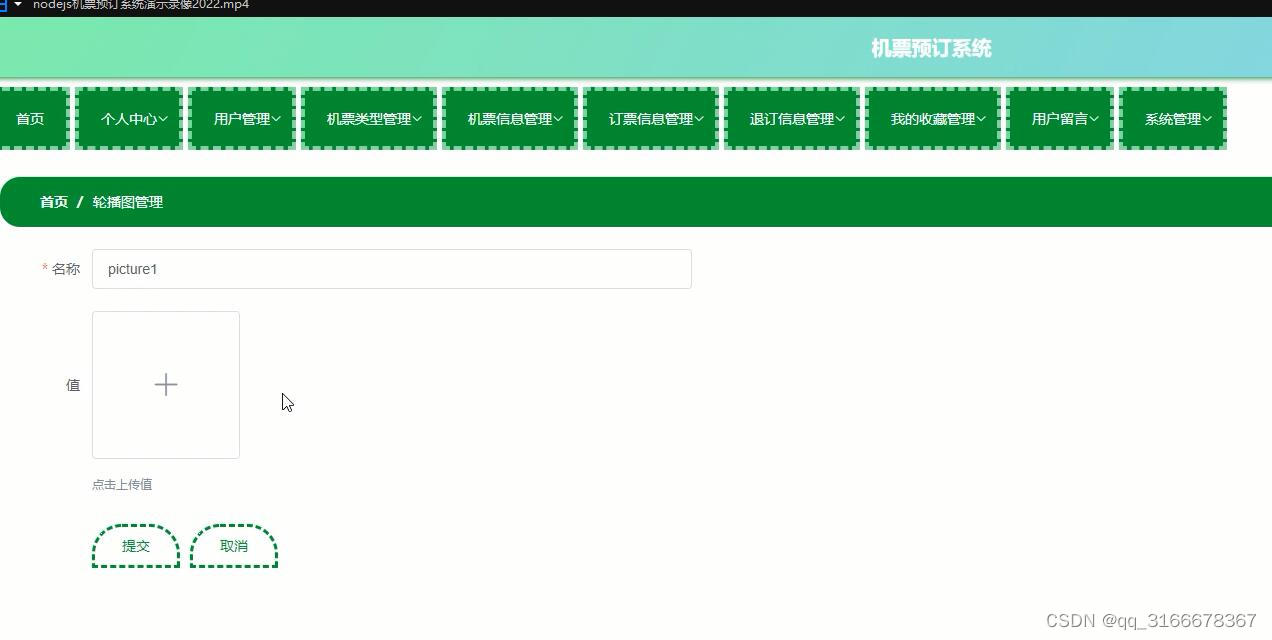
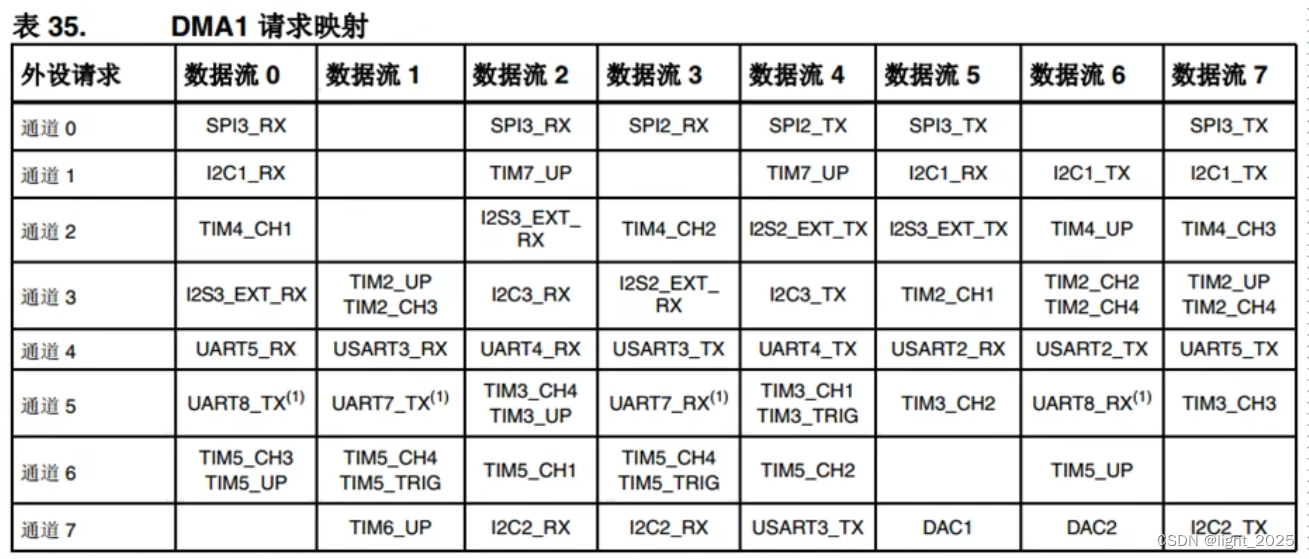
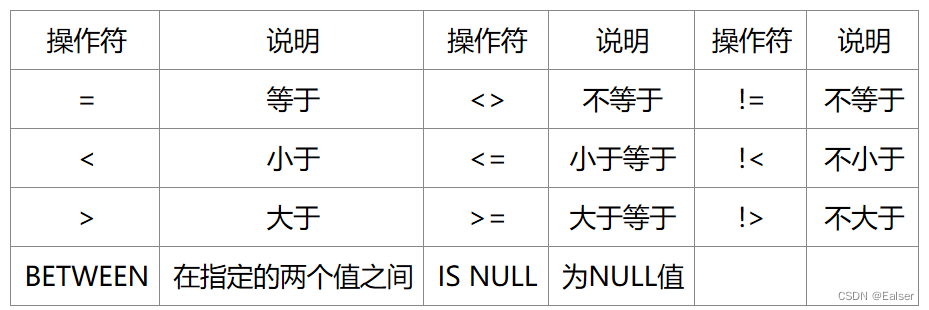
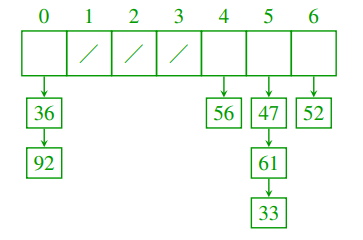
摘要
-我们提出了自由形式和开放式视觉问答(VQA)的任务。给定一张图像和一个关于图像的自然语言问题,任务是提供一个准确的自然语言答案。镜像现实场景,比如帮助视障人士,问题和答案都是开放式的。视觉问题有选择地针对图像的不同区域,包括背景细节和底层上下文。因此,在VQA上取得成功的系统通常需要比生成通用图像标题的系统更详细地了解图像和复杂的推理。此外,VQA适合自动评估,因为许多开放式答案只包含几个单词或一组封闭的答案,这些答案可以以多项选择的形式提供。我们提供了一个包含~ 0.25M幅图像、~ 0.76M个问题和~ 10M个答案的数据集(www.visualqa.org),并讨论了它提供的信息。提供了许多VQA的基线和方法,并与人类的表现进行了比较。我们的VQA演示可以在CloudCV (http://cloudcv.org/vqa)上获得。
介绍
我们正在见证多学科人工智能(AI)研究问题的新热潮。特别是,结合计算机视觉(CV)、自然语言处理(NLP)和知识表示与推理(KR)的图像和视频字幕的研究在过去的一年里急剧增加[16]、[9]、[12]、[38]、[26]、[24]、[53]。这种兴奋部分源于这样一种信念,即像图像字幕这样的多学科任务是解决AI问题的一步。然而,目前的技术水平表明,对图像的粗略场景级理解与单词n-gram统计配对足以生成合理的图像字幕,这表明图像字幕可能不像期望的那样“ai完整”。
是什么造就了一个令人信服的“AI-complete”任务?我们认为,为了产生下一代AI算法,一个理想的任务应该(i)需要超越单个子领域(如CV)的多模态知识,(ii)有一个定义良好的定量评估指标来跟踪进度。对于某些任务,如图像字幕,自动评估仍然是一个困难而开放的研究问题[51],[13],[22]。
在本文中,我们介绍了自由形式和开放式视觉问答(VQA)任务。VQA系统将图像和关于图像的自由形式、开放式、自然语言问题作为输入,并产生自然语言答案作为输出。这种目标驱动的任务适用于视障用户[3]或情报分析人员主动引出视觉信息时遇到的场景。示例问题如图1所示。
开放式问题需要潜在的大量AI能力来回答——细粒度识别(例如,“披萨上是什么样的奶酪?”),对象检测(例如,“如何……”)

活动识别(例如,“这个人在哭吗?”)、知识库推理(例如,“这是素食披萨吗?”)和常识推理(例如,“这个人的视力是20/20吗?”)。、“这个人期待有人陪伴吗?”)。VQA[19]、[36]、[50]、[3]也适用于自动定量评估,从而可以有效地跟踪该任务的进度。虽然许多问题的答案都是简单的“是”或“否”,但确定正确答案的过程通常远非微不足道(例如在图1中,“这个人有20/20的视力吗?”)。此外,由于关于图像的问题往往倾向于寻求特定的信息,对于许多问题来说,简单的一到三个单词的答案就足够了。在这种情况下,我们可以很容易地通过正确回答的问题数量来评估所提出的算法。在本文中,我们提出了一个开放式的回答任务和一个选择题任务[45],[33]。与需要自由形式回答的开放式任务不同,选择题任务只需要一个从预定义的可能答案列表中进行选择的算法。我们展示了一个包含来自MS COCO数据集[32]的204,721张图像的大型数据集,以及一个新创建的抽象场景数据集[57],[2],其中包含50,000个场景。MS COCO数据集具有描绘多样化和复杂场景的图像,这些图像有效地引出了引人注目和多样化的问题。我们收集了一个“逼真”抽象场景的新数据集,通过消除解析真实图像的需要,使研究只关注VQA所需的高级推理。为每个图像或场景收集了三个问题。每个问题由10名受试者连同他们的自信一起回答。该数据集包含超过760K个问题,大约1000万个答案。
虽然使用开放式问题提供了许多好处,但了解被问到的问题类型以及哪种类型的各种算法可能擅长回答仍然是有用的。为此,我们分析了被提问的问题类型和所提供的答案类型。通过几个可视化,我们展示了所提问题的惊人多样性。我们还探讨了问题的信息内容及其答案与图像说明的不同之处。对于基线,我们提供了几种结合使用文本和最先进视觉特征的方法[29]。作为VQA计划的一部分,我们将组织年度挑战和相关研讨会,讨论最先进的方法和最佳实践。
VQA提出了一系列丰富的挑战,其中许多挑战被视为自动图像理解和一般AI的圣杯。然而,它包含了CV、NLP和KR[5]、[8]、[31]、[35]、[4]社区在过去几十年里取得了重大进展的几个组成部分。VQA提供了一个有吸引力的平衡,一方面推动了最先进的技术,另一方面又足够方便社区开始在任务上取得进展。
相关工作
最近有几篇论文已经开始研究视觉问答[19]、[36]、[50]、[3]。然而,与我们的工作不同的是,这些都是相当有限的(有时是合成的)小数据集设置。例如,[36]只考虑答案来自16个基本颜色或894个对象类别的预定义封闭世界的问题。[19]还考虑从固定的对象词汇表、属性、对象之间的关系等模板中生成的问题。相比之下,我们提出的任务涉及由人类提供的开放式、自由形式的问题和答案。我们的目标是增加提供正确答案所需的知识和推理种类的多样性。对于在这个更困难和不受约束的任务上取得成功至关重要的是,我们的VQA数据集比[19],[36]大两个数量级(>250,000,分别比2,591和1,449张图像)。提出的VQA任务与其他相关工作有联系:[50]研究了视频和相应文本的联合解析,以回答每个包含15个视频剪辑的两个数据集上的查询。[3]使用众包工作者来回答视障用户提出的关于视觉内容的问题。在并发工作中,[37]提出将LSTM结合到用CNN的图像来生成答案。在他们的模型中,LSTM问题表示以每个时间步的CNN图像特征为条件,最终的LSTM隐藏状态用于顺序解码答案短语。相比之下,本文开发的模型探索了“后期融合”——即LSTM问题表示和CNN图像特征是独立计算的,通过元素智能乘法融合,然后通过全连接层生成输出答案类上的softmax分布。[34]生成抽象场景,以捕获与回答(纯文本)填空和视觉释义问题相关的视觉常识。[47]和[52]使用视觉信息来评估常识断言的合理性。[55]引入了一个10k图像的数据集,并提示了描述场景特定方面的字幕(例如,单个对象,接下来会发生什么)。在我们工作的同时,[18]为COCO图像收集了中文的问题和答案(后来由人类翻译成英文)。[44]使用COCO字幕自动生成了四种类型的问题(对象、计数、颜色、位置)。
