MyBatis
文章目录
- MyBatis
- XML语言简介
- 用途
- 各部分注解
- 声明
- 元素
- 属性
- 注释
- CDATA
- 转义字符
- 搭建环境
- 读取实体类
- 创建实体与映射关系的文件
- 配置MyBatis
- 创建工具类
- 接口实现
- Mybatis工作流程
- 增删改查
- 指定映射规则
- 指定构造方法
- 字段名称带下划线处理
- 条件查询
- 插入数据
- 复杂查询和事务
- 一对多查询
- 多对一查询
- Mybatis分页
- 事务操作
- 动态SQL
- if
- choose (when, otherwise)
- trim (where, set)
- 动态更新 set
- foreach
- SQL片段
- 缓存机制
- 使用注解开发
- 操作
- 自定义映射规则 @Result
- 注解来完成复杂查询
- @ResultMap
- @ConstructorArgs
- @Param 注解
- 通过注解控制缓存机制
- 探究Mybatis的动态代理机制
- 核心组件
- 实现
概括:一种更加简洁高效和数据库交互的技术
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java对象)映射成数据库中的记录
XML语言简介
可拓展标记语言;是SGML的子集,可以描述很复杂的数据关系
用途
用于组织和存储数据,除此之外都和XML本身无关
- 配置文件(例子:Tomcat的web.xml,server.xml…),XML能够非常清晰描述出程序之间的关系
- 程序间数据的传输,XML的格式是通用的,能够减少交换数据时的复杂
- 充当小型数据库,如果我们的数据有时候需要人工配置的,那么XML充当小型的数据库是个不错的选择,程序直接读取XML文件显然要比读取数据库要快
各部分注解
<?xml version="1.0" encoding="UTF-8" ?> //头部申明
<outer> //根节点
<name>S</name>//子标签
<desc>HAHAH</desc>
<inner type="1"> //可以存放属性
<age>10</age>
<sex>男</sex>
</inner>
</outer>
HTML主要用于通过编排来展示数据,而XML主要是存放数据,它更像是一个配置文件!当然,浏览器也是可以直接打开XML文件的
一个XML文件存在以下的格式规范:
- 必须存在一个根节点,将所有的子标签全部包含。
- 可以但不必须包含一个头部声明(主要是可以设定编码格式)
- 所有的标签必须成对出现,可以嵌套但不能交叉嵌套
- 区分大小写。
- 标签中可以存在属性,比如上面的type="1"就是inner标签的一个属性,属性的值由单引号或双引号包括。
声明
<?xml version="1.0" encoding="UTF-8" standalone="no"?> //头部申明
version :版本
encoding:编码;
standalone:独立使用;默认是no。standalone表示该xml是不是独立的,如果是yes,则表示这个XML文档时独立的,不能引用外部的DTD规范文件;
元素
在XML当中元素和标签指的是一个东西
元素中需要值得注意的地方:
- XML元素中的出现的空格和换行都会被当做元素内容进行处理
- 每个XML文档必须有且只有一个根元素
- 元素必须闭合
- 大小写敏感
- 不能交叉嵌套
- 不能以数字开头
属性
命名规范和XML一致
<!--属性名是name,属性值是china-->
<中国 name="china">
</中国>
注释
XML文件也可以使用注释:
<?xml version="1.0" encoding="UTF-8" ?>
<!-- 注释内容 -->
CDATA
通俗的来讲,就是那有些内容的特殊含义改成就单纯字面意思,这种情况,就需要把这些区都放在CDATA区
<test>
<name><![CDATA[我看你<><><>是一点都不懂哦>>>]]></name>
</test>
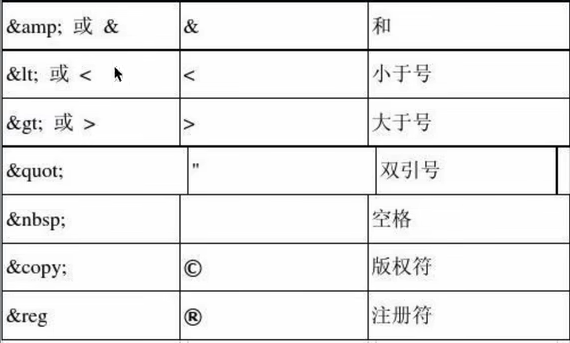
转义字符
JDK为我们内置了一个叫做org.w3c的XML解析库,我们来看看如何使用它来进行XML文件内容解析:
public static void main(String[] args) {
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); //创建对象
try {
DocumentBuilder db = dbFactory.newDocumentBuilder(); //创建对象
Document doc = db.parse("file:test.xml");
//每一个标签作为一个节点
NodeList list = doc.getElementsByTagName("outer"); //可能有挺多text
Node root = list.item(0); //获取第一个
NodeList childs = root.getChildNodes(); //一个节点下可以有很多结点,节点可以是一个带有内容的标签,也可以是一段文本
for (int i = 0; i < childs.getLength(); i++) {
Node child = childs.item(i);
if(child.getNodeType() == Node.ELEMENT_NODE) { //过滤换行符
// 输出节点名称,也就是标签名称,以及标签内部的文本(内部的内容都是子节点,所以要获取内部的节点)
System.out.println(child.getNodeName() + ";" + child.getFirstChild().getNodeValue());
}
}
}catch(Exception e) {
e.printStackTrace();
}
}
搭建环境
文档网站:链接
下载Jar包-添加为库(注意jar包要添加在lib目录下)
配置文件
在不是在Java代码中配置了,而是通过一个XML文件去配置,这样就使得硬编码的部分大大减少,项目后期打包成Jar运行不方便修复,但是通过配置文件,我们随时都可以去修改,就变得很方便了,同时代码量也大幅度减少,配置文件填写完成后,只需要关心项目的业务逻辑而不是如何去读取配置文件;
按照官方文档给定的提示,在项目根目录下新建名为mybatis-config.xml的文件,并填写以下内容:
注意不要在标签里面写注释,否则可能会报错!!!
