本文介绍基于Python语言,针对一个文件夹下大量的Excel表格文件,基于其中每一个文件,随机从其中选取一部分数据,并将全部文件中随机获取的数据合并为一个新的Excel表格文件的方法。
首先,我们来明确一下本文的具体需求。现有一个文件夹,其中有大量的Excel表格文件(在本文中我们就以.csv格式的文件为例);如下图所示。
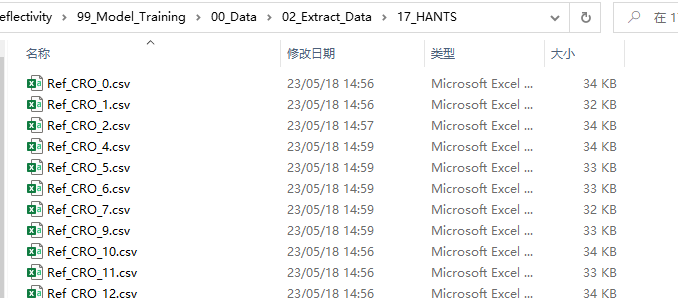
其中,每一个Excel表格文件都有着如下图所示的数据格式;其中的第1行表示每一列的名称,第1列则表示时间。

我们希望实现的,就是从每一个Excel表格文件中,随机选取10行数据(第1行数据肯定不能被选进去,因为其为列名;第1列数据也不希望被选进去,因为这个是表示时间的数据,我们后期不需要),并将这一文件夹中全部的Excel表格文件中每一个随机选出的10行数据合并到一起,作为一个新的Excel表格文件。
明白了需求,我们即可开始代码的撰写;本文用到的具体代码如下所示。
# -*- coding: utf-8 -*-
"""
Created on Fri May 19 01:47:06 2023
@author: fkxxgis
"""
import os
import pandas as pd
original_path = "E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/19_2022Data"
result_path = "E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/20_Train_Model"
result_df = pd.DataFrame()
for file in os.listdir(original_path):
if file.endswith(".csv"):
df = pd.read_csv(os.path.join(original_path, file))
sample_df = df.sample(n = 10, axis = 0)
sample_df = sample_df.iloc[ : , 1 : ]
result_df = pd.concat([result_df, sample_df])
result_df.to_csv(os.path.join(result_path, "Train_Model_1.csv"), index = False)
代码中首先定义了原始数据文件夹(也就是有大量Excel表格文件的文件夹)路径和结果数据文件夹路径。然后,创建了一个空的DataFrame,用于存储抽样后的数据。
接下来是一个for循环,遍历了原始数据文件夹中的所有.csv文件,如果文件名以.csv结尾,则读取该文件。然后,使用Pandas中的sample()函数随机抽取了该文件中的10行数据,并使用iloc[]函数删除了10行数据中的第1列(为了防止第1列表示时间的列被选中,因此需要删除)。最后,使用Pandas中的concat()函数将抽样后的数据添加到结果DataFrame中。
最后,使用Pandas中的to_csv()函数将结果DataFrame保存到结果数据文件夹中,文件名为Train_Model_1.csv,并设置index = False表示不保存索引。
运行上述代码,我们即可获得数据合并后的文件,且第1列数据也已经被剔除了。
至此,大功告成。
欢迎关注:疯狂学习GIS











![[技术分享]Android平台实时音视频录像模块设计之道](https://img-blog.csdnimg.cn/4ed38d30c8834706a111301cbef140af.jpeg)