基于文本的问答是NLP和文本处理社区中研究得很好的问题(最近的例子是[15],[14],[54],[45])。其他相关的文本任务包括句子补全(例如,[45]与多项选择答案)。这些方法为VQA技术提供了灵感。文本中的一个关键问题是问题的基础。例如,[54]合成的文本描述和基于一组固定位置的演员和对象的模拟的qa对。VQA自然以图像为基础——需要同时理解文本(问题)和视觉(图像)。我们的问题是由人类生成的,这使得对常识性知识和复杂推理的需求更加必要。
描述视觉内容(Visual Content)。与VQA相关的是图像标注[11]、[29]、图像字幕[30]、[17]、[40]、[9]、[16]、[53]、[12]、[24]、[38]、[26]和视频字幕[46]、[21]等任务,其中生成单词或句子来描述视觉内容。虽然这些任务既需要视觉知识,也需要语义知识,但字幕通常是非特定的(例如,由[53]观察到的)。VQA中的问题需要关于图像的详细具体信息,而一般的图像标题几乎没有用处[3]。
其他视觉+语言任务。最近的几篇论文探索了视觉和语言交叉的任务,这些任务比图像标题更容易评估,比如共同参考分辨率[28],[43]或生成参考表达式[25],[42]对于图像中的特定对象,这将允许人类识别被引用的对象(例如,“穿红衬衫的那个”,“左边的狗”)。虽然任务驱动和具体,但一组有限的视觉概念(例如,颜色,位置)倾向于通过引用表达来捕获。正如我们所展示的,从视觉问题及其答案中产生了更丰富的视觉概念。
VQA数据收集
我们现在描述视觉问答(VQA)数据集。我们从描述真实图像和抽象图像开始

用于收集问题的场景。接下来,我们描述我们收集问题的过程以及相应的答案。对收集到的问题和答案以及基线“&方法”结果的分析将在以下章节中提供。
真正的图像。我们使用了来自新发布的Microsoft Common Objects in Context (MS COCO)[32]数据集的123,287张训练和验证图像以及81,434张测试图像。收集MS COCO数据集,寻找包含多个对象和丰富上下文信息的图像。考虑到这些图像的视觉复杂性,它们非常适合我们的VQA任务。我们收集的图像越多样化,得到的问题集及其答案就越多样化、全面和有趣。
抽象的场景。具有真实图像的VQA任务需要使用复杂且经常有噪声的视觉识别器。为了吸引有兴趣探索VQA所需的高级推理而不是低级视觉任务的研究人员,我们创建了一个新的抽象场景数据集[2],[57],[58],[59],其中包含50K个场景。该数据集包含20个“纸娃娃”人体模型[2],跨越性别、种族和年龄,有8种不同的表情。四肢是可调节的,以允许连续的姿势变化。剪贴画可以用来描绘室内和室外的场景。该套装包含100多个物体和31个动物,摆出各种姿势。使用这种剪贴画可以创建更逼真的场景(见图2的下一行),与以前的论文[57],[58],[59]相比,这些场景更接近真实图像。用户界面见附录,
附加细节,以及示例。
分裂。对于真实图像,我们遵循与MC COCO数据集[32]相同的训练/val/测试分割策略(包括test- dev, test-standard, test-challenge, test-reserve)。对于VQA挑战(参见第6节),test-dev用于调试和验证实验,并允许无限制地提交给评估服务器。test -standard是VQA竞赛的“默认”测试数据。当与最先进的技术进行比较时(例如,在论文中),结果应该在test-standard上报告。Test-standard还用于维护公共排行榜,该排行榜在提交时更新。Test-reserve用于防止可能的过拟合。如果一种方法在测试标准和测试储备上的分数存在实质性差异,这就会引发危险信号,并促使进一步调查。test-reserve的结果不会公开披露。最后,通过test-challenge来确定挑战赛的优胜者。
对于抽象场景,我们创建了拆分进行标准化,将场景分为20K/10K/20K,分别用于训练/val/测试拆分。抽象场景没有细分(test-dev, test-standard, test-challenge, test-reserve)。
字幕。MS COCO数据集[32],[7]已经为所有图像包含了5个单句字幕。我们还使用相同的用户界面为所有抽象场景收集了5个单句说明文字1 进行收集。
的问题。收集有趣、多样、构思合理的问题是一项重大挑战。许多简单的问题
可能只需要低级的计算机视觉知识,比如“猫是什么颜色的?”或“场景中有多少把椅子?”然而,我们也想要一些需要关于场景常识的问题,比如“图中的动物发出什么声音?”重要的是,问题还应该要求图像正确回答,而不是仅仅使用常识信息来回答,例如,在图1中,“胡子是由什么制成的?”。通过拥有各种各样的问题类型和难度,我们可能能够衡量视觉理解和常识推理的持续进步。
为了收集这些“有趣”的问题,我们测试和评估了许多用户界面。具体来说,我们进行了试点研究,要求人类受试者就他们认为“蹒跚学步的孩子”、“外星人”或“智能机器人”难以回答的给定图像提出问题。我们发现“智能机器人”界面引出了最有趣、最多样化的问题。如附录所示,我们最终的界面是这样表述的:
“我们已经建造了一个智能机器人。它能理解很多图像。它可以识别和命名所有的物体,它知道物体在哪里,它可以识别场景(例如,厨房,海滩),人们的表情和姿势,以及物体的属性(例如,物体的颜色,它们的纹理)。你的任务就是给这个智能机器人树桩!
