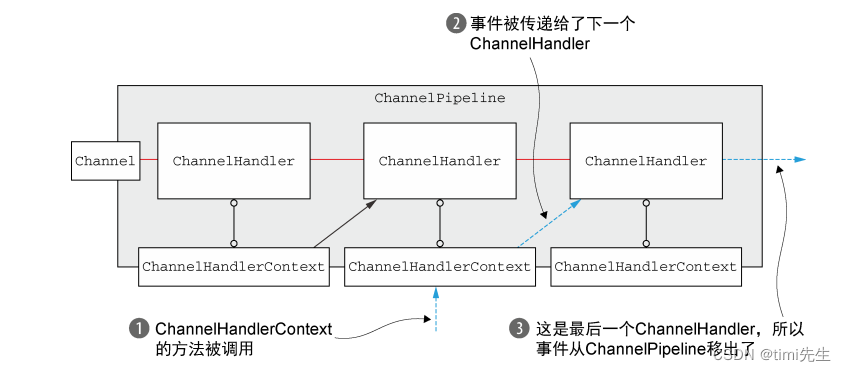
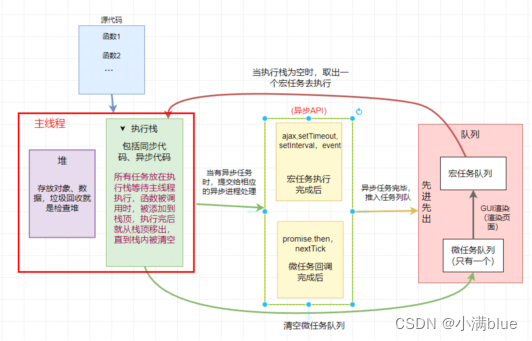
1.JS运行机制(EventLoop事件循环)
- Js是单线程,每次只能执行一项任务,其他任务按照顺序排队等待,使用eventloop来解决线程阻塞的问题。
- 在执行栈过程中,有同步代码和异步代码时,首先会执行完所有的同步代码,异步代码分类添加到宏任务队列或微任务队列中。
- 先微后宏,先执行微任务(promise、async、await、nextTick),再执行宏任务(setTimeOut、setInterval)。
- 执行栈执行完再从任务队列取出任务,再按规则执行,反复循坏就是EventLoop。
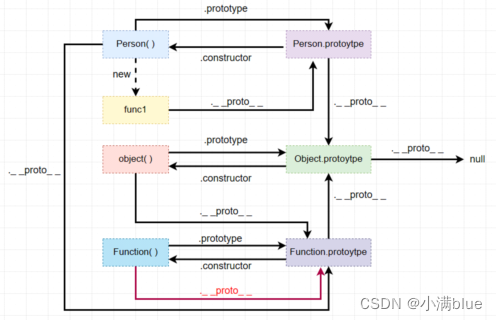
2.原型和原型链
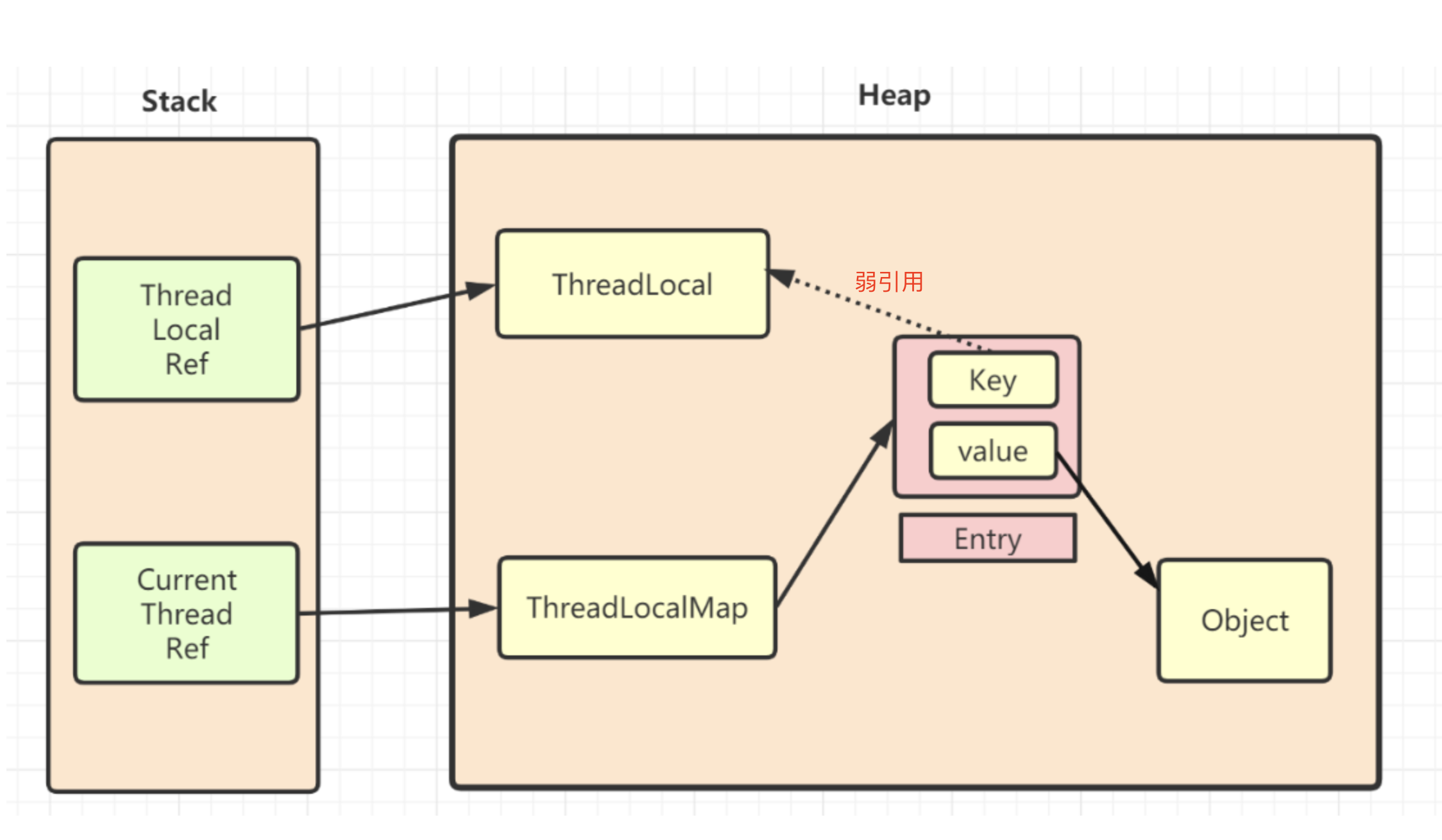
- 每个函数都有一个prototype属性,这个属性称为显示原型,它指向的是一个对象,这个对象就是原型对象;
- 原型对象是用来存放实例对象的共有属性和公有方法的,它有个constructor属性,指向它的构造函数,每个实例对象都有_ _proto_ _属性,被称为隐式原型;
- 通过_ _proto_ _链接起来的链式结构就称为原型链,查找属性时沿着原型链向上查找,直到它的最顶层Object.prototype的proto属性值为null;
- 构造函数是使用new关键字的函数,用来创建对象,所有函数都是Function()的实例;let fun1 = new Person(name,age); function Person(name,age){ };
- Function instanceof Object => true;Object instanceof Function => true;
3.栈和堆
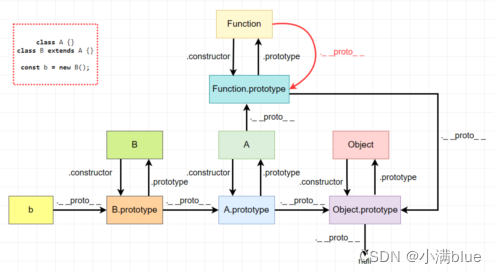
- 栈是一种连续存储的数据结构,先进后出;要读取栈中的某个元素,要将其之前所有元素出栈才能完成;
- 栈内存用于存放临时变量,主要存储各种基本类型的变量,Boolean、number、string、undefined、null;
- 栈内元素只能通过栈顶访问,另一端为栈底;
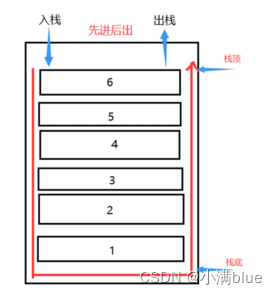
- 堆是非连续的树形存储数据结构,先进先出;
- 堆内存存储没规律可言,主要负责对象Object类型的存储;
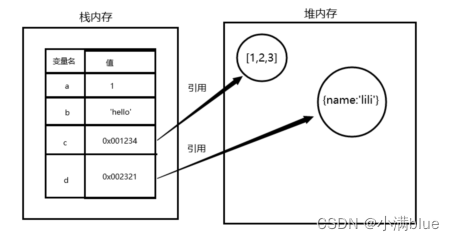
- 栈系统效率较高,堆内存需要分配空间和地址,还要把地址存到栈中,效率低;
- 栈内存中变量当执行环境结束就会被销毁被垃圾回收制回收,堆内存中的变量只在所有对它引用都结束时才会被回收;
4.深拷贝和浅拷贝
- 深拷贝和浅拷贝主要针对的是对象(引用类型)
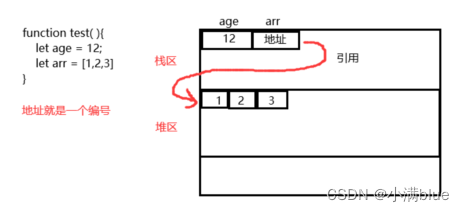
- 浅拷贝只拷贝了地址,并没有拷贝数据,所以其中一个改变,另一个随之改变;深拷贝拷贝了地址和数据,互不影响;
- 浅拷贝实现方式:Object.assign()、Array.prototype.slice()、Array.prototype.concat()、解构、扩展运算符(…);
- 深拷贝实现方法:JSON.parse(JSON.stringify())、递归;
