本图由AI生成
文/王吉伟
近期的AIGC领域仍旧火爆异常。
但火的不只是AIGC应用,还有巨头之间的AI竞赛,以及接连不断上新的AI大模型(LLM,Large Language Model)。
面对ChatGPT带来的技术冲击,为了研发谷歌多模态AI模型及应对微软GPT-4版Security Copilot竞争,谷歌先是将谷歌大脑和DeepMind团队合并为“Google DeepMind”部门,接着又推出了基于Sec-PaLM LLM大模型技术的谷歌云安全AI 工作台(Security AI Workbench)。
亚马逊推出了AI大模型服务Amazon Bedrock,马斯克成立了人工智能公司X.AI,并囤下万张NVIDIA芯片。
有媒体将之比喻为围剿ChatGPT。

但ChatGPT并不惊慌,仍然按照既有节奏新增了隐私功能使得用户数据不再被用于模型训练,并计划在未来几个月推出ChatGPT企业版。
对于谷歌、亚马逊等的动作,ChatGPT似乎并不在意,反而是微软总裁说了一句“中国将是 ChatGPT 的主要对手”,又将舆论目光引向国内。
国内市场则也迎来了“百模大战”时代。从3月开始到现在,各科技大厂及科研机构已经陆续发布了百度文心一言、阿里通义千问、华为云盘古、京东言犀等30多个大模型,目前还在不断上新,难怪微软总裁会发出前面的感慨。
然而在AI竞赛和“百模大战”的身后,笑得最开心的应该是NVIDIA。
竞争越激烈,算力需求也就越大,NVIDIA GPU也就卖得越好。
生成式AI应用的爆发和大模型的争相发布,让NVIDIA的算力供应迎来更辉煌的时代。黄仁勋先生在NVIDIA GTC23说的金句“我们正处于AI的iPhone时刻”,到现在已经广为流传,以至于GTC23已经过去一个多月,仍有很多人念念不忘。

已经连续举办14年的GTC如今已是全球最重要的AI大会之一,GTC23举办会议更是达到650多场,超过25万名注册用户深入参与到GTC各个主题的会议。
黄仁勋更是用长达78分钟的时间,讲述了NVIDIA及其合作伙伴如何提供训练和部署尖端AI 服务所需的各种技术。
看完他的分享以及多个会议及合作发布之后,王吉伟频道认为,AI大模型所带来的多元化算力需求,正在造就算力供给形式的进一步演变。
为什么这么说?本文就跟大家探讨一下。
AIGC应用持续爆发
这一轮AIGC技术带来的AI火爆,主要体现在C端的AI应用上。与以往AI主要改进和优化B端不同,LLM所带来ChatGPT、Midjourney等杀手级应用,在变革B端的同时,也让亿万用户对AI技术有了直观且震撼的感受。
ChatGPT、Midjourney还在快速进化着,在文字、代码、图片生成等领域叱咤风云的同时,更多厂商所推出的同类应用也在快速发展,AI生成音乐、视频、游戏的应用也正在雨后春笋般的出现。
现在,基于GPT-3\4、Dall-E等模型的AI应用越来越多。单是从GPT来看,GPT-3 DEMO网站统计的GPT-3应用程序已经超过800个,但这些程序并不包括企业推出的GPT应用。

随着更多组织引入或者自身搭建AI大模型,他们将利用这些技术改造已有应用,并会以对话的方式生成更多AI应用。
同时更多LLM的API开放服务,让创业变得更加简单。创业者只需要接入API就能将LLM集成到产品之中,大大提升产品业务效率和使用体验。
除了调用AI,创业者们也会基于Stable Diffusion、Meta AI等开源模型打造更多的生成式AI应用,满足不同领域的用户的需求。
Crunchbase数据显示,2021年获得投资的AIGC创业项目数量为291,2022年这一数据为211。经历了从年初到现在的AI应用大爆发,预测2023年的创业项目同样会迎来大爆发。
在诸多的AIGC工具中,有一类基于GPT的应用是用于生成程序的,可以让用户通过自然语言快速生成GPT应用。包括一些低代码、RPA等工具也在借助GPT让用户简单快速地打造需要的程序。这些AI工具的出现,直接让生成式AI应用出现倍数级增长。

