目录
1.问题描述
2.问题原因
3.问题解决
3.1思路1——忽视最后一层权重
额外说明:假如载入权重不写strict=False, 直接是model.load_state_dict(pre_weights, strict=False),会报错找不到key?
解决办法是:加上strict=False,这个语句就是指忽略掉模型和参数文件中不匹配的参数
3.2思路2——更改最后一层参数
额外说明:假如原有的model默认类别数 和 载入权重类别数不一致,代码如何更改?
1.问题描述
训练一个CNN时,比如ResNet, 借助迁移学习的方式使用预训练好的权重,在导入权重后报错:
RuntimeError: Error(s) in loading state_dict for ResNet:
size mismatch for linear.weight: copying a param with shape torch.Size([100, 2048]) from checkpoint, the shape in current model is torch.Size([10, 2048]).
size mismatch for linear.bias: copying a param with shape torch.Size([100]) from checkpoint, the shape in current model is torch.Size([10]).RuntimeError: Error(s) in loading state_dict for ResNet:
size mismatch for linear.weight: copying a param with shape torch.Size([100, 2048]) from checkpoint, the shape in current model is torch.Size([10, 2048]).
size mismatch for linear.bias: copying a param with shape torch.Size([100]) from checkpoint, the shape in current model is torch.Size([10]).
类似的也可以有:
RuntimeError: Error(s) in loading state_dict for ResNet:
size mismatch for fc.weight: copying a param with shape torch.Size([100, 2048]) from checkpoint, the shape in current model is torch.Size([10, 2048]).
size mismatch for fc.bias: copying a param with shape torch.Size([100]) from checkpoint, the shape in current model is torch.Size([10]).
导入权重的核心代码为:
model = model_dict[opt.model](num_classes=10)
model_path = "./save/models/ResNet50_vanilla/ckpt_epoch_240.pth"
pre_weights = torch.load(model_path)['model']
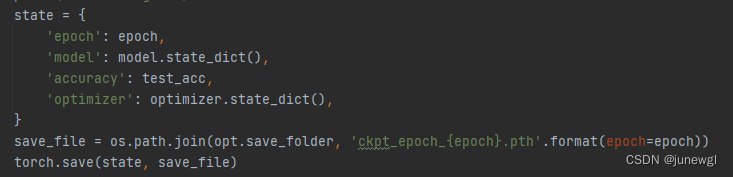
model.load_state_dict(pre_weights, strict=False)这里的pre_weighets后面还加的有['model']是因为在保存文件的时候出了保存权重,还保存有epoch, acc等等。
2.问题原因
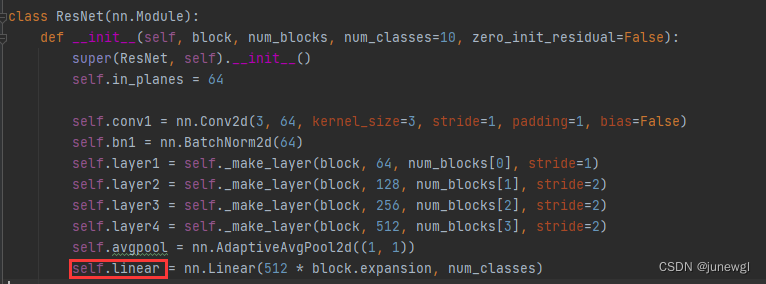
根本原因在于预训练权重的某一层参数和模型需要的参数对应不上,这里比如就是model.linear层,其实就是相当于全连接层fc, 可以直接model文件中去查看,最后一层的命名。比如进入定义好的ResNet文件中查看最后一层名字为linear。
具体的描述:预训练权重中最后一层的输出类别为100, 而现在我们的目标类别是10,所以导致linear层的参数对应不上,进而报错。(更常见的是在imagenet数据上训练分类类别为1000, 目标类别为10,也会是相同的错误)
3.问题解决
3.1思路1——忽视最后一层权重
查阅相关解决办法后,可以使用pop()函数弹出最后一层的参数,这样相当于导入的时候,只有前面网络层参数,就不会报最后一层参数不匹配的问题。所以把权重文件弹出pre_weights.pop('linear.weight')
pre_weights.pop('linear.bias')
核心代码:
model = model_dict[opt.model](num_classes=10)
model_path = "./save/models/ResNet50_vanilla/ckpt_epoch_240.pth"
pre_weights = torch.load(model_path)['model']
pre_weights.pop('linear.weight')
pre_weights.pop('linear.bias')
model.load_state_dict(pre_weights, strict=False)额外说明:假如载入权重不写strict=False, 直接是model.load_state_dict(pre_weights, strict=False),会报错找不到key?
RuntimeError: Error(s) in loading state_dict for ResNet:
Missing key(s) in state_dict: "linear.weight", "linear.bias".
解决办法是:加上strict=False,这个语句就是指忽略掉模型和参数文件中不匹配的参数
3.2思路2——更改最后一层参数
因为这里仅仅是最后一层参数不匹配,所以可以获取导入权重的最后一层,然后更改最终的分类类别数目
核心代码:
model.load_state_dict(pre_weights, strict=False)
in_channel = model.linear.in_features
model.linear = nn.Linear(in_channel, n_cls)
代码意思就是:
1.先按照正常的载入模型,如果原来的model文件默认的类别数目和载入权重默认的类别数目一致的话,那么就直接使用上述核心代码就行。
2.获取最后一层的输入特征维度,这里的model.linear.in_features, 是因为在model文件中自定义最后一层为self.linear,要根据实际名称更改
3.更新最后一层的输出特征维度,这里也要使用model.linear
额外说明:假如原有的model默认类别数 和 载入权重类别数不一致,代码如何更改?
举例子:比如model文件中默认分类类别数是10,如下图所示

但是载入权重文件的的分类类别数是100,如下图所示(这个权重文件训练的数据集就是100个分类类别)
![]()
此时,我想要在一个数据集只有7个类别的数据集上进行迁移学习,载入权重的话,就应该这样写:
# model
model = model_dict[opt.model](num_classes=100)
# print(model)
model_path = "./save/models/ResNet50_vanilla/ckpt_epoch_240.pth"
pre_weights = torch.load(model_path)['model']
# pre_weights.pop('linear.weight')
# pre_weights.pop('linear.bias')
# model.load_state_dict(pre_weights, strict=False)
# # # 更改最后的全连接层
model.load_state_dict(pre_weights, strict=False)
in_channel = model.linear.in_features
model.linear = nn.Linear(in_channel, n_cls)核心的想法是:实例化模型的时候,需要更改模型的分类类别数100 和 权重文件的类别100数保持一致,也就是如下
model = model_dict[opt.model](num_classes=100)
![[附源码]计算机毕业设计毕业生就业管理系统Springboot程序](https://img-blog.csdnimg.cn/6984e5400e57446b83e8a554a38b3e02.png)





![深入URP之Shader篇2: 目录结构和Unlit Shader分析[上]](https://img-blog.csdnimg.cn/81ca27a90ef149308c63722e5078bd1f.png)



![[附源码]计算机毕业设计云南美食管理系统Springboot程序](https://img-blog.csdnimg.cn/198c5612d7da40c59fd7457bab70a6c3.png)