问一个关于这个场景的问题,这个智能机器人可能无法回答,但任何一个人都可以在看着图像中的场景时轻松回答。”
为了对一般的与图像无关的问题产生偏见,受试者被指示提出需要图像来回答的问题。
真实图像和抽象场景都使用了相同的用户界面。总共为每个图像/场景收集了来自独特工作者的三个问题。在撰写问题时,受试者会看到之前已经针对该图像提出的问题,以增加问题的多样性。总的来说,数据集包含超过0.76M个问题。
的答案。开放式问题会产生多种可能的答案。对于许多问题,一个简单的“是”或“否”的回答就足够了。然而,其他问题可能需要一个简短的短语。多个不同的答案也可能是正确的。例如,“白色”、“棕褐色”或“off-white”的答案可能都是同一个问题的正确答案。人类受试者也可能对“正确”答案持不同意见,例如,一些人说“是”,而另一些人说“不是”。为了处理这些差异,我们从不同的工人那里为每个问题收集了10个答案,同时也确保回答问题的工人没有问这个问题。我们要求受试者提供的答案是“一个简短的短语,而不是一个完整的句子。实事求是地回答,避免使用会话语言或插入你的观点。”除了回答问题外,研究对象还被问到“你认为你能正确回答这个问题吗?”,并给出“不”、“可能”和“是”的选择。有关用户界面的更多详细信息,请参阅附录以收集答案。对所提供答案的分析请参见第4节。
为了进行测试,我们提供了两种方式来回答这些问题
选项:(i)开放式和(ii)选择题。
对于开放式任务,生成的答案使用以下准确性指标进行评估:
也就是说,如果至少有3个工作人员提供了准确的答案,那么这个答案就被认为是100%准确的。2 在比较之前,所有答案都是小写的,数字转换为数字,标点和冠词被删除。我们避免使用软指标,如Word2Vec[39],因为它们经常将我们希望区分的单词组合在一起,例如“左”和“右”。我们也避免使用机器翻译中的评价指标,如BLEU和ROUGE,因为这些指标通常适用于包含多个单词的句子,并且可靠。在VQA中,大多数答案(89.32%)是单个单词;因此,预测答案与基真答案之间不存在高阶n-gram匹配,低阶n-gram匹配退化为精确字符串匹配。此外,已经发现BLEU和ROUGE等自动指标与人类对图像标题评估等任务的判断相关性很差[6]。
对于选择题,每个问题有18个备选答案。与开放式任务一样,所选选项的准确性是根据提供该答案的人类受试者的数量(除以3并裁剪为1)来计算的。我们从四组答案中生成正确和不正确答案的候选集:正确:最常见的(10个中)正确答案。似是而非:为了生成不正确但仍然似是而非的答案,我们要求三名受试者在没有看到图像的情况下回答问题。有关收集这些答案的用户界面的更多详细信息,请参阅附录。如果没有找到三个唯一的答案,我们使用词袋模型从最近邻问题中收集额外的答案。这些答案的使用有助于确保图像,而不仅仅是常识知识,是回答问题所必需的。人气:这是最受欢迎的10个答案。例如,这些是“是”,“否”,“2”,“1”,“白色”,“3”,“红色”,“蓝色”,“4”,“绿色”的真实图像。最受欢迎的答案的包含使得算法更难以从提供的答案集中推断问题的类型,也就是说,仅仅因为答案中存在“是”和“否”,就学习到这是一个“是或否”的问题。随机:从数据集中的随机问题中得到正确答案。为了生成总共18个候选答案,我们首先找到正确的、可信的和受欢迎的答案的并集。我们加入随机答案,直到找到18个独特的答案。答案的顺序是随机的。选择题示例在附录中。
请注意,所有18个候选人的答案都是唯一的。但由于每个问题都有10个不同的科目回答,这10个答案中有可能不止一个出现在18个选项中。在这种情况下,根据准确度指标,多个选项可能具有非零的准确度。
vqa数据集分析
在本节中,我们对VQA训练数据集中的问题和答案进行了分析。为了理解所提问的问题和所提供的答案的类型,我们将问题类型和答案的分布可视化。我们还探索了在没有图像的情况下,仅使用常识性信息回答问题的频率。最后,我们分析图像标题中包含的信息是否足以回答问题。
该数据集包括来自MS COCO数据集[32]的204,721幅图像的614,163个问题和7,984,119个答案(包括有和没有看图像的工作人员提供的答案),以及50,000个抽象场景的150,000个问题和1,950,000个答案。
问题
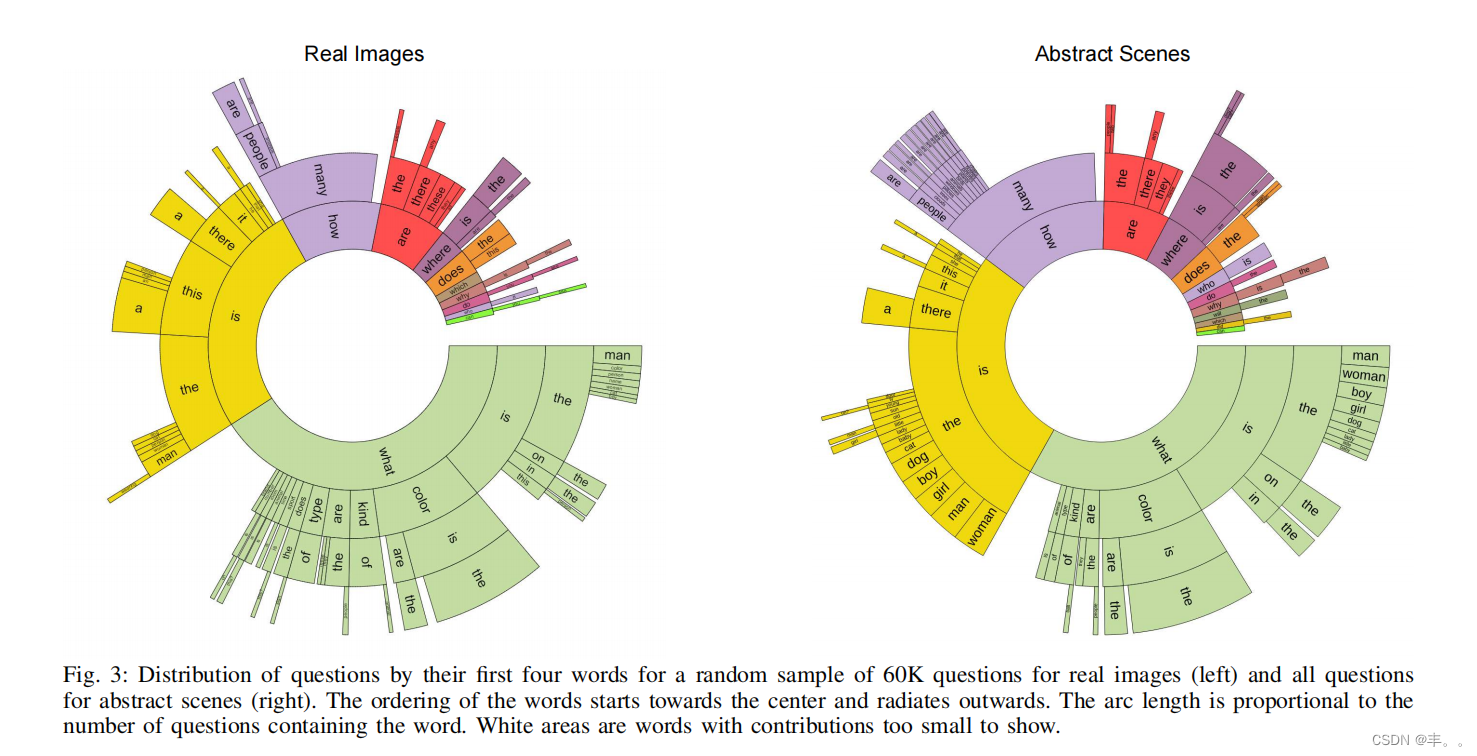
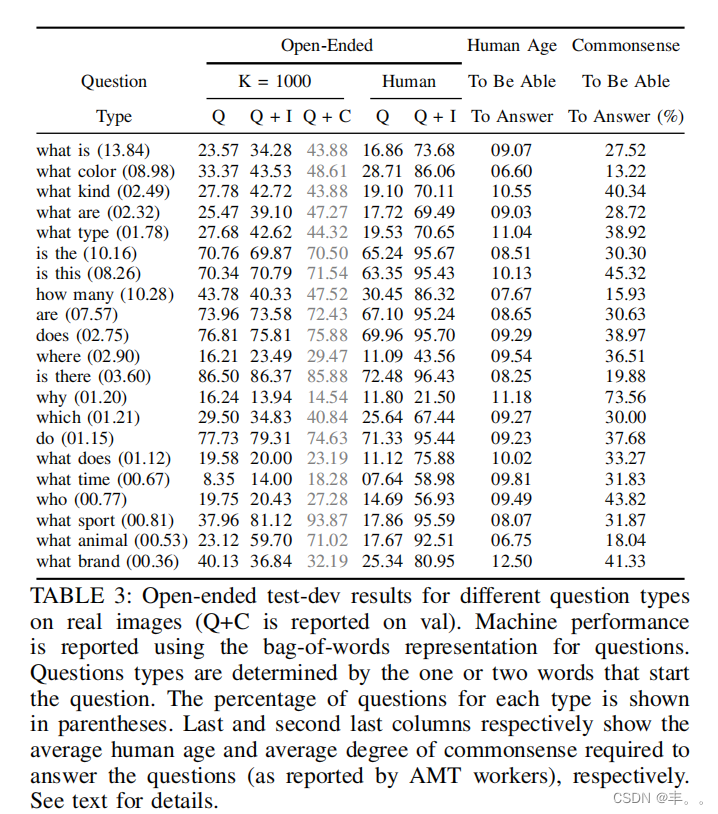
