一、groupby分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
- DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=_NoDefault.no_default, squeeze=_NoDefault.no_default, observed=False, dropna=True):使用映射器或按一Series列对 DataFrame 进行分组。 groupby 操作涉及拆分对象、应用函数和组合结果的某种组合。可用于对大量数据进行分组并对这些组进行计算操作
- by:映射、函数、标签或标签列表,用于确定分组依据的组。如果 by 是一个函数,则对对象索引的每个值调用它。如果传递了字典或序列,则序列或字典值将用于确定组(序列的值首先对齐。如果传递了长度等于所选轴的列表或 ndarray,则按原样使用这些值来确定组。标签或标签列表可以按列自身传递到组。请注意,元组被解释为(单个)键
- axis:{0 or ‘index’, 1 or ‘columns’}, 默认0 沿行(0)或列(1)分割。对于系列,此参数未使用,默认为 0
- level:int,级别名称,或此类的序列,默认 None 如果轴是 MultiIndex(分层),则按特定级别或级别分组。不要同时指定 by 和 level
- as_index:bool,默认值为 True,是否进行索引,对于聚合输出,返回以组标签作为索引的对象。仅与 DataFrame 输入相关。as_index=False 实际上是“SQL 样式”分组输出
- sort:bool,默认True 排序组键。通过关闭它获得更好的性能。请注意,这不会影响每个组内的观察顺序。 Groupby 保留每个组中行的顺序
- group_keys:bool,可选,当调用 apply 并且 by 参数生成类似索引(即转换)结果时,将组键添加到索引以标识片段。默认情况下,当结果的索引(和列)标签与输入匹配时,不包括组键,否则将包含组键。如果生成的结果相对于输入没有相似索引,则此参数无效
- squeeze:bool,默认值 False,如果可能,请减小返回类型的维数,否则返回一致的类型
- observed:bool,默认为 False,这仅适用于任何 groupers 是 Categoricals 的情况。若为True:仅显示categorical groupers的观察值。若为False:显示categorical groupers的所有值
- dropna:bool,默认为True,若为True,且组键包含 NA 值,则将删除 NA 值以及行/列。若为 False,则 NA 值也将被视为组中的键
- 返回:DataFrameGroupBy,返回包含有关组信息的 groupby 对象
代码示例如下
import pandas as pd
import numpy as np
df = pd.DataFrame({'颜色': ['蓝色', '灰色', '蓝色', '灰色', '黑色'], '商品': ['钢笔', '钢笔', '铅笔', '铅笔', '文具盒'],'售价':[2.5, 2.3, 1.5, 1.3, 5.2],'会员价':[2.2, 2, 1.3, 1.2, 5.0]})
