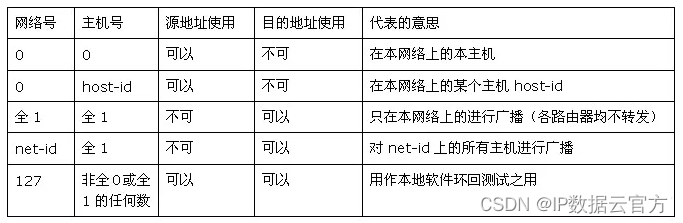
1. 解决了什么问题?
单目 3D 检测成本低、配置简单,对一张 RGB 图像预测 3D 空间的 3D 边框。最难的任务就是预测实例深度,因为相机投影后会丢失深度信息。以前的方法大多直接预测深度,本文则指出 RGB 图像上的实例深度不是一目了然的,它由视觉深度信息和实例属性信息耦合,很难直接用网络学到。

2. 提出了什么方法?
将实例深度看作为实例视觉表面深度(visual depth)和实例属性深度(attribute depth)的结合。Visual depth 与物体的外观和画面中的位置有关。Attribute depth 则取决于物体的内在属性(维度、朝向等),它关注于 RoI 内的特征,与图像中的仿射变换无关。Visual depth 定义是物体上每个点到相机的绝对深度值,attribute depth 是从这些点到物体 3D 中心的相对深度偏移量。我们用不同的 heads 来提取不同类型的特征,分别进行深度预测。
对于每个图块,分割为 m × n m\times n m×n个网格。每个网格表示物体的一小部分,它有一个 visual depth 和 attribute depth。考虑到遮挡和 3D 位置的不确定性,uncertainty 表示每个深度预测的置信度。推理时,每个目标输出 m × n m\times n m×n个实例深度预测,自适应地获取最终的实例深度预测和置信读。
Preliminaries
单目 3D 目标检测的输入是一张 RGB 图像 I ∈ R H × W × 3 \text{I}\in \mathbb{R}^{H\times W\times 3} I∈RH×W×3,在 3D 空间预测单模态的 3D 边框,包括 3D 中心点位置 ( x , y , z ) (x,y,z) (x,y,z)、维度 ( h , w , l ) (h,w,l) (h,w,l)和朝向角 θ \theta θ,朝向角通常指的是偏航角。经过特征编码后,得到特征图 F ∈ R H 4 × W 4 × C \text{F}\in \mathbb{R}^{\frac{H}{4}\times \frac{W}{4}\times C} F∈R4H×4W×C, C C C是通道数。然后 F \text{F} F输入进 3 个 2D 检测 heads,即 2D 热力图 H ∈ R H 4 × W 4 × B \text{H}\in \mathbb{R}^{\frac{H}{4}\times \frac{W}{4}\times B} H∈R4H×4W×B、2D 偏移量 O 2 d ∈ R H 4 × W 4 × 2 \text{O}_{2d}\in \mathbb{R}^{\frac{H}{4}\times \frac{W}{4}\times 2} O2d∈R4H×4W×2、2D size S 2 d ∈ R H 4 × W 4 × 2 \text{S}_{2d}\in \mathbb{R}^{\frac{H}{4}\times \frac{W}{4}\times 2} S2d∈R4H×4W×2, B B B是类别数。这样,我们可以得到 2D 边框预测。然后,根据这些 2D 框从特征图 F \text{F} F上使用 RoI Align 提取单个目标的特征, F o b j ∈ R n × 7 × 7 × C \text{F}_{obj}\in \mathbb{R}^{n\times 7\times 7\times C} Fobj∈Rn×7×7×C,其中 7 × 7 7\times 7 7×7是 RoI Align 的大小, n n n是 RoIs 的个数。最后,将这些目标特征 F o b j \text{F}_{obj} Fobj输入进 3D 检测 heads 获取 3D 参数。于是,我们就有了 3D 中心点映射偏移量 O 3 d ∈ R n × 2 \text{O}_{3d}\in \mathbb{R}^{n\times 2} O3d∈Rn×2、3D 边框维度 S 3 d ∈ R n × 3 \text{S}_{3d}\in \mathbb{R}^{n\times 3} S3d∈Rn×3、朝向角 Θ ∈ R n × k × 2 \Theta\in \mathbb{R}^{n\times k\times 2} Θ∈Rn×k×2( k k k是 multi-bin 里面的个数)、visual depth D v i s ∈ R n × 7 × 7 \text{D}_{vis}\in \mathbb{R}^{n\times 7\times 7} Dvis∈Rn×7×7、visual depth uncertainty U v i s ∈ R n × 7 × 7 \text{U}_{vis}\in \mathbb{R}^{n\times 7\times 7} Uvis∈Rn×7×7、attribute depth D a t t r ∈ R n × 7 × 7 \text{D}_{attr}\in \mathbb{R}^{n\times 7\times 7} Dattr∈Rn×7×7、attribute depth uncertainty U a t t r ∈ R n × 7 × 7 \text{U}_{attr}\in \mathbb{R}^{n\times 7\times 7} Uattr∈Rn×7×7。有了这些参数,我们就可计算出最终的 3D 边框预测。
Decoupled Instance Depth
Visual Depth
表示物体表面在小 RoI 网格上的物理深度。每个网格的 visual depth 就是网格内所有像素的平均深度。单目图像里的 visual depth 有一个重要特性。对于一个单目系统,visual depth 高度依赖物体的 2D 框大小(远处的物体在图像上要小一些)以及图像中的位置(图像坐标系里的
v
v