问题的类型。给定英语中生成的问题的结构,我们可以根据问题开头的单词将问题聚类为不同的类型。图3显示了真实图像(左)和抽象场景(右)基于问题的前四个单词的问题分布。有趣的是,无论是真实图像还是抽象场景,问题的分布都非常相似。这有助于证明,抽象场景引出的问题类型与真实图像引出的问题类型相似。存在着令人惊讶的各种各样的问题类型,包括“什么是……”、“那里有……吗”、“有多少……”和“有没有……”。从数量上看,不同类型问题的百分比如表3所示。几个示例问题和答案如图2所示。一个特别有趣的问题类型是“什么是……”问题,因为它们有不同的集合
可能答案的百分比。参见附录中“什么是……”问题的可视化。
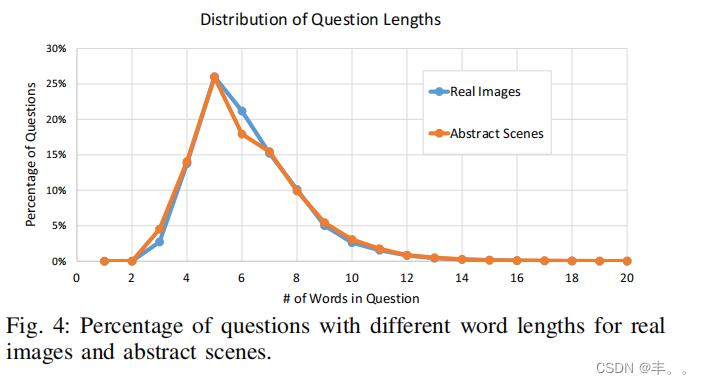
长度。图4显示了问题长度的分布。我们看到,大多数问题的长度在4到10个单词之间。
答案
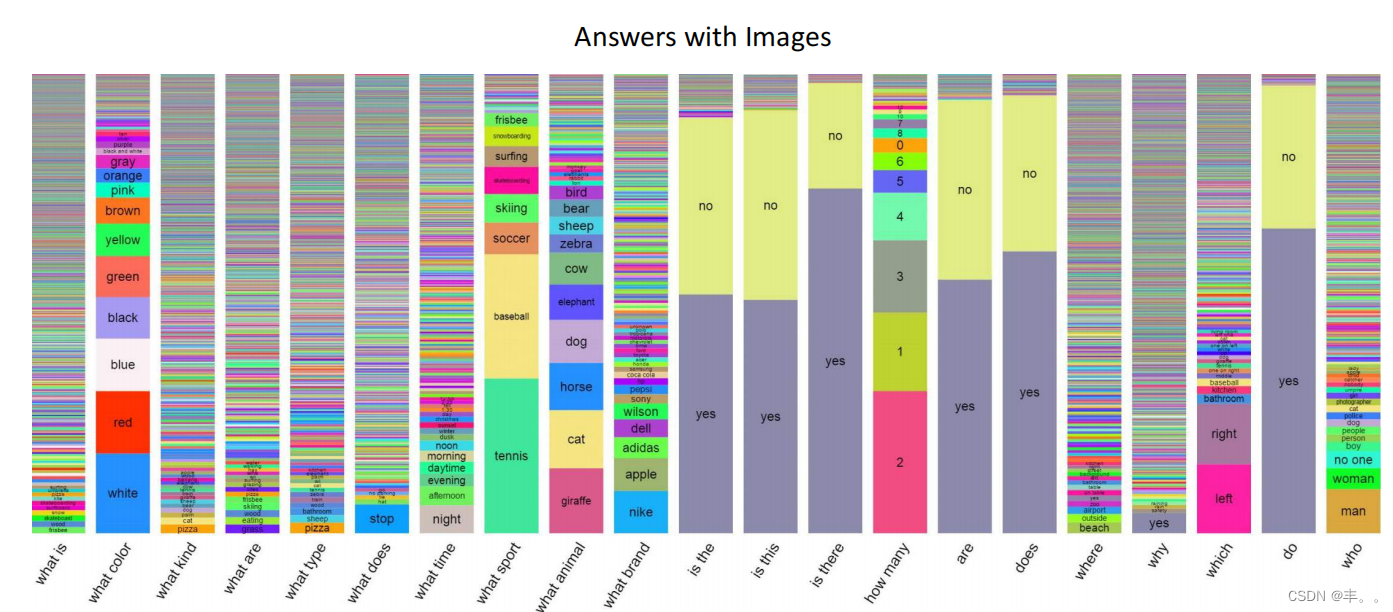
典型的答案。图5(上)显示了几种问题类型的答案分布。我们可以看到,许多问题类型,如“是…,“Are…”,以及“是否……”,通常用“是”和“不是”来回答。其他问题,如“什么是……”和“什么类型的……”有丰富多样的回答。其他类型的问题,如“什么颜色……”或“哪个……”,则有更专门的回答,比如颜色,或者“左”和“右”。见附录中最受欢迎的答案列表。
长度。大多数答案由一个单词组成,包含一个、两个或三个单词的答案分布,真实图像的答案分别为89.32%、6.91%和2.74%,抽象场景的答案分别为90.51%、5.89%和2.49%。答案的简洁并不令人惊讶,因为这些问题往往会从图像中引出特定的信息。这是对比
使用一般描述整个图像的图像说明,因此往往较长。我们的答案的简洁使得自动评估成为可能。虽然人们可能很容易相信答案的简洁会让问题变得更容易,但请记住,它们是人类对开放式问题提供的开放式答案。这些问题通常需要复杂的推理才能得出这些看似简单的答案(见图2)。目前,我们的数据集中有23234个唯一的单字答案,用于真实图像,3770个用于抽象场景。
“Yes/No”和“Number”的答案。很多问题的答案要么是“是”,要么是“否”(有时是“可能”)——真实图像和抽象场景的问题分别占38.37%和40.66%。在这些“是/否”的问题中,有一种偏向于“是”的倾向——对于真实图像和抽象场景,58.83%和55.86%的“是/否”答案是“是”。问题类型如“有多少……”的问题类型可以用
数字——关于真实图像和抽象场景的问题中,有12.31%和14.48%是“数字”问题。“2”是“数字”问题中最受欢迎的答案,占真实图像“数字”答案的26.04%,占抽象场景“数字”答案的39.85%。
主题的信心。当受试者回答问题时,我们会问“你认为你能正确回答这个问题吗?”图6显示了回答的分布情况。对于真实图像和抽象场景,大多数答案都被标记为自信。
人类的协议。自信的自我判断是否对应于被试之间的答案一致?图6显示了(i) 7个或更多、(ii) 3−7个或(iii)少于3个受试者在给定其平均置信度分数(0 =不自信,1 =自信)的情况下同意答案的问题百分比。正如预期的那样,受试者之间的一致性
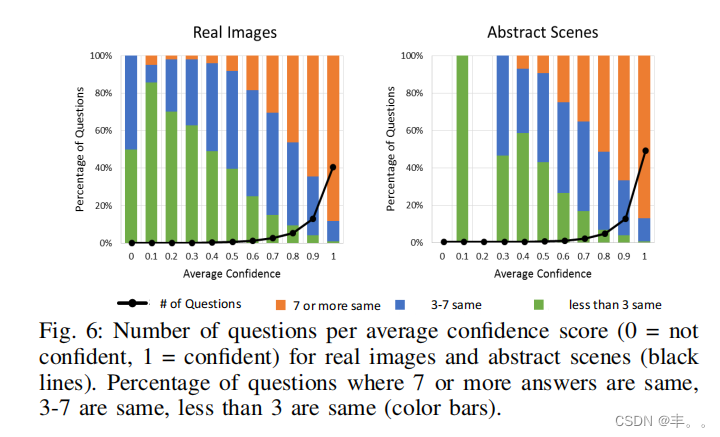
信心越大,越高。然而,即使所有的受试者都很自信,答案也可能会有所不同。这并不奇怪,因为有些答案可能会有所不同,但含义非常相似,比如“快乐”和“快乐”。
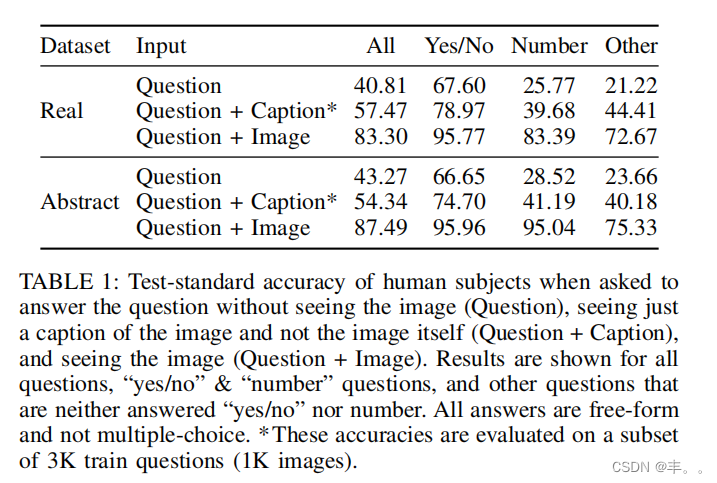
如表1(问题+图像)所示,在真实图像(83.30%)和抽象场景(87.49%)的答案中,存在显著的人与人之间的一致性。注意,对于真实图像,平均每个问题有2.70个唯一答案,对于抽象场景,则有2.39个唯一答案。“是/否”问题的一致性明显更高(> 95%),而其他问题的一致性更低(< 76%),这可能是因为我们执行了精确的字符串匹配,没有考虑同义词、复数等问题。请注意,自动确定同义词是一个困难的问题,因为答案粒度的水平可能因问题而异。
常识性知识
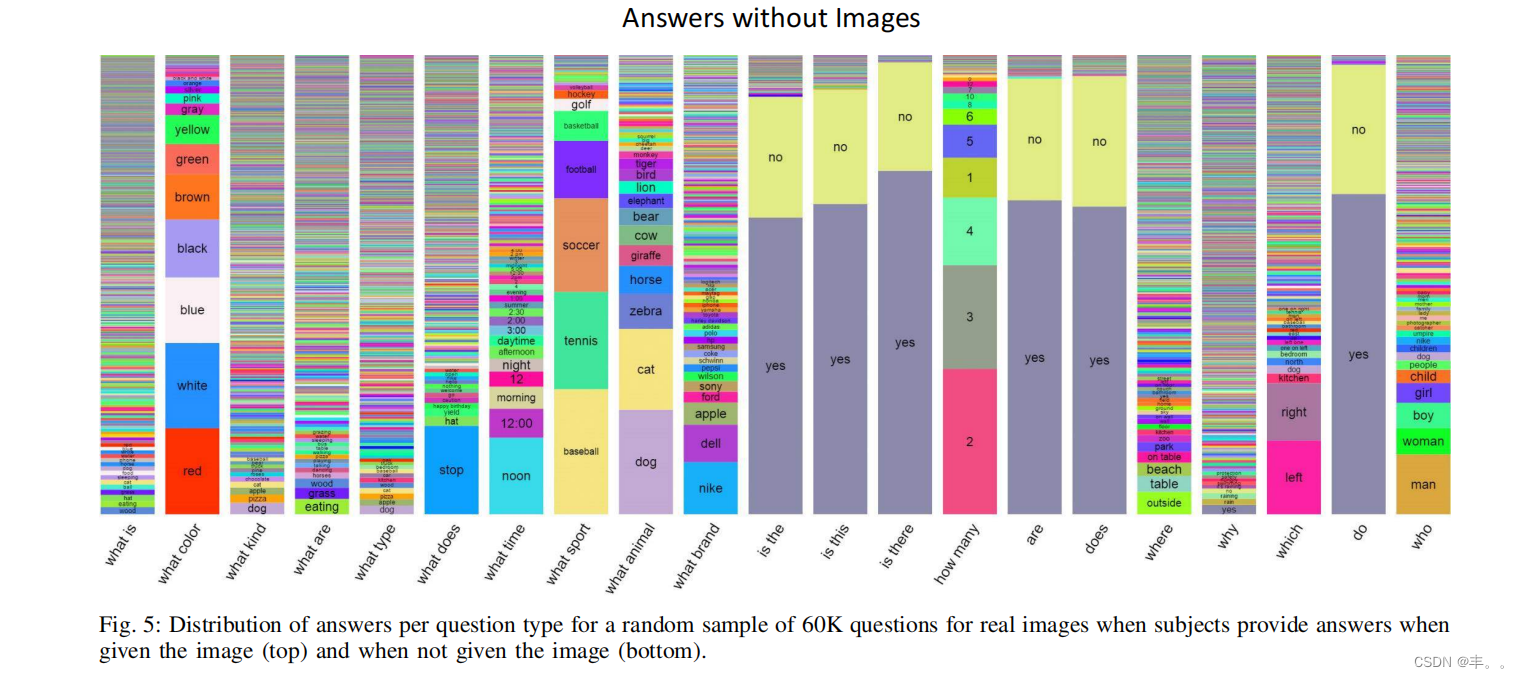