5.防抖和节流
- 防抖:事件触发后,在n秒后执行回调,在这n秒内再次被触发,则重新计时;(输入框联想功能、短信验证码、提交表单)
- 节流:规定时间内只能触发一次函数,如果多次触发,只生效一次;(scroll事件、播放计算进度条事件、)
//节流throttle代码:
function throttle(fn,delay) {
let canRun = true;
return function () {
if (!canRun) return;
canRun = false;
setTimeout(() => {
fn.apply(this, arguments);
canRun = true;
}, delay);
};
}
//防抖debounce代码:
function debounce(fn,delay) {
var timeout = null;
return function (e) {
clearTimeout(timeout);
timeout = setTimeout(() => {
fn.apply(this, arguments);
}, delay);
};
}- 设置echarts防抖,保证拖动窗口大小,只执行一次获取浏览器宽高的方法;
- 地图层级变化时,利用防抖,地图层级变化完成再执行撒点操作;
- 全景图片查看,利用防抖,快速点击后查看最后一次点击的图片;
- 查看文档、下载功能,利用节流,在规定时间内,只加载一次文档或只执行一次下载功能;
6.数据类型及判断
- 基本数据类型(8种):string、number、null、undefined、boolean、symbol、bigint,bigint支持比number范围更大的整数值数据类型;
- 所有基本类型Boolean值为false的只有6个:0、NaN、’ ’、null、undefined、false;
- &&=>都是true才是true;||=>有一个true就是true;!=>取反;
- typeof判断基本数据类型,typeof null类型是object;
- instanceof只能判断引用数据类型,运行机制是判断其在原型链中能否找到该类型的原型,[ ] instanceof Array => true,不能检测null、undefined;
- constructor适用于基本和引用数据类型,(true).constructor => Boolean;
- Object.prototype.toString.call();
- null==undefined => true; null===undefined => false;NaN==NaN =>false;
- objected.is(+0,-0)=>false;onjected.is(NaN,NaN)=>true;
7.垃圾回收机制(GC)
- 浏览器的js具有自动回收垃圾机制,垃圾收集器会按照固定的时间间隔,周期性的找出不使用的变量,然后释放内存,防止内存泄漏;
- 垃圾回收方法:引用计数法、标记清除法;
- 引用计数法(现代主流浏览器不再用):看一个对象是否有指向它的引用;跟踪记录每个值被引用的次数,被引用一次就记录一次,多次引用就累加,减少1个引用就减1,如果引用次数为0,则释放内存;缺点:如果两个对象回想引用,但是两个都没有使用;
- 标记清除法:从根部出发定时扫描内存中的对象,凡是能从根部到达的对象,都还是需要使用的,那些无法由根部出发触及的对象,标记为不再使用,销毁掉标记的值,回收它们的内存空间;