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="${数据库连接URL}"/>
<property name="username" value="${用户名}"/>
<property name="password" value="${密码}"/>
</dataSource>
</environment>
</environments>
</configuration>
这里注意记得添加;两边都要添加URI
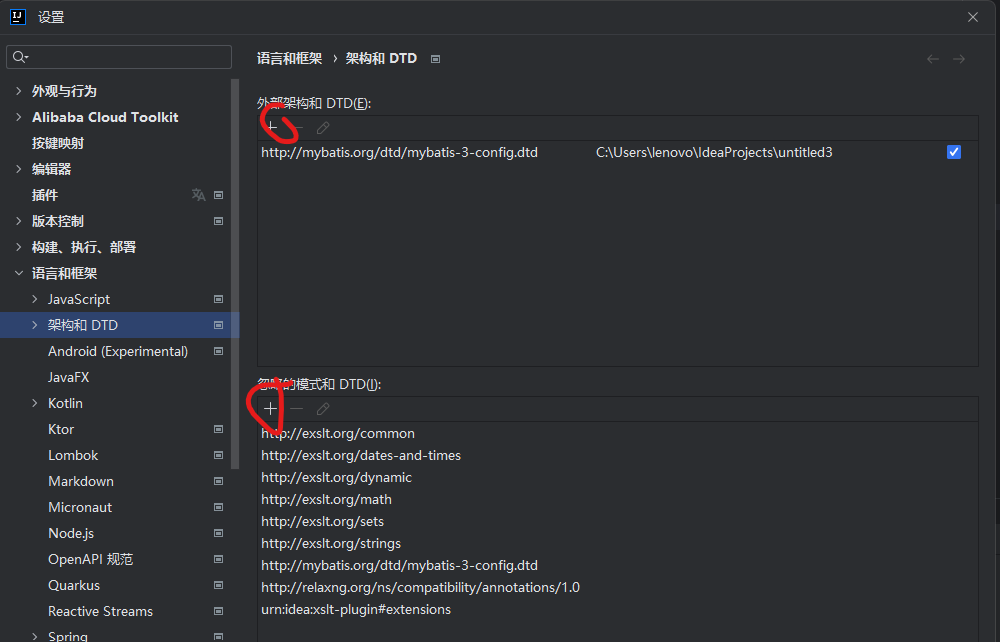
在最上方还引入了一个叫做DTD(文档类型定义)的东西,它提前帮助我们规定了一些标签,我们就需要使用Mybatis提前帮助我们规定好的标签来进行配置(因为只有这样Mybatis才能正确识别我们配置的内容)
通过进行配置,告诉了Mybatis我们链接数据库的一些信息,包括URL、用户名、密码等,这样Mybatis就知道该链接哪个数据库、使用哪个账号进行登陆了(也可以不使用配置文件,这里不做讲解,还请自行阅读官方文档)
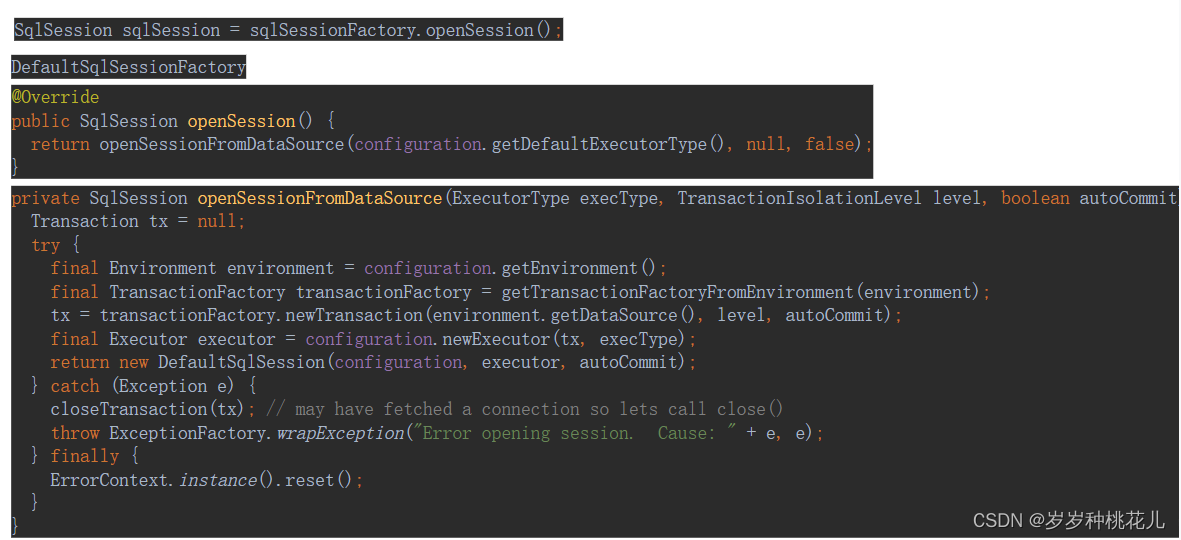
配置文件完成后,我们需要在Java程序启动时,让Mybatis对配置文件进行读取并得到一个SqlSessionFactory对象:
public static void main(String[] args) throws FileNotFoundException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(new FileInputStream("mybatis-config.xml"));
try (SqlSession sqlSession = sqlSessionFactory.openSession(true)){
//暂时还没有业务
}
}
直接运行即可,虽然没有干什么事情,但是不会出现错误,如果之前的配置文件编写错误,直接运行会产生报错!
SqlSessionFactory对象是什么东西:
每个基于MyBatis的应用都是以SqlSessionFactory为核心的;既可以通过此来创造多个会话;每个会话就相当于不同的地方登录一个账号去访问数据库;也可以认为成是JDBC的statement
而通过SqlSession就可以完成几乎所有的数据库操作,这个接口中定义了大量数据库操作的方法,因此只需要通过一个对象就能完成数据库交互了
现在通过mybatis-config.xml来了解一下,详细可参考:官方文档
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development"> <!--定义环境,default表示默认环境 -->
<environment id="development">
<transactionManager type="JDBC"/> <!-- 事务管理器-->
<dataSource type="POOLED"> <!-- 数据源,Mybatis使用连接池的方式获取连接-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/need"/>
<property name="username" value="root"/>
<property name="password" value="26221030"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/test/mapper/TestMapper.xml"/> //更改处
</mappers>
</configuration>
首先就从environments标签说起,一般情况下,在开发中,都需要指定一个数据库的配置信息,environment就是用于进行这些配置的!实际情况下可能会不止有一个数据库连接信息,可以提前定义好所有的数据库信息
在environments标签上有一个default属性,来指定默认的环境,当然如果我们希望使用其他环境,可以修改这个默认环境,也可以在创建工厂时选择环境:
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(new FileInputStream("mybatis-config.xml"), "环境ID");
可以给类型起一个别名,以简化Mapper的编写:
<!-- 需要在environments的上方 -->
<typeAliases>
<typeAlias type="com.test.entity.Student" alias="Student"/>
</typeAliases>
现在Mapper就可以直接使用别名了:
<mapper namespace="com.test.mapper.TestMapper">
<select id="selectStudent" resultType="Student">
select * from student
</select>
</mapper>
如果这样还是很麻烦,我们也可以直接让Mybatis去扫描一个包,并将包下的所有类自动起别名(别名为首字母小写的类名)
<typeAliases>
<package name="com.test.entity"/>
</typeAliases>
也可以为指定实体类添加一个注解,来指定别名:
@Data
@Alias("lbwnb")
public class Student {
private int sid;
private String name;
private String sex;
}
当然,Mybatis也包含许多的基础配置,通过使用:
<settings>
<setting name="" value=""/>
</settings>
所有的配置项可以在中文文档处查询
读取实体类
来尝试一下直接读取实体类,读取实体类肯定需要一个映射规则,比如类中的哪个字段对应数据库中的哪个字段,在查询语句返回结果后,Mybatis就会自动将对应的结果填入到对象的对应字段上。首先编写实体类,,直接使用Lombok是不是就很方便了:
import lombok.Data;
@Data
public class Student {
int sid; //名称最好和数据库字段名称保持一致,不然可能会映射失败导致查询结果丢失
String name;
String sex;
}
创建实体与映射关系的文件
在根目录下重新创建一个mapper文件夹,新建名为TestMapper.xml的文件作为映射器,并填写以下内容:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace属性是名称空间,必须唯一 -->
<mapper namespace="TestMapper"> <!--如果报错,建议直接忽略 -->
<select id="selectStudent" resultType="com.test.entity.Student">
select * from student
</select>
</mapper>
其中namespace就是命名空间,每个Mapper都是唯一的,因此需要用一个命名空间来区分,它还可以用来绑定一个接口。我们在里面写入了一个select标签,表示添加一个select操作,同时id作为操作的名称,resultType指定为我们刚刚定义的实体类,表示将数据库结果映射为Student类,然后就在标签中写入我们的查询语句即可。
如果只要一个sid
SELECT *FROM student WHERE sid = #{sid}
main里面也要改
System.out.println((Student)sqlSession.selectOne("selectStudent", 26221012));
编写好后,在配置文件中添加这个Mapper映射器:
<mappers>
<mapper url="file:mappers/TestMapper.xml"/>
<!-- 这里用的是url,也可以使用其他类型 -->
</mappers>
最后在程序中使用我们定义好的Mapper即可:
public static void main(String[] args) throws FileNotFoundException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(new FileInputStream("mybatis-config.xml"));
try (SqlSession sqlSession = sqlSessionFactory.openSession(true)){
List<Student> student = sqlSession.selectList("selectStudent"); //注意要和xml语句里的selectid保持一致
student.forEach(System.out::println);
}
}
Mybatis非常智能,只需要一个映射关系,就能够直接将查询结果转化为一个实体类
