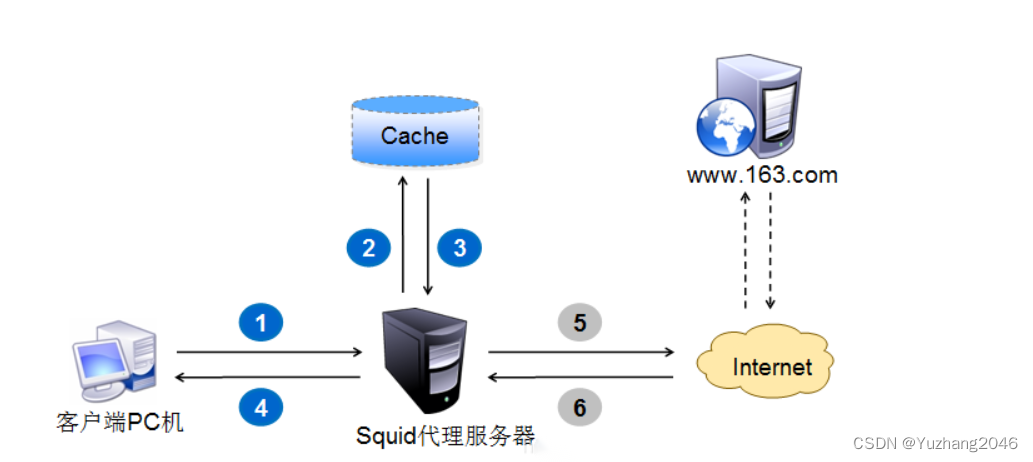
Airbnb 基础设施的一个重要作用是保证我们的云能够根据需求上升或下降进行自动扩缩容,我们每天的流量波动都非常大,需要依靠动态扩缩容来保证服务的正常运行。为了支持扩缩容,Airbnb 使用了 Kubernetes 编排系统,并且使用了一种基于 Kubernetes 的服务配置接口。 现在来讨论一下如何使用 Kubernetes Cluster Autoscaler 来动态调整集群的大小,这些改进增加了可定制性和灵活性,以满足 Airbnb 独特的业务需求。 在过去的几年中,Airbnb 已经将几乎所有的在线服务从手动编排的 EC2 实例迁移到了 Kubernetes。现如今,在近百个集群中运行了上千个节点来适应这些工作负载。 然而,这些变化并不是一蹴而就的,在迁移过程中,随着新技术栈上的工作负载和流量越来越多,底层的 Kubernetes 集群也随之变得越来越复杂。这些演变可以划分为如下三个阶段:
在使用 Kubernetes 之前,每个服务实例都运行在其所在的机器上,通过手动分配足够的容量来满足流量增加的场景。每个团队的容量管理方式都不尽相同,且一旦负载下降,很少会取消配置。 一开始 Kubernetes 集群的配置相对比较简单,配置有几个集群,每个集群都有单独的底层节点类型和配置,它们只运行无状态的在线服务。随着服务开始迁移到 Kubernetes,我们便开始在多租户环境中运行容器化的服务。这种聚合方式减少了资源浪费,并且将这些服务的容量管理整合到 Kuberentes 控制平面上。 在这个阶段,需要我们手动扩展集群,但相比之前仍然有着显著的提升。
集群配置的第二个阶段是因为更多样化的工作负载而出现的,每个试图在 Kubernetes 上运行的工作负载都有着不同的需求。为了满足这些需求,为此创建了一个抽象的集群类型,集群类型定义了集群的底层配置,这意味着集群类型的所有集群都是相同的,从节点类型到集群组件设置都是相同的。 越来越多的集群类型导致出现了越来越多的集群,最初通过手动方式来调节每个集群容量的方式,很快就变得崩溃了。为了解决这个问题,我们为每个集群添加了 Kubernetes Cluster Autoscaler 组件,该组件会基于pod requests 来动态调节集群的大小。如果一个集群的容量被耗尽,则 Cluster Autoscaler 会添加一个新的节点来满足 pending 状态的 pods。 同样,如果在一段时间内集群的某些节点的利用率偏低,则 Cluster Autoscaler 会移除这些节点。这种方式非常适合我们的场景,为我们节省了大约 5% 的总的云开销,以及手动扩展集群的运维开销。
当 Airbnb 的几乎所有在线计算都转移到 Kubernetes 时,集群类型的数量已经增长到 30 多个了,集群的数量也增加到了 100 多个。这种扩展使得 Kubernetes 集群管理相当乏味,例如,在集群升级时需要单独对每种类型的集群进行单独测试。 在第三个阶段,通过创建异构集群来整合集群类型,这些集群可以通过单个 Kubernetes 控制平面来容纳许多不同的工作负载:
首先,这种方式极大降低了集群管理的开销,因为拥有更少、更通用的集群会减少需要测试的配置数量;
其次,现在大多数 Airbnb 的服务已经运行在 Kubernetes 集群上,每个集群的效率可以为成本优化提供一个很大的杠杆。 整合集群类型允许在每个集群中运行不同的工作负载,这种工作负载类型的聚合(有些大,有些小)可以带来更好的封装和效率,从而提高利用率。通过这种额外的工作负载灵活性,可以有更多的空间来实施复杂的扩展策略,而不是默认的 Cluster Autoscaler 扩展逻辑。具体来说就是计划实现与 Airbnb 特定业务逻辑相关的扩缩容逻辑。
随着对集群的扩展和整合,就实现了异构(每个集群有多种实例类型),我们开始在扩展期间实现特定的业务逻辑,并且意识到有必要对扩缩容的行为进行某些变更。 要对 Cluster Autoscaler 所做的最重要的改进是提供一种新方法来确定要扩展的节点组,在内部 Cluster Autoscaler 会维护一系列映射到不同候选扩容对象的节点组,它会针对当前 Pending 状态的 pods 执行模拟调度,然后过滤掉不满足调度要求的节点组。如果存在 Pending 的 pods,Cluster Autoscaler 会尝试通过扩展集群来满足这些 pods,所有满足 pod 要求的节点组都会被传递给一个名为 Expander 的组件。