形象是必要的吗?显然,有些问题有时不需要图像就可以只用常识正确回答,例如,“消防栓的颜色是什么?”我们通过让三个受试者在没有看到图像的情况下回答问题来探索这个问题(见图2中蓝色的例子)。在表1(问题)中,我们显示了在所有问题中提供正确答案的问题的百分比,“是/否”问题,以及其他不是“是/否”的问题。对于“是/否”的问题,人类受试者的反应要比随机的好。而对于其他问题,人类的正确率只有21%左右。这表明,理解视觉信息对VQA至关重要,仅凭常识性信息是不够的。
为了显示有图像和没有图像提供的答案的质的差异,我们在图5(下图)中显示了各种问题类型的答案分布。对于有图像和没有图像的答案,颜色、数字甚至“是/否”回答的分布都有惊人的不同。
哪些问题需要常识?为了识别需要常识推理才能回答的问题,我们进行了两次AMT研究(对来自VQA训练真实图像的10K个问题的子集),询问受试者
1)他们是否认为一个问题需要com-
用常识来回答问题,以及2)他们认为一个人为了能够正确回答问题而必须达到的最年轻年龄组
-幼儿(3-4岁),幼儿(5-8岁),大孩子(9-12岁),青少年(13-17岁),成人(18岁以上)。
每个问题向10个受试者展示。我们发现,在3个或更多的问题中,47.43%的人对常识投了赞成票,(18.14%:6个或更多)。在“回答问题所需的感知人类年龄”研究中,我们发现了以下回答分布:幼儿:15.3%,幼儿:39.7%,较大的儿童:28.4%,青少年:11.2%,成年人:5.5%。在图7中,我们展示了几个问题,其中大多数受试者选择了指定的年龄范围。令人惊讶的是,回答这些问题所需的感知年龄在不同的年龄范围内分布得相当好。正如预期的那样,被成年人(18岁以上)认为可以回答的问题通常需要专业知识,而那些由蹒跚学步的孩子(3-4岁)可以回答的问题则更为通用。
我们通过在“某个问题是否需要常识”研究中投票“是”的被试(10人中)的百分比来衡量回答一个问题所需的常识程度。表3显示了回答问题所需的平均年龄和平均常识程度(在0 - 100的范围内)的细粒度细分。所有问题的平均年龄和平均常识程度分别为8.92和31.01%。
区分以下几点很重要:
1)一个人需要多大年纪才能正确回答问题,以及
2)人们认为一个人需要多大年纪才能正确回答一个问题。
我们的年龄标注捕捉到了后者——MTurk员工在不受控制的环境中的感知。因此,表3中问题类型的相对顺序比绝对年龄数字更重要。根据两项研究所需的常识,问题的两个排名在很大程度上是相关的(Pearson’s rank correlation: 0.58)。
Captions vs.Questions
通用的图片说明是否提供了足够的信息来回答问题?表1(问题+标题)显示了人类答对问题的百分比

受试者会得到问题和人类提供的描述图像的标题,但不是图像本身。正如预期的那样,结果比单独向人类展示问题要好。然而,准确率明显低于向受试者展示实际图像时的准确率。这表明,为了正确回答问题,更深入的图像理解(超出图像说明通常捕获的内容)是必要的。事实上,我们发现,在真实图像和抽象场景中,标题中提到的名词、动词和形容词的分布在统计上与我们的问题+答案中提到的分布(Kolmogorov-Smirnov检验,p < .001)都有显著差异。详见附录。
VQA baseline 与方法
在本节中,我们使用几个基线和新方法探索MS COCO图像的VQA数据集的难度。我们在VQA训练+val上进行训练。除非另有说明,所有人类准确率都在test-standard上,机器准确率在test-dev上,涉及人类字幕(灰色字体)的结果在train上训练,在val上测试(因为字幕不可用于测试)。
baseline
我们实现了以下基线:
- random:我们从VQA train/val数据集的前1K个答案中随机选择一个答案。
2)先验(“是”):对于开放式和多项选择任务,我们总是选择最受欢迎的答案(“是”)。请注意,“是”总是多项选择题的选项之一。
3)每个q型先验:对于开放式任务,我们选择每个问题类型中最受欢迎的答案(详见附录)。对于多项选择任务,我们使用Word2Vec[39]特征空间中的余弦相似度,从提供的选项中选择与开放式任务中选择的答案最相似的答案。
4)最近邻:给定一个测试图像、问题对,我们首先从训练集中找到K个最近邻问题和相关图像。关于如何找到邻居的详细信息,请参见附录。接下来,对于开放式任务,我们从这组最近邻问题(图像对)中选择最常见的基础真值答案。类似于
“每q型先验”基线,对于多项选择任务,我们使用余弦相似度从提供的选项中选择与开放式任务中选择的答案最相似的答案