- 内存泄漏:程序已经动态分配的堆内存由于某些原因没有得到释放,造成系统内存浪费,导致程序运行速度减慢,甚至系统崩溃;
- 导致内存泄漏:闭包、定时器、DOM
8.数组去重
- Set方法,form浅拷贝数组
function unique(arr){
return Array.from(new Set(arr))
}
- 双重for循环
function unique(arr){
let newArr:any = [];
for(let i=0;i<arr.length;i++){
let repeat:boolean = false;
for(let j=0;j<newArr.length;j++){
if(arr[i]===newArr[j]){
repeat = true;
break;
}
}
if(!repeat) newArr.push(arr[i]);
}
return newArr;
}
- 数组splice方法
function unique(arr){
for(var i=0;i<arr.length;i++){
for(var j=i+1;j<arr.length;j++){
if(arr[i]==arr[j]){
arr.splice(j,1);
j--;
}
}
}
return arr;
}
- 利用filter方法
function unique(arr){
let newArr = arr.filter((it,index)=>{
return arr.indexOf(it) = index;
})
return newArr;
}
- 利用includes方法
function unique(arr){
let newArr:any[] = [];
for(let i=0;i<arr.length;i++;){
if(!newArr.includes(arr[i])){
newArr.push(arr[i]);
}
}
return newArr;
}
- 利用对象
function unique(arr){
let newArr:any[] = [];
let obj:any = {};
arr.forEach(it=>{
if(!obj[it]){
newArr.push(it);
obj[it] = true;
}
});
return newArr
}
- 利用indexOf方法
function unique(arr){
let newArr:any[] = [];
for(let i=0;i<arr.length;i++;){
if(newArr.indexOf(arr[i])==-1){
newArr.push(arr[i]);
}
}
return newArr;
}
9.cookie,localstorage,sessionstorage 的区别
- cookie:可设置失效时间,不设置则默认关闭浏览器后失效;4KB左右,每次都会携带在http头中,使用cookie保存过多会带来性能问题;
- localstorage:永久保存,除非手动清除;大小5MB
- sessionStorage:仅在当前网页回话下有效,关闭页面或浏览器被清除,资源不共享,大小5MB。
10.事件
- 事件是文档和浏览器窗口发生的特定的交互瞬间,事件就发生了;
- 事件类型:事件捕获、事件冒泡;
- 事件捕获:由外向内,从事件发生的顶点开始,逐级往下查找,直到目标元素;
- 事件冒泡:由内向外,从目标元素触发,逐级向上传递,直到根节点;