配置MyBatis
创建工具类
由于SqlSessionFactory一般只需要创建一次,因此可以创建一个工具类来集中创建SqlSession,这样会更加方便一些:
package com.test.entity;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class MybatisUtil {
//在类加载时就进行创建
private static SqlSessionFactory sqlSessionFactory;
static {
try {
sqlSessionFactory = new SqlSessionFactoryBuilder().build(new FileInputStream("mybatis-config.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
/**
* 获取一个新的会话
* @param autoCommit 是否开启自动提交(跟JDBC是一样的,如果不自动提交,则会变成事务操作)
* @return SqlSession对象
*/
public static SqlSession getSession(boolean autoCommit){
return sqlSessionFactory.openSession(autoCommit);
}
}
之后的使用
public static void main(String[] args) throws FileNotFoundException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(new FileInputStream("mybatis-config.xml"));
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
//映射文件的命名空间.SQL片段的ID,就可以调用对应的映射文件中的SQL
System.out.println((Student)sqlSession.selectOne("selectStudent", 26221012));
}
}
接口实现
可以通过namespace来绑定到一个接口上,利用接口的特性,可以直接指明方法的行为,而实际实现则是由Mybatis来完成
把文件分类一下,如图所示
接口简单定义
public interface TestMapper {
List<Student> selectStudent();
}
之后更改 TestMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.test.mapper.TestMapper"> <!--更改处-->
<select id="selectStudent" resultType="com.test.entity.Student">
select * from student
</select>
</mapper>
再更改 mybatis-config.xml 作为内部资源后,需要修改一下配置文件中的mapper定义,不使用url而是resource表示是Jar内部的文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development"> <!--连接环境信息-->
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--交互必备四个属性-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306"/>
<property name="username" value=" "/>
<property name="password" value=" "/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/test/mapper/TestMapper.xml"/> <!--更改处-->
</mappers>
</configuration>
main方法使用;直接通过sqlsession获取对应的实现类,通过接口中的定义行为来直接获取结果
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
mapper.selectStudent().forEach(System.out::println);
}
}
TestMapper虽然是自行定义的一个接口,但是当我们调用getClass()方法之后,会发现实现类名称很奇怪,它其实是通过动态代理生成的,相当于动态生成了一个实现类,而不是预先定义好
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
System.out.println(testMapper.getClass());

Mybatis工作流程
- 通过Reader对象读取Mybatis映射文件
- 通过SqlSessionFactoryBuilder对象创建SqlSessionFactory对象
- 获取当前线程的SQLSession
- 事务默认开启
- 通过SQLSession读取映射文件中的操作编号,从而读取SQL语句
- 提交事务
- 关闭资源
增删改查
注意:这个insert/update/delete标签只是一个模板,在做操作时,其实是以SQL语句为核心的, 即在做增/删/时,insert/update/delete标签可通用, 但做查询时只能用select标签,我们提倡什么操作就用什么标签
在前面我们演示了如何快速进行查询,我们只需要编写一个对应的映射器既可以了:
<!--
查询所有数据
返回值类型讲道理是List<Student>的,但我们只要写集合中的类型就行了
-->
<mapper namespace="com.test.mapper.TestMapper">
<select id="studentList" resultType="Student">
select * from student
</select>
</mapper>
不喜欢使用实体类,那么这些属性还可以被映射到一个Map上:
<select id="selectStudent" resultType="Map">
select * from student
</select>
public interface TestMapper {
List<Map> selectStudent(); //定义返回类型
}
Map中就会以键值对的形式来存放这些结果了
指定映射规则
如果我们修改Sutdent类里的字段名称,没有保持一致,会造成输出的时候产生错误;通过指定映射规则,可以交换映射字段
type:表示实体全路径名
id:为实体与表的映射取一个任意的唯一名字
result标签:映射非主键属性
property属性:实体的属性名
column属性:表的字段名
<resultMap id="Test" type="Student">
<result column="sid" property="xxxx"/>
</resultMap>
<select id="selectStudent" resultMap="Test">
指定构造方法
如果一个类中存在多个构造方法,那么很有可能会出现这样的错误:
### Exception in thread "main" org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: org.apache.ibatis.executor.ExecutorException: No constructor found in com.test.entity.Student matching [java.lang.Integer, java.lang.String, java.lang.String]
### The error may exist in com/test/mapper/TestMapper.xml
### The error may involve com.test.mapper.TestMapper.getStudentBySid
### The error occurred while handling results
### SQL: select * from student where sid = ?
### Cause: org.apache.ibatis.executor.ExecutorException: No constructor found in com.test.entity.Student matching [java.lang.Integer, java.lang.String, java.lang.String]
at org.apache.ibatis.exceptions.ExceptionFactory.wrapException(ExceptionFactory.java:30)
...
