概述
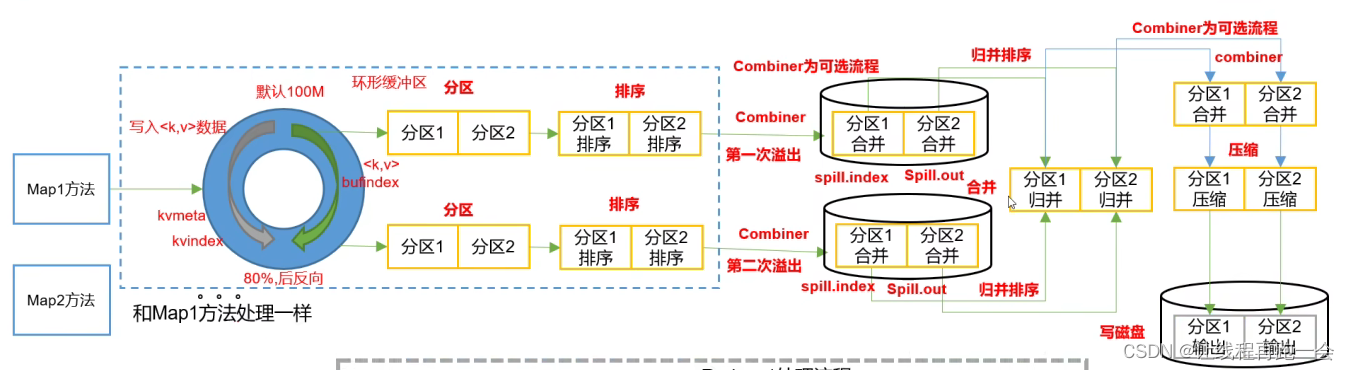
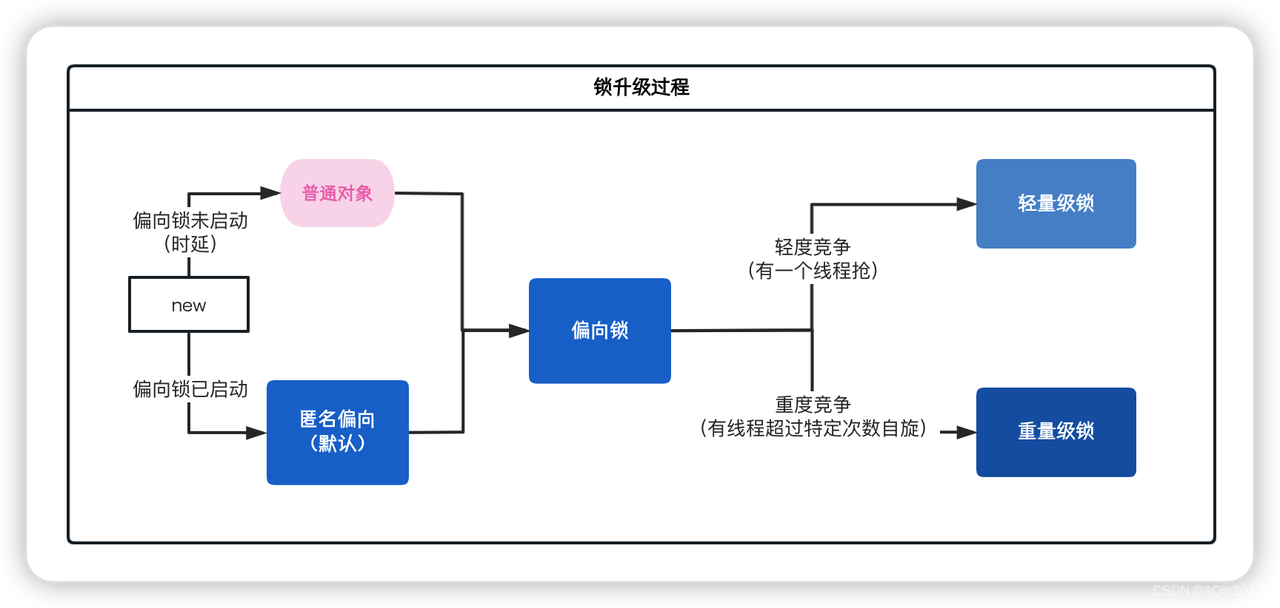
Conbiner在MapReduce的Shuffle阶段起作用,它负责局部数据的聚合,我们可以看到,对于大数据量,如果没有Combiner,将会在磁盘上写入多个文件等待ReduceTask来拉取,但是如果有Combiner组件,我们可以通过Combiner来减小中间结果文件的大小,从而增加传输的效率。
以wordcount为例,从map出来的kv已经经过了排序是有序的,我们可以进行一次Combiner将相同key的value进行一个合并,从而减少数据量。接着再进行一次归并排序,将多个溢写文件合并到一起。如果溢写的文件特别多,一次归并排序不能全部合并(默认一次归并10个溢写文件),可以再进行一次归并。最终只有一个中间结果文件产生。
- Combiner是MapReduce程序中Mapper和Reducer之外的一个组件。
- Combiner组件的父类就是Reducer
- Combiner和Reducer的区别在于运行的位置
- Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来。
- 比如wordcount案例,我们可以对它增加一个Combiner,因为这样不会影响最终结果。
- 但是对于求平均值这种案例,比如(3+5+7+2+6)/5 != (3+5+7)/3 + (2+6)/2
实现
Combiner只需要继承Reducer类并重写reduce方法即可,我们只需要在wordcount案例基础之上增加一个类WordCountCombiner并在Runner类中修改job的属性即可。
WordCountCombiner类
public class WordCountCombiner extends Reducer<Text, LongWritable,Text,LongWritable> {
private LongWritable OUT_KEY = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
OUT_KEY.set(sum);
context.write(key,OUT_KEY);
}
}修改job属性
//设置combiner
job.setCombinerClass(WordCountCombiner.class);