- 事件流:页面接受事件的先后顺序;
- 事件委托(事件代理):利用事件冒泡,把子元素的事件绑定到父元素上,如果子元素阻止了事件冒泡,则事件委托无法实现;
- event.stopPropagation().stop;
- addEvtentListener(‘click’,函数名,true/false);默认为false(事件冒泡),true为事件捕获;
11.重绘和回流(重排)
- 重绘:元素样式改变不改变布局,浏览器重绘对元素进行更新,如颜色改变;
- 回流:元素的大小、结构变化,浏览器重新渲染页面,如width,height改变;
12.网页从开始到加载过程
- 输入网址后做域名解析
- 根据ip地址查找服务器,开始请求数据
- 服务器返回数据,浏览器开始解析
- 浏览器再次请求页面中使用的资源文件
- 解析展示整个页面
13.浏览器渲染引擎工作原理和流程
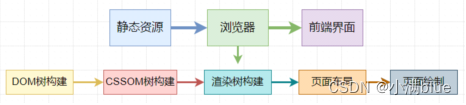
- 打包出来的 HTML、CSS、JavaScript 等文件,经过浏览器运行之后就会显示出页面,这个过程就是浏览器的渲染进程来操作实现的,渲染进程的主要任务就是将静态资源转化为可视化界面;
- 5个步骤:
- DOM树构建:使用HTML解析器解析HTML文档,将每个HTML元素转化为DOM节点,生成DOM树;
- CSSOM树构建:CSS解析器解析CSS,转化为CSS对象再组装起来,构建CSSOM树;
- 渲染树构建:DOM树和CSSOM树构建完后,浏览器根据这两棵树构建一棵渲染树;
- 页面布局:渲染树构建后,浏览器会计算出元素的大小和位置;
- 页面绘制:页面布局完后,浏览器把每个页面转换为像素,并对所有媒体文件进行解码
14.字符串方法
- str.concat():拼接字符串;(不如用模板字符串代替)
- str.slice(startIndex,endIndex):截取字符串,不包括endIndex处元素;
- str.substring(startIndex,endIndex):两个参数为负数或者NaN都会被当做0,如果大于字符串的长度则会被当做字符串的长度来计算,如果 startIndex 大于 endIndex,则 substring 的执行效果就像两个参数调换了一样;
- str.trim():删除字符串两端的空白符;
- str.toLowerCase():字符串值转为小写;
- str.toUpperCase():字符串值转为大写形;
- str.replace(正则要替换的元素,要替换的新的元素):返回替换后的新字符串;
- str.split():可以使用一个指定的分隔符来将字符串拆分成数组,返回一个数组;
- str.charAt(index):从一个字符串中返回指定的字符;
- str.includes():是否包含指定字符,包含返回true,否则返回false;
- str.indexOf():是否包含指定字符,包含则返回index,不包含返回-1;
- str.lastIndexOf():用法和indexOf相同, lastIndexOf()是从后往前查找;
- str.search():使用正则表达式查找指定字符串,找到返回首次匹配成功的index,没找到返回-1;
- str.match():返回一个字符串匹配正则表达式的结果,如果未设置全局匹配,则会返回第一个完整匹配及其相关的捕获组,捕获组中包含有groups、index、input等属性
15.数组方法
- 改变原数组