Gartner预计到2025年,生成式人工智能将占所有生成数据的10%,目前这一比例还不到1%。这个数据意味着,在未来AIGC从1%到10%的发展进程中,将会出现海量AI应用。
事实上,推出LLM的大型企业是生成式AI应用的主要推动者,他们首先会将AIGC应用在自身产品体系推广,然后再服务更多客户。
LLM成为云计算和AI服务的主要部分之后,每个云计算厂商和推出LLM的厂商都将用此技术服务其生态内成千上万的客户,这些客户也会将生成式AI技术引入到企业内部软件应用之中。
AI大模型层出不穷
在AIGC应用海量爆发背后,正是各大科技厂商不断推出的AI大模型。在以OpenAI的GPT、Dall-E为代表的LLM出尽风头后,出于应战更出于商业生态所需,其他厂商陆续推出了各自的大模型。
在谷歌率先推出Bard并与NVIDIA联合开发了参数量高达5300亿的Megatron-Turing后,Meta发布了BlenderBot3、亚马逊推出了自有的大型语言模型泰坦(Titan),OpenAI前元老创立的Anthropic发布了Claude,Stability AI拥有Stable Diffusion并于近期推出了开源大语言模型StableLM。
马斯克也于近日启动了基于自研大模型的“TruthGPT”聊天机器人,为此他已经成立了X.AI公司,招募工程师,并已在NVIDIA购入高性能GPU。

除了大型公司,美国还有LLM领域比较知名的初创企业,比如前谷歌研究人员创立的Character.AI、由前LinkedIn联合创始人、DeepMind联合创始人等联合创立的Inflection AI、来自谷歌AI团队成员创立的Cohere以及Adept.ai等,这些AI公司都有自研AI大模型。
美国的AI大模型先人一步,其他国家自然也不能落下。