v越小,表示深度越深)。所以,如果我们对图像做仿射变换,visual depth 也会随之变换,深度值应该随之缩放。这个过程就是 affine-sensitive。

Attribute Depth
表示从物体视觉表面到目标 3D 中心点的深度偏移量。它和物体的内在属性联系更加紧密,所以叫做 attribute depth。例如,当车辆朝向与 3D 空间的 z z z轴(深度方向)平行时,车尾的 attribute depth 就是车子长度的一半;当朝向与 x x x轴平行,则 attribute depth 是车子宽度的一半。Attribute depth 取决于物体的语义信息和内在特性,并且对于仿射变换是不敏感的,因为物体的内在特性不会随着仿射变换而变化。这个过程就是 affine-invariant。
作者使用 2 个 heads 分别预测 visual depth 和 attribute depth。有以下的好处:
- 以一种合理并自然的方式将目标深度解耦,更能全面、准确地表示物体;
- 网络针对不同类型的深度提取不同的特征,加速学习;
- 深度解耦了,就能通过仿射变换进行有效的数据增广。
数据增广
在单目 3D 检测领域,很少用仿射变换做数据增广,因为变换后的深度信息是不知道的。在数据增广中,作者增加了随机裁剪和尺度缩放策略。图像上的 3D 中心映射点也进行相同的仿射变换。用图像上
y
y
y轴的缩放系数来对 visual depth 做缩放,因为
d
=
f
⋅
h
3
d
h
2
d
d=\frac{f\cdot h_{3d}}{h_{2d}}
d=h2df⋅h3d,
f
,
h
3
d
,
h
2
d
f,h_{3d},h_{2d}
f,h3d,h2d分别是焦距、物体的 3D 高度和 2D 高度。Attribute depth 会保持不变,因为它对仿射变换无感。类似地,物体的其它内在特性如观测角、维度,都保持不变。

Depth Uncertainty and Aggregation
因为 3D 定位比较困难,2D 分类得分无法充分表示单目 3D 检测的置信度。本文将实例深度 uncertainty 解耦为 visual depth uncertainty 和 attribute depth uncertainty。只有当物体的 visual depth uncertainty 和 attribute depth uncertainty 都很低时,实例深度的置信度才。
假设 D v i s ∈ R n × 7 × 7 \text{D}_{vis}\in \mathbb{R}^{n\times 7\times 7} Dvis∈Rn×7×7里的每一个 visual depth d v i s d_{vis} dvis以及 U v i s ∈ R n × 7 × 7 \text{U}_{vis}\in \mathbb{R}^{n\times 7\times 7} Uvis∈Rn×7×7里其对应的 uncertainty u v i s u_{vis} uvis预测都服从 Laplace 分布 L ( d v i s , u v i s ) L(d_{vis},u_{vis}) L(dvis,uvis)。类似,attribute depth 的分布是 L ( d a t t , u a t t ) L(d_{att},u_{att}) L(datt,uatt),其中 d a t t ∈ D a t t ∈ R n × 7 × 7 d_{att}\in \text{D}_{att} \in \mathbb{R}^{n\times 7\times 7} datt∈Datt∈Rn×7×7, u a t t ∈ U a t t ∈ R n × 7 × 7 u_{att}\in \text{U}_{att}\in \mathbb{R}^{n\times 7\times 7} uatt∈Uatt∈Rn×7×7。因此,实例深度分布就是 L ( d ~ i n s , u ~ i n s ) L(\tilde{d}_{ins}, \tilde{u}_{ins}) L(d~ins,u~ins),其中 d ~ i n s = d v i s + d a t t \tilde{d}_{ins} = d_{vis}+d_{att} d~ins=dvis+datt, u ~ i n s = u v i s 2 + u a t t 2 \tilde{u}_{ins}=\sqrt{u_{vis}^2 + u_{att}^2} u~ins=uvis2+uatt2。然后用 D ~ i n s ( p a t c h ) ∈ R n × 7 × 7 \tilde{\text{D}}_{ins(patch)}\in \mathbb{R}^{n\times 7\times 7} D~ins(patch)∈Rn×7×7和 U ~ i n s ( p a t c h ) ∈ R n × 7 × 7 \tilde{\text{U}}_{ins(patch)}\in \mathbb{R}^{n\times 7\times 7} U~ins(patch)∈Rn×7×7表示 RoI 内的实例深度以及 uncertainty。
为了获得最终的实例深度,首先将 uncertainty 转化为概率,
P
i
n
s
(
p
a
t
c
h
)
=
exp
(
−
U
~
i
n
s
(
p
a
t
c
h
)
)
{\text{P}}_{ins(patch)}=\exp(-\tilde{\text{U}}_{ins(patch)})
Pins(patch)=exp(−U~ins(patch)),其中
P
i
n
s
(
p
a
t
c
h
)
∈
R
n
×
7
×
7
{\text{P}}_{ins(patch)}\in \mathbb{R}^{n\times 7\times 7}
Pins(patch)∈Rn×7×7。然后聚合图块内的实例深度。对于第
i
∈
{
i
,
.