df
df.groupby([ '商品']).mean(numeric_only=True)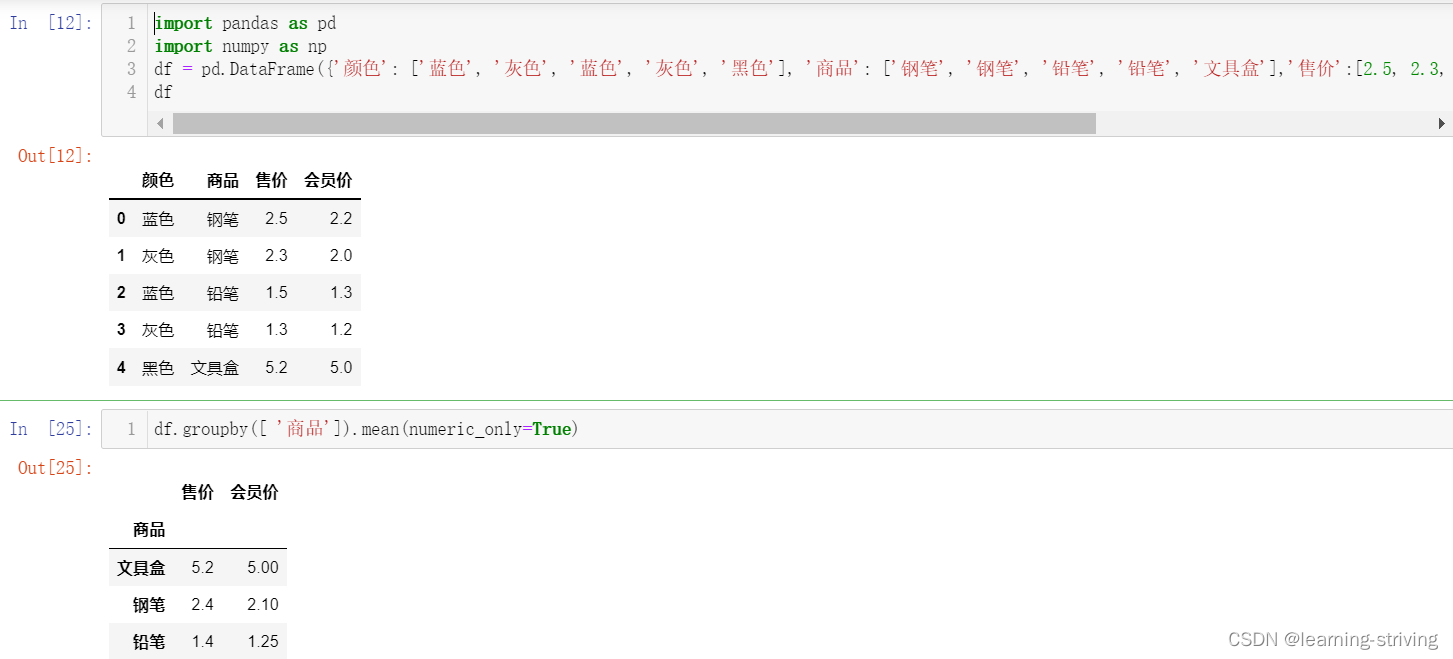
二、分层索引
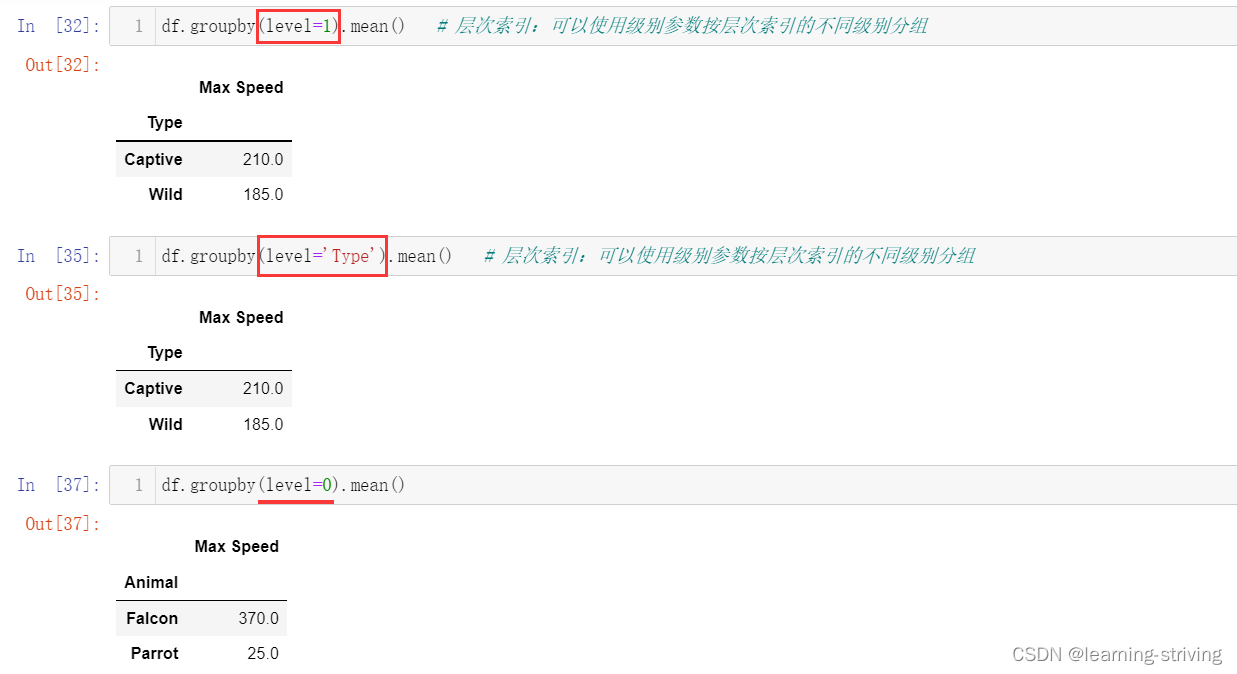
可以使用 level 参数按分层索引的不同级别进行分组
arrays = [['Falcon', 'Falcon', 'Parrot', 'Parrot'],
['Captive', 'Wild', 'Captive', 'Wild']]
index = pd.MultiIndex.from_arrays(arrays, names=('Animal', 'Type')) # from_arrays用于将数组arrays转为多索引multiIndex,多维数组作为参数,高维指定高层索引,低维指定低层索引
index
--------------------------------------------------------------
df = pd.DataFrame({'Max Speed': [390., 350., 30., 20.]}, index=index) # index为行标签索引
df
df.groupby(level=1).mean() # 层次索引:可以使用级别参数按层次索引的不同级别分组