很多国家的相关组织也陆续发布了AI大模型,目前已知的部分国家的行动包括:
俄罗斯Yandex研发了大模型YaLM;英国DeepMind推出了Gopher超大型语言模型,前几天英国还宣布斥资1亿英镑建立新的“基础模型工作组”(Foundation Model Taskforce),以开发能带来“全球竞争力”的 AI 方案;韩国Naver研发了HyperCLOVA;以色列A21 Labs推出了Jurassic-1 Jumbo。
至于中国,更是开启了“百模大战”。
从3月16日百度基于文心大模型的“文心一言”发布后,国内就开启了“百模大战”模式。
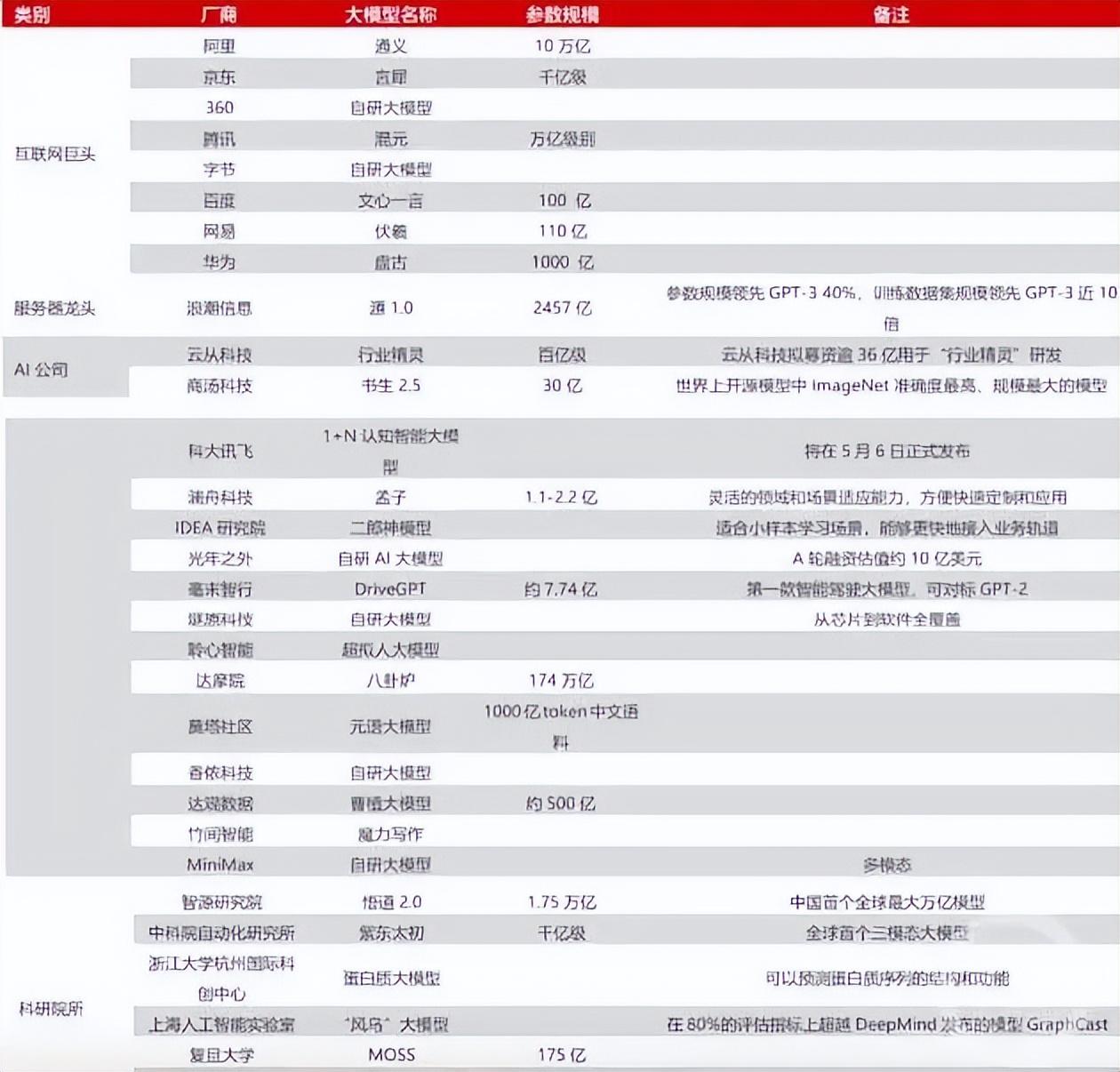
厂商们的AI大模型发布都集中在了4月,目前华为的盘古、360的智脑、商汤的日日新、阿里的通义千问、京东的言犀、腾讯的混元、中科院的紫东太初、科大讯飞的1+N认知、浪潮的源1.0、昆仑万维的天工3.5、云从科技的行业精灵、知乎的“知海图AI”、第四范式的“式说3.0”、科大讯飞的“星火认知”等大模型都已发布。
此外美团的联合创始人王慧文、搜狗创始人王小川,都创立新公司征战AI大模型,亦有其他巨头企业的AI项目负责人或者高管投身此领域。
目前而言,上述大模型再加上科研院系所公布的大模型,国内已有超过30个大模型亮相。可以肯定的是,后面还会继续有大型科技公司发布自己的AI大模型。
除了各国多个组织发布的AI大模型,Stable Diffusion等开源大模型也是一股不可忽视的力量。越来越多的开源模型,正在以本地部署的形式进入更多企业成为其构建生成式AI应用的模型层。
在大模型之外,像斯坦福发布的52k数据的Alpaca、AI风险投资公司Age of AI开发的FreedomGPT等中小模型,同样也是各大组织在安全及私有化部署层面关注的重点。