来看一个没指定的,但是可以运行的
public Student(int xxxx) {
System.out.println("构造方法1 xxxx" + xxxx);
}
public Student(int xxxx, String name, String sex) {
System.out.println("构造2 xxxx" + xxxx);
System.out.println("构造2 name" + xxxx);
}
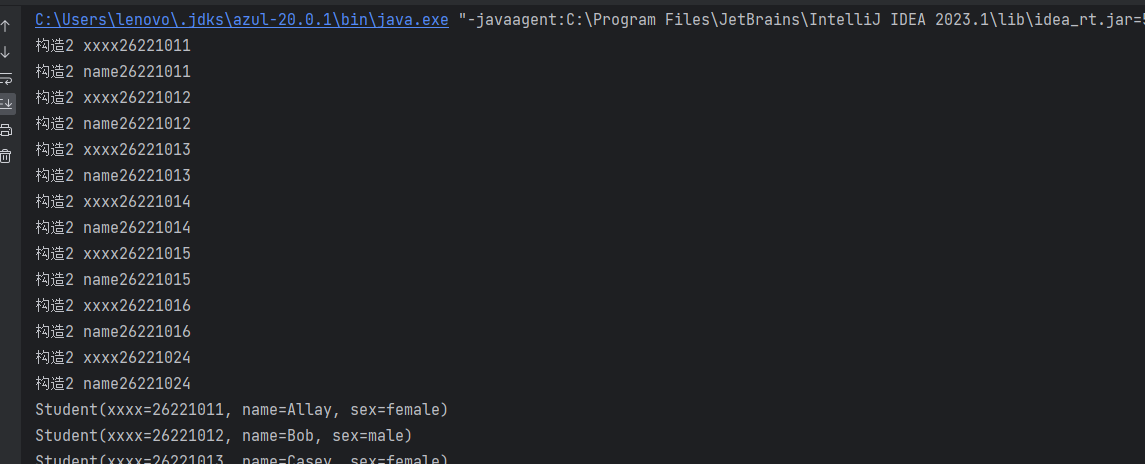
可以发现基本都是构造2号方法
这时就需要使用constructor标签来指定构造方法:
<resultMap id="test" type="Student">
<constructor>
<arg column="sid" javaType="Integer"/>
<arg column="name" javaType="String"/>
<arg column="sex" javaType="String"/>
</constructor>
</resultMap>
值得注意的是,指定构造方法后,若此字段被填入了构造方法作为参数,将不会通过反射给字段单独赋值,而构造方法中没有传入的字段,依然会被反射赋值
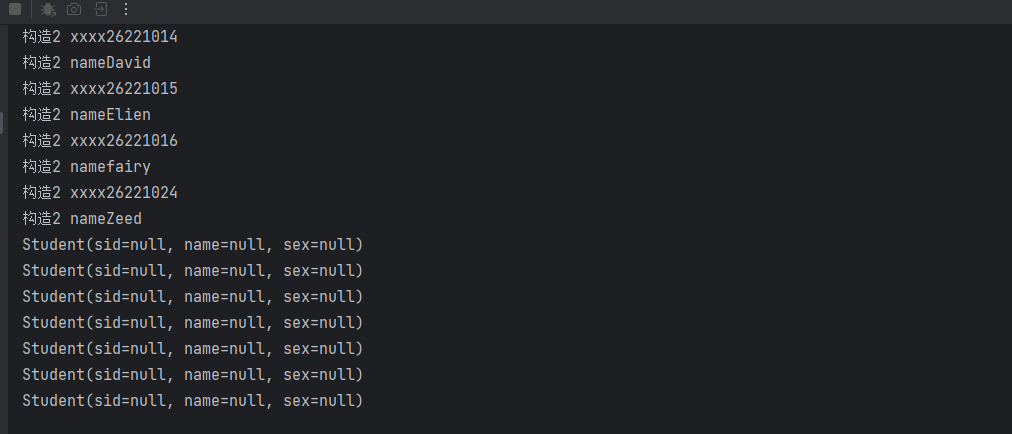
字段名称带下划线处理
如果数据库中存在一个带下划线的字段,可以通过设置让其映射为以驼峰命名的字段,比如my_test映射为myTest
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
如果不设置,默认为不开启,也就是默认需要名称保持一致
条件查询
当只想要sid的时候
Student getStudentBySid(int sid);
<select id="getStudentBySid" parameterType="int" resultType="Student">
select * from student where sid = #{sid}
</select>
通过使用#{xxx}或是${xxx}来填入我们给定的属性
实际上Mybatis本质也是通过PreparedStatement首先进行一次预编译,有效地防止SQL注入问题,但是如果使用${xxx}就不再是通过预编译,而是直接传值,因此一般都使用#{xxx}来进行操作
使用parameterType属性来指定参数类型(非必须,可以不用,推荐不用)
插入数据
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
System.out.println(mapper.addStudent(new Student().setSid(26221014).setName("Fred").setSex("male")));
}
}
设置xml文件
<insert id="addStudent" >
INSERT INTO student( sid,name, sex) VALUES(#{sid},#{name},#{sex})
</insert>
接口设置
public interface TestMapper {
int addStudent(Student student);
}
Student类设置
@Data
@Accessors(chain = true) //使用Lombok插件
public class Student {
int sid;
String name;
String sex;
}
删除同理,就直接sql语句转换即可
复杂查询和事务
一对多查询
查一个学生有几个老师
一个老师可以教授多个学生,可以将老师的学生全部映射给此老师的对象,比如:
@Data
public class Teacher {
int tid;
String name;
List<Student> studentList;
}
映射为Teacher对象时,同时将其教授的所有学生一并映射为List列表,显然这是一种一对多的查询,那么这时就需要进行复杂查询了。而之前编写的都非常简单,直接就能完成映射,因此现在需要使用resultMap来自定义映射规则:
<select id="getTeacherByTid" resultMap="asTeacher">
select *, teacher.name as tname from student inner join teach on student.sid = teach.sid
inner join teacher on teach.tid = teacher.tid where teach.tid = #{tid}
</select>
<resultMap id="asTeacher" type="Teacher">
<id column="tid" property="tid"/>
<result column="tname" property="name"/>
<collection property="studentList" ofType="Student">
<id property="sid" column="sid"/>
<result column="name" property="name"/>
<result column="sex" property="sex"/>
</collection>
</resultMap>
可以看到,我们的查询结果是一个多表联查的结果,而联查的数据就是我们需要映射的数据(比如这里是一个老师有N个学生,联查的结果也是这一个老师对应N个学生的N条记录),其中id标签用于在多条记录中辨别是否为同一个对象的数据,比如上面的查询语句得到的结果中,tid这一行始终为1,因此所有的记录都应该是tid=1的教师的数据,而不应该变为多个教师的数据,如果不加id进行约束,那么会被识别成多个教师的数据!