Word2Vec[39]特征空间。
方法
对于我们的方法,我们开发了一个2通道视觉(图像)+语言(问题)模型,最终得到K个可能输出的softmax。我们选择前K = 1000个最频繁的答案作为可能的输出。这组答案涵盖了train+val答案的82.67%。我们将模型的不同组成部分描述如下:
图像通道:该通道为图像提供嵌入。我们实验了两种嵌入——
- I:使用VG- GNet[48]的最后一个隐藏层的激活作为4096-dim图像嵌入。
- norm I:这些2 是来自VGGNet的最后一个隐藏层的规范化激活[48]。
问题通道(Question Channel):该通道为问题提供了嵌入。我们实验了三种嵌入——
1)词袋问题(BoW Q):用问题中排名前1000的单词来创建词袋表示。由于问题开头的单词和答案之间存在很强的相关性(见图5),我们找到问题的前10个、第二和第三个单词,并创建一个30维词袋表示。将这些特征连接起来,得到问题的1030 -dim嵌入。 - LSTM Q:使用带有一个隐藏层的LSTM来获得问题的1024-dim嵌入。从LSTM中获得的嵌入是LSTM的隐藏层中最后一个细胞状态和最后一个隐藏状态表示(每个都是512-dim)的串联。每个问题词由一个全连接层+ tanh非线性用300 dim嵌入编码,然后将其馈送到LSTM。嵌入层的输入词汇由训练数据集中看到的所有问题词组成。
3)更深的LSTM Q:使用具有两个隐藏层的LSTM来获得问题的2048-dim嵌入。从LSTM中获得的嵌入是最后一个细胞状态和最后一个隐藏状态表示(每个
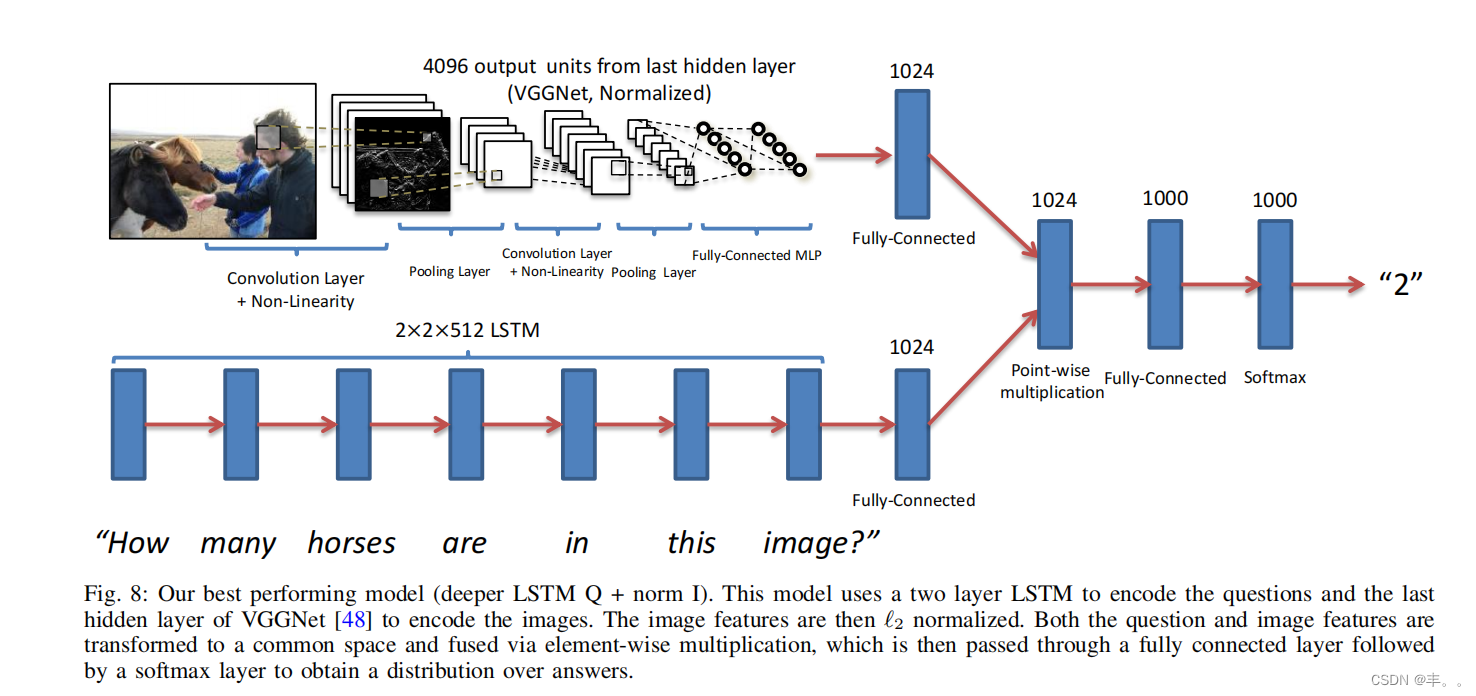
为512-dim),分别来自LSTM的两个隐藏层。因此,图8中的2(隐藏层)x 2(细胞状态和隐藏状态)x 512(每个细胞状态的维度,以及隐藏状态)。接下来是一个全连接层+ tanh非线性,将2048-dim嵌入转换为1024-dim。问题词的编码方式与LSTM Q中的编码方式相同。
多层感知器(multilayer Perceptron, MLP):将图像和问题嵌入结合起来,获得单个嵌入。
1)对于BoW Q + I方法,我们简单地将BoW Q和I嵌入连接起来。
2)对于LSTM Q + I,以及更深层的LSTM Q +范数I(图8)方法,首先通过全连接层+ tanh非线性将图像嵌入转换为1024-dim,以匹配问题的LSTM嵌入。转换后的图像和LSTM嵌入(在公共空间中)然后通过元素智能乘法融合。
然后将这个组合的图像+问题嵌入传递给MLP——一个完全连接的神经网络分类器,具有2个隐藏层和1000个隐藏单元(dropout 0.5),每层具有tanh非线性,然后是一个softmax层,以获得K个答案的分布。整个模型是端到端的学习,具有交叉熵损失。VGGNet参数被冻结为ImageNet分类所学习的参数,而不是在图像通道中进行微调。
我们还尝试提供字幕作为模型的输入。与表1类似,我们假设将人工生成的标题作为输入。我们使用包含标题中最流行的1000个单词的词袋表示作为标题嵌入(caption)。对于BoW Question + Caption (BoW Q + C)方法,我们简单地将BoW Q和C嵌入连接起来。
为了测试,我们报告了两个不同任务的结果:开放式从所有任务中选择激活度最高的答案
可能的K个答案和多项选择从潜在的答案中选出激活度最高的答案。
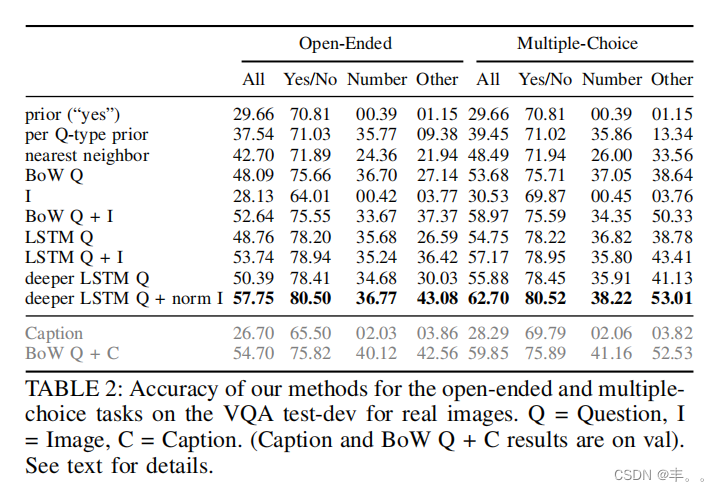
结果
表2显示了我们对真实图像的VQA测试开发中开放式和多项选择任务的基线和方法的准确性。正如预期的那样,完全忽略问题的单独视觉模型(I)表现相当差(开放式:28.13% /多项选择:30.53%)。事实上,在开放式任务上,视觉单独模型(I)的表现比先验(“是”)基线更差,后者同时忽略了图像和问题(对每个问题都回答“是”)。
有趣的是,忽略图像的单独使用语言的方法(每Q型先验、BoW Q、LSTM Q)表现出奇地好,BoW Q在开放式任务上达到48.09%(多项选择题上达到53.68%),LSTM Q在开放式任务上达到48.76%(多项选择题上达到54.75%);两者都优于最近邻基线(开放式:42.70%,multiple-
