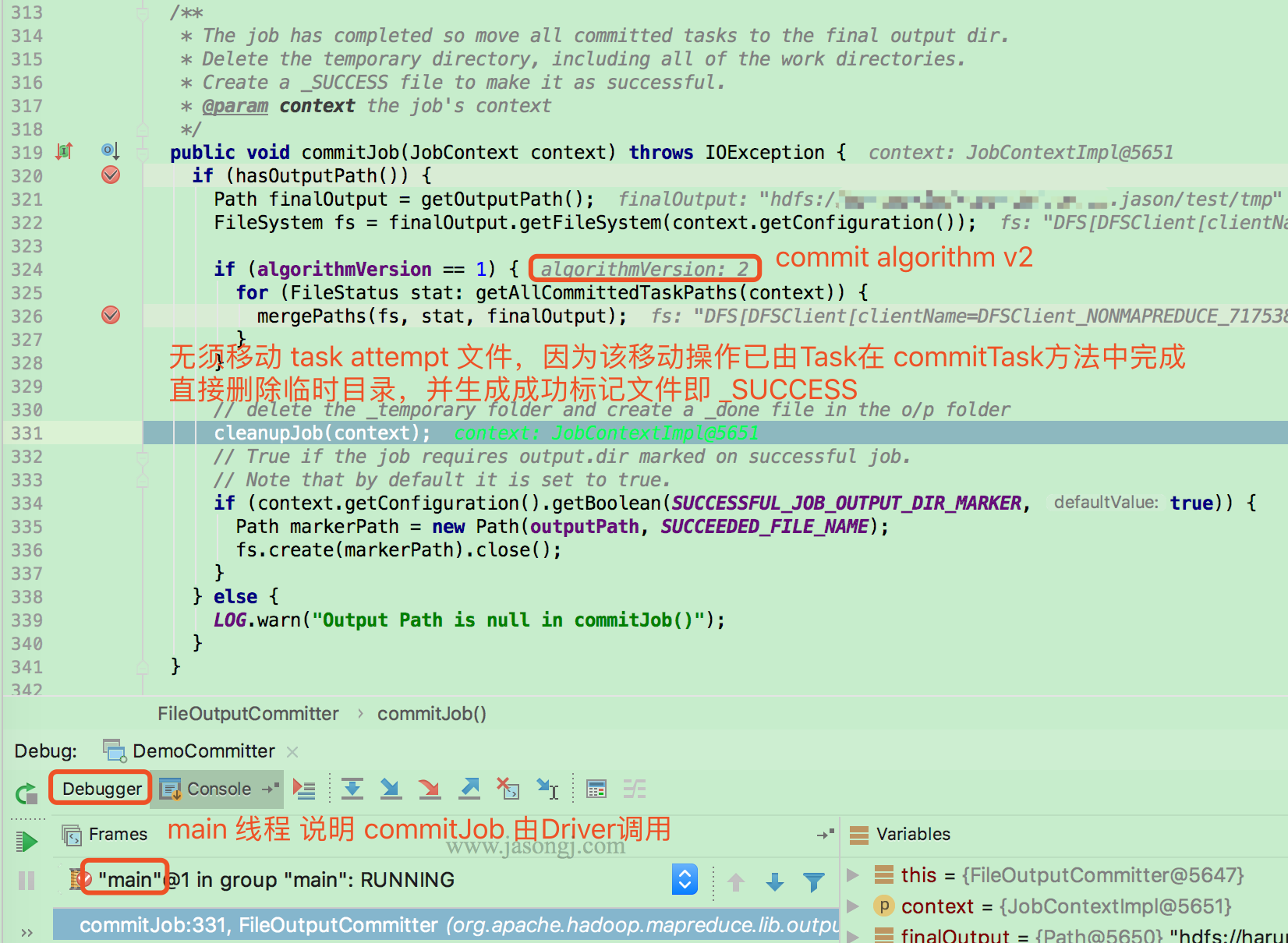
所有 commit 过的 Task 输出文件移动到 finalOutput 即 ${output.dir.root} 后,Driver 通过 cleanupJob 删除 ${output.dir.root}/_temporary/ 下所有内容
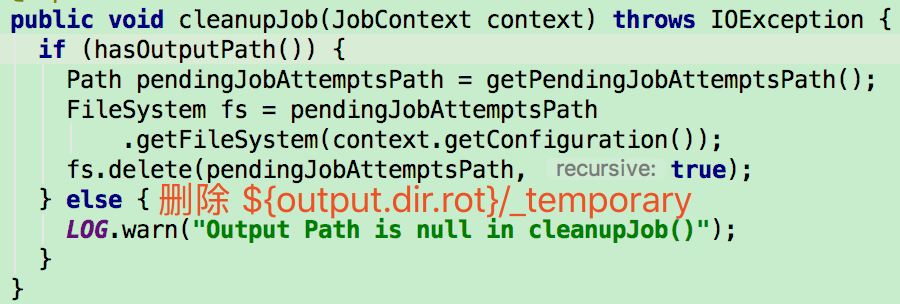
recoverTask
上文所述的 commitTask 与 commitJob 机制,保证了一次 Application Attemp 中不同 Task 的不同 Attemp 在 commit 时的数据一致性
而当整个 Application retry 时,在之前的 Application Attemp 中已经成功 commit 的 Task 无须重新执行,其数据可直接恢复
恢复 Task 时,先获取上一次的 Application Attempt,以及对应的 committedTaskPath,即 ${output.dir.root}/_temporary/${preAppAttempt}/${taskAttempt}
若 mapreduce.fileoutputcommitter.algorithm.version 的值为 1,并且 preCommittedTaskPath 存在(说明在之前的 Application Attempt 中该 Task 已被 commit 过),则直接将 preCommittedTaskPath 重命名为 committedTaskPath
若 mapreduce.fileoutputcommitter.algorithm.version 的值为 2,无须恢复任何数据,因为在之前 Application Attempt 中 commit 过的 Task 的数据已经在 commitTask 中被移动到 ${output.dir.root} 中

abortTask
中止 Task 时,由 Task 调用 FileOutputCommitter.abortTask 方法删除 ${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt}
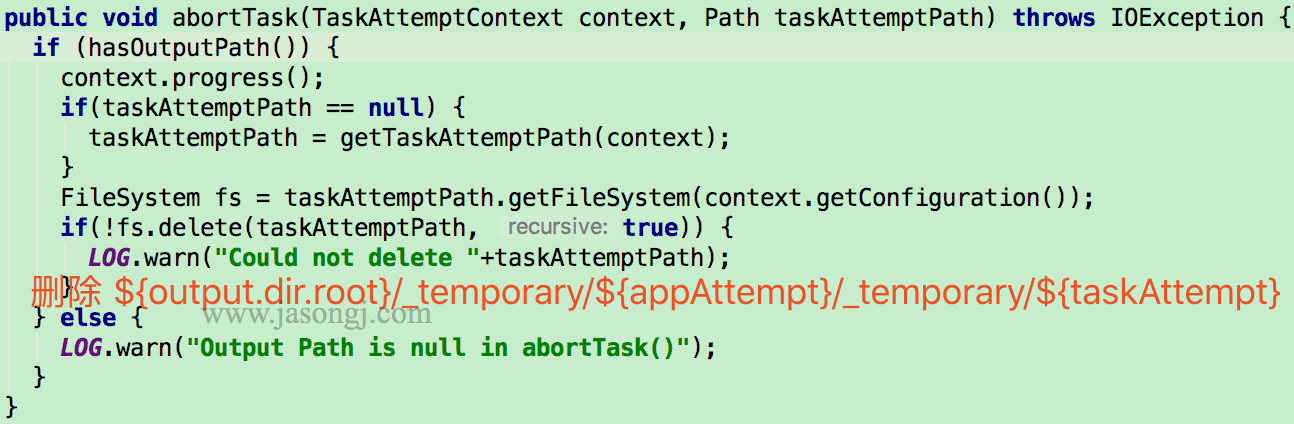
abortJob
中止 Job 由 Driver 调用 FileOutputCommitter.abortJob 方法完成。该方法通过 FileOutputCommitter.cleanupJob 方法删除 ${output.dir.root}/_temporary
总结
V1 vs. V2 committer 过程
V1 committer(即 mapreduce.fileoutputcommitter.algorithm.version 的值为 1),commit 过程如下