通过使用collection来表示将得到的所有结果合并为一个集合,比如上面的数据中每个学生都有单独的一条记录,因此tid相同的全部学生的记录就可以最后合并为一个List,得到最终的映射结果,当然,为了区分,最好也设置一个id,只不过这个例子中可以当做普通的result使用
多对一查询
查询一个老师带了几个学生
@Data
@Accessors(chain = true)
public class Student {
private int sid;
private String name;
private String sex;
private Teacher teacher;
}
@Data
public class Teacher {
int tid;
String name;
}
现在我们希望的是,每次查询到一个Student对象时都带上它的老师,同样的,我们也可以使用resultMap来实现(先修改一下老师的类定义,不然会很麻烦):
<resultMap id="test2" type="Student">
<id column="sid" property="sid"/>
<result column="name" property="name"/>
<result column="sex" property="sex"/>
<association property="teacher" javaType="Teacher"> <!--关联属性,指定为teahcer类属性-->
<id column="tid" property="tid"/>
<result column="tname" property="name"/>
</association>
</resultMap>
<select id="selectStudent" resultMap="test2">
select *, teacher.name as tname from student left join teach on student.sid = teach.sid
left join teacher on teach.tid = teacher.tid
</select>
通过使用association进行关联,形成多对一的关系,实际上和一对多是同理的,都是对查询结果的一种处理方式罢了
public class main {
public class void main(String[] args) {
try(SqlSession session = MybatisUtil.getSession(true)) {
TestMapper mapper = session.getMapper(TestMapper.class);
mapper.selectStudent(1).forEach(System.out::println);
}
}
}
Mybatis分页
Paging:即有很多数据,就需要分页来分割数据,可提高整体运行性能,增强用户使用体验需求等
不使用分页将遇到的问题:
- 客户端问题:数据太多影响用户的体验感且也不方便操作查找,甚至出现加载太慢的问题
- 服务器问题:数据太多会造成内存溢出,且对服务器的性能也不友好
当需要接受多个参数时,我们使用Map集合来装载
语法
SELECT * FROM user LIMIT 3;
接口设置
List<User> selectLimit(Map<String,Integer> map);
xml文件
<select id="selectLimit" parameterType="map" resultMap="UserMap">
select * from mybatis.user limit #{startIndex},#{pageSize}
</select>
测试
public class UserDaoTest {
@Test
public void limitTest(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("startIndex",0);
map.put("pageSize",2);
List<User> list=mapper.selectLimit(map);
for (User u: list) {
System.out.println(u);
}
sqlSession.close();
}
}
事务操作
可以关闭自动提交来开启事务模式,之后用commit就行了
public class main {
public class void main(String[] args) {
try(SqlSession session = MybatisUtil.getSession(false)) {
TestMapper mapper = session.getMapper(TestMapper.class);
mapper.addStudent(new Student.setName("Veid").setSex("male"));
session.commit(); //提交事务
}
}
}
动态SQL
官网链接
动态 SQL 是 MyBatis 的强大特性之一。如果使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦
if
<select id="selectStudent" resultType="student">
SELECT*FROM student WHERE sid = #{sid}
<if test="sid %2 == 0"> <!--如果if成立,则进行AND语句,必须两个都满足-->
AND sex = 'male'
</if>
</select>
如果需要两个条件,则直接在加一个就行了
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
choose (when, otherwise)
有些时候,只需要多个条件满足一个就行了,于是提供了choose语句,挺像switch
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
trim (where, set)
看这个例子
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
假设没有条件符合,那么最后的语句等同于
SELECT * FROM BLOG
WHERE
如果匹配第二个,则:会导致出错
SELECT * FROM BLOG
WHERE
AND title like ‘someTitle’
对其进行简单改动
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
如果 where 元素与你期望的不太一样,你也可以通过自定义 trim 元素来定制 where 元素的功能。比如,和 where 元素等价的自定义 trim 元素为:
<trim prefix="WHERE" prefixOverrides="AND |OR ">
<!--prefixOverrides 属性会忽略通过管道符分隔的文本序列(注意此例中的空格是必要的)。上述例子会移除所有 prefixOverrides 属性中指定的内容,并且插入 prefix 属性中指定的内容-->
...
</trim>
动态更新 set
能只更新想更新的,忽略不更新的
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
这个例子中,set 元素会动态地在行首插入 SET 关键字,并会删掉额外的逗号(这些逗号是在使用条件语句给列赋值时引入的)。
或者,你可以通过使用trim元素来达到同样的效果:
<trim prefix="SET" suffixOverrides=",">
...