选择:48.49%)。我们的定量结果和分析表明,这可能是由于语言模型利用了关于问题类型的微妙统计先验(例如,“香蕉是什么颜色?”可以在不看图像的情况下回答为“黄色”。有关问题中微妙偏差的详细讨论,请参见[56]。
我们的最佳模型(深层LSTM Q +规范I(图8),使用VQA测试开发精度选择)在VQA测试标准上的准确性为58.16%(开放式)/ 63.09%(多项选择)。我们可以看到,我们的模型能够显著优于单独的视觉基线和单独的语言基线。总的趋势是,选择题的结果比开放式的要好。所有方法的表现都明显不如人类。
我们的VQA演示可以在CloudCV [1] - http://cloudcv上获得。org/vqa。这将在我们开发时使用更新的模型进行更新。
为了进一步了解这些结果,我们在表3中按问题类型计算了准确率。有趣的是,对于需要更多推理的问题类型,如“Is the”或“How many”,场景级图像特征并没有提供任何额外的信息。然而,对于可以使用场景级信息回答的问题,比如“什么运动”,我们确实看到了改进。同样,对于答案可能包含在通用标题中的问题,我们也看到了改进,比如“什么动物”。对于所有类型的问题,结果都比人类的准确率差。
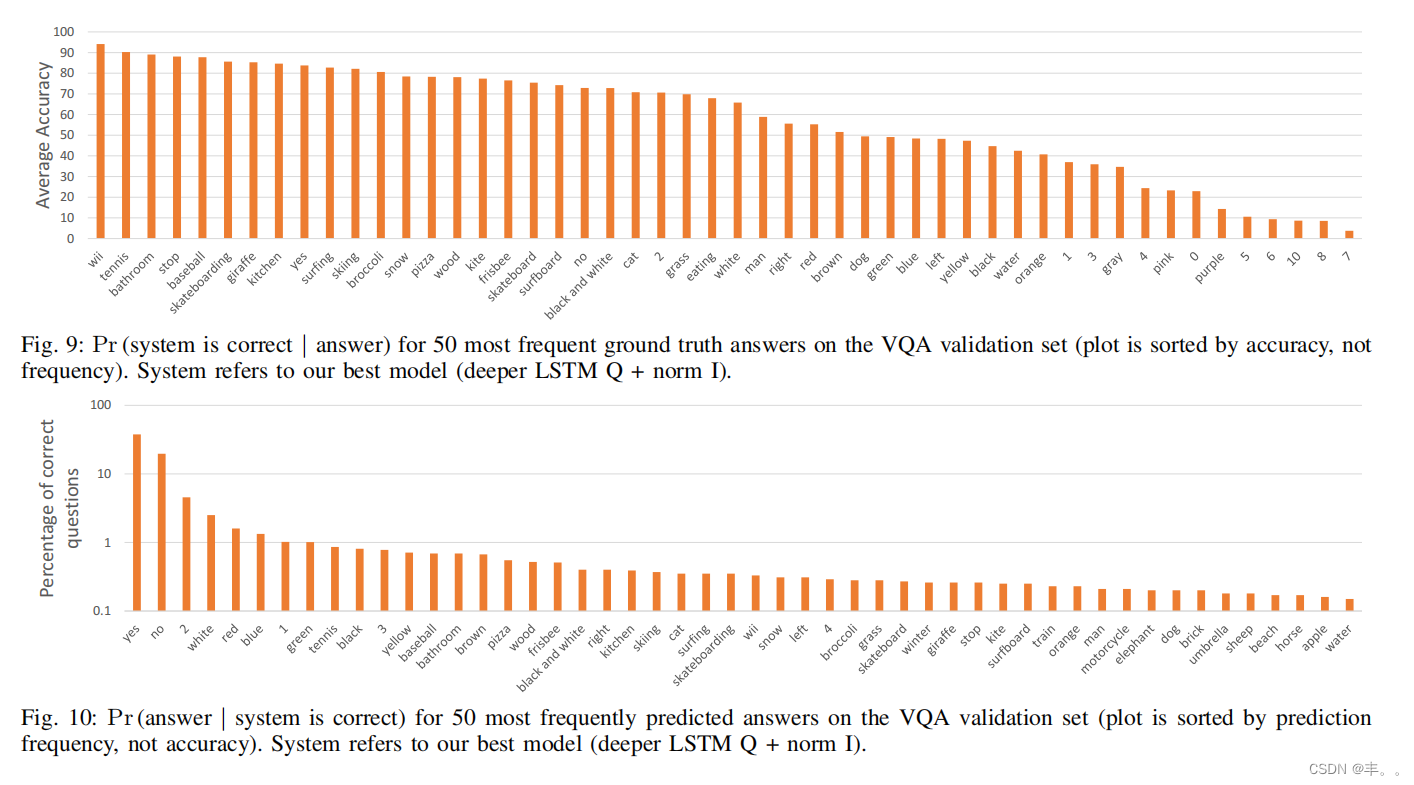
我们还分析了我们最好的模型(更深层次的LSTM Q +规范I)在具有某些特定(基础真值)答案的问题子集上的准确性。在图9中,我们展示了该模型在VQA验证集中具有50个最常见的基础真答案的问题上的平均准确率(图是按准确率排序的,而不是频率)。我们可以看到,该模型对于常见的视觉对象(如“wii”、“网球”、“浴室”)的答案表现良好,而对于计数(如“2”、“1”、“3”)的性能则有些平淡无奇,对于更高的计数(如“5”、“6”、“10”、“8”、“7”)的性能尤其差。
在图10中,我们展示了当系统在VQA验证集上是正确的情况下,50个最常预测的答案的分布(图是根据预测频率而不是准确性排序的)。在这个分析中,“系统是正确的”意味着它具有VQA精度1.0(参见第3节的精度度量)。我们可以看到,当模型正确时,频繁出现的基础真值答案(例如,“是”、“否”、“2”、“白色”、“红色”、“蓝色”、“1”、“绿色”)比其他答案更频繁地被预测。
最后,在我们有年龄注释(人类需要多大年龄才能正确回答问题)的验证问题上评估我们的最佳模型(更深层次的LSTM Q +规范I),我们估计我们的模型表现得和4.74岁的孩子一样好!同一组问题所需的平均年龄为8.98岁。在我们有常识性注释(问题是否需要常识来回答)的验证问题上评估同一模型,我们估计它的常识性程度为17.35%。同一组问题所需的平均常识性程度为31.23%。同样,这些估计反映了土耳其工人认为的年龄和常识
都需要回答这个问题详见附录。
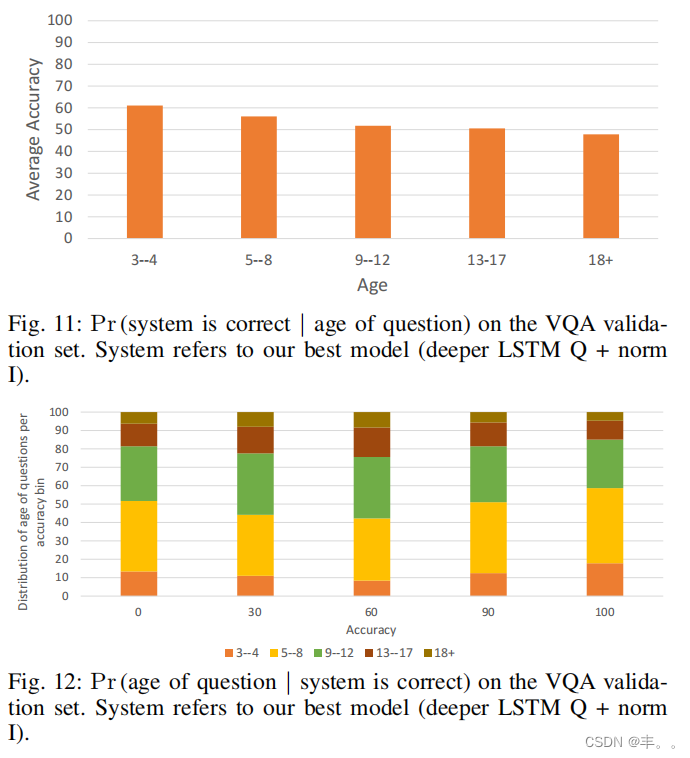
我们进一步分析了模型在不同年龄组的验证问题上的性能,我们为这些验证问题提供了年龄注释。在图11中,我们计算了模型对属于不同年龄组的问题所做预测的平均准确率。也许正如预期的那样,模型的准确率随着问题年龄的增加而下降(从3 - 4岁年龄组的61.07%下降到18+年龄组的47.83%)。
在图12中,我们展示了我们的系统在我们有年龄注释的验证问题上实现的不同精度级别的问题年龄分布。有趣的是,不同年龄组的相对比例在所有精度箱中是一致的,属于5-8年龄组的问题构成了大部分预测,这是预期的,因为5-8是数据集中最常见的年龄组(见图7)。
表4显示了我们的最佳模型(更深的LSTM Q +规范I)的不同精简版本在VQA测试开发上的开放式和多项选择任务的准确性。不同的精简版本如下-
1)没有I Norm:在这个模型中,来自VGGNet的最后一个隐藏层的激活[48]没有被“2标准化”。比较表4和表2中的准确率,我们可以看到,对于开放式任务,图像特征的“2归一化”使性能提高了0.16%,对于多项选择任务则提高了0.24%。
2)串联(Concatenation):在该模型中,转换后的图像和LSTM嵌入被串联(而不是按元素相乘),导致
- K = 2000:在这个模型中,我们使用K = 2000个最常见的答案作为可能的输出。比较表4和表2中的准确率,我们可以看到K = 2000在开放式任务中的表现比K = 1000好0.40%,在多项选择任务中的表现比K = 1000好1.16%。