可以看到,所有大型企业都将推出自有大模型,同时很多组织已经意识到企业的应用程序都要构建于企业数字化架构的模型层之上,大模型将会成为所有企业的基础设施。
那么问题来了,现在全球有这么多的大模型,那将需要多么庞大的算力?这些算力又该如何供应?
别着急,下一节就会讲到。
算力需求的急剧攀升
AI大模型的快速发展,带来全球算力市场需求的高速上涨。随着AI技术的不断突破以及各种开源架构的推进,算法模型和数据反而成了最简单的,倒是算力不足成了大模型厂商遇到的最大的问题,或者说它已经成了影响AI大模型能力的主要因素。
LLM对算力的需求到底有多大?以ChatGPT为例,GPT-3训练成本预计在500万美元/次。
为支持ChatGPT对于强大算力的需求,微软于2019 年投资10亿美元建造了一台大型顶尖超级计算机,配备了数万个NVIDIA Ampere架构GPU,还在60多个数据中心总共部署了几十万个NVIDIA GPU进行辅助。
一个杀手级AI应用ChatGPT,就需要这么大的算力支持。而OpenAI还有Dall-E等多个大模型,可见OpenAI这家公司对算力的需求有多大。

不仅如此,模型参数的增长也会导致算力需求猛增。比如华为云盘古大模型的预训练参数规模达到2000亿,而阿里达摩院的M6模型参数更是达到10万亿,这些大模型对算力的需求已然超过ChatGPT。
OpenAI仅是一个大模型公司,上述谷歌等国外大型企业以及创业公司,还有国内已经超过30家推出大模型的组织,不管是自建数据中心还是将模型托管,想要大模型快速迭代与发展,都离不开庞大算力。
所以,在解决了算法模型和数据集后,为了让自有大模型能够快速落地商用,全球大模型厂商都把心思放到了算力之上,千方百计增加自身算力。
在算力打造方面,目前大模型厂商普遍采用的是GPU+CPU+NPU的异构方式。一般是以NVIDIA GPU为主,搭配自研或者其他厂商的小算力GPU、CPU及NPU。而想要在短期内获得并保证超大算力,NVIDIA是不二之选。

与此同时,与NVIDIA合作打造定制化GPU集群,为模型训练提供高效稳定可用的基础算力系统,也成了大模型厂商的共同选择。
为了满足OpenAI多模型的算力需求,微软基于NVIDIA最新旗舰芯片和NVIDIA Quantum-2 InfiniBand网络互连技术,推出Azure可大规模扩展的AI虚拟机系列以显著加速AI模型的开发。
亚马逊云科技和NVIDIA合作,构建全球最具可扩展性且按需付费的人工智能(AI)基础设施,以训练日益复杂的大语言模型(LLM)和开发生成式AI应用程序。
Meta与NVIDIA联合打造了RSC,这是全球最快的AI超级计算机之一。

在国内,有信息透露,百度在年初紧急下单3000台8张芯片(2.4万枚GPU)的服务器,百度全年会有5万枚Hopper架构GPU的需求。
阿里云预计在今年需要1万枚左右,其中6000枚也是该GPU。
近期腾讯所发布的新一代高性能计算集群HCC,同样采用了国内首发的NVIDIA Hopper架构GPU。
相关数据统计,国内对NVIDIA新一代Hopper架构GPU的需求,至少是数十万的级别。
当前阶段的LLM大发展,算力源头最终都指向了NVIDIA。这意味着,NVIDIA所提供的算力已经无处不在。
无处不在的NVIDIA算力
AI已经进入大模型时代,接下来所有领域所有行业都将进行一轮IT架构与应用程序的重大变革,所有组织都要引入大模型,所有AI应用都要建立在模型层之上。
NVIDIA自诞生以来一直致力于加速运算,尤其是2006年推出CUDA开发平台(通用并行计算架构)至今,所有行业早已认知到CUDA的价值,拥有CUDA支持的NVIDIA GPU也早已成为AI训练首选。
现在,几乎每个厂商推出的大模型,都需要以NVIDIA GPU为主的算力解决方案做支撑。构建于这些大模型之上的生成式AI应用,将会在各个领域得到应用。从这个角度而言,NVIDIA的算力已经无处不在。

而为了满足不同厂商的需求,NVIDIA也在不断求变。
GTC23期间,NVIDIA发布了用于数据中心的 NVIDIA Hopper架构GPU、Grace Hopper和Grace,其中Hopper GPU NVL是一款带有双 GPU NVLink的GPU产品,用于支持像ChatGPT这样的大型语言模型推理。
推出了搭载8个NVIDIA Hopper GPU的新版本DGX ,可以连接成为一个巨大的GPU,将成为全球大模型厂商构建AI基础设施的蓝图。
为了加速把DGX能力带给初创企业和其他各类企业,助力其快速打造新产品和制定AI战略,NVIDIA发布了用于AI云计算平台的NVIDIA DGX Cloud。
在加速生成式AI技术应用方面,NVIDIA还发布了NVIDIA AI Foundations云服务系列,为需要构建、完善和运行自定义大型语言模型及生成式AI的客户提供服务。

同时为帮助企业部署处于快速发展的生成式AI模型,NVIDIA发布了用于AI视频的NVIDIA L4 GPU、用于图像生成的NVIDIA L40 GPU、用于大型语言模型部署的NVIDIA H100 NVL 以及用于推荐模型的NVIDIA Grace Hopper。
这些产品、平台和解决方案的发布,可以让NVIDIA的算力以更强劲的动力传输到更多领域。
NVIDIA以算力助力多领域企业成长的案例已有太多,这里我们也来看几个GTC23展示的案例。
比如在医药领域,三井物产株式会社正在与NVIDIA合作开展“Tokyo-1”项目。该项目旨在使用高分辨率分子动力学模拟和用于药物研发的生成式 AI 模型等技术,为日本制药行业的领导者提供强大动力。