</trim>
foreach
动态 SQL 的另一个常见使用场景是对集合进行遍历(尤其是在构建 IN 条件语句的时候)。比如:
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT * FROM POST P
<where>
<foreach item="item" index="index" collection="list"
open="ID in (" separator="," close=")" nullable="true">
#{item}
</foreach>
</where>
</select>
允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。这个元素也不会错误地添加多余的分隔符
可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值
SQL片段
有时候可能某个 sql 语句我们用的特别多,为了增加代码的重用性,简化代码,我们需要将这些代码抽取出来,然后使用时直接调用
<sql id="if-title-author">
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</sql>
引用片段
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog
<where>
<!-- 引用 sql 片段,如果refid 指定的不在本文件中,那么需要在前面加上 namespace -->
<include refid="if-title-author"></include>
<!-- 在这里还可以引用其他的 sql 片段 -->
</where>
</select>
缓存机制
Mybatis内置了一个强大的事务性查询缓存机制,可以非常方便呢配置和定制
缓存机制:提前将一部分内容放入缓存,下次需要数据的时候就直接从缓存中读取,这样就相当于直接从内存中获取,而不是再去向数据库索要数据,效率会更高
适用:经常查询且不常更改的数据
Mybatis内置了一个缓存机制,查询时,缓存中存在数据就可以直接从缓存中读取,而不是去向数据库进行请求
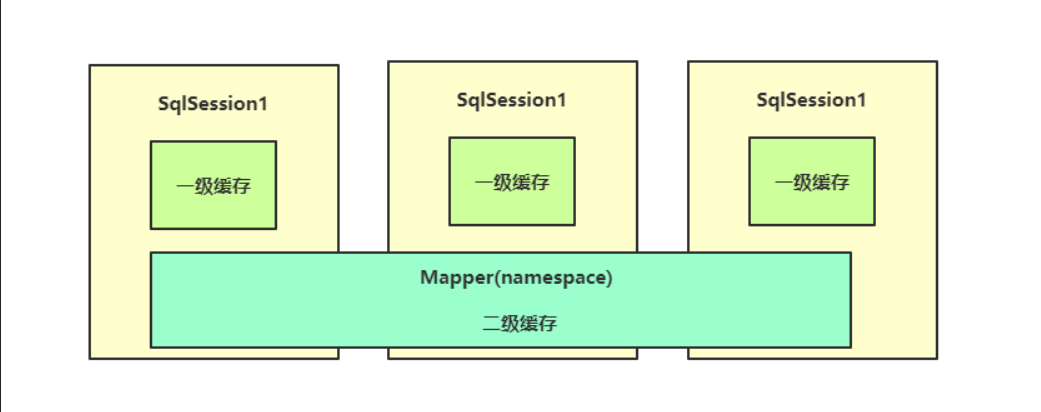
Mybatis存在一级缓存和二级缓存
一级缓存:默认情况下,只启用了本地的会话缓存,只对一个会话中的数据进行缓存(一级缓存无法关闭,只能调整)
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student1 = testMapper.getStudentBySid(1);
Student student2 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
比如说上面的代码,两次得到的是一个Student对象,也就是第二次查询的时候并没有重新去构造对象。而是直接得到之前创建好的对象
但是当我们对数据库进行修改时,会使得缓存失效;一个会话的DML操作只会重置当前会话的缓存,不会重置其他会话的缓存;其他会话的缓存不会更新
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student1 = testMapper.getStudentBySid(1);
testMapper.addStudent(new Student().setName("小李").setSex("男"));
Student student2 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
还有一种情况则是,当前会话结束的时候,也会清理全部的缓存;也就是说,一级缓存只针对单个会话,多个会话之间不相通
一级缓存给我们提供了很高速的访问效率,但是作用范围实在是有限;如果一个会话结束,那么之前的缓存就全部失效了;如果希望缓存能够扩展到所有会话都是用,就可以通过二级缓存来实现,二级缓存默认关闭状态,要开启二级缓存,需要再映射器XML文件中添加:
<cache/>
可见二级缓存是Mapper级的,也就是说,当一个会话失效,缓存依然存在于二级缓存中;因此如果再次创建一个新的会话会直接使用之前的缓存;
配置
<cache
eviction = "FIFO"
flushInterval = "60000"
size = "512"
readOnly = "true" />
给个代码
public static void main(String[] args) {
Student student;
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
student = testMapper.getStudentBySid(1);
}
try (SqlSession sqlSession2 = MybatisUtil.getSession(true)){
TestMapper testMapper2 = sqlSession2.getMapper(TestMapper.class);
Student student2 = testMapper2.getStudentBySid(1);
System.out.println(student2 == student);
}
}
会发现得到的依然是缓存的结果
如果我们不希望某个方法开启缓存,则可以通过添加useCache属性关闭缓存
<select id="getStudentBySid" resultType="Student" useCache="false">
SELECT* FROM student WHERE sid = #{sid}
</select>
我们也可以使用flushCache="false"在每次执行后都清空缓存,通过这这个我们还可以控制DML操作完成之后不清空缓存
<select id="getStudentBySid" resultType="Student" flushCache="true">
select * from student where sid = #{sid}
</select>
添加了二级缓存之后,会先从二级缓存中查找数据,当二级缓存没有时,才会从一级缓存中读取,如果还没有,则直接请求数据库
public static void main(String[] args) {
try(SqlSession ssession = MybatisUtil.getSession(true)) {
TestMapper mapper = ssession.getMapper(TestMapper.class);
Student student2;
try(SqlSession ssession2 = MybatisUtil.getSession(true)) {
TestMapper mapper2 = ssession2.getMapper(TestMapper.class);
student2 = mapper2.getStudentBySid(1);
}
Student student1 = mapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
上述代码得到的结果仍然是同一个对象,因为都是从二级缓存开始查找
读取顺序:二级缓存 => 一级缓存 => 数据库
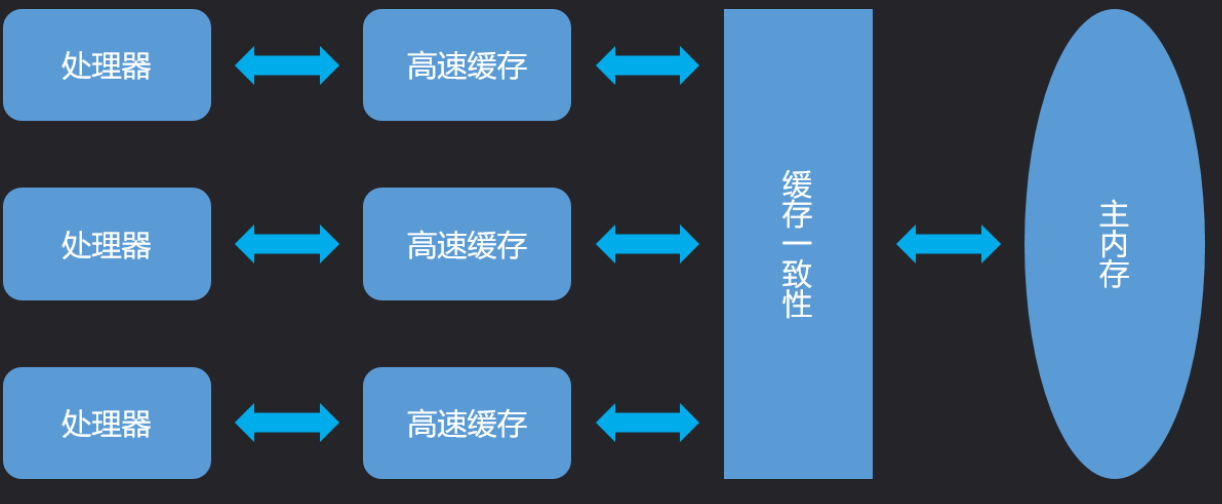
虽然缓存机制提供了很大的性能提升,但是缓存中存在一个问题,也就是缓存一致性问题;也就是说当多个CPU在操作自己的缓存时,可能会出现各自的缓存内容不同步的问题,而Mybatis也会这样,我们来看看这个例子:
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
while (true){
Thread.sleep(3000);
System.out.println(testMapper.getStudentBySid(1));
}
}
}
现在循环地每三秒读取一次,而在这个过程中,使用IDEA手动修改数据库中的数据,将1号同学的学号改成100,那么理想情况下,下一次读取将无法获取到小明,因为小明的学号已经发生变化了,但是结果却是依然能够读取,并且sid并没有发生改变,这也证明了Mybatis的缓存在生效,因为我们是从外部进行修改,Mybatis不知道我们修改了数据,所以依然在使用缓存中的数据,但是这样很明显是不正确的,因此,如果存在多台服务器或者是多个程序都在使用Mybatis操作同一个数据库,并且都开启了缓存,需要解决这个问题,要么就得关闭Mybatis的缓存来保证一致性:
<settings>
<setting name="cacheEnabled" value="false"/>
</settings>
要么就是先缓存共用,也就是让所有的Mybatis都用同一个缓存进行数据存储,等后面学习缓存框架就行了
<select id="getStudentBySid" resultType="Student" useCache="false" flushCache="true">
select * from student where sid = #{sid}
</select>
使用注解开发
- 注解的本质是使用反射,底层是代理模式
- 使用注解来映射简单语句会使代码显得更加简洁
- 如果需要做一些很复杂的操作,最好用 XML 来映射语句
可以无需xml映射器配置,而是直接使用注解在接口上进行配置
操作
首先来看一下,使用XML进行映射器编写时,需要先在XML中定义映射规则和SQL语句,然后再将其绑定到一个接口的方法定义上,然后再使用接口来执行:
<insert id="addStudent">
insert into student(name, sex) values(#{name}, #{sex})
</insert>
int addStudent(Student student);
而现在可以直接使用注解来实现,每个操作都有一个对应的注解:
@Insert("insert into student(name, sex) values(#{name}, #{sex})")
int addStudent(Student student);
当然,还需要修改一下配置文件中的映射器注册:
<mappers>
<mapper class="com.test.mapper.MyMapper"/>
<!-- 也可以直接注册整个包下的 <package name="com.test.mapper"/> -->
</mappers>
通过直接指定Class,来让Mybatis知道这里有一个通过注解实现的映射器
自定义映射规则 @Result
我们接着来看一下,如何使用注解进行自定义映射规则:
@Results({
@Result(id = true, column = "sid", property = "sid"),
@Result(column = "sex", property = "name"),
@Result(column = "name", property = "sex")
})
@Select("select * from student")
List<Student> getAllStudent();
直接通过@Results注解,就可以直接进行配置了,此注解的value是一个@Result注解数组,每个@Result注解都都一个单独的字段配置,其实就是我们之前在XML映射器中写的:
<resultMap id="test" type="Student">
<id property="sid" column="sid"/>
<result column="name" property="sex"/>
<result column="sex" property="name"/>
</resultMap>
注解来完成复杂查询
还是使用一个老师多个学生的例子:
@Results({
@Result(id = true, column = "tid", property = "tid"),
@Result(column = "name", property = "name"),
@Result(column = "tid", property = "studentList", many =
@Many(select = "getStudentByTid")
)
})
@Select("select * from teacher where tid = #{tid}")
Teacher getTeacherBySid(int tid);
@Select("select * from student inner join teach on student.sid = teach.sid where tid = #{tid}")
List<Student> getStudentByTid(int tid);
多出了一个子查询,而这个子查询是单独查询该老师所属学生的信息,而子查询结果作为@Result注解的一个many结果,代表子查询的所有结果都归入此集合中(也就是之前的collection标签)
<resultMap id="asTeacher" type="Teacher">
<id column="tid" property="tid"/>
<result column="tname" property="name"/>
<collection property="studentList" ofType="Student">
<id property="sid" column="sid"/>
<result column="name" property="name"/>
<result column="sex" property="sex"/>
</collection>
</resultMap>
同理,@Result也提供了@One子注解来实现一对一的关系表示,类似于之前的assocation标签:
@Results({
@Result(id = true, column = "sid", property = "sid"),
@Result(column = "sex", property = "name"),
@Result(column = "name", property = "sex"),
@Result(column = "sid", property = "teacher", one =
@One(select = "getTeacherBySid")
)
})
@Select("select * from student")
List<Student> getAllStudent();
如果现在希望直接使用注解编写SQL语句但是我希望映射规则依然使用XML来实现:
@ResultMap("test")
@Select("select * from student")
List<Student> getAllStudent();
@ResultMap
提供了@ResultMap注解,直接指定ID即可,这样就可以使用XML中编写的映射规则了
那么如果出现之前的两个构造方法的情况,且没有任何一个构造方法匹配的话,该怎么处理呢?
@Data
@Accessors(chain = true)
public class Student {
public Student(int sid){
System.out.println("我是一号构造方法"+sid);
}
public Student(int sid, String name){
System.out.println("我是二号构造方法"+sid+name);
}
private int sid;
private String name;
private String sex;
}
@ConstructorArgs
可以通过@ConstructorArgs注解来指定构造方法:
@ConstructorArgs({
@Arg(column = "sid", javaType = int.class),
@Arg(column = "name", javaType = String.class)
})
@Select("select * from student where sid = #{sid} and sex = #{sex}")
Student getStudentBySidAndSex(@Param("sid") int sid, @Param("sex") String sex);
得到的结果和使用constructor标签效果一致
@Param 注解
这个注解是为SQL语句中参数赋值而服务的。@Param的作用就是给参数命名
比如在mapper里面某方法Aint id,当添加注解后A@Param("userId") int id,也就是说外部想要取出传入的id值,只需要取它的参数名userId。将参数值传如SQL语句中,通过#{userId}进行取值给SQL的参数赋值
- 基本类型的参数和String类型,需要加上这个注解,引用类型不需要加
- 只有一个基本类型的参数,可以省略
- 在sql中引用的就是@Param(“xxx”)中设定的属性名
当不添加@Param时参数列表中出现两个以上的参数时,会出现错误:
@Select("select * from student where sid = #{sid} and sex = #{sex}")
Student getStudentBySidAndSex(int sid, String sex);
Exception in thread "main" org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: org.apache.ibatis.binding.BindingException: Parameter 'sid' not found. Available parameters are [arg1, arg0, param1, param2]
### Cause: org.apache.ibatis.binding.BindingException: Parameter 'sid' not found. Available parameters are [arg1, arg0, param1, param2]
at org.apache.ibatis.exceptions.ExceptionFactory.wrapException(ExceptionFactory.java:30)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:153)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:145)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:140)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectOne(DefaultSqlSession.java:76)
at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:87)
at org.apache.ibatis.binding.MapperProxy$PlainMethodInvoker.invoke(MapperProxy.java:145)
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:86)
at com.sun.proxy.$Proxy6.getStudentBySidAndSex(Unknown Source)
at com.test.Main.main(Main.java:16)
原因是Mybatis不明确到底哪个参数是什么,因此我们可以添加@Param来指定参数名称:
@Select("select * from student where sid = #{sid} and sex = #{sex}")
Student getStudentBySidAndSex(@Param("sid") int sid, @Param("sex") String sex);