- Task 线程将 TaskAttempt 数据写入
${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt} - commitTask 由 Task 线程将
${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt}移动到${output.dir.root}/_temporary/${appAttempt}/${taskAttempt} - commitJob 由 Driver 单线程依次将所有
${output.dir.root}/_temporary/${appAttempt}/${taskAttempt}移动到${output.dir.root},然后创建_SUCCESS标记文件 - recoverTask 由 Task 线程将
${output.dir.root}/_temporary/${preAppAttempt}/${preTaskAttempt}移动到${output.dir.root}/_temporary/${appAttempt}/${taskAttempt}
V2 committer(即 mapreduce.fileoutputcommitter.algorithm.version 的值为 2),commit 过程如下
- Task 线程将 TaskAttempt 数据写入
${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt} - commitTask 由 Task 线程将
${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt}移动到${output.dir.root} - commitJob 创建
_SUCCESS标记文件 - recoverTask 无需任何操作
V1 vs. V2 committer 性能对比
V1 在 Job 执行结束后,在 Driver 端通过 commitJob 方法,单线程串行将所有 Task 的输出文件移动到输出根目录。移动以文件为单位,当 Task 个数较多(大 Job,或者小文件引起的大量小 Task),Name Node RPC 较慢时,该过程耗时较久。在实践中,可能因此发生所有 Task 均执行结束,但 Job 不结束的问题。甚至 commitJob 耗时比 所有 Task 执行时间还要长
而 V2 在 Task 结束后,由 Task 在 commitTask 方法内,将自己的数据文件移动到输出根目录。一方面,Task 结束时即移动文件,不需等待 Job 结束才移动文件,即文件移动更早发起,也更早结束。另一方面,不同 Task 间并行移动文件,极大缩短了整个 Job 内所有 Task 的文件移动耗时
V1 vs. V2 committer 一致性对比
