查询结果排序
排序
规则如下:
1.语句:
SELECT A1,A2....
FROM 表名
WHERE 选择条件
order by 属性1(ASC升序),属性3(DESC降序);如果没有说明默认是升序排列:

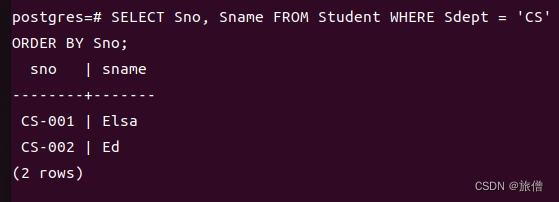

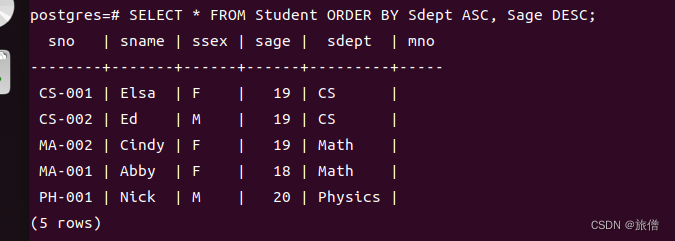
2.对于空值的处理 如果是升序排列 NULL放在最后一行,如果是降序则放在第一行
上图为 按升序排列查询的结果
3.Order by 通常 只对最终结果排序 不对中间的结果排序 这个和我们之后要讲到的嵌套查询有关,
不用管中间的嵌套是什么 order by最后只是展现在我们面前的样子。
限制查询结果的数量
Limit语句
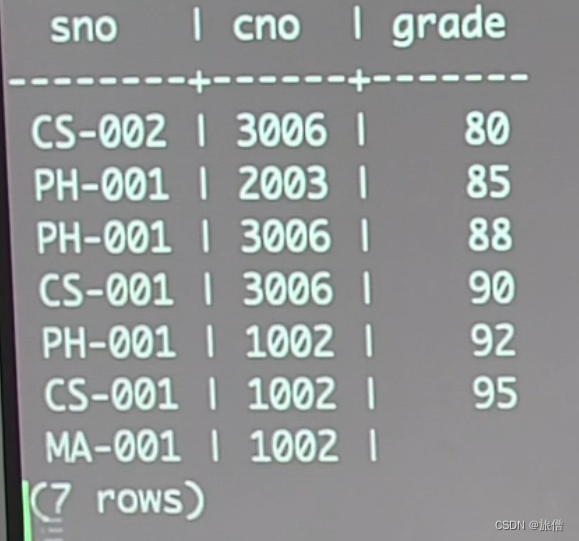
举一个简单的例子:查询选修某一课程的最高分的前两名
思路: 1. 将成绩排序 2.限制查询结果的数量
SELECT Sno,Grade FROM SC where Cno = '3006' ORDER BY GRADE DESC LIMIT2;
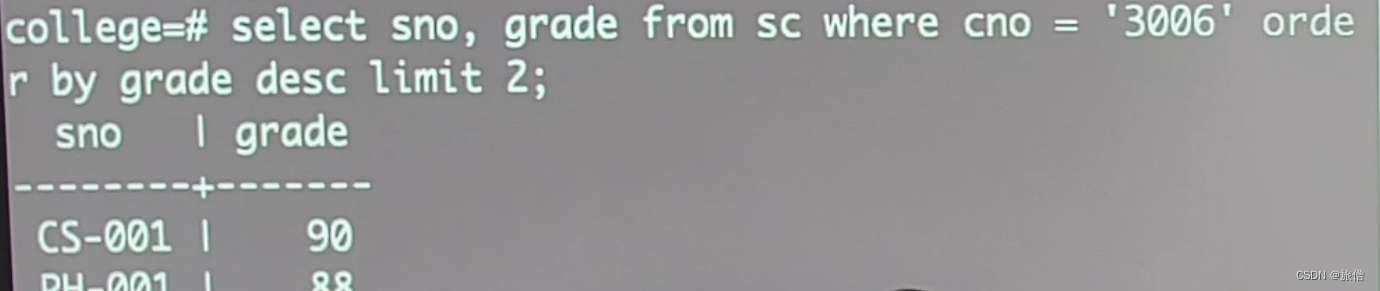 Offset语句 可以搭配limit一起使用
Offset语句 可以搭配limit一起使用
查询成绩在第二名和第三名之间的学生成绩
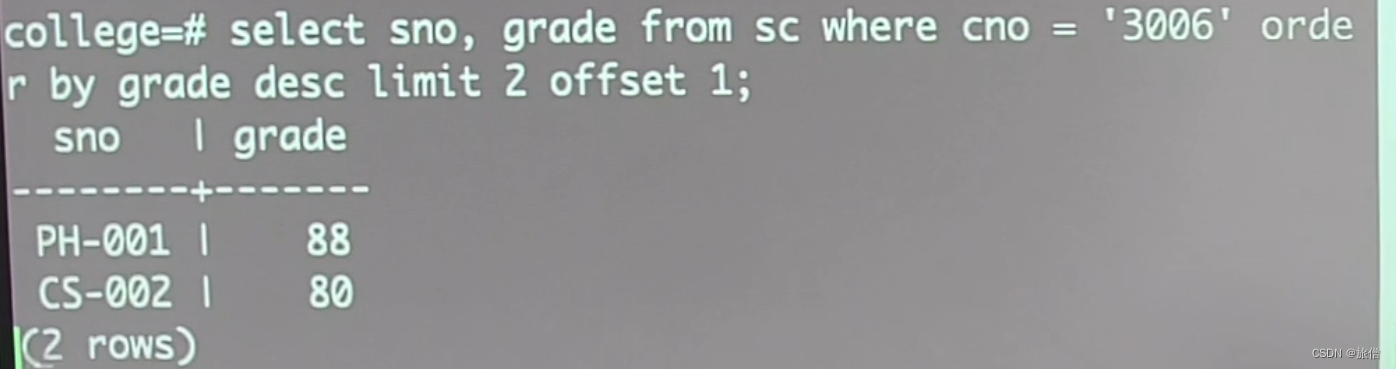
从偏移开始后边的两条元组直接输出出来
聚集
按照几个属性作为分组属性分组 元组分完组之后可以在上面做聚集,求最大值最小值 平均值
常见的聚集函数

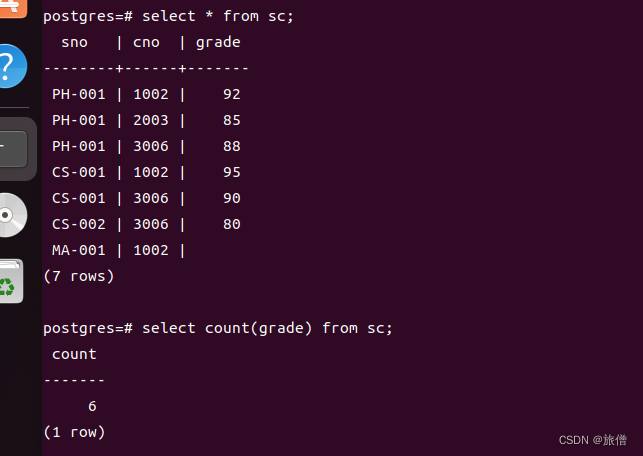
通过实验验证发现count不计算空值
查询最高分和最低分的几种方法
这个例子比较特殊因为grade 里面包含了空值