通过该项目,用户将能够访问 NVIDIA DGX 节点,以支持其进行分子动力学模拟、大型语言模型训练、量子化学、为潜在药物创建新型分子结构的生成式 AI 模型等。Tokyo-1 用户还可以通过NVIDIA BioNeMo 药物研发软件和服务,利用大型语言模型来处理化学、蛋白质、DNA 和 RNA 数据格式。
在汽车领域,NVIDIA与新能源汽车(NEV)制造商比亚迪将拓宽 NVIDIA DRIVE Orin™ 中央计算平台的应用范围,将用于其更多新能源车型之中。DRIVE Orin的强大计算能力能够实时处理各种冗余传感器信息,且这项技术还能为汽车制造商提供充足的计算裕量,支持其在整个汽车生命周期内,开发和运行全新的软件驱动型服务。
NVIDIA DRIVE Orin作为当前市面上性能最高的车规级处理器,自去年投产以来,已成为交通行业新一代新能源汽车、自动驾驶出租车和卡车的人工智能的首选引擎。
在通讯领域,AT&T和NVIDIA宣布了一项新合作,AT&T将通过使用NVIDIA驱动的AI来处理数据、优化服务车队路线规划并创建用于员工支持与培训的数字虚拟形象,以持续转变运营方式和增强可持续性。

AT&T是首个探索使用全套NVIDIA AI平台的电信运营商。这些产品包括使用NVIDIA AI Enterprise软件套件来提升其数据处理能力,这一套件包含NVIDIA RAPIDS Accelerator for Apache Spark;通过NVIDIA cuOpt,实现实时车辆路线规划和优化;通过NVIDIA Omniverse Avatar Cloud Engine和NVIDIA Tokkio,打造数字虚拟形象;以及通过NVIDIA Riva更好地利用对话式AI。
随着更多领域的客户采用NVIDIA的算力解决方案,NVIDIA的算力也将跟随合作伙伴为用户提供的服务而遍及更多垂直细分领域。
后记:市场需求造就算力模式演变
为了加速算力赋能千行百业,NVIDIA持续推出更多解决方案以满足更多客户的需求。而随着用户对于算力需求的变化,NVIDIA也在不断探索更加多元化的算力解决方案。
从GTC23所发布的一系列产品、技术及解决方案来看,NVIDIA已经从硬件算力供应商发展成为能够提供软硬件一体解决方案及AI云计算的多元化算力供应商。
这个改变一方面来自于NVIDIA对于全球客户对算力需求变化的时刻洞悉与及时响应,另一方面也来自于NVIDIA对算力如何更好助力人工智能发展的持续探索。

当然,更主要的是AI大模型爆发式增长所带来的庞大的算力需求,真正造就了一个无比庞大的市场。
在算力市场增速与规模方面,中国信息通信研究院数据,目前全球计算设备算力总规模达到615EFlops(Flops为算力单位,即每秒浮点运算次数),增速达到44%,预计2030年全球算力规模达到56ZFlops,平均年增速达到65%。
未来7年的算力供应,可以想象NVIDIA将会占据多大市场份额。
不说国外,单是中国市场目前已推出的三十多个大模型,就能感受到广大组织对算力的巨大需求,更不用说今后全球要出现的更多大模型。
不管是大模型、中模型还是小模型,只要组织构建或者引入大模型都离不开算力支持。

现在,发布自有大模型或者中模型正在成为大型企业的标配,而使用大模型和生成式AI技术也即将成为企业运营标配。
这两个标配的实施与落地的过程,便是NVIDIA算力走进更多组织的机会。并且,这个机会将会伴随着AGI(Artificial General Intelligence,通用人工智能)的一路发展而长期存在。
两个标配需求,也将进一步促进以NVIDIA为首的厂商算力供应模式开始从硬件方式走向更多元的发展。
市场需求,正在造就算力供应模式的演变。
而在这个演变进程中,无论是技术创新、产品引领、方案打造还是在算力变革,NVIDIA都扮演了绝对的主角。
黄仁勋在GTC23上表示,我们正处于AI 的iPhone时刻。AI大模型到来后,又何尝不是NVIDIA的iPhone时刻。
全文完
【王吉伟频道,关注AIGC与IoT,专注数字化转型、业务流程自动化与RPA。欢迎关注与交流。】