5)截断的Q Vocab @ 5:在该模型中,嵌入层(对问题词进行编码)的输入词汇仅由在训练数据集中出现至少5次的问题词组成,从而将词汇量从14770(使用所有问题词时)减少到5134(减少65.24%)。剩余的问题词被替换为UNK(未知)令牌。比较表4和表2中的准确率,我们可以看到截断问题词汇@ 5比使用所有问题词汇在开放式任务中表现更好0.24%,在多项选择任务中表现更好0.17%。
6)截断的Q Vocab @ 11:在该模型中,嵌入层(对问题词进行编码)的输入词汇仅由在训练数据集中出现至少11次的问题词组成,从而将词汇量从14770(使用所有问题词时)减少到3561(减少75.89%)。剩余的问题词被替换为UNK (un- unknown)标记。比较表4和表2中的准确率,我们可以看到截断问题词汇@ 11比使用所有问题词汇在开放式任务和多项选择任务中分别提高0.06%和0.02%。
7)过滤数据集:我们创建了VQA训练+ val数据集的过滤版本,其中我们只保留主题置信度为“是”的答案。此外,我们只保留那些至少有50%(10个中的5个)答案被标注为主题置信度“yes”的问题。过滤后的数据集由344600个问题组成,
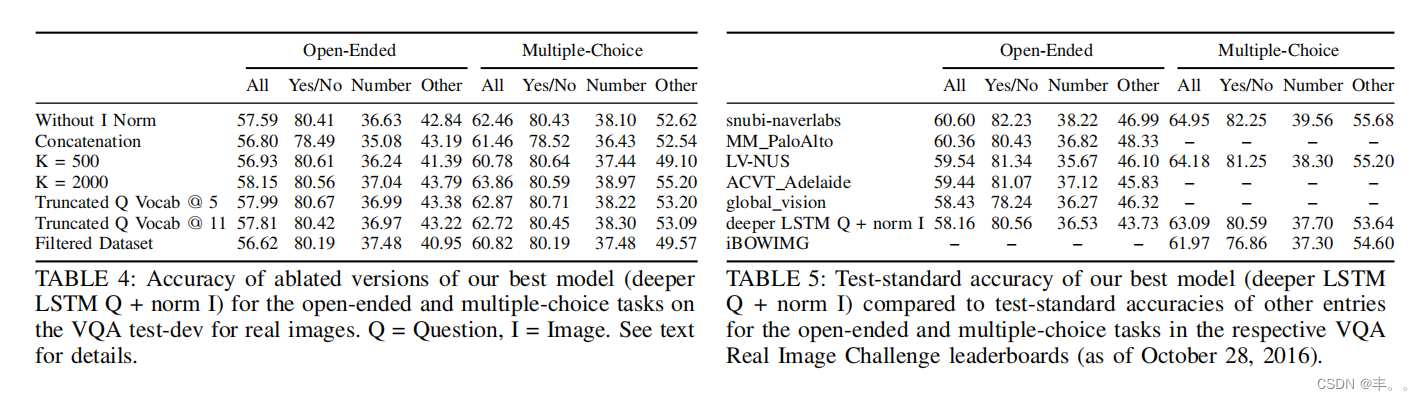
与原始数据集中的369861个问题相比,从而导致数据集的大小只减少了6.83%。过滤后的数据集平均每个问题有8.77个答案。我们没有对测试集进行过滤,以便可以将在过滤后的数据集上训练的模型的准确率与在原始数据集上训练的模型的准确率进行比较。表4中的“过滤后的数据集”行显示了在过滤后的数据集上训练时更深层的LSTM Q +范数I模型的性能。将这些准确率与表2中相应的准确率进行比较,我们可以看到,在过滤版本上训练的模型在开放式任务上的表现差了1.13%,在多项选择任务上的表现差了1.88%。
VQA的挑战与讨论
我们已经建立了一个评估服务器3 ,可以在其中上传测试集的结果,并返回准确性细分。我们正在组织年度挑战和研讨会,以促进这一领域的系统进展;该研讨会的第一个实例将在20164年CVPR举行。我们建议在VQA数据集上报告结果的论文-
1)报告测试标准准确性,可以使用以下链接中的非测试开发阶段(即“test2015”或“Challenge test2015”)中的任何一个来计算:[e-real | e-abstract | mc-real | mc-abstract]。
2)将它们的测试标准精度与相应的test2015排行榜[oe-real-leaderboard | oe-abstract-leaderboard | mc-real-leaderboard | mc- abstract-leaderboard]上的测试标准精度进行比较。
详情请参见挑战页面5。开放式真题和多项选择真题的积分排行榜截图如图13所示。我们还比较了我们的最佳模型(深度LSTM Q + norm I)在开放式和多项选择任务(真实图像)上的测试标准准确性与表5中相应排行榜上的其他条目(截至2016年10月28日)。
结论
最后,我们介绍了可视化问答(VQA)任务。给定一个图像和一个开放式的,自然的关于图像的语言问题,任务是提供准确的自然语言答案。我们提供了一个包含超过250K张图像、760K个问题和大约10M个答案的数据集。我们展示了数据集中各种各样的问题和答案,以及准确回答这些问题所需的计算机视觉、自然语言处理和常识推理方面的各种AI能力。
我们向人类受试者征集的问题是开放式的,没有特定的任务。对于某些应用领域,收集特定于任务的问题会很有用。例如,问题可以从视觉受损的受试者那里收集[3],或者问题可以集中在一个特定的领域(比如体育)。Bigham等人[3]创建了一个应用程序,允许视障人士捕捉图像,并提出由人类受试者回答的开放式问题。有趣的是,这些问题很少能用通用的字幕来回答。针对任务特定数据集的训练可能有助于实现实际的VQA应用。
我们认为VQA具有独特的优势,可以在“ai完成”问题上推动前沿,同时可以接受自动评估。考虑到社区最近的进展,我们认为进行这种努力的时机已经成熟。
致谢我们要感谢亚马逊土耳其机器人的工作人员付出的无数小时的努力。这项工作得到了保罗·g·艾伦家族基金会的部分支持,通过向D.P.颁发奖项,弗吉尼亚理工大学的ICTAS通过向D.B.和D.P.颁发奖项,谷歌教师研究奖给D.P.和D.B.,国家科学基金会职业奖给D.B.,陆军研究办公室YIP奖给D.B.,以及海军研究办公室给D.B.的资助