V1 只有 Job 结束,才会将数据文件移动到输出根目录,才会对外可见。在此之前,所有文件均在 ${output.dir.root}/_temporary/${appAttempt} 及其子文件内,对外不可见。
当 commitJob 过程耗时较短时,其失败的可能性较小,可认为 V1 的 commit 过程是两阶段提交,要么所有 Task 都 commit 成功,要么都失败。
而由于上文提到的问题, commitJob 过程可能耗时较久,如果在此过程中,Driver 失败,则可能发生部分 Task 数据被移动到 ${output.dir.root} 对外可见,部分 Task 的数据未及时移动,对外不可见的问题。此时发生了数据不一致性的问题
V2 当 Task 结束时,立即将数据移动到 ${output.dir.root},立即对外可见。如果 Application 执行过程中失败了,已 commit 的 Task 数据仍然对外可见,而失败的 Task 数据或未被 commit 的 Task 数据对外不可见。也即 V2 更易发生数据一致性问题
三、V1和V2 commiter版本比较
mapreduce.fileoutputcommitter.algorithm.version 参数对文件输出有很大的影响,下面总结一下两种版本在各方面的优缺点。
1、性能方面
v1在task结束后只是将输出文件拷到临时目录,然后在job结束后才由Driver把这些文件再拷到输出目录。如果文件数量很多,Driver就需要不断的和NameNode做交互,而且这个过程是单线程的,因此势必会增加耗时。如果我们碰到有spark任务所有task结束了但是任务还没结束,很可能就是Driver还在不断的拷文件。
v2在task结束后立马将输出文件拷贝到输出目录,后面Job结束后Driver就不用再去拷贝了。
因此,在性能方面,v2完胜v1。
2、数据一致性方面
v1在Job结束后才批量拷文件,其实就是两阶段提交,它可以保证数据要么全部展示给用户,要么都没展示(当然,在拷贝过程中也无法保证完全的数据一致性,但是这个时间一般来说不会太长)。如果任务失败,也可以直接删了_temporary目录,可以较好的保证数据一致性。
v2在task结束后就拷文件,就会造成spark任务还未完成就让用户看到一部分输出,这样就完全没办法保证数据一致性了。另外,如果任务在输出过程中失败,就会有一部分数据成功输出,一部分没输出的情况。
因此在数据一致性方面,v1完胜v2
3、总结
很明显,如果我们执着于性能,不在乎数据输出时的一致性,完全可以将mapreduce.fileoutputcommitter.algorithm.version设置为2来提高性能。
但是如果我们对输出要求很高的数据一致性,那么最好不要为了性能将mapreduce.fileoutputcommitter.algorithm.version设置为2。