df.groupby(level='Type').mean() # 层次索引:可以使用级别参数按层次索引的不同级别分组
df.groupby(level=0).mean()
三、设置是否包含NaN
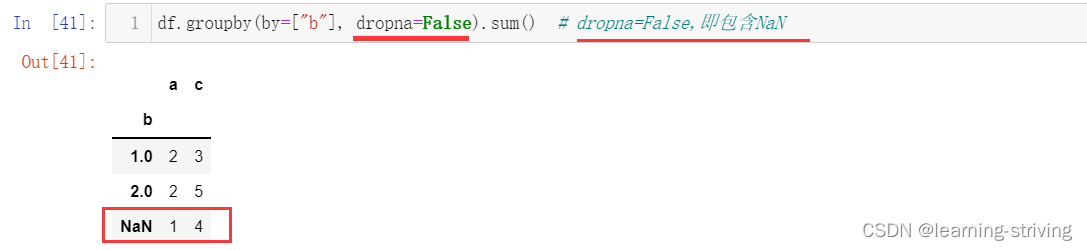
可以通过设置 dropna 参数来选择是否在组键中包含 NA,默认设置为 True,即不包含NaN值
l = [[1, 2, 3], [1, None, 4], [2, 1, 3], [1, 2, 2]]
df = pd.DataFrame(l, columns=["a", "b", "c"])
df
df.groupby(by=["b"]).sum() # 还可以通过设置 dropna 参数来选择是否在组键中包含 NA,默认设置为 True
df.groupby(by=["b"], dropna=False).sum() # dropna=False,即包含NaN
l = [["a", 12, 12], [None, 12.3, 33.], ["b", 12.3, 123], ["a", 1, 1]]
l
df = pd.DataFrame(l, columns=["a", "b", "c"]) # columns为列标签索引
df
df.groupby(by="a").sum() # 按a列分组,对其他列进行求和,默认dropna=True,即不包含NaN值
df.groupby(by="a", dropna=False).sum() # 为False时包含NaN值
四、排除组键
