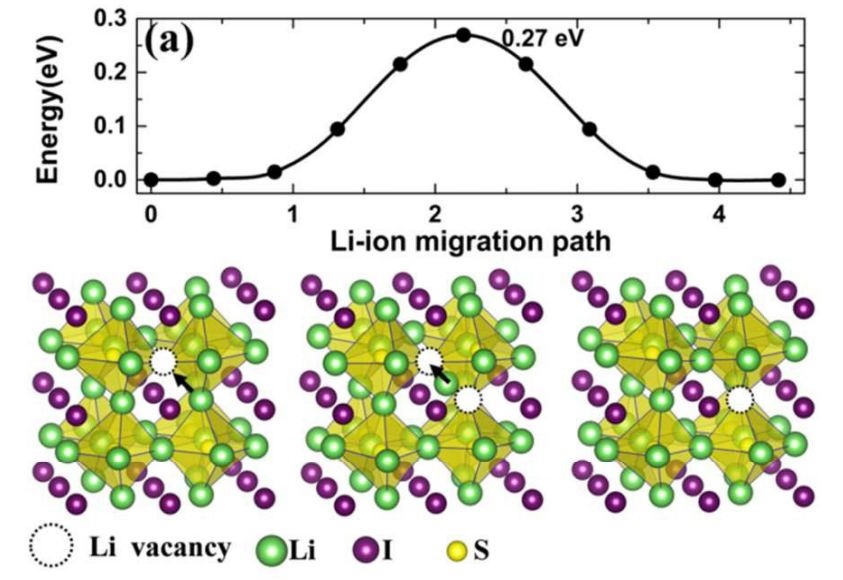
文章目录
- 一、Transformer的Attention
- 1. Self-Attention
- 2. Masked Self-Attention
- 3. Multi-Head Attention
- 二、Transformer Decoder(GPT)
- 1. GPT的网络结构
- 2. GPT的计算原理
一、Transformer的Attention
1. Self-Attention
如前篇文章所述(https://blog.csdn.net/liuqiker/article/details/130599569?spm=1001.2014.3001.5501),Scaled dot-prodect Attention是先计算Query和各个Key的相似性,即每个Key对应Value的权重系数,进而对Value进行加权求和(矩阵乘法),即得到了最终的Attention数值。其中,Key和Value是相同的数值,即代表同一个来源的句子,Query代表的是目标句子,Query和Key往往是不同的。
而在Self-Attention中,Query则和Key、Value相同,故而这时的Attention称为Self-Attention,即句子中每个词在这个句子中的Attention,如下图:

2. Masked Self-Attention
Masked Self-Attention是对Self-Attention的改进,在Self-Attention中,会计算每个单词与句子中所有其他单词的关系权重。而在实际的自然语言生成过程中,句子都是逐字生成的,当前字正在生成时,该字后边的句子内容还是未知的,即为空,因此,影响当前字的只有当前位置之前的句子,而不包括当前位置之后还处于未知状态的内容。此时Masked Self-Attention应运而生,如下图:

上述公式中,给Q和K的权重系数矩阵,加上一个右上角的值全为“负无限大”的矩阵,这样就掩盖了当前的Query与其后所有字的权重系数(置为0),称为Masked Self-Attention。
上节中的例子经过Mask后,变为如下形式:

3. Multi-Head Attention
Multi-Head Attention即将QKV映射到不同的空间让多个Head去学习不同的特征,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以提升模型效果。原理如下图:

那么,如何获得同一组QKV的不同空间特征呢?答案是进行线性变换,即对每组QKV,通过Linear计算,取得对应的特征矩阵,再对不同的特征矩阵组做Attention计算,最后将计算结果合并到一起且再经过Linear计算,得到最终的Multi-Head Attention,如下图:

注:d_model(词向量的维度)等于d_k(Linear变换的矩阵维度)乘以h(Head的数量)。
二、Transformer Decoder(GPT)
1. GPT的网络结构

上图是一个标准的GPT(Transformer Decoder)的网络结构,从下往上,共分为如下几个部分:
1. Inputs:GPT的输入,常见的是一段文字输入。在GPT中,我们会先将输入的句子中每个文字(或词语)映射为机器可以识别的token(即一个数字),常见的方法是维护一个词汇表,取该文字(或词语)在词汇表中的index为token。对于中文的句子,还要注意一句话中某些字可以组成一个词语,代表某一个完整的意思,那么这个词语在词汇表中的index就作为token,而不是将词语中的每个字拆开分别查找index;
2. Input Embedding:Embedding即词向量,该层是将输入的token映射为更紧凑的矩阵(1中映射得来的token转换成one-hot编码后,是一个稀疏矩阵,浪费了大量的计算资源,故需要转换成更紧凑的矩阵);
3. Positional Encoding:位置编码是将每个字(词)在句子中的位置做相应编码(即一个代表[1, 2, 3, …]的向量),并将其与输入相加,目的是让模型知道每个字(词)在句子中的位置信息,实验表明,该方式可以提高模型的准确度;
4. Multi-Head Attention:如上节所述,该层用于计算QKV的权重系数矩阵,即Attention,注意,这里的Attention是Masked Self-Attention;
5. Add&Norm:类似于残差网络的设计,将经过Multi-Head Attention前的输入,和经过Multi-Head Attention之后的输出相加并做Norm,可以让信息保存的更加完整;
6. Feed Forward:该层由两个Dense层组成,激活函数是relu,作用是对Attention做线性变换,更好的识别其代表的特征;
7. Add&Norm:同5;
8. Linear&Softmax:输出层,输出一个固定长度的文字序列,每个文字有不同的准确率(由于存在Softmax,所有的概率相加为1),如果想让模型输出更加多样化,则可以随机选择准确率最大的几个字,反之,则减小选择的范围;
注:图中的N,代表重复N次,不同的GPT版本N的大小不同,代表的参数规模也不同。
2. GPT的计算原理
GPT的计算过程基本如1中所述,这里引用一张网络上的图片做个总结: