前言:KuiperInfer是一个从零实现一个高性能的深度学习推理库,中文教程已经非常完善了。本系列博客主要是自己学习的一点笔记和二次开发的教程,欢迎更多的AI推理爱好者一起来玩。这篇写一下计算图相关的知识点,重点说明ONNX有什么缺点?为什么选择PNNX?如何构建计算图?PNNX的计算图里有哪些优化手段值得学习?
目录
为什么选择PNNX?
从OpenPPL的角度看为什么不选择ONNX?
讨论
构建计算图
C++ 前向声明
学习:PNNX中的计算图优化手段
1. Constant Folding
2. 去除冗余算子
3. 各种融合Pass
4. 算子等效变化Transform
参考
为什么选择PNNX?
首先这个问题要问nihui,为什么有了onnx还要再写一个pnnx?当然是为了有产出好晋升。当然是onnx有其自己的缺点,强烈推荐nihui自己写的博客:
PNNX: PyTorch Neural Network Exchange - 知乎
这里我总结一下:
- PyTorch 一些模型的算子可能在 ONNX 是没有的,这样导出 ONNX 的时候会出错导不出来。
- PyTorch 导 ONNX,有时候会导出一个非常复杂的计算图,这个情况会导致推理效率的下降。
- ONNX对第三方库的算子支持不够;导出的计算图比较复杂、细碎。

从OpenPPL的角度看为什么不选择ONNX?
我在之前openppl/ppl的文章里有写过,在做量化之前做了大量的计算图优化操作:
https://xduwq.blog.csdn.net/article/details/128839708
事实上,量化精度很大程度上取决于推理的支持,如果直接用onnx做推理的话,算子拆的稀巴烂,插入的量化节点必然会过多,严重影响量化后的模型推理。所以ppq在做量化之前做了大量的预处理-计算图优化。

讨论
当然会有很多大佬觉得根本没有必要花大力气再造一个ONNX,排除个人因素(影响个人升职加薪)之外,很多人会觉得我们只要像OpenPPL那样自己再做一些图优化就行。

我个人觉得PNNX还是挺好用的,真香就完事……
构建计算图
这一方面傅大狗说的非常详细,kuiper会封装PNNX,然后转换成自己的计算图,请看原文和视频:
自制深度学习推理框架-第七课-构建自己的计算图
自制深度学习推理框架-第七课-构建自己的计算图 - 知乎
C++ 前向声明
在定义IR的时候使用了C++中前向声明的知识点。先看一下源代码(在KuiperInfer/ir.h):
class Operator;
class Operand
{
public:
void remove_consumer(const Operator* c);
Operator* producer;
std::vector<Operator*> consumers;
// 0=null 1=f32 2=f64 3=f16 4=i32 5=i64 6=i16 7=i8 8=u8 9=bool 10=cp64 11=cp128 12=cp32
int type;
std::vector<int> shape;
// keep std::string typed member the last for cross cxxabi compatibility
std::string name;
std::map<std::string, Parameter> params;
};
class Operator
{
public:
std::vector<Operand*> inputs;
std::vector<Operand*> outputs;
// keep std::string typed member the last for cross cxxabi compatibility
std::string type;
std::string name;
std::vector<std::string> inputnames;
std::map<std::string, Parameter> params;
std::map<std::string, Attribute> attrs;
};
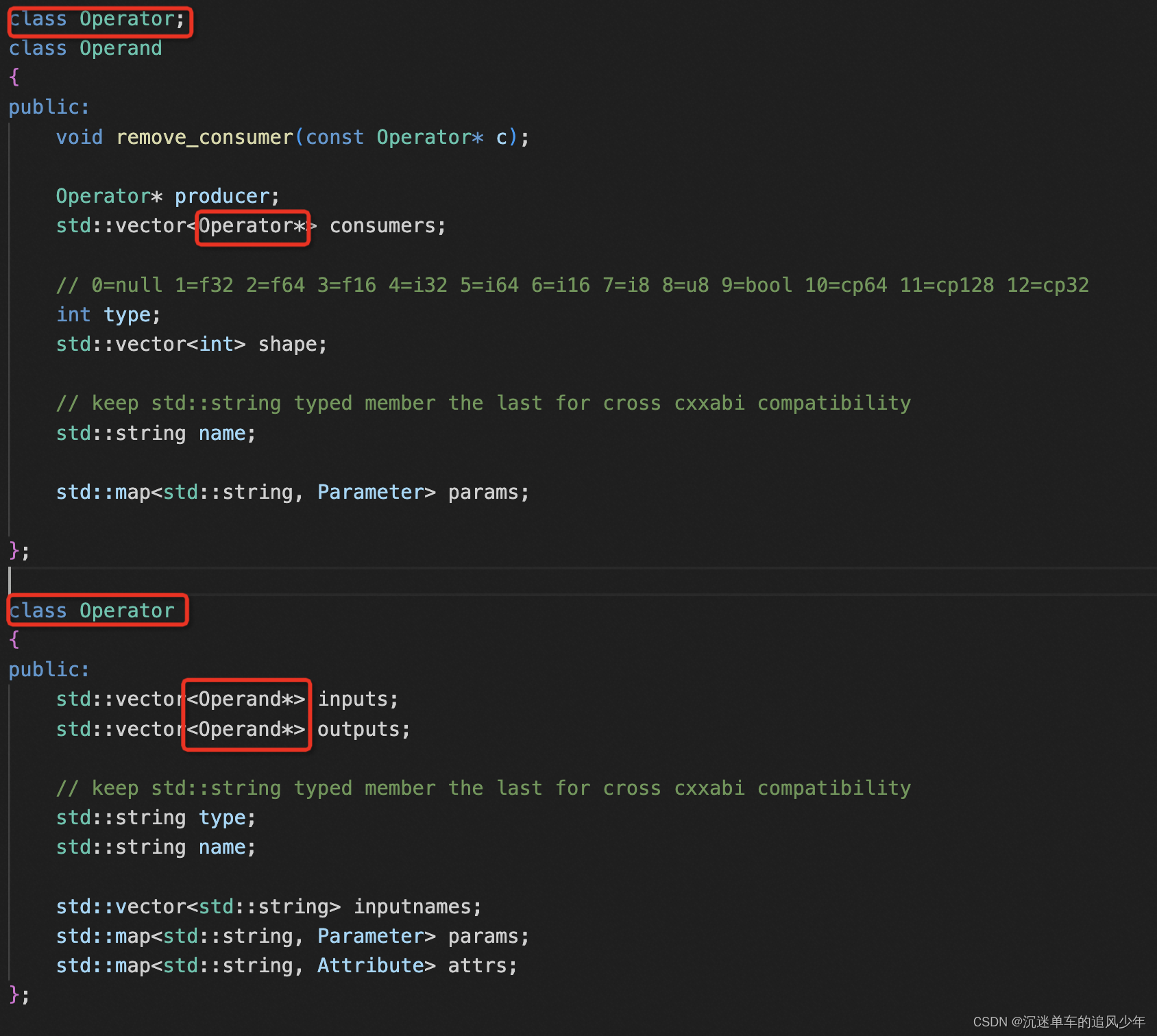
前向声明:可以声明一个类而不定义它。这个声明,有时候被称为前向声明(forward declaration)。在声明之后,定义之前,类Operator是一个不完全类型(incompete type),即已知Operator是一个类型,但不知道包含哪些成员。不完全类型只能以有限方式使用,不能定义该类型的对象,不完全类型只能用于定义指向该类型的指针及引用,或者用于声明(而不是定义)使用该类型作为形参类型或返回类型的函数。
请注意:尽管使用了前向引用声明,但是在提供一个完整的类声明之前,不能定义该类的对象,也不能在内联成员函数中使用该类的对象。 即当你使用前向引用声明时,你只能使用被声明的符号,而不能涉及类的任何细节。
如以下写法是错误的:
class Fred; //前向引用声明
class Barney
{
public:
void method()
{
x->yabbaDabbaDo(); //错误:Fred类的对象在定义之前被使用
}
private:
Fred* x; //正确,经过前向引用声明,可以声明Fred类的对象指针
};
class Fred
{
public:
void yabbaDabbaDo();
private:
Barney* y;
};学习:PNNX中的计算图优化手段
计算图优化手段是很多AI推理框架/AI编译器的重要卖点之一,而PNNX在这方面做的非常好,非常值得抄袭借鉴!
ncnn/tools/pnnx at master · Tencent/ncnn · GitHub
PNNX分成了5个level优化,很像AI编译器高pass优化到低pass优化的思路啊:


博主的功力还没有太多这方面的经验,我们可以看看大佬是怎么总结的:
如何选择深度学习推理框架? - 知乎
1. Constant Folding
首先是常量折叠,有时候我们有一些计算是会用到常量的,这些常量可以初始化成为图的一部分,不需要在推理的时候去算。适用于常量折叠的情况包括:
- 没有输入节点的算子,但是又不是input,例如引入的一个常量输入到某个算子中,这个Node是需要被挑出来的;
- 对于中间计算用到了Shape的操作,如果输入是固定的,那么这个shape可以被实现固定,不过对于torchscript来说,这点比较麻烦,因为torchscript默认都是动态的;
- 一些奇葩的操作可以被shrink,例如你在Conv外面又算了一次Pad,此时我们可以把Pad的操作柔到Conv里。
找到了这些可以被折叠的算子之后,就可以做折叠,其实就是把这些Node,改成Attribute,然后新建一个Operator,把这个Attribute当作是改Operator的固定参数。
2. 去除冗余算子
例如一些十分简单的:
- Identity Elimination;
- Slice Elimination;
- Unsqueeze Elimination;
- Dropout Elimination;
- Expand Elimination;
- Pooling Elimination;
- Duplicated Reshape Elimination;
- Opposite Operator Elimination;
- Common subGraph Elimination;
这些都是基本的操作,dropout大家都懂,Identity这个玩意儿实际上就是返回你的输入,也就是说你给他什么输入,他给你返回什么,看起来什么都没做,但是有些人写网络的和会用到这个,比如你要删除某个算子,但是又不想影响后面的操作,假设维度不变的时候,你就可以直接把那一层变为Identity。
这个Identity去掉的逻辑也很简单,遍历整个图,看看哪些算子的输入输出是一样的,如果是,那就把他删掉,直接把当前节点的输入接到下一个节点的输入。
对于Slice的剔除,主要是针对一个维度为d,然后slice为 [0, d-1]的操作,这就是slice了个寂寞,我们可以直接干掉。判断方法也很简单:
if (!op->inputs[0]->shape.empty() && op->inputs[0]->shape == op->outputs[0]->shape)
{
matched = true;
}直接看输入shape是不是空,以及shape是否slice了个寂寞。
还有Expand也是可以被拿掉的,如果你Expand了之后维度没变,那不就是expand了个寂寞么?直接干掉,判断逻辑可以复用Slice。
这个Pooling在1x1的时候是可以被干掉的,你pool了等于没有pool,要你何用?
当然后面这两种情况,取决于你的实际支持模型,一般高级一点的算法工程师不会干出这么猥琐的事情。
还有重复的Reshape,是可以合并成一个的。
对于前后反义的算子也可以被拿掉,例如,你先Squeeze了一下,然后又Expandim了,而且axis一样,就可以被换成Identity,然后被后面的Pass拿掉。所以你在此看到了Identity的应用了。
公共子图也是可以被优化的。例如,多个输入输入到了一个相同的Node后者Module,此时可以将其合并成一个。
最后其实还有一些量化相关的操作可以拿掉,比如:
- Quant-dequant Elimination;
关于QDQ的支持暂时不展开了,这个坑比较深。
3. 各种融合Pass
其实这些操作在量化里面也会用到,而且这些fusion非常有必要,可以极大的提高模型的运行速度,例如:
- Conv + (Add) Bias fusion;
- Conv + Scale fusion;
- Conv + Mul fusion;
- Conv + Relu fusion;
- MatMul + Add fusion;
- MatMul + Scale fusion;
- BN + Scale fusion;
- Conv + Bn fusion;
- Conv + Bn + Bias fusion;
- Conv + Bn + Relu fusion;
- FC + BN fusion;
- FC + Add Fusion;
类似于这样的计算等效,目的是减少访存的次数,从而被动增加推理速度。前提是框架里面要有对应的融合后算子的推理支持。
除此之外,你还可以做一些更高级别的融合Pass,这也需要推理Layer的强力支持。例如:
- BERT Embeding + LayerNorm + AttentionMask fusion;
- FC + LayerNorm fusion;
- MultiHead Attention fusion;
这些融合可以进一步的提高模型的速度,在Fastransformer,HuggingFace的transformer ONNXRuntime推理里面,都有这样的操作,尤其是对于Transformer-based的模型,融合大块算子显得非常有必要。
当然,这一部分也有量化相关的融合:
- Conv + BN + Relu -> ConvInt8;
- Conv1dQuant -> Conv2dQuant;
4. 算子等效变化Transform
对算子进行等效,也是必不可少的一步,这一步我们将一些不常用的算子替换成常用的算子,由于常用算子通常做了计算优化,可以更快。
- MatMul to Conv2D;
- FC (InnerProduct) to Conv2D 1x1;
- BN to Scale;
- ShuffleChannel to Reshape + Permute;
- GroupConv to Conv + Slice
差不多就是这些内容,最后以不就是把这些优化之后,鼓励的算子删掉就行了。
参考
- c++中的前向声明_前向声明 c++_和大黄的博客-CSDN博客
- https://www.cnblogs.com/wkfvawl/p/10801725.html
- PNNX: PyTorch Neural Network Exchange - 知乎
- ncnn/tools/pnnx at master · Tencent/ncnn · GitHub
- 如何选择深度学习推理框架? - 知乎