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon', 'Parrot', 'Parrot'], 'Max Speed': [380., 370., 24., 26.]})
df
df.groupby("Animal", group_keys=True).apply(lambda x: x) # 使用 group_keys 包含或排除组键,默认为 True(包含)
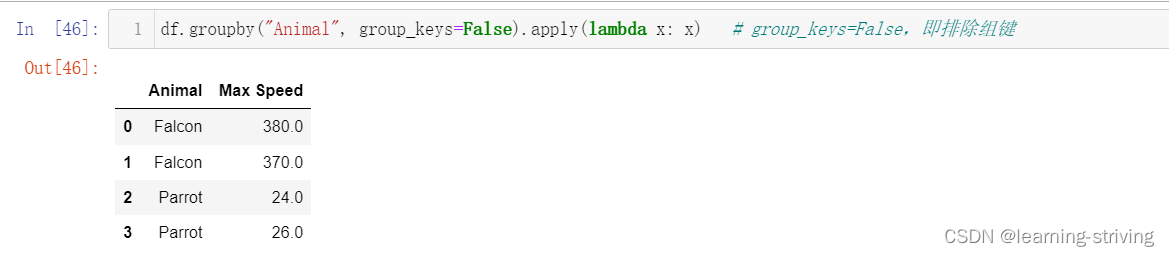
df.groupby("Animal", group_keys=False).apply(lambda x: x) # group_keys=False,即排除组键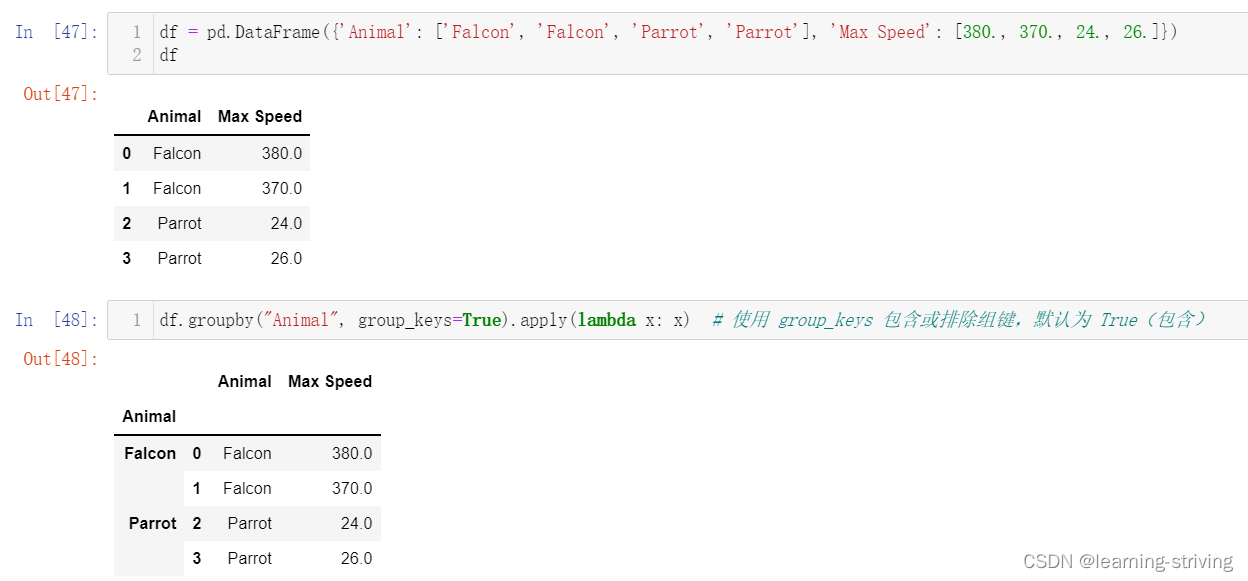
五、星巴克零售店铺数据
星巴克directory.csv数据获取下载:https://pan.baidu.com/s/1LG7YlezfSvPC6I7IvfUk4Q?pwd=fsp8
# 读取星巴克店的数据
starbucks = pd.read_csv("../data/directory.csv")
starbucks.head() # head()表示取前五
---------------------------------------------------
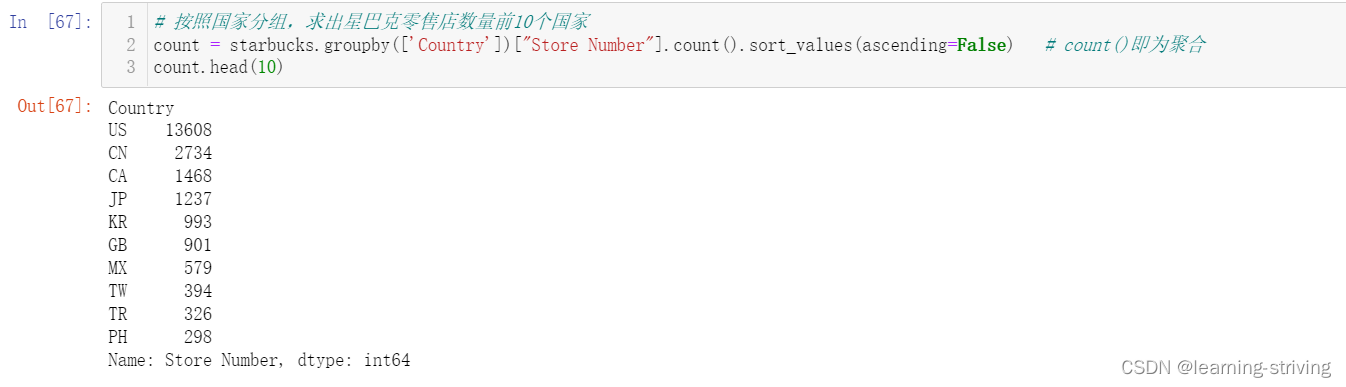