.
.
,
N
}
i\in \lbrace i,...,N\rbrace
i∈{i,...,N}个物体,我们有:
d
i
n
s
=
∑
D
~
i
n
s
(
p
a
t
c
h
)
i
P
i
n
s
(
p
a
t
c
h
)
i
∑
P
i
n
s
(
p
a
t
c
h
)
i
d_{ins}=\sum \frac{\tilde{\text{D}}_{ins(patch)_i}{\text{P}}_{ins(patch)_i}}{\sum {\text{P}}_{ins(patch)_i}}
dins=∑∑Pins(patch)iD~ins(patch)iPins(patch)i
对应的实例深度置信度就是:
p
i
n
s
=
∑
(
P
i
n
s
(
p
a
t
c
h
)
i
∑
P
i
n
s
(
p
a
t
c
h
)
i
P
i
n
s
(
p
a
t
c
h
)
i
)
p_{ins}=\sum \left( \frac{\text{P}_{ins(patch)_i}}{\sum \text{P}_{ins(patch)_i}}\text{P}_{ins(patch)_i}\right)
pins=∑(∑Pins(patch)iPins(patch)iPins(patch)i)
因此,最终的 3D 检测置信度就是
p
=
p
2
d
⋅
p
i
n
s
p=p_{2d}\cdot p_{ins}
p=p2d⋅pins,
p
2
d
p_{2d}
p2d是 2D 检测置信度。
损失函数
2D 检测:延续了 CenterNet,2D 热力图 H \text{H} H表示图像上物体大概的中心位置。其大小是 H 4 × W 4 × B \frac{H}{4}\times \frac{W}{4}\times B 4H×4W×B, H , W , B H,W,B H,W,B分别是输入图像的高度、宽度和类别数。2D 偏移量 O 2 d O_{2d} O2d表示相对于 2D 中心点的偏移。2D 大小 S 2 d S_{2d} S2d表示 2D 框的高度和宽度。跟 CenterNet 一样,损失函数由 L H , L O 2 d , L S 2 d \mathcal{L}_H,\mathcal{L}_{O_{2d}},\mathcal{L}_{S_{2d}} LH,LO2d,LS2d组成。
3D 检测:
- 对于 3D 物体的维度,使用了常用的变换和损失设计 L S 3 d \mathcal{L}_{S_{3d}} LS3d。
- 对于朝向角,网络预测观测角,使用 multi-bin 损失 L Θ \mathcal{L}_{\Theta} LΘ。
- 使用图像平面上的 3D 中心点投影和实例的深度来还原物体的 3D 坐标。通过预测关于 2D 中心点的 3D 投影的偏移量,实
现 3D 中心点投影。损失函数是 L O 3 d = Smooth L 1 ( O 3 d , O 3 d ∗ ) \mathcal{L}_{O_{3d}}=\text{Smooth}L_1(O_{3d}, O_{3d}^*) LO3d=SmoothL1(O3d,O3d∗), ∗ * ∗表示对应的标签。 - 通过将激光雷达的点云投影到图像上得到 visual depth,然后实例深度标签减去 visual depth 标签,得到 attribute depth 标签。Visual depth 损失是: L D v i s = 2 u v i s ∥ d v i s − d v i s ∗ ∥ + log ( u v i s ) \mathcal{L}_{D_{vis}}=\frac{\sqrt{2}}{u_{vis}}\left\|d_{vis}-d_{vis}^*\right\|+\log(u_{vis}) LDvis=uvis2∥dvis−dvis∗∥+log(uvis), u v i s u_{vis} uvis是 uncertainty。
类似地,我们有 attribute depth 损失 L D a t t \mathcal{L}_{D_{att}} LDatt,实例深度损失 L D i n s \mathcal{L}_{D_{ins}} LDins。整体损失是:
L = L H + L O 2 d + L S 2 d + L S 3 d + L Θ + L D v i s + L D a t t + L D i n s \mathcal{L}=\mathcal{L}_H+\mathcal{L}_{O_{2d}}+\mathcal{L}_{S_{2d}}+\mathcal{L}_{S_{3d}}+\mathcal{L}_\Theta+\mathcal{L}_{D_{vis}}+\mathcal{L}_{D_{att}}+\mathcal{L}_{D_{ins}} L=LH+LO2d+LS2d+LS3d+LΘ+LDvis+LDatt+LDins
3. 有什么优点?
将实例的深度解耦为 visual depth 和物体的内在属性,网络能学到不同类型的深度特征。并且在数据增广时,能对图像有效地进行仿射变换,取得不错的效果。