1. BiFPN特征融合
BiFPN是目标检测中神经网络架构设计的选择之一,为了优化目标检测性能而提出。主要用来进行多尺度特征融合,对神经网络性能进行优化。来自EfficientDet: Scalable and Efficient Object Detection这篇论文。
在这篇论文中,作者主要贡献如下:
- 首先,提出了一种加权双向特征金字塔网络(BIFPN),该网络可以简单快速的实现多尺度特征融合
- 其次,提出了一种Compound Scaling方法,该方法可以同时对所有的主干网络、特征网络和框/类预测网络的分辨率、深度和宽度进行统一缩放
双向特征金字塔网络BIFPN
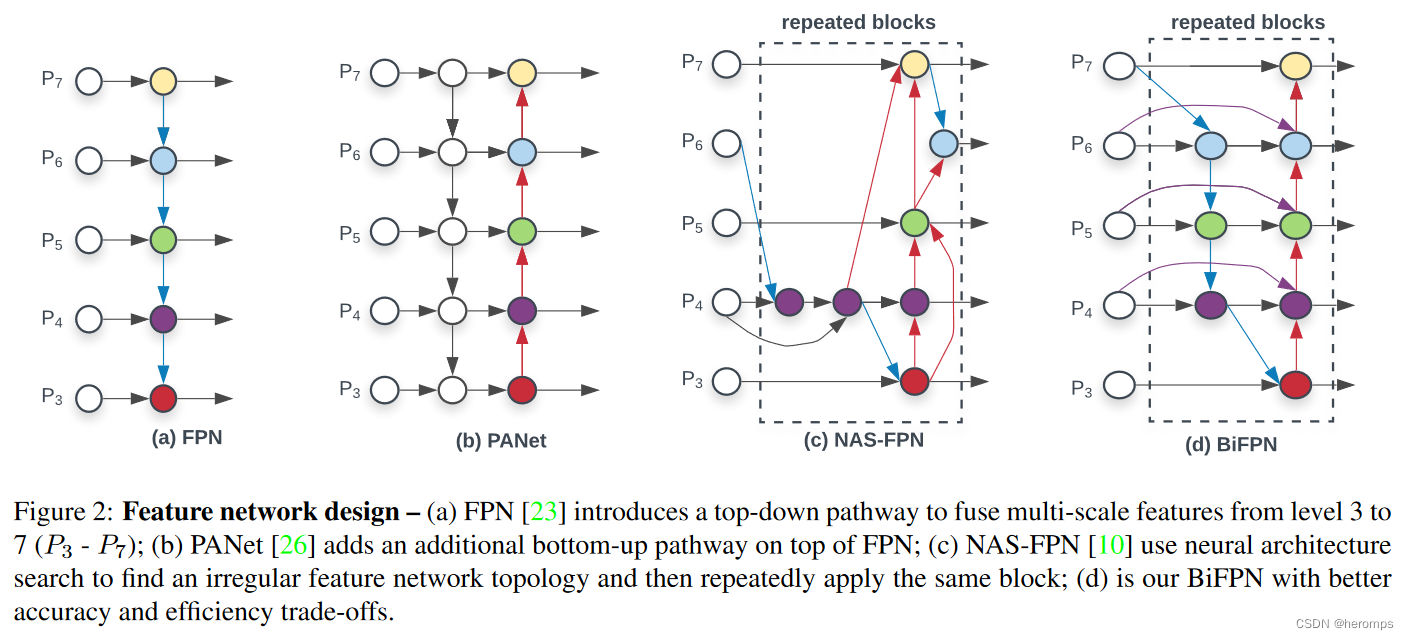
对于多尺度特征统合,在融合不同的输入特征时,以往的研究(FPN以及一些对FPN的改进工作)大多是没有去别的特征相加;然而由于这些不同的输入特征具有不同的分辨率,因此对特征融合的贡献往往也是不平等的。
为了解决这个问题,作者提出了一种简单却有效的加权特征金字塔网络BiFPN,引入了可学习的全职来学习不同输入特征的贡献,同时反复应用自顶而下和自下而上的多尺度特征融合。 - 新的Neck部分—BiFPN:多尺度特征融合的目的,是聚合不同分辨率的特征;以往的特征融合方法对所有输入特征一视同仁,为了解决这个问题,BiFPN引入了加权策略(类似于attention,SENet中的注意力通道)
FPN:p3-p7是输入图像的下采样,分辨率分别为输入图像的 1 / 2 i 1/2^i 1/2i,最后特征融合的公式为:
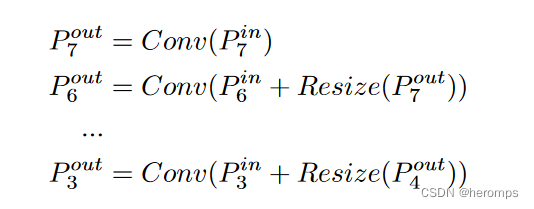
其中,Resize的通常操作是upsampling 或者 downsampling - 加权:加上一个可学习的权重,也就是 O = ∑ i w i ⋅ I i O=\sum_iw_i\cdot I_i O=∑iwi⋅Ii,其中 w i w_i wi是一个可学习的参数,如果不对 w i w_i wi进行限制,很容易导致训练不稳定,于是作者很自然的想到了对每个权重使用softmax,即 O = ∑ i e i w ϵ + ∑ j w j ⋅ I i O = \sum_i \frac{e^w_i}{\epsilon + \sum_j w_j}\cdot I_i O=∑iϵ+∑jwjeiw⋅Ii,但是这样速度太慢了,于是又提出了加速限制方法 O = ∑ i w i ϵ + ∑ j w j ⋅ I i O = \sum_i \frac{w_i}{\epsilon + \sum_j w_j}\cdot I_i O=∑iϵ+∑jwjwi⋅Ii
- 双向 :最终的特征图结合了双向尺度链接和快速归一化融合。
具体例子由下图所描述:
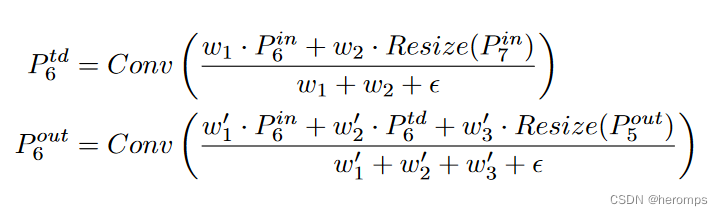
2. yolov5添加BiFPN(以yolov5s为例)
2.1 修改yolov5s.yaml
BiFPN_Add本质是add操作,不是concat操作,因此,BiFPN_Add的各个输入层要求大小完全一致(通道数、feature map大小等),因此,这里要修改之前的参数[-1, 13, 6],来满足这个要求:
- -1层就是上一层的输出,原来上一层的输出channel数为256,这里改成512
- 13层就是这里[-1, 3, C3, [512, False]], # 13
- 这样修改后,BiFPN_Add各个输入大小都是[bs,256,40,40]
- 最后BiFPN_Add后面的参数层设置为[256, 256]也就是输入输出channel数都是256
将concat替换成BIFPN_ADD
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 BiFPN head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, BiFPN_Add2, [256, 256]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, BiFPN_Add2, [128, 128]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [512, 3, 2]], # 为了BiFPN正确add,调整channel数
[[-1, 13, 6], 1, BiFPN_Add3, [256, 256]], # cat P4 <--- BiFPN change 注意v5s通道数是默认参数的一半
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Add2, [256, 256]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
** 打印模型参数**
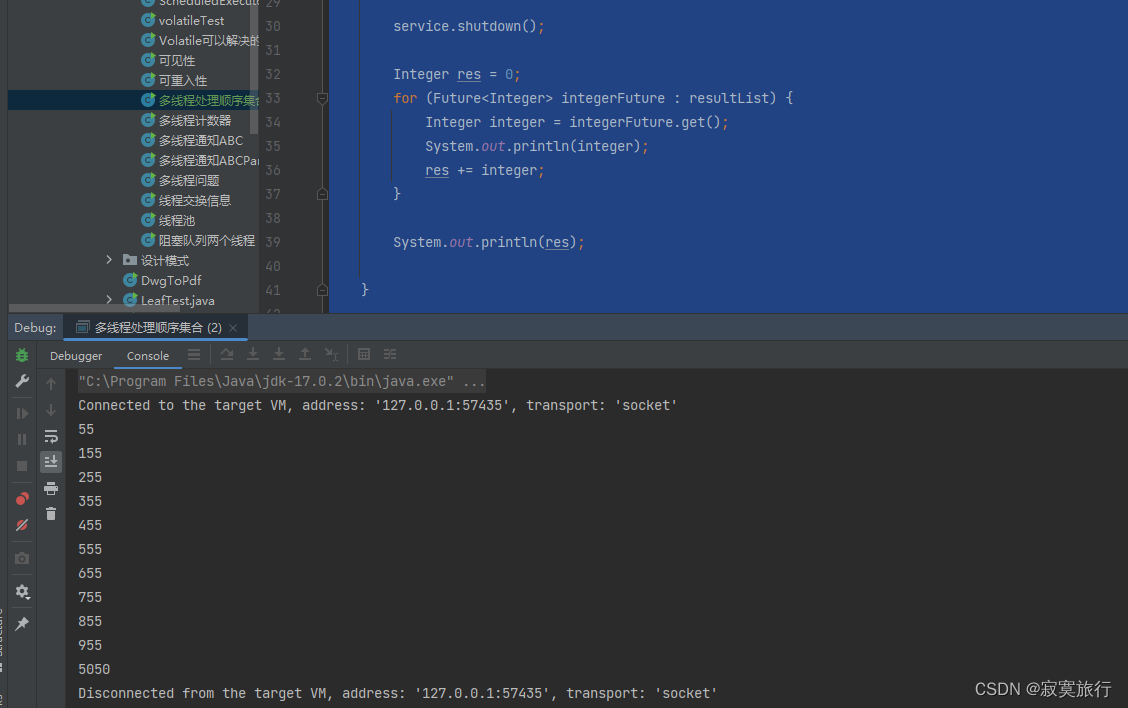
对模型文件进行测试并查看输出结果
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 65794 models.common.BiFPN_Add2 [256, 256]
13 -1 1 296448 models.common.C3 [256, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 16514 models.common.BiFPN_Add2 [128, 128]
17 -1 1 74496 models.common.C3 [128, 128, 1, False]
18 -1 1 295424 models.common.Conv [128, 256, 3, 2]
19 [-1, 13, 6] 1 65795 models.common.BiFPN_Add3 [256, 256]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 65794 models.common.BiFPN_Add2 [256, 256]
23 -1 1 1051648 models.common.C3 [256, 512, 1, False]
24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 278 layers, 7384006 parameters, 7384006 gradients, 17.2 GFLOPs
2.2 修改commen.py
添加下面的代码:
# 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支add操作
class BiFPN_Add2(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add2, self).__init__()
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1]))
# 三个分支add操作
class BiFPN_Add3(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add3, self).__init__()
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
2.3 修改yolo.py
在parse_model函数中找到elif m is Concat:语句,在其后面加上BiFPN_Add相关语句:
elif m is Concat:
c2 = sum(ch[x] for x in f)
# 添加bifpn_add结构
elif m in [BiFPN_Add2, BiFPN_Add3]:
c2 = max([ch[x] for x in f])
2.4 修改torch_utils.py
向优化器中添加BIFPN的权重参数,将BiFPN_Add2和BiFPN_Add3函数中定义的w参数,加入g[1]
from models.common import *
g = [], [], [] # optimizer parameter groups
bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
for v in model.modules():
for p_name, p in v.named_parameters(recurse=0):
if p_name == 'bias': # bias (no decay)
g[2].append(p)
elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
g[1].append(p)
# BiFPN_Concat
elif isinstance(v, BiFPN_Add2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g[1].append(v.w)
elif isinstance(v, BiFPN_Add3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g[1].append(v.w)
else:
g[0].append(p) # weight (with decay)



![[抢先看] 全平台数据 (数据库) 管理工具 DataCap 1.10.0](https://img-blog.csdnimg.cn/f91d473864804e62b27cbe3dd0295994.png)