# 按照国家分组,求出星巴克零售店数量前10个国家
count = starbucks.groupby(['Country'])["Store Number"].count().sort_values(ascending=False) # count()即为聚合,sort_values表示进行排序,ascending=False即降序排序
count.head(10)
---------------------------------------------------
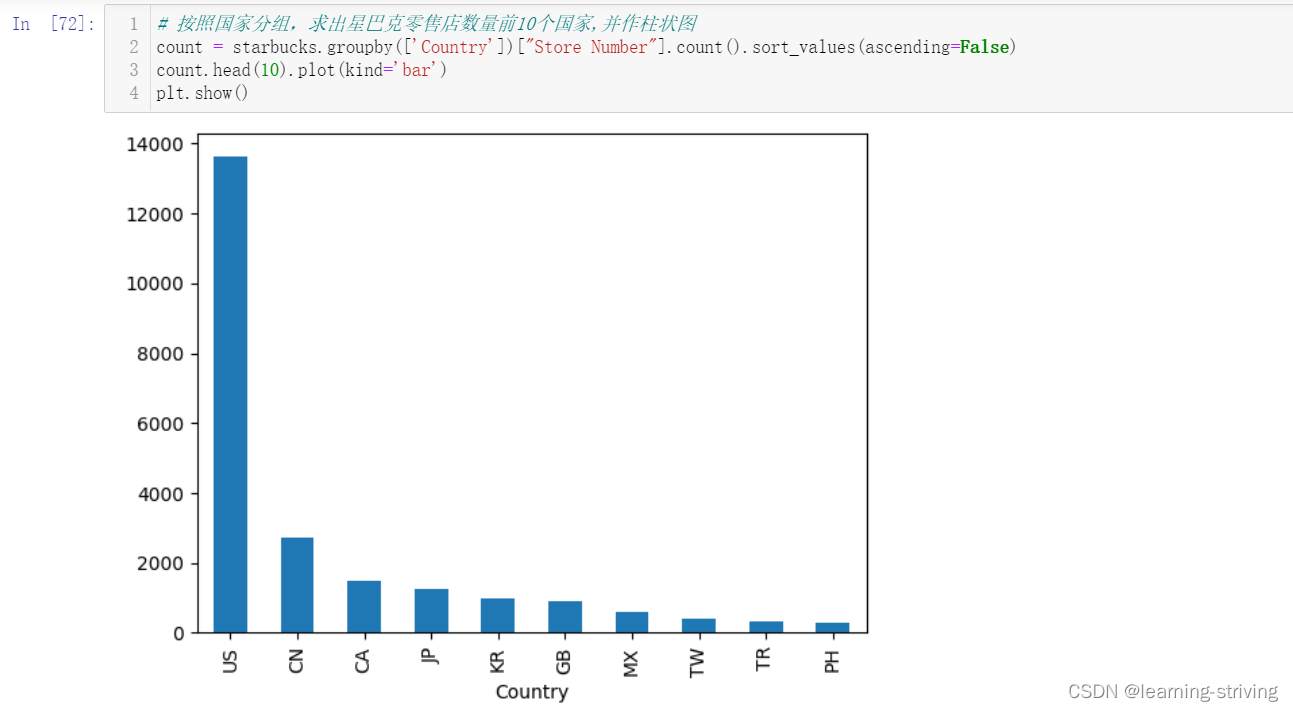
# 按照国家分组,求出星巴克零售店数量前10个国家,并作柱状图
count = starbucks.groupby(['Country'])["Store Number"].count().sort_values(ascending=False)
count.head(10).plot(kind='bar')
plt.show()
---------------------------------------------------
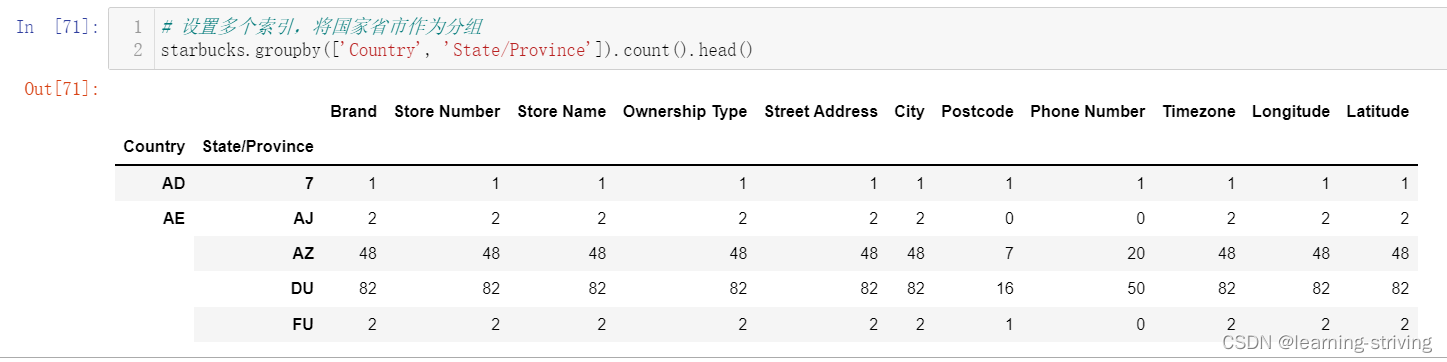
# 设置多个索引,将国家省市作为分组
starbucks.groupby(['Country', 'State/Province']).count().head() 操作如下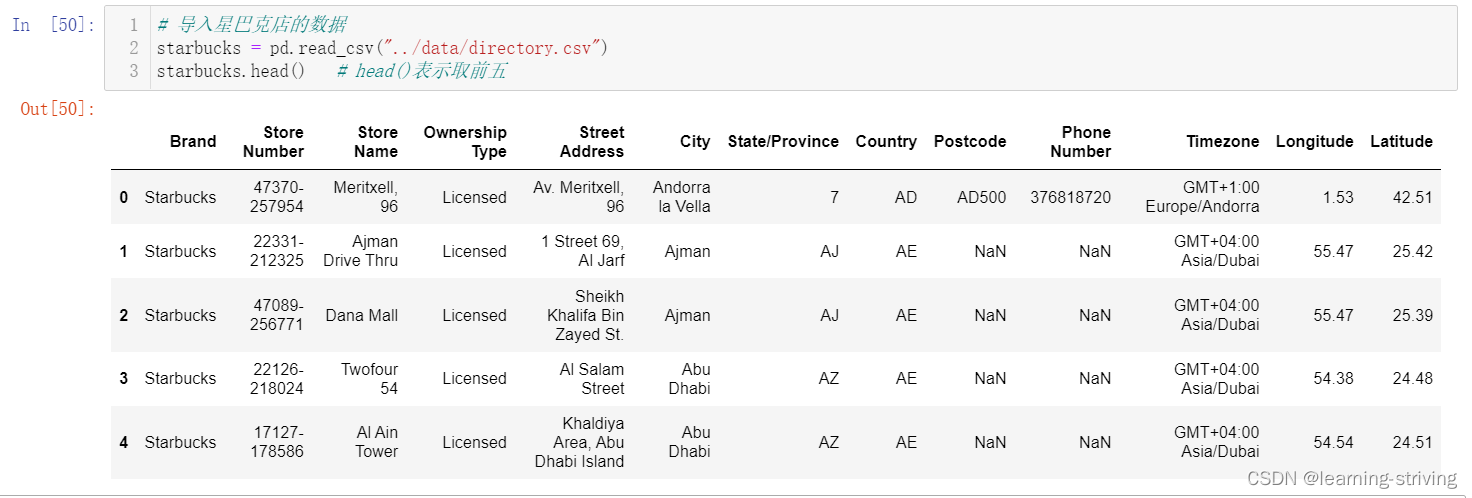
以下结构与MultiIndex结构 类似
 学习导航:http://xqnav.top/
学习导航:http://xqnav.top/