- push():数组末尾添加元素;
- pop():删除数组最后一个元素;
- shift():删除头部元素;
- unshift():数组开头添加;
- sort():排序,arr.sort((a,b)=>a-b);升序;
- splice():splice(0,1)从第一个元素开始截取一个元素;
- reverse():原数组倒序;
- forEach():遍历数组;
- 返回新数组
- concat():合并数组;
- slice():提取数组slice(1,2),1起2止,止不算;
- join():数组分割为字符串;
- toString():数组转字符串;
- map():没有return时,只遍历数组;
- filter():返回满足条件的元素组成的数组;
- every():每个元素都满足条件返回true;
- some():有一个元素满足条件返回true;
- find():返回第一个满足条件的元素;
- findIndex():返回第一个满足条件的下标,没有则返回-1;
- indexOf():从前往后找,返回当前查找的下标,没有返回-1;
- lastIndexOf():从后往前找,返回第一个满足的下标,没有返回-1;
- reduce():4个参数,arr.reduce((prev,cur,index,arr)=>{},init);(arr: 表示将要原数组;prev:表示上一次调用回调时的返回值,或者初始值init;cur:表示当前正在处理的数组元素;index:表示正在处理的数组元素的索引,若提供init值,则索引为0,否则索引为1;init: 表示初始值).例:计算数组中每个元素出现的次数;数组扁平化;
- includes():是否包含指定值,includes(a,b);a为查找元素,b为查找起始索引;包含返回true,否则false;
- flat():数组扁平化,可去除空项;
- fill():填充一个数组;fill(value,start,end);填充值,开始填充位置,结束位置;
- Array.from():将对象或字符串转为数组;
批量生成测试数据:
Array.from({length:100}).map(it,index)=>{return {id:index,name:’test’+index}};
16.ES6新特性
- 模板字符串、箭头函数、promise、const/let、解构赋值、扩展运算符(…)、class类的继承、Symbol、Map;
17.浏览器线程
- JS 引擎线程:单线程,负责解析运行 JavaScript 脚本。和 GUI 渲染线程互斥,JS 运行耗时过长就会导致页面阻塞。
- GUI 渲染线程:负责渲染页面,解析 HTML,CSS 构成 DOM 树等,当页面重绘或者回流都会调起该线程。和 JS 引擎线程是互斥的,当 JS 引擎线程在工作的时候,GUI 渲染线程会被挂起,GUI 更新被放入在 JS 任务队列中,等待 JS 引擎线程空闲的时候继续执行。
- 事件触发线程:当事件符合触发条件被触发时,该线程会把对应的事件回调函数添加到任务队列的队尾,等待 JS 引擎处理。
- 定时器触发线程:浏览器定时计数器并不是由 JS 引擎计数的,阻塞会导致计时不准确。开启定时器触发线程来计时并触发计时,计时完成后会被添加到任务队列中,等待 JS 引擎处理。
- http 请求线程:http 请求的时候会开启一条请求线程,请求完成有结果了之后,将请求的回调函数添加到任务队列中,等待 JS 引擎处理。
待更新......