Expander 负责根据需求进一步过滤节点组,Cluster Autoscaler 有大量内置的扩展器选项,每个选型都有不同的处理逻辑。例如,默认是随机扩展器,它会随机选择可用的节点组,另一个是 Airbnb 曾经使用过的优先级扩展器 ,它会根据用户指定的分级优先级列表来选择需要扩展的节点组。 当使用异构集群逻辑的同时,可以发现默认的扩展器无法在成本和实例类型选择方面满足复杂的业务需求。假设,想要实现一个基于权重的优先级扩展器,目前的优先级扩展器仅允许用户为节点组设置不同的等级,这意味着它会始终以确定的顺序来扩展节点组。如果某个等级有多个节点组,则会随机选择一个节点组。基于权重的优先级策略可以支持在同一个等级下设置两个节点组,其中 80% 的时间会扩展一个节点组,另外 20% 的时间会扩展另一个节点组,但默认并不支持基于权重的扩展器。 除了当前支持的扩展器的某些限制外,还有一些操作上的问题:
Cluster Autoscaler 的发布流水线比较严格,在合并到上游之前,需要花大量时间来审核变更,但我们的业务逻辑和所需的扩展策略是在不断变化的,能够满足当前需求的扩展器并不一定能够满足未来的需求;
我们的业务逻辑是与 Airbnb 关联的,其他用户则没有这种业务逻辑,因此实现的特定逻辑并不一定对上游用户有用; 因此可以对 Cluster Autoscaler 中的新扩展器类型提出了一些要求:
我们希望扩展器是可扩展的,能够被其他用户使用,其他用户在使用默认的 Expanders 可能会遇到类似的限制,那么希望提供一个通用的解决方案,并回馈上游;
解决方案应该能够独立于 Cluster Autoscaler 部署,这样可以能够响应快速变更的业务需求。
解决方案应该能够融入 Kubernetes Cluster Autoscaler 生态系统,这样就无需一直维护一个 Cluster Autoscale 的分支。 鉴于这些需求,可以提出了一种设计,将扩展职责从 Cluster Autoscaler 的核心逻辑中分离出来,设计一种可插拔的“自定义扩展器” ,它实现 gRPC 客户端(类似 custom cloud provider),该自定义扩展器分为两个组件:
第一个组件是内置到 Cluster Autoscaler 中的 gRPC 客户端,这个 Expander 与 Cluster Autoscaler 中的其他扩展器遵循相同的接口,负责将 Cluster Autoscaler 中的有效节点组信息转换为定义好的 protobuf 格式,并接收来自 gRPC 服务端的输出,将其转换回 Cluster Autoscaler 要扩展的最终的可选列表。 service Expander {
rpc BestOptions ( BestOptionsRequest) returns ( BestOptionsResponse)
} message BestOptionsRequest {
repeated Option options;
map< string, k8s. io. api. core. v1. Node> nodeInfoMap;
} message BestOptionsResponse {
repeated Option options;
} message Option {
string nodeGroupId;
int32 nodeCount;
string debug;
repeated k8s. io. api. core. v1. Pod pod;
}
第二个组件是 gRPC 服务端,这需要由用户实现,该服务端作为一个独立的应用或服务运行,通过客户端传递的信息以及复杂的扩展逻辑来选择需要扩容的节点组。当前通过 gRPC 传递的 protobuf 消息是 Cluster Autoscaler 中传递给 Expander 的内容的(略微)转换版本。 在前面的例子中,可以非常容易地实现加权随机优先级扩展器,方法是让服务器从优先级列表中读取,并通过 confimap 读取权重百分比,然后进行相应的选择。
其实实现还包含一个故障保护选项,建议使用该选项将“多个扩展器”作为参数传递给 Cluster Autoscaler,使用该选择后,如果服务端出现故障,Cluster Autoscaler 仍然能够使用一个备用的扩展器进行扩展。 由于服务端作为一个独立的应用运行,因此可以在 Cluster Autoscaler 外开发扩展逻辑,且 gRPC 服务端可以根据用户需求实现自定义,因此这种方案对整个社区来说也非常有用。 在内部,从 2022 年开始,Airbnb 就一直在使用这种方案来扩缩容所有的集群,期间一直没有出现任何问题,它允许动态地选择何时去扩展特定的节点组来满足 Airbnb 的业务需求,从而实现可以开发一个可扩展的自定义扩展器。







![[Nginx 发布项目] 打包后的项目,使用nginx发布](https://img-blog.csdnimg.cn/45bc9b3e282e44f683b3b5ab1499e5c7.png)