**探究:**要是我两个参数一个是基本类型一个是对象类型呢?
System.out.println(testMapper.addStudent(100, new Student().setName("小陆").setSex("男")));
@Insert("insert into student(sid, name, sex) values(#{sid}, #{name}, #{sex})")
int addStudent(@Param("sid") int sid, @Param("student") Student student);
那么这个时候,就出现问题了,Mybatis就不能明确这些属性是从哪里来的:
### SQL: insert into student(sid, name, sex) values(?, ?, ?)
### Cause: org.apache.ibatis.binding.BindingException: Parameter 'name' not found. Available parameters are [student, param1, sid, param2]
at org.apache.ibatis.exceptions.ExceptionFactory.wrapException(ExceptionFactory.java:30)
at org.apache.ibatis.session.defaults.DefaultSqlSession.update(DefaultSqlSession.java:196)
at org.apache.ibatis.session.defaults.DefaultSqlSession.insert(DefaultSqlSession.java:181)
at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:62)
at org.apache.ibatis.binding.MapperProxy$PlainMethodInvoker.invoke(MapperProxy.java:145)
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:86)
at com.sun.proxy.$Proxy6.addStudent(Unknown Source)
at com.test.Main.main(Main.java:16)
那么就通过参数名称.属性的方式去让Mybatis知道要用的是哪个属性:
@Insert("insert into student(sid, name, sex) values(#{sid}, #{student.name}, #{student.sex})")
int addStudent(@Param("sid") int sid, @Param("student") Student student);
注意点:
- 当使用了@Param注解来声明参数的时候,SQL语句取值使用#{},${}取值都可以
- 不使用@Param注解时,参数只能有一个,并且是Javabean。在SQL语句里可以引用JavaBean的属性,而且只能引用JavaBean的属性
通过注解控制缓存机制
使用@CacheNamespace注解直接定义在接口上即可,然后我们可以通过使用@Options来控制单个操作的缓存启用
@CacheNamespace(readWrite = false)
public interface MyMapper {
@Select("select * from student")
@Options(useCache = false)
List<Student> getAllStudent();
探究Mybatis的动态代理机制
核心组件
- SqlSessionFactoryBuilder(构造器): 它可以从XML、注解或者手动配置Java代码来创建SqlSessionFactory。
- SqlSessionFactory: 用于创建SqlSession (会话) 的工厂
- SqlSession: SqlSession是Mybatis最核心的类,可以用于执行语句、提交或回滚事务以及获取映射器Mapper的接口
- SQL Mapper: 它是由一个Java接口和XML文件(或注解)构成的,需要给出对应的SQL和映射规则,它负责发送SQL去执行,并返回结果
实现

比如说自己瓜太多了,就想找人一起卖其他人就是代理
那么现在我们来尝试实现一下这样的类结构,首先定义一个接口用于规范行为:
public interface Shopper {
//卖瓜行为
void saleWatermelon(String customer);
}
然后需要实现一下卖瓜行为,也就是要告诉老板卖多少钱,这里就直接写成成功出售:
public class ShopperImpl implements Shopper{
//卖瓜行为的实现
@Override
public void saleWatermelon(String customer) {
System.out.println("成功出售西瓜给 ===> "+customer);
}
}
最后老板代理后肯定要用自己的方式去出售这些西瓜,成交之后再按照我们告诉老板的价格进行出售:
public class ShopperProxy implements Shopper{
private final Shopper impl;
public ShopperProxy(Shopper impl){
this.impl = impl;
}
//代理卖瓜行为
@Override
public void saleWatermelon(String customer) {
//首先进行 代理商讨价还价行为
System.out.println(customer + ":哥们,这瓜多少钱一斤啊?");
System.out.println("老板:两块钱一斤。");
System.out.println(customer + ":你这瓜皮子是金子做的,还是瓜粒子是金子做的?");
System.out.println("老板:你瞅瞅现在哪有瓜啊,这都是大棚的瓜,你嫌贵我还嫌贵呢。");
System.out.println(customer + ":给我挑一个。");
impl.saleWatermelon(customer); //讨价还价成功,进行我们告诉代理商的卖瓜行为
}
}
现在我们来试试看:
public class Main {
public static void main(String[] args) {
Shopper shopper = new ShopperProxy(new ShopperImpl()); //获取shopper接口的代理类,代理类再执行方法
shopper.saleWatermelon("小强");
}
}
这样的操作称为静态代理,也就是说我们需要提前知道接口的定义并进行实现才可以完成代理,而Mybatis这样的是无法预知代理接口的,我们就需要用到动态代理。
JDK提供的反射框架就为我们很好地解决了动态代理的问题,在这里相当于对JavaSE阶段反射的内容进行一个补充。
public class ShopperProxy implements InvocationHandler {
Object target;
public ShopperProxy(Object target){
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String customer = (String) args[0];
System.out.println(customer + ":哥们,这瓜多少钱一斤啊?");
System.out.println("老板:两块钱一斤。");
System.out.println(customer + ":你这瓜皮子是金子做的,还是瓜粒子是金子做的?");
System.out.println("老板:你瞅瞅现在哪有瓜啊,这都是大棚的瓜,你嫌贵我还嫌贵呢。");
System.out.println(customer + ":行,给我挑一个。");
return method.invoke(target, args);
}
}
通过实现InvocationHandler来成为一个动态代理,我们发现它提供了一个invoke方法,用于调用被代理对象的方法并完成我们的代理工作。现在就可以通过 Proxy.newProxyInstance来生成一个动态代理类:
public static void main(String[] args) {
Shopper impl = new ShopperImpl();
Shopper shopper = (Shopper) Proxy.newProxyInstance(impl.getClass().getClassLoader(),
impl.getClass().getInterfaces(), new ShopperProxy(impl));
shopper.saleWatermelon("小强");
System.out.println(shopper.getClass());
}
通过打印类型我们发现,就是我们之前看到的那种奇怪的类:class com.sun.proxy.$Proxy0,因此Mybatis其实也是这样的来实现的(肯定有人问了:Mybatis是直接代理接口啊,你这个不还是要把接口实现了吗?)那我们来改改,现在我们不代理任何类了,直接做接口实现:
public class ShopperProxy implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String customer = (String) args[0];
System.out.println(customer + ":哥们,这瓜多少钱一斤啊?");
System.out.println("老板:两块钱一斤。");
System.out.println(customer + ":你这瓜皮子是金子做的,还是瓜粒子是金子做的?");
System.out.println("老板:你瞅瞅现在哪有瓜啊,这都是大棚的瓜,你嫌贵我还嫌贵呢。");
System.out.println(customer + ":行,给我挑一个。");
return null;
}
}
public static void main(String[] args) {
Shopper shopper = (Shopper) Proxy.newProxyInstance(Shopper.class.getClassLoader(),
new Class[]{ Shopper.class }, //因为本身就是接口,所以直接用就行
new ShopperProxy());
shopper.saleWatermelon("小强");
System.out.println(shopper.getClass());
}