select max(grade) from sc;//使用聚集函数
select grade from sc where grade is not null order by grade desc limit 1;//思考为啥需要加not null 查看上方的order by查询
查询最低分
select min(grade) from sc;
select grade from sc oder by grade limit 1;//不需要加not null 因为null在最后一行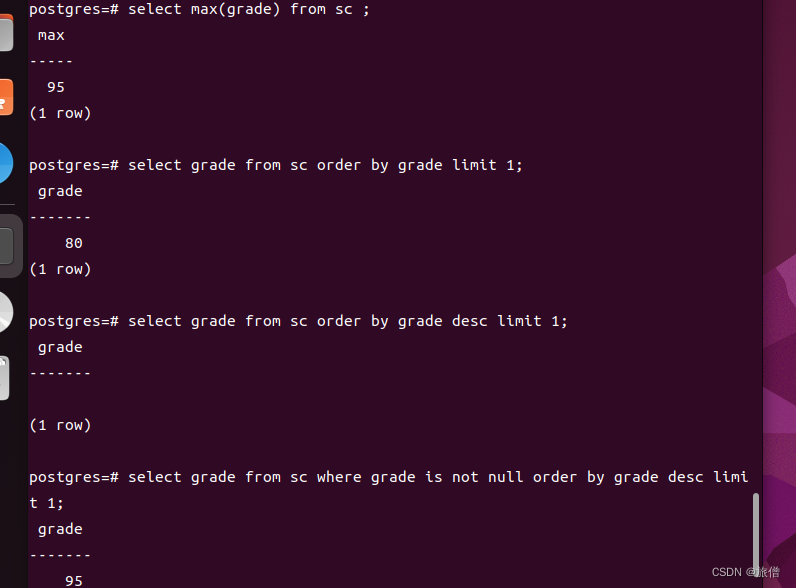
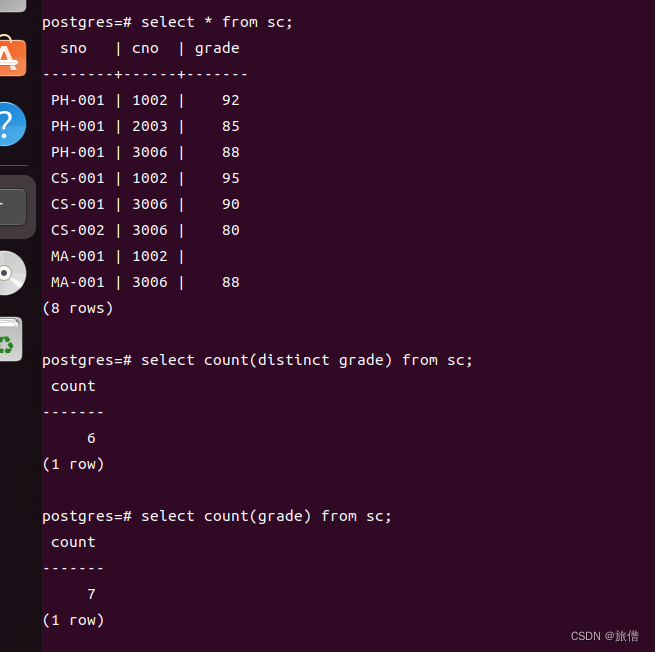
count(*)和count(属性)的区别count(*)连空的都包括 count(属性)只计算非空值
count可以和distinct一起搭配使用 查询不重的分数
聚集函数不能出现在where子句中:

分组查询GROUP BY
语法:
GROUP BY A1,A2;案例:
统计选课人数和平均成绩。
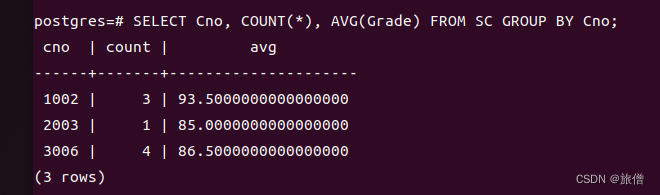
还是一样空值不参与运算。
分组查询之后筛选 HAVING 语句
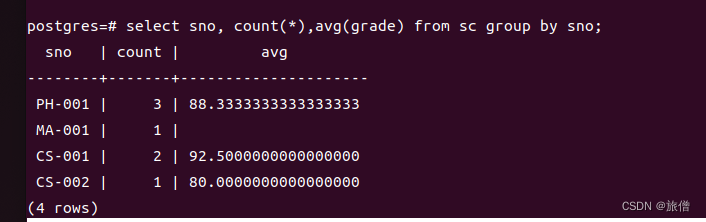
比如报名参加运动会 将每个学院参加的人数做一个统计 但是小于三十人的视为无效
GROUP BY A1,A2 HAVING 条件;没加having之前
加了having 之后
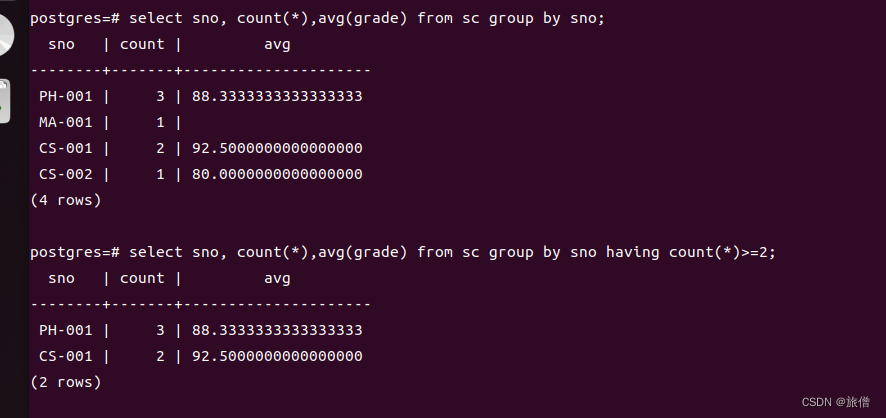
having 相当于一个选择条件选择条件作用在分组上。
分组查询的执行过程
 窗口函数
窗口函数
用法举例
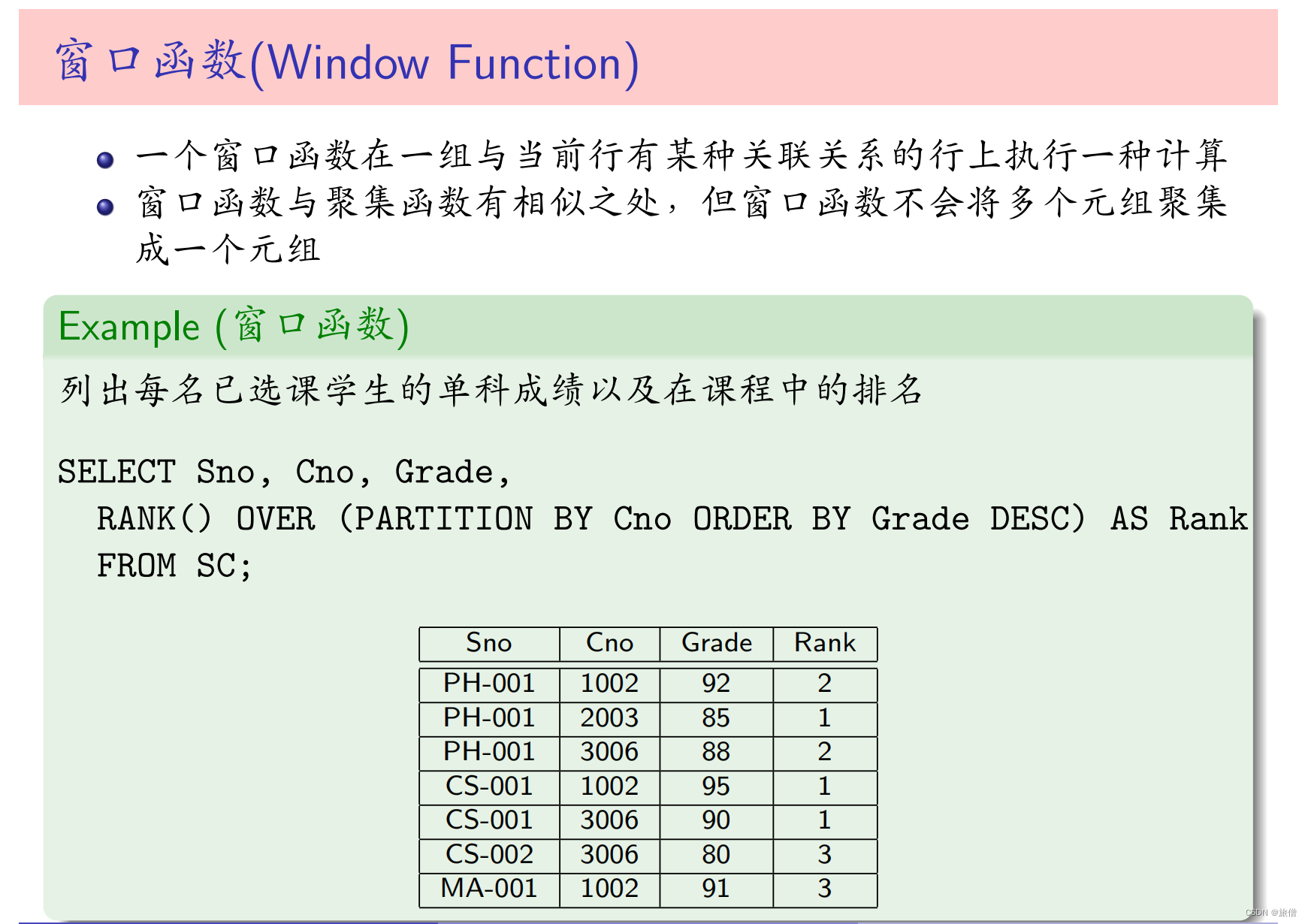
和GROUP BY的区别就是既能进行分组又能进行保留原始数据 